您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Puppeteer 介绍
Puppeteer 翻译是操纵木偶的人,利用这个工具,我们能做一个操纵页面的人。 Puppeteer 是一个 Nodejs 的库,支持调用 Chrome的API来操纵Web ,相比较 Selenium 或是 PhantomJs ,它最大的特点就是它的操作 Dom 可以完全在内存中进行模拟既在 V8 引擎中处理而不打开浏览器,而且关键是这个是Chrome团队在维护,会拥有更好的兼容性和前景。
Puppeteer 用处
Puppeteer 使用
安装 Puppeteer
由于封网,直接下载 Chromium 会失败,可以先阻止下载 Chromium 然后再手动下载它
# 安装命令 npm i puppeteer --save # 错误信息 ERROR: Failed to download Chromium r515411! Set "PUPPETEER_SKIP_CHROMIUM_DOWNLOAD" env variable to skip download. # 设置环境变量跳过下载 Chromium set PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=1 # 或者可以这样干,只下载模块而不build npm i --save puppeteer --ignore-scripts # 成功安装模块 + puppeteer@0.13.0 added 1 package in 1.77s
手动下载 Chromium,下载完后将压缩包解压,会有个 Chromium.app,将其放在你喜欢的目录下,例如 /Users/huqiyang/Documents/project/z/chromium/Chromium.app。正常安装包后 Chromium.app 会在 .local-chromium中
Tip:下载 Chromium 失败解决办法
更换国内Chromium源
PUPPETEER_DOWNLOAD_HOST=https://storage.googleapis.com.cnpmjs.org npm i puppeteer
或者用 cnpm 安装
npm install -g cnpm --registry=https://registry.npm.taobao.org cnpm i puppeteer
点击查阅 Puppeteer API
初试 Puppeteer,截个图吧
知识点
const puppeteer = require('puppeteer');
(async () => {
const browser = await (puppeteer.launch({
// 若是手动下载的chromium需要指定chromium地址, 默认引用地址为 /项目目录/node_modules/puppeteer/.local-chromium/
executablePath: '/Users/huqiyang/Documents/project/z/chromium/Chromium.app/Contents/MacOS/Chromium',
//设置超时时间
timeout: 15000,
//如果是访问https页面 此属性会忽略https错误
ignoreHTTPSErrors: true,
// 打开开发者工具, 当此值为true时, headless总为false
devtools: false,
// 关闭headless模式, 不会打开浏览器
headless: false
}));
const page = await browser.newPage();
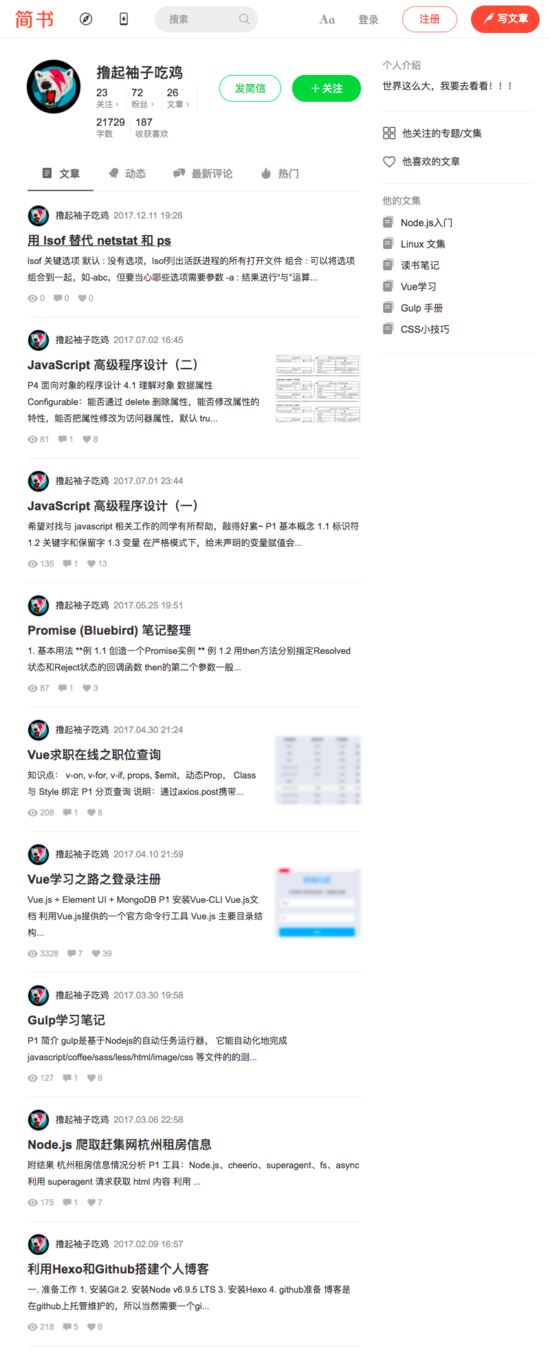
await page.goto('https://www.jianshu.com/u/40909ea33e50');
await page.screenshot({
path: 'jianshu.png',
type: 'png',
// quality: 100, 只对jpg有效
fullPage: true,
// 指定区域截图,clip和fullPage两者只能设置一个
// clip: {
// x: 0,
// y: 0,
// width: 1000,
// height: 40
// }
});
browser.close();
})();
运行结果
进阶,获取网易云音乐的歌词和评论
网易云音乐的API经过AES和RSA算法加密,需要携带加密的信息通过POST方式请求才能获取到数据。但 Puppeteer 出现后,这些都不重要了,只要它页面上显示了,通过 Puppeteer 都能获取到该元素。
知识点
const fs = require('fs');
const puppeteer = require('puppeteer');
(async () => {
const browser = await (puppeteer.launch({ executablePath: '/Users/huqiyang/Documents/project/z/chromium/Chromium.app/Contents/MacOS/Chromium', headless: false }));
const page = await browser.newPage();
// 进入页面
await page.goto('https://music.163.com/#');
// 点击搜索框拟人输入 鬼才会想起
const musicName = '鬼才会想';
await page.type('.txt.j-flag', musicName, {delay: 0});
// 回车
await page.keyboard.press('Enter');
// 获取歌曲列表的 iframe
await page.waitFor(2000);
let iframe = await page.frames().find(f => f.name() === 'contentFrame');
const SONG_LS_SELECTOR = await iframe.$('.srchsongst');
// 获取歌曲 鬼才会想起 的地址
const selectedSongHref = await iframe.evaluate(e => {
const songList = Array.from(e.childNodes);
const idx = songList.findIndex(v => v.childNodes[1].innerText.replace(/\s/g, '') === '鬼才会想起');
return songList[idx].childNodes[1].firstChild.firstChild.firstChild.href;
}, SONG_LS_SELECTOR);
// 进入歌曲页面
await page.goto(selectedSongHref);
// 获取歌曲页面嵌套的 iframe
await page.waitFor(2000);
iframe = await page.frames().find(f => f.name() === 'contentFrame');
// 点击 展开按钮
const unfoldButton = await iframe.$('#flag_ctrl');
await unfoldButton.click();
// 获取歌词
const LYRIC_SELECTOR = await iframe.$('#lyric-content');
const lyricCtn = await iframe.evaluate(e => {
return e.innerText;
}, LYRIC_SELECTOR);
console.log(lyricCtn);
// 截图
await page.screenshot({
path: '歌曲.png',
fullPage: true,
});
// 写入文件
let writerStream = fs.createWriteStream('歌词.txt');
writerStream.write(lyricCtn, 'UTF8');
writerStream.end();
// 获取评论数量
const commentCount = await iframe.$eval('.sub.s-fc3', e => e.innerText);
console.log(commentCount);
// 获取评论
const commentList = await iframe.$$eval('.itm', elements => {
const ctn = elements.map(v => {
return v.innerText.replace(/\s/g, '');
});
return ctn;
});
console.log(commentList);
})();
运行结果



高级爬虫
爬取SPA应用,并生成预渲染内容(即“SSR” 服务端渲染),通俗讲就是在页面上显示的内容我们都能获取到。下面我们就通过爬取 瓜子二手车直卖网 的车辆信息来认识它。
首先通过 axios 来试试
const axios = require('axios');
const useAxios = () => {
axios.get('https://www.guazi.com/hz/buy/')
.then(((result) => {
console.log(result.data);
}))
.catch((err) => {
console.log(err);
});
};
结果它返回给我这个玩意,这显然不是我要的内容

通过 Puppeteer 爬取
const fs = require('fs');
const puppeteer = require('puppeteer');
(async () => {
const browser = await (puppeteer.launch({ executablePath: '/Users/huqiyang/Documents/project/z/chromium/Chromium.app/Contents/MacOS/Chromium', headless: true }));
const page = await browser.newPage();
// 进入页面
await page.goto('https://www.guazi.com/hz/buy/');
// 获取页面标题
let title = await page.title();
console.log(title);
// 获取汽车品牌
const BRANDS_INFO_SELECTOR = '.dd-all.clearfix.js-brand.js-option-hid-info';
const brands = await page.evaluate(sel => {
const ulList = Array.from($(sel).find('ul li p a'));
const ctn = ulList.map(v => {
return v.innerText.replace(/\s/g, '');
});
return ctn;
}, BRANDS_INFO_SELECTOR);
console.log('汽车品牌: ', JSON.stringify(brands));
let writerStream = fs.createWriteStream('car_brands.json');
writerStream.write(JSON.stringify(brands, undefined, 2), 'UTF8');
writerStream.end();
// await bodyHandle.dispose();
// 获取车源列表
const CAR_LIST_SELECTOR = 'ul.carlist';
const carList = await page.evaluate((sel) => {
const catBoxs = Array.from($(sel).find('li a'));
const ctn = catBoxs.map(v => {
const title = $(v).find('h3.t').text();
const subTitle = $(v).find('div.t-i').text().split('|');
return {
title: title,
year: subTitle[0],
milemeter: subTitle[1]
};
});
return ctn;
}, CAR_LIST_SELECTOR);
console.log(`总共${carList.length}辆汽车数据: `, JSON.stringify(carList, undefined, 2));
// 将车辆信息写入文件
writerStream = fs.createWriteStream('car_info_list.json');
writerStream.write(JSON.stringify(carList, undefined, 2), 'UTF8');
writerStream.end();
browser.close();
})();
运行结果


以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。