



您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
文件查看
cat
nl
tac
revcat常用选项
-E:显示行结束符$
-n:对显示出的每一行进行编号
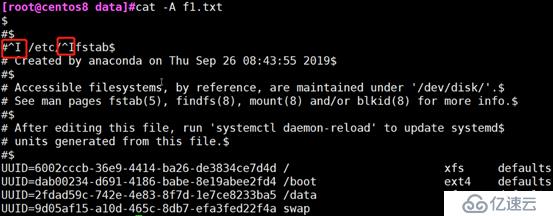
-A:显示所有控制符
-b:非空行编号
-s:压缩连续的空行成一行
cat -E :显示行结束符$ 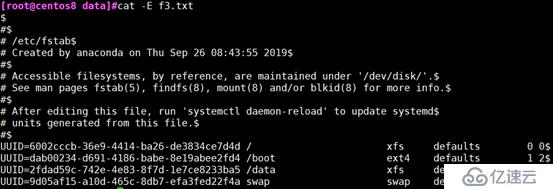
cat -A:显示所有控制符
cat -n :对显示出的每一行进行编号 ,包括空行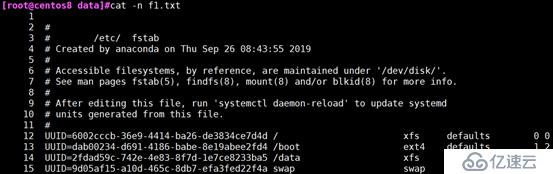
cat -b:非空行编号 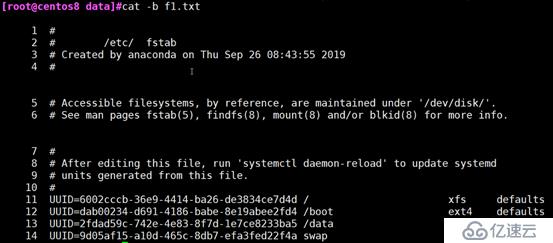
cat -s :压缩连续的空行成一行 (压缩相邻的空行成一行)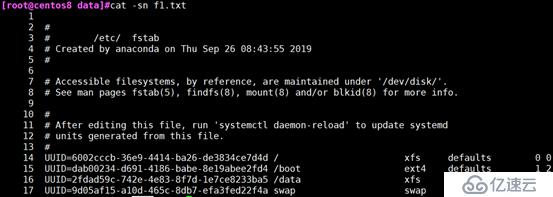
把文件按相反方向显示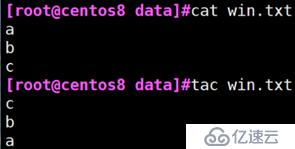
跟cat -b效果一样,编号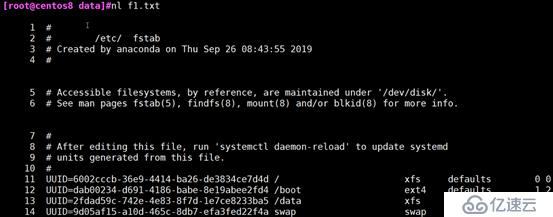
把文件同一行的内容反方向显示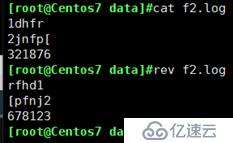
hexdump
od
xxd
more
less
more:分页查看文件

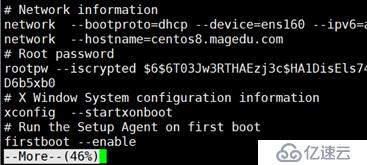
more -d: 显示翻页及退出提示
less:一页一页地查看文件或STDIN输出 
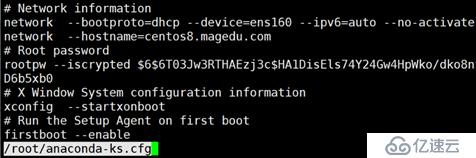
显示文本前或后行内容
head
tail
tailf
默认显示前十行
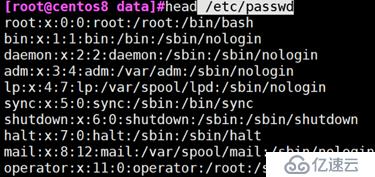
head -c :显示文本前x字节
例:取出/etc/passwd 文件的前十个字节
head -n(n可省略) :显示文本前x行内容
例:取出/etc/passwd文件的前十行内容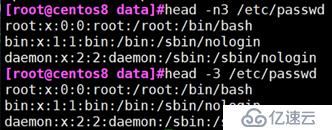
默认显示文本的后十行
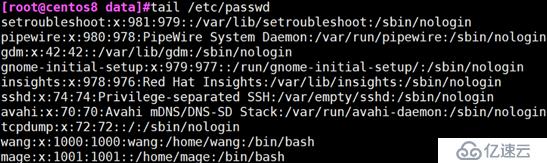
tail -n :显示文件后x行
tail -f :跟踪文件新加内容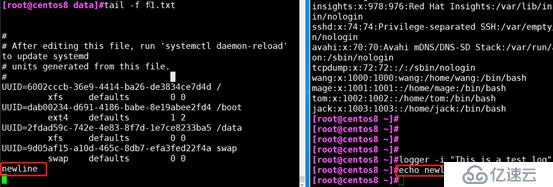
tail -F:跟踪文件名

找出ifconfig “网卡名” 命令结果中本机的IPv4地址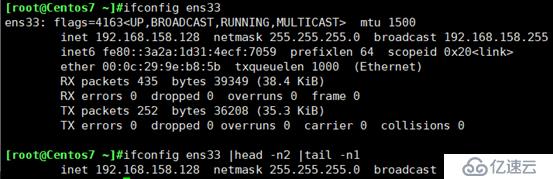
cut
按列抽取文本
-d DELIMITER: 指明分隔符,默认tab
-f FILEDS:
#: 第#个字段
#,#[,#]:离散的多个字段,例如1,3,6
#-#:连续的多个字段, 例如1-6
混合使用:1-3,7
-c 按字符切割
--output-delimiter=STRING指定输出分隔符
显示文件或STDIN数据的指定列
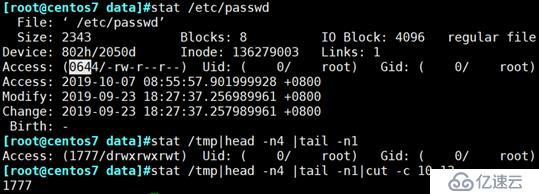
cut -d: -f1 /etc/passwd
cat /etc/passwd | cut -d: -f7
cut -c2-5 /usr/share/dict/words
cut -d -f 例:以冒号为分隔符,取出第1.3.4列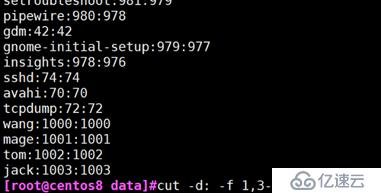
cut -c:按字符切割 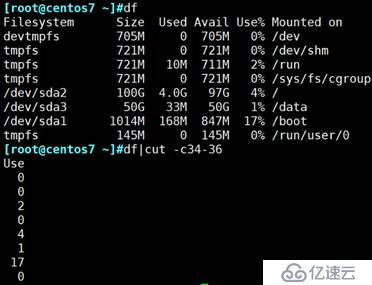
取出ip地址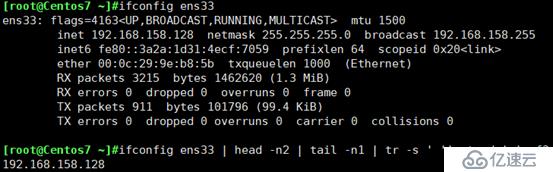
取出版本号
取出磁盘空间使用率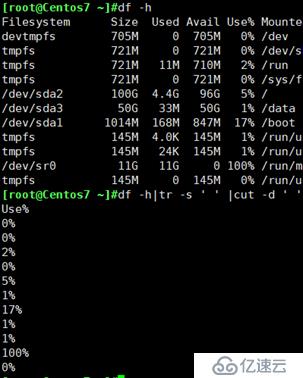
查出/tmp的权限,以数字方式显示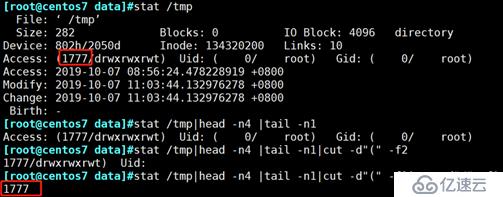
paste
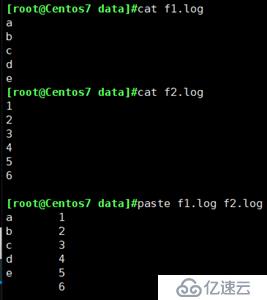
合并文件
-d 分隔符:指定分隔符,默认用TAB
-s : 所有行合成一行显示
paste -s:
例:把文件a/b.log文件合成一行显示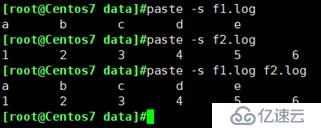
分析文本的工具
wc
文本数据统计
sort
整理文本
diff和patch
比较文件
.
wc
可用于统计文件的行总数、单词总数、字节总数和字符总数
可以对文件或STDIN中的数据统计
wc story.txt
39 237 1901 story.txt
行数 字数 字节数 常用选项
-l 只计数行数
-w 只计数单词总数
-c 只计数字节总数
-m 只计数字符总数
-L 显示文件中最长行的长度
wc -l: 只查看文件行数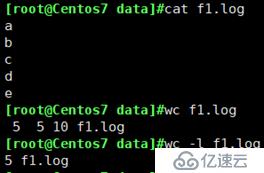
wc -w :只计文本单词总数
wc -L :挑出a.log文件最长的一行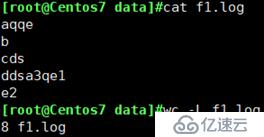
wc -m:只计字符总数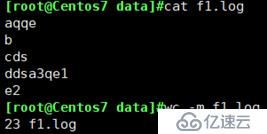
wc -c :只计字节总数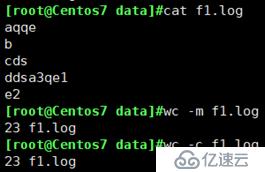
sort
文本排序
把整理过的文本显示在STDOUT,不改变原始文件
常用选项
-r 执行反方向(由上至下)整理
-R 随机排序
-n 执行按数字大小整理
-f 选项忽略(fold)字符串中的字符大小写
-u 选项(独特,unique)删除输出中的重复行
-t c 选项使用c做为字段界定符
-k # 选项按照使用c字符分隔的 # 列来整理能够使用多次
sort -nr :把文本数字按大到小进行排序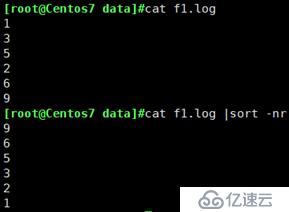
sort -R:随机排序
例: 随机排序1到55的数字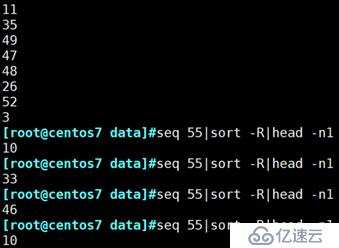
sort -u : 去掉重复行
例:删除a.log文件的重复行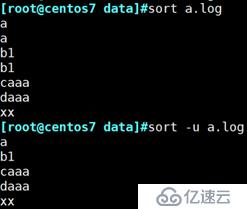
查出分区空间使用率的最大百分比值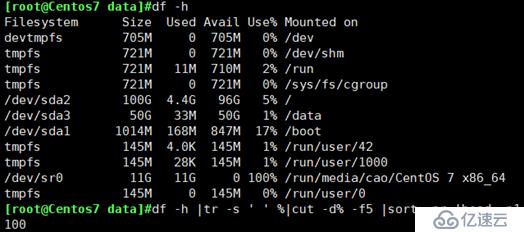
查出用户UID最大值的用户名、UID及shell类型 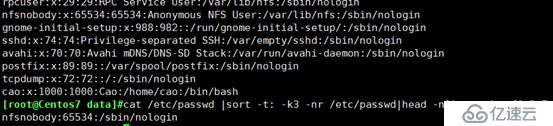
uniq
从输入中删除前后相接的重复的行
常用选项
-c: 显示每行重复出现的次数
-d: 仅显示重复过的行
-u: 仅显示不曾重复的行
注:连续且完全相同方为重复
常和sort命令一起使用
sort userlist.txt | uniq -c
例:查看a.log文件不显示相邻的重复行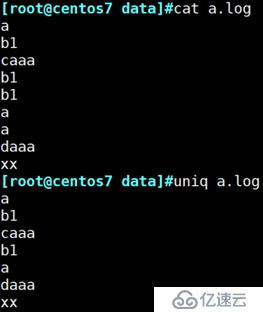
uniq -c :显示每行重复出现次数
例:查看a.log文件每行重复出现的次数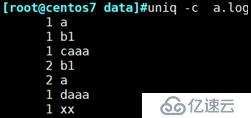
uniq -d : 只显示相邻的重复行
例:查看a.log文件重复过的行
uniq -u :只显示不重复行
例:查看文件a.log文件没有重复过的行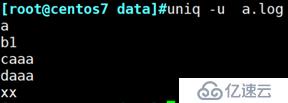
统计访问过日志的IP地址,并取出访问次数最多的前三个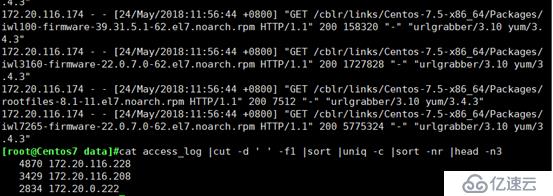
diff
比较两个文件之间的区别
-u :命令的输出被保存在一种叫做“补丁”的文件中 使用 -u 选项来输出“统一的(unified)”diff格式文件,最适用于补丁文件
.
patch
-b:复制在其它文件中进行的改变(要谨慎使用) 适用 -b 选项来自动备份改变了的文件
.
diff -u foo.conf foo2.conf > foo.patch
patch -b foo.conf foo.patch
例:查看文件a.log和aa.log文件的不同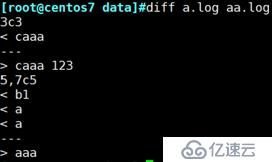
diff -u :显示的更加详细
例: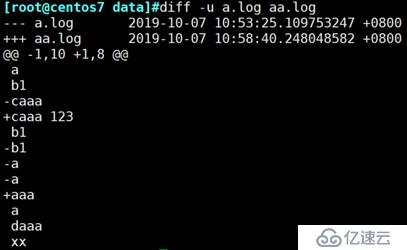
文本处理三剑客sed
grep:文本过滤(模式:pattern)工具
sed:stream editor,文本编辑工具
awk:Linux上的实现gawk,文本报告生成器
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检 查;打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件
常用选项--color=auto: 对匹配到的文本着色显示
-m # 匹配#次后停止
-v 显示不被pattern匹配到的行
-i 忽略字符大小写
-n 显示匹配的行号
-c 统计匹配的行数
-o 仅显示匹配到的字符串
-q 静默模式,不输出任何信息
-A # after, 后#行
-B # before, 前#行
-C # context, 前后各#行
-e 实现多个选项间的逻辑or关系 grep –e ‘cat ’ -e ‘dog’ file
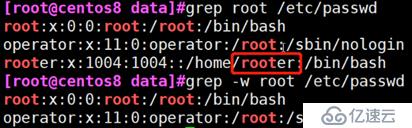
-w 匹配整个单词
-E 使用ERE
-F 相当于fgrep,不支持正则表达式
-f file 根据模式文件处理
从/etc/passwd中找出包含root的行

grep -m
例: 过滤/etc/passwd中出现的前两次bash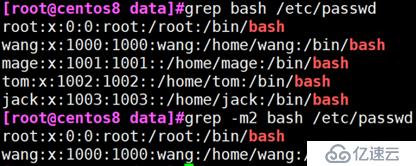
grep -v
例: 显示/etc/passwd文件中不匹配到bash的行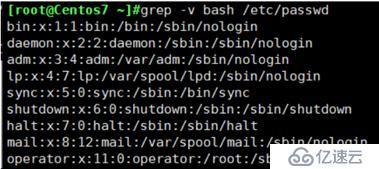
grep -i :忽略大小写

grep -n
例:显示/etc/passwd文件中匹配到root在文件中的行数

grep -c
例:统计/etc/passwd文件中匹配到root的行数

grep -o
例:只显示/etc/passwd文件中匹配到的bash字符串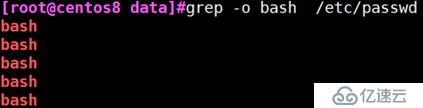
grep -q
例: 不输出任何信息

grep -A
例:显示找到root行的后三行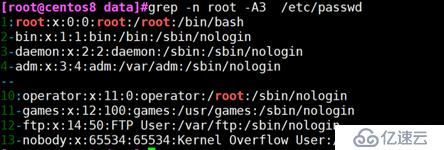
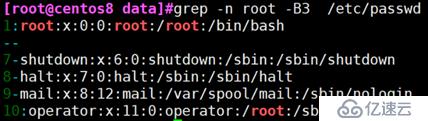
grep -B
例: 显示找到root行的前三行
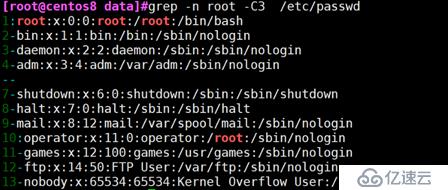
grep -C
例:显示找到root行的前三行和后三行
grep -e
例 :显示/etc/passwd文件中匹配到root或bash的行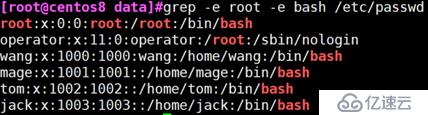
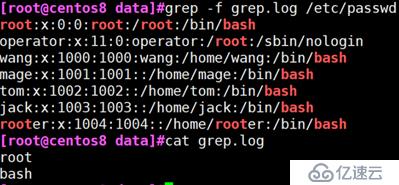
grep -f
例:满足greo.log文件中任意一行的都显示出来
例: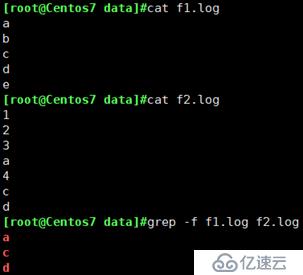
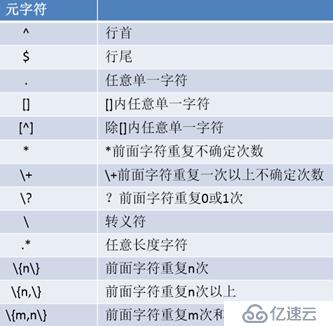
正则表达式
由一类特殊字符及文本字符所编写的模式, 其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能
分两类基本正则表达式:BRE,grep,vim
扩展正则表达式:ERE,grep -E, egrep,nginx
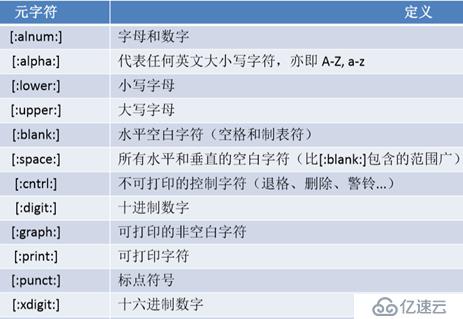

取出分区利用率最大的值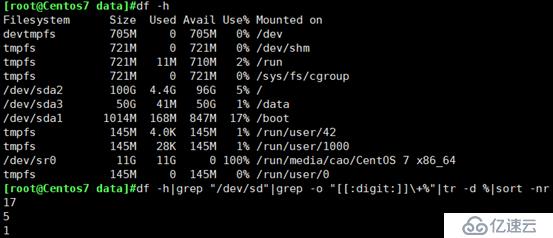
例

例:搜索以bash结尾的行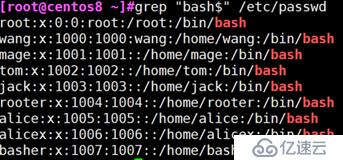
egrep及扩展的正则表达式
egrep = grep -E
扩展正则表达式的元字符:
字符匹配:
. 任意单个字符 [] 指定范围的字符 [^] 不在指定范围的字符
次数匹配:* 匹配前面字符任意次
? 0或1次
- 1次或多次
{m} 匹配m次
{m,n} 至少m,至多n次
.
位置锚定:
^ 行首
$ 行尾
\<, \b 语首
\>, \b 语尾
.
分组:
()
后向引用:\1, \2, ...
.
或者:
a|b a或b
C|cat C或cat
(C|c)at Cat或cat
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。