您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了Python实现爬虫的方法有哪些,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
首页外观如下:
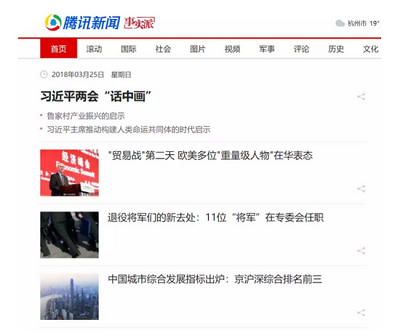
比如说我们想抓取每个新闻的标题和链接,并将其组合为一个字典的结构打印出来。首先查看 HTML 源码确定新闻标题信息组织形式。
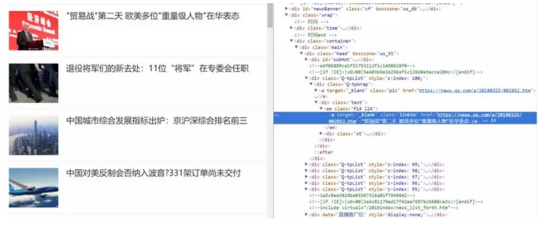
可以目标信息存在于 em 标签下 a 标签内的文本和 href 属性中。可直接利用 requests 库构造请求,并用 BeautifulSoup 或者 lxml 进行解析。
方式一: requests + BeautifulSoup + select css选择器
# select method
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'http://news.qq.com/'
Soup = BeautifulSoup(requests.get(url=url, headers=headers).text.encode("utf-8"), 'lxml')
em = Soup.select('em[class="f14 l24"] a')
for i in em:
title = i.get_text()
link = i['href']
print({'标题': title,
'链接': link
})很常规的处理方式,抓取效果如下:

方式二: requests + BeautifulSoup + find_all 进行信息提取
# find_all method
import requests
from bs4 import BeautifulSoup
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'http://news.qq.com/'
Soup = BeautifulSoup(requests.get(url=url, headers=headers).text.encode("utf-8"), 'lxml')
em = Soup.find_all('em', attrs={'class': 'f14 l24'})for i in em:
title = i.a.get_text()
link = i.a['href']
print({'标题': title,
'链接': link
})同样是 requests + BeautifulSoup 的爬虫组合,但在信息提取上采用了 find_all 的方式。效果如下:

方式三: requests + lxml/etree + xpath 表达式
# lxml/etree method
import requests
from lxml import etree
headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'http://news.qq.com/'
html = requests.get(url = url, headers = headers)
con = etree.HTML(html.text)
title = con.xpath('//em[@class="f14 l24"]/a/text()')
link = con.xpath('//em[@class="f14 l24"]/a/@href')
for i in zip(title, link):
print({'标题': i[0],
'链接': i[1]
})使用 lxml 库下的 etree 模块进行解析,然后使用 xpath 表达式进行信息提取,效率要略高于 BeautifulSoup + select 方法。这里对两个列表的组合采用了 zip 方法。python学习交流群:125240963效果如下:

方式四: requests + lxml/html/fromstring + xpath 表达式
# lxml/html/fromstring method
import requests
import lxml.html as HTML
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.119 Safari/537.36'}
url = 'http://news.qq.com/'
con = HTML.fromstring(requests.get(url = url, headers = headers).text)
title = con.xpath('//em[@class="f14 l24"]/a/text()')
link = con.xpath('//em[@class="f14 l24"]/a/@href')
for i in zip(title, link):
print({'标题': i[0],'链接': i[1]
})跟方法三类似,只是在解析上使用了 lxml 库下的 html.fromstring 模块。抓取效果如下:

感谢你能够认真阅读完这篇文章,希望小编分享的“Python实现爬虫的方法有哪些”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。