您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
针对排序来说,order by 是我们使用非常频繁的关键字。结合之前我们对索引的了解再来看这篇文章会让我们深刻理解在排序的时候,是如何利用索引来达到少扫描表或者使用外部排序的。
先定义一个表辅助我们后面理解:
CREATE TABLE `t` ( `id` int(11) NOT NULL, `city` varchar(16) NOT NULL, `name` varchar(16) NOT NULL, `age` int(11) NOT NULL, `addr` varchar(128) DEFAULT NULL, PRIMARY KEY (`id`), KEY `city` (`city`) ) ENGINE=InnoDB;
这时我们写一条查询语句
select city,name,age from t where city='杭州' order by name limit 1000 ;
根据上面的表定义来看,city=xxx 可以使用到我们定义的一个索引。但是 order by name 明显我们没有索引,所以肯定需要先用索引查询到 city=xxx 然后再进行回表查询,最后再排序。
全字段排序
在 city 字段上面创建索引之后,我们使用执行计划来查看这个语句

可以看到有索引的情况下 我们这里还是使用了 "Using filesort" 表示需要排序,MySQL 会给每个线程分配一块内存用于排序 称为 sort_buffer。
我们在执行上面 select 语句的时候通常经历了这样一个过程
1. 初始化 sort_buffer, 确认放入 name, city, age 这三个字段。
2. 从索引 city 找到第一个满足 city='杭州'条件的主键 id。
3. 回表取到 name, city, age 三个字段值,存入 sort_buffer 中。
4. 从索引 city 取下一个主键 id 记录。
5. 重复 3-4 步骤,直到 city 不满足条件。
6. 对 sort_buffer 中的数据按照字段 name 做快速排序。
7. 排序结果取前 1000 行返回给客户端。
这被我们称为全字段排序。
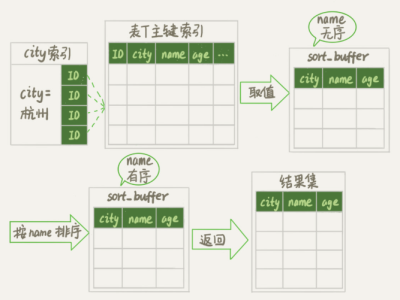
按照 name 排序这个动作即可能在内存中完成,也可以能使用外部文件排序。这取决于 sort_buffer_size 。sort_buffer_size 的默认值是1048576 byte 也就是 1M,如果要排序的数据量小于 1m 排序就在内存中完成,如果排序数据量大,内存放不下,则使用磁盘临时文件辅助排序。
Rowid 排序
如果单行很大,需要的字段全部放进 sort_buffer 效果就不会很好。
MySQL 中专门用于控制排序的行数据长度有个参数 max_length_for_sort_data 默认是1024,如果超过了这个值就会使用 rowid 排序。那么执行上面语句的流程就变成了
1. 初始化 sort_buffe 确定放入两个字段即 name 和 id 。
2. 从索引 city 找到第一个满足 city = '杭州'条件的主键 id。
3. 回表取 name 和 id 两个字段 存入 sort_buffer 中。
4. 取下个满足条件的记录 重复 2 3 步骤。
5. 对 sort_buffer 中的 name 进行排序。
6.遍历结果取前 1000 行。然后按照 id 再回一次表取的结果字段返回给客户端。
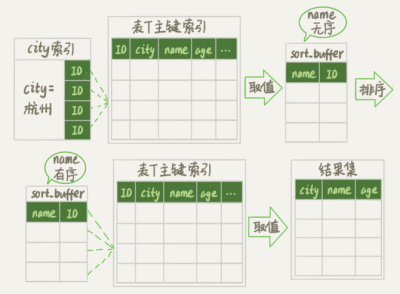
其实并不是所有 oder by 语句都需要进行上面的二次排序操作。从上面分析的执行过程,我们可以注意到。MySQL 之所以需要生成临时表,是因为要在临时表上做排序,是因为之前我们取得的是数据是无序的。
如果我们对刚才的索引修改一下,使得他是一个联合索引,那么第二个字段我们拿到的值其实就是有序的了。
联合索引满足这么一个条件,当我们的第一个索引字段是相等的情况下,第二个字段是有序的。
这能保证如果我们建立 (city,name) 索引的话,当我们在搜索 city='杭州'的情况的是时候找到的目标第二个字段 name 其实是有序的。所以查询过程可以简化成。
1. 从索引 (city, name) 找到第一个满足 city = '杭州'条件的主键 id 。
2. 回表取到 name city age 三个值返回。
3. 取下一个 id 。
4. 重复2 3 两个步骤直到 1000 条记录,或者是不满足 city = '杭州'条件结束。
也因为查询过程都可以使用到索引的有序性,所以不再需要排序也不需要时使用 sort buffer 了。
更近一步的优化就是之前说过的索引覆盖,将需要查询的字段也覆盖进索引中,再省掉回表的步骤,可以让整个查询的速度更快。
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。