您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
正则表达式又称正规表达式、常规表达式。正则表达式是由普通字符与元字符组成的文字模式。模式用于描述在搜索文本时要匹配的一个或多个字符串。正则表达式一般用于脚本编程与文本编辑器中。很多文本处理器与程序设计语言均支持正则表达式,在Linux 系统中常见的文本处理器如grep、egrep、sed、awk。正则表达式具备很强大的文本匹配功能,能够在文本海洋中快速高效地处理文本。
正则表达式对于系统管理员来说是非常重要的,系统运行过程中会产生大量的信息,这些信息有些是非常重要的,有些则仅是告知的信息。身为系统管理员如果直接看这么多的信息数据,无法快速定位到重要的信息,如“用户账号登录失败”“服务启动失败”等信息。这时可以通过正则表达式快速提取“有问题”的信息。如此一来,可以将运维工作变得更加简单、方便。
正则表达式的字符串表达方法根据不同的严谨程度与功能分为基本正则表达式与扩展正则表达式。基础正则表达式是常用的正则表达式的最基础的部分。
1.查找特定字符
-n 表示显示行号
-i 表示不区分大小写
(符合匹配标准的字符,字体颜色会变为红色)
(1)查找出特定字符“the” 所在位置
[root@localhost ~]# grep -n 'the' /opt/httpd.conf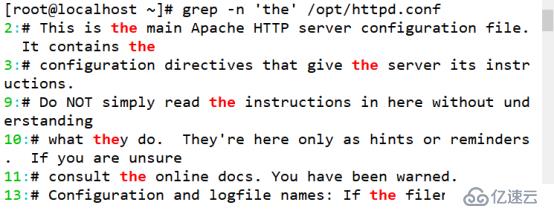
(2)反向查找不包含“the”字符的行
[root@localhost~]# grep -vn 'the' /opt/httpd.conf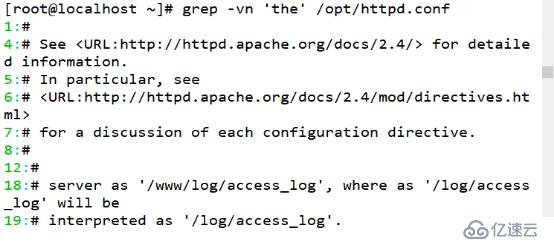
2.利用中括号“[ ]”来查找集合字符
(1)查找“shirt”与“short”这两个字符串,“[]”中无论有几个字符,都仅代表一个字符,也就是说“[io]”表示匹配“i”或者“o”。
[root@localhost ~]# grep -n 'sh[io]rt' /opt/httpd.conf
(2)查找重复单个单词字符
[root@localhost ~]# grep -n 'oo' /opt/httpd.conf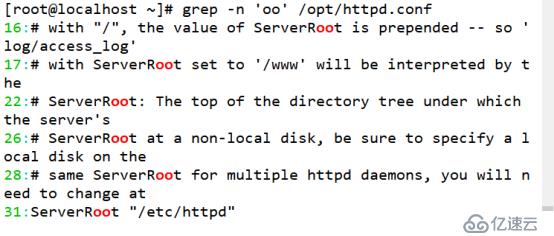
(3)通过集合字符的反向选择“[^]”来实现查找“oo”前面不是“R”的字符串
[root@localhost ~]# grep -n '[^R]oo' /opt/httpd.conf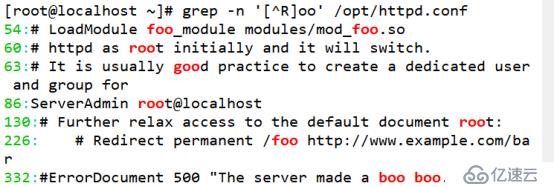
(4)查找“oo”前面存在小写或大写字母,其中“a-z”表示小写字母,“A-Z”表示大写字母
[root@localhost ~]# grep -n '[^a-z]oo' /opt/httpd.conf //小写字母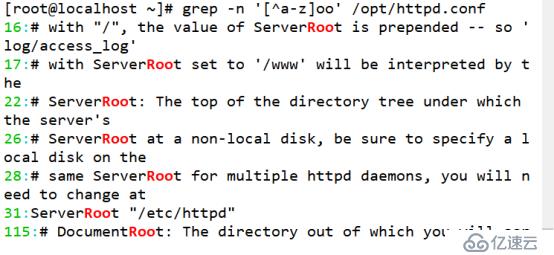
[root@localhost ~]# grep -n '[^A-Z]oo' /opt/httpd.conf //大写字母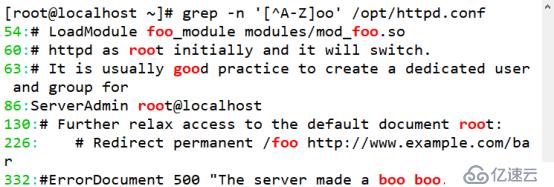
(5)查找包含数字的行
[root@localhost ~]# grep -n '[0-9]' /opt/httpd.conf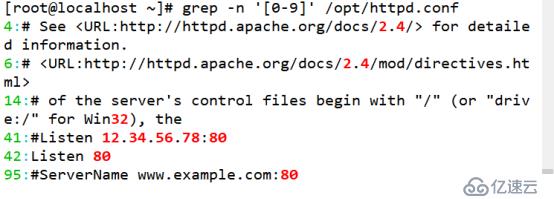
3.查找行首“^”与行尾字符“$”
(1)查找以root开头的行
[root@localhost ~]# grep -n '^root' /etc/passwd
(2)查找以bash结尾的行
[root@localhost ~]# grep -n 'bash$' /etc/passwd
(3)查询以小写或大写字母开头的行
小写字母开头的行可以通过“^[a-z]”规则来过滤,查询大写字母开头的行使用“^[A-Z]”规则,查询不以字母开头的行使用“^[^a-zA-Z]”规则。
[root@localhost ~]# grep -n '^[a-z]' /etc/passwd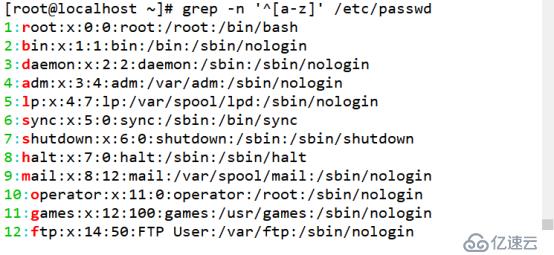
(4)查询以问号?结尾的行,需要使用转义字符“\”将具有特 殊意义的字符转化成普通字符
[root@localhost ~]# grep -n '\?$' /opt/httpd.conf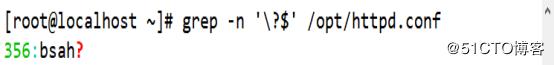
(5)查询一空白行,使用^$
[root@localhost ~]# grep -n '^$' /opt/httpd.conf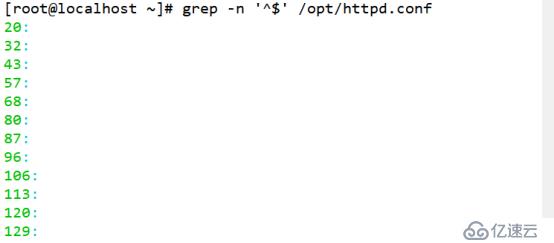
4.查找任意一个字符“.”与重复字符“*”
(1)查找以w开头d结尾的字符串
[root@localhost ~]# grep -n 'w..d' /opt/httpd.conf
(2)查询包含至少两个 o 以上的字符串,可用星号元字符. 代表的是重复零个或多个前面的单字符,所以凡是包含 o、oo、ooo、ooo,等的资料都符合标准。
[root@localhost ~]# grep -n 'ooo*' test.txt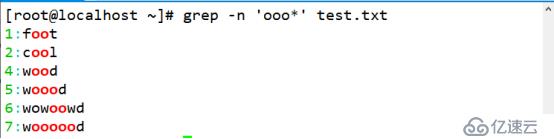
(3)查询以 w 开头 d 结尾,其中间包含至少一个 o 的字符串
[root@localhost ~]# grep -n 'woo*d' test.txt
(4)查询以 w 开头 d 结尾,中间的字符可有可无的字符串。
[root@localhost ~]# grep -n 'w.*d' test.txt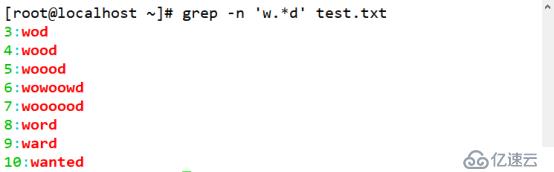
(5)查询任意数字所在行
[root@localhost ~]# grep -n '[0-9][0-9]*' /opt/httpd.conf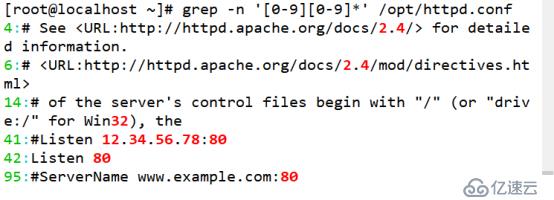
5.查找连续字符范围{ }
在使用“{}”字符时,需要利用转义字符“\”,将“{}”字符转换成普通字符。
(1)查询两个o的字符
[root@localhost ~]# grep -n 'o\{2\}' test.txt
(2)查询以 w 开头以 d 结尾,中间包含 2~3个 o 的字符串
root@localhost ~]# grep -n 'wo\{2,\}d' test.txt
(3)查询以 w 开头以 d 结尾,中间包含 2 以上 o 的字符串
[root@localhost ~]# grep -n 'wo\{2,\}d' test.txt
| 元字符 | 作用 |
|---|---|
| ^ | 匹配输入字符串的开始位置。在方括号表达式中使用,表示不包含该字符集合。 |
| $ | 匹配输入字符串的结尾位置。 |
| . | 匹配除“\r\n”之外的任何单个字符 |
| \ | 将下一个字符标记为特殊字符、原义字符、向后引用、八进制转义符。 |
| * | 匹配前面的子表达式零次或多次。要匹配“”字符,请使用“\” |
| [ ] | 字符集合。匹配所包含的任意一个字符。例如,“[abc]”可以匹配“plain”中的“a” |
| ^ ] | 赋值字符集合。匹配未包含的一个任意字符。 |
| [n1-n2] | 字符范围。匹配指定范围内的任意一个字符。 |
| {n} | n 是一个非负整数,匹配确定的 n 次 |
| {n,} | n 是一个非负整数,至少匹配 n 次。 |
| n,m | m 和n 均为非负整数,其中 n<=m,最少匹配 n 次且最多匹配 m 次 |
通常情况下会使用基础正则表达式就已经足够了,但有时为了简化整个指令,需要使用范围更广的扩展正则表达式。此外grep 命令仅支持基础正则表达式,如果使用扩展正则表达式,需要使用 egrep 命令。egrep 命令与 grep 命令的用法基本相似。egrep 命令是一个搜索文件获得模式,使用该命令可以搜索文件中的任意字符串和符号,也可以搜索一个或多个文件的字符串,一个提示符可以是单个字符、一个字符串、一个字或一个句子。
| 元字符 | 作用 |
|---|---|
| + | 重复一个或者一个以上的前一个字符 |
| ? | 零个或者一个的前一个字符 |
| l | 使用或者(or)的方式找出多个字符 |
| () | 查找“组”字符串 |
| ()+ | 辨别多个重复的组 |
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。