您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“如何安装配置hadoop”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“如何安装配置hadoop”吧!
由于我的java系统是已经安装完毕,而且是1.8版本满足hadoop要求,只要将java home 指向安装的目录即可
先要取得java的安装目录
先取得java命令路径,命令路径头就是java的安装目录
ll了两次都是软链接,最后在/usr/lib...下找到了java的目录,目录我们只要复制到jre即可,多了少了都报错。
vim /etc/profile #配置java home
#------------------------
# properties jdk
#------------------------
export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64/jre
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib/dt.jar:${JAVA_HOME}/lib/tools.jar:${JRE_HOME}/lib
export PATH=${PATH}:${JAVA_HOME}/bin:${JRE_HOME}/binhttp://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
#下载地址
mkdir /hadoop/
#创建hadoop 文件夹,将上面的文件下载到该文件夹,并解压
ln -s hadoop-3.1.2 hadoop.soft
#创建个软连接文件
vim /etc/profile #配置 hadoop home
#---------------------------
# property hadoop
#------------------------
export HADOOP_HOME=/hadoop/hadoop.soft
export PATH=${PATH}:${HADOOP_HOME}/sbin:${HADOOP_HOME}/binsource /etc/profile
#重载下配置文件
hadoop version
#执行hadoop 验证命令,如果出现以下字符说明安装成功了
cd /hadoop/hadoop.soft/etc/hadoop #进入配置文件文件夹
需要修改的以下文件
slaves
hadoop-env.sh
yarn-en.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
1.修改slaves
vim slaves
Slave1 Slave2 #两个子节点
2.修改hadoop-env.sh,JAVA_HOME=$JAVA_HOME这一行,把它注释掉,另外增加一行,添加内容。export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64/jre
#添加java home的路径
3.修改yarn-env.sh,JAVA_HOME=$JAVA_HOME这一行,把它注释掉,另外增加一行,添加内容。export JAVA_HOME=/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.181-7.b13.el7.x86_64/jre
4.修改core-site.xml,在<configuration> </configuration>之间添加内容。
<property> <name>hadoop.tmp.dir</name> <value>/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://Master:9000</value> #这里填主机的host </property>
5.修改hdfs-site.xml,同样在<configuration></configuration>之间添加内容。
<property> <name>dfs.namenode.secondary.http-address</name> <value>Master:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/hadoop/dfs/date</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property>
6.修改mapred-site.xml文件,配置文件中没有这个文件,首先需要将mapred-site.xml.tmporary文件改名为mapred-site.xml
<property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>Master:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>Master:19888</value> </property>
7.修改yarn-site.xml
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> <value>Master</value> </property>
在把需要的文件夹创建下
cd /hadoop
mkdir -pv tmp
mkdir -pv dfs/{name,date}
在把整个文件夹传送给两个子节点,保证所有节点的文件文件路径都一样,java 和hadoop 的home也配置成一样,主节点怎么配子节点一样配
scp -r /hadoop Slave1:/ #将整个hadoop文件夹复制一份给节点1
scp -r /hadoop Slave2:/
四,格式化节点,启动hadoop
hdfs namenode -format #格式化节点
这一步,在配置完所有文件后,开启hdfs,star-dfs.sh之前。只使用一次,之后每次开启hadoop都不需要,格式化名称节点,如果没有格式化名称节点,就启动hadoop,start-dfs.sh,后面会出问题。
解决方法:
关闭hdfs,把tmp,logs文件删除,重新格式化namenode
stop-all.sh #关闭所有节点
rm -rf tmp
rm -rf logs
hdfs namenode -format
启动节点
su hadoop #切换到hadoop账号
start-all.sh #启动所有有节点
netstat -nltp #查看监听端口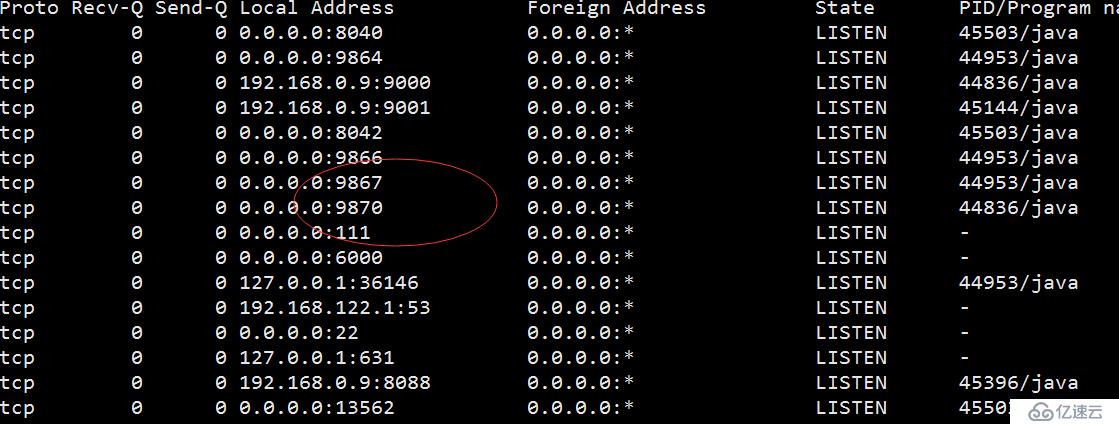
访问9870端口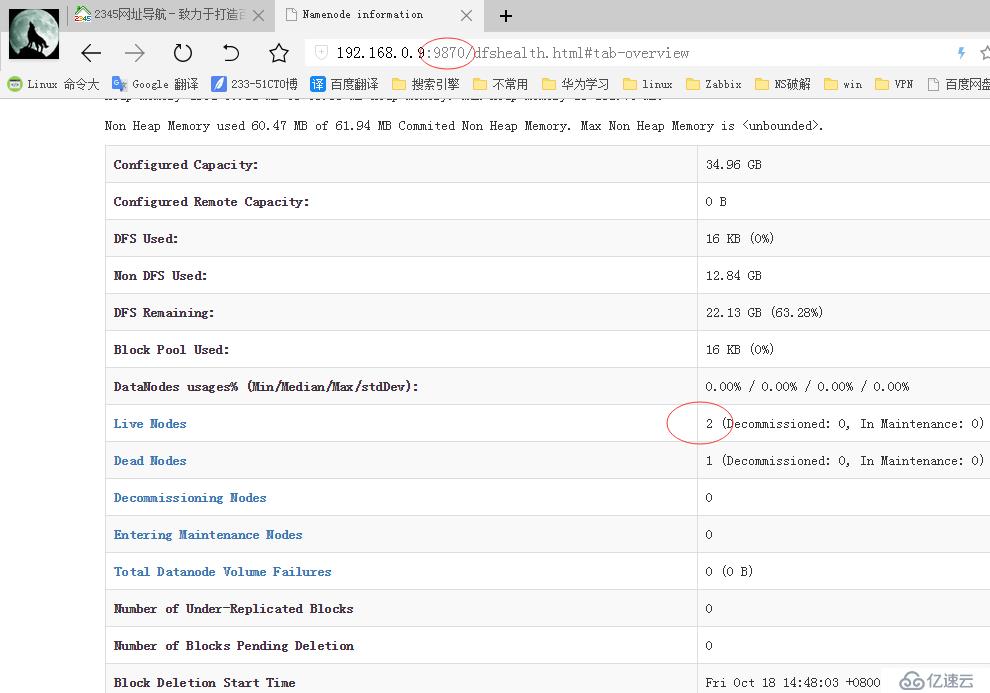
我这有两个节点在线,另一个我关闭测试的,如果花红圈的地方只有一个主节点的话
可以登录到子节点 运行以下命令,在子节点上启动
su hadoop
hadoop-daemon.sh start datanode #启动本机节点
hadoop fs -mkdir /666 新建文件夹
hdfs dfs -put test.txt /666 上传文件
hadoop fs -ls / 查看根目录
hadoop fs -rmr /666 删除666目录
上传一张图片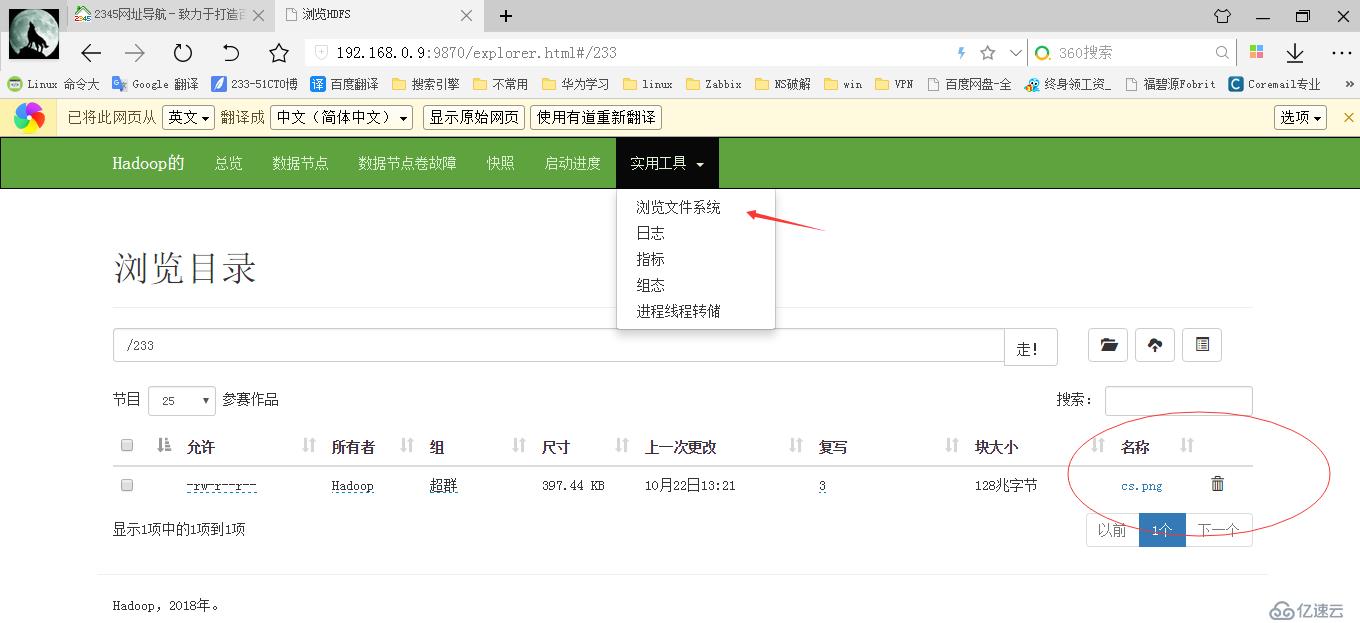
到浏览器上看看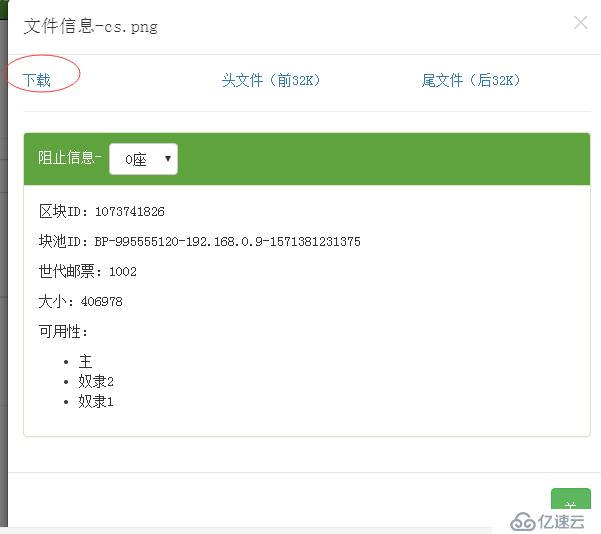
下载下来看看
感谢各位的阅读,以上就是“如何安装配置hadoop”的内容了,经过本文的学习后,相信大家对如何安装配置hadoop这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。