您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关Scrapy框架爬取西刺代理网免费高匿代理的实现,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。
思路:
分析网页结构,确定数据提取规则
创建Scrapy项目
编写item,定义数据字段
编写spider,实现数据抓取
编写Pipeline,保存数据到数据库中
配置settings.py文件
运行爬虫项目
代码实现
items.py
import scrapy class XicidailiItem(scrapy.Item): # 国家 country=scrapy.Field() # IP地址 ip=scrapy.Field() # 端口号 port=scrapy.Field() # 服务器地址 address=scrapy.Field() # 是否匿名 anonymous=scrapy.Field() # 类型 type=scrapy.Field() # 速度 speed=scrapy.Field() # 连接时间 connect_time=scrapy.Field() # 存活时间 alive_time=scrapy.Field() # 验证时间 verify_time=scrapy.Field()
xicidaili_spider.py
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import scrapy
from myscrapy.items import XicidailiItem
class XicidailiSpider(scrapy.Spider):
name = 'xicidaili'
allowed_domains=['www.xicidaili.com']
# start_urls=['http://www.xicidaili.com/nn/1']
def start_requests(self):
urls=[]
for i in range(1,11):
urls.append('http://www.xicidaili.com/nn/'+str(i))
for url in urls:
yield scrapy.Request(url,callback=self.parse,method='GET')
def parse(self, response):
tr_list=response.xpath('//table[@id="ip_list"]/tr')
for tr in tr_list[1:]: # 过滤掉表头行
item=XicidailiItem()
item['country']=tr.xpath('./td[1]/img/@alt').extract_first()
item['ip']=tr.xpath('./td[2]/text()').extract_first()
item['port']=tr.xpath('./td[3]/text()').extract_first()
item['address']=tr.xpath('./td[4]/a/text()').extract_first()
item['anonymous']=tr.xpath('./td[5]/text()').extract_first()
item['type']=tr.xpath('./td[6]/text()').extract_first()
item['speed']=tr.xpath('./td[7]/div/@title').re(r'\d{1,3}\.\d{0,}')[0]
item['connect_time']=tr.xpath('./td[8]/div/@title').re(r'\d{1,3}\.\d{0,}')[0]
item['alive_time']=tr.xpath('./td[9]/text()').extract_first()
item['verify_time']=tr.xpath('./td[10]/text()').extract_first()
yield itempipelines.py
class XicidailiPipeline(object): """ 西刺代理爬虫 item Pipeline create table xicidaili( id int primary key auto_increment, country varchar(10) not null, ip varchar(30) not null, port varchar(10) not null, address varchar(30) not null, anonymous varchar(10) not null, type varchar(20) not null, speed varchar(10) not null, connect_time varchar(20) not null, alive_time varchar(20) not null, verify_time varchar(20) not null); """ def __init__(self): self.connection = pymysql.connect(host='localhost', user='root', password='123456', db='mydb', charset='utf8', # 不能用utf-8 cursorclass=pymysql.cursors.DictCursor) def process_item(self,item,spider): with self.connection.cursor() as cursor: sql='insert into xicidaili' \ '(country,ip,port,address,anonymous,type,speed,connect_time,alive_time,verify_time) values' \ '(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s);' args=(item['country'],item['ip'],item['port'],item['address'],item['anonymous'],item['type'],item['speed'],item['connect_time'],item['alive_time'],item['verify_time']) spider.logger.info(args) cursor.execute(sql,args) self.connection.commit() def close_spider(self,spider): self.connection.close()
settings.py
ITEM_PIPELINES = {
'myscrapy.pipelines.XicidailiPipeline': 300,
}结果
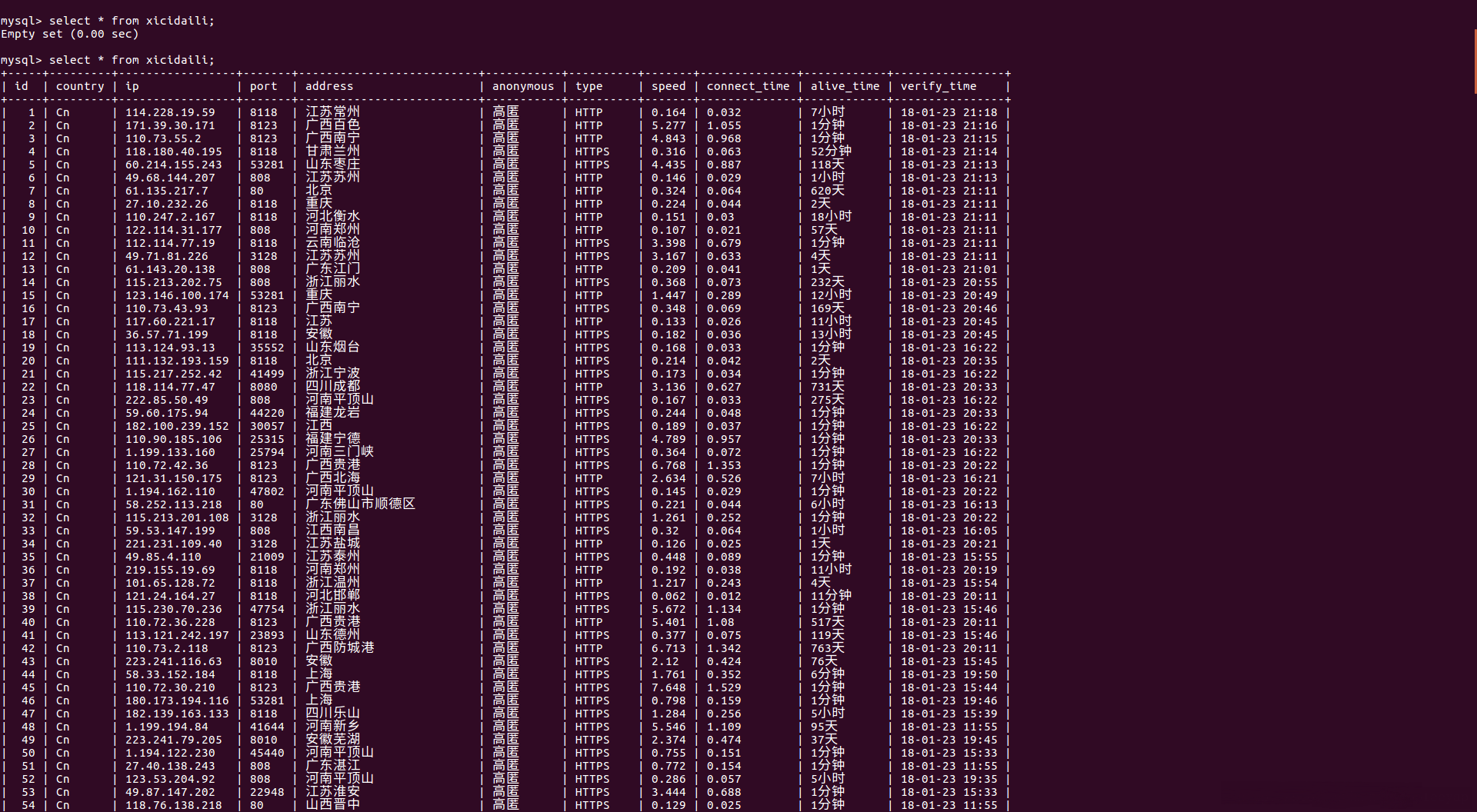
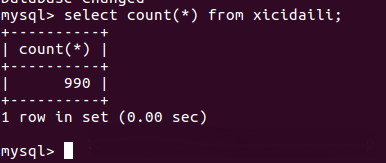
关于Scrapy框架爬取西刺代理网免费高匿代理的实现就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。