您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Python新手编写脚本处理数据,各种心酸各种语法查找,以此留念!
原始数据格式如下图所示:
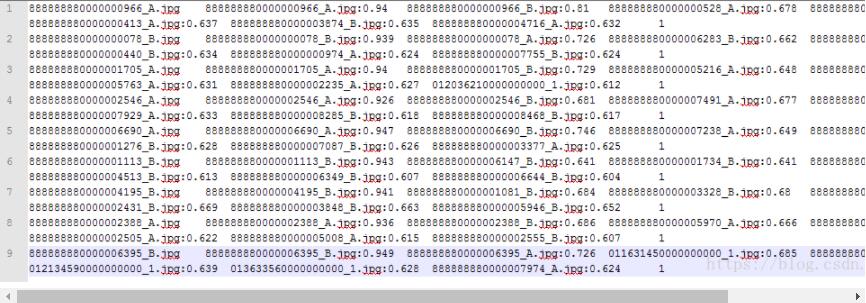
这里是一个人脸测试数据,其中每行第一个为测试图片编号,后面为Top 7图片编号及其对应的评分,即与测试图片的相似度度量结果。我们这里的目的是将每行Top 7对应的评分数据抽取出来,并且将评分第二的数值与一个阈值(这里是0.7)进行比较,超过阈值表示此次测试成功,结果为正样本,记为1,否则置0。并最终将其保存至另一个文本文件用于作为机器学习模型的训练样本数据。
Python脚本处理后的文件格式如下所示:
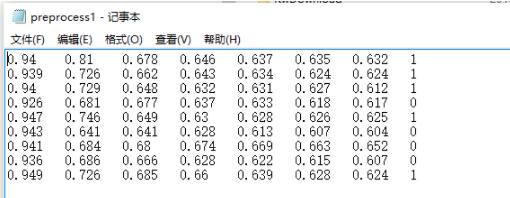
对应的Python代码如下所示,附有小白详细注释。
# -*- coding: cp936 -*-
import re
import linecache
filename = 'face_test_data.txt'
with open(filename, 'r') as f:
line = f.readline()
while line:
eachline = line.split()###按行读取文本文件
#print eachline 返回一个列表,以空格作为元素拆分标识
#print line 返回的是一整行数据,相当于一个字符串元素
count = len(eachline)#返回列表长度,即列表元素数目
n = 0
element = []#初始化空列表用于存储所需评分数据
while n < count:
elem_index = eachline[n:n+1] #类型为列表
#print elem_index, len(elem_index[0])
#print elem_index 返回类型为列表
if len(elem_index[0]) > 24:
element.append(elem_index[0][25:])
#element = [qiege(elem_index[n]) for elem_index in eachline]
n=n+1
#print element[1] #概率数值列表
if element[1] >= '0.7':
element.append(1)
#print '1'
else:
element.append(0)
#print '0'
#生成每行末尾有\t文件
'''
file = open('preprocess.txt', 'a')
for i in range(len(element)):
file.write(str(element[i])+'\t')
file.write('\n')
file.close()
'''
#生成每行末尾无\t文件,可直接用于np.loadtxt()读取文本生成矩阵数据
file = open('_preprocess.txt', 'a')
for i in range(len(element)-1):
file.write(str(element[i])+'\t')
file.write(str(element[-1])+'\n')
#file.write('\n')
file.close()
line = f.readline()
以上这篇Python 文本文件内容批量抽取实例就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持亿速云。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。