жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іpythonдёӯsocketзҪ‘з»ңзј–зЁӢд№ӢзІҳеҢ…зҡ„зӨәдҫӢеҲҶжһҗзҡ„еҶ…е®№гҖӮе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢдёҖиө·и·ҹйҡҸе°Ҹзј–иҝҮжқҘзңӢзңӢеҗ§гҖӮ
дёҖпјҢзІҳеҢ…й—®йўҳиҜҰжғ…
1пјҢеҸӘжңүTCPжңүзІҳеҢ…зҺ°иұЎпјҢUDPж°ёиҝңдёҚдјҡзІҳеҢ…
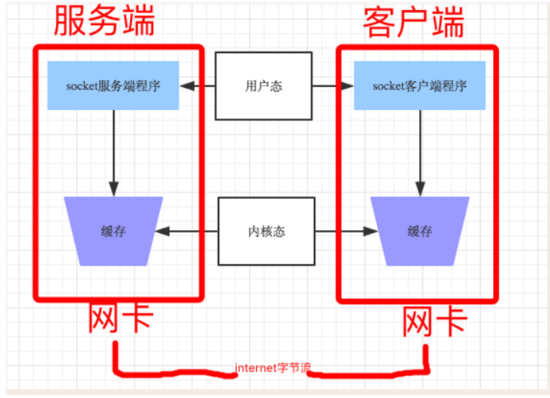
дҪ зҡ„зЁӢеәҸе®һйҷ…дёҠж— жқғзӣҙжҺҘж“ҚдҪңзҪ‘еҚЎзҡ„пјҢдҪ ж“ҚдҪңзҪ‘еҚЎйғҪжҳҜйҖҡиҝҮж“ҚдҪңзі»з»ҹз»ҷз”ЁжҲ·зЁӢеәҸжҡҙйңІеҮәжқҘзҡ„жҺҘеҸЈпјҢйӮЈжҜҸж¬ЎдҪ зҡ„зЁӢеәҸиҰҒз»ҷиҝңзЁӢеҸ‘ж•°жҚ®ж—¶пјҢе…¶е®һжҳҜе…ҲжҠҠж•°жҚ®д»Һз”ЁжҲ·жҖҒcopyеҲ°еҶ…ж ёжҖҒпјҢиҝҷж ·зҡ„ж“ҚдҪңжҳҜиҖ—иө„жәҗе’Ңж—¶й—ҙзҡ„пјҢйў‘з№Ғзҡ„еңЁеҶ…ж ёжҖҒе’Ңз”ЁжҲ·жҖҒд№ӢеүҚдәӨжҚўж•°жҚ®еҠҝеҝ…дјҡеҜјиҮҙеҸ‘йҖҒж•ҲзҺҮйҷҚдҪҺпјҢ еӣ жӯӨsocket дёәжҸҗй«ҳдј иҫ“ж•ҲзҺҮпјҢеҸ‘йҖҒж–№еҫҖеҫҖиҰҒ收йӣҶеҲ°и¶іеӨҹеӨҡзҡ„ж•°жҚ®еҗҺжүҚеҸ‘йҖҒдёҖж¬Ўж•°жҚ®з»ҷеҜ№ж–№гҖӮиӢҘиҝһз»ӯеҮ ж¬ЎйңҖиҰҒsendзҡ„ж•°жҚ®йғҪеҫҲе°‘пјҢйҖҡеёёTCP socket дјҡж №жҚ®дјҳеҢ–з®—жі•жҠҠиҝҷдәӣж•°жҚ®еҗҲжҲҗдёҖдёӘTCPж®өеҗҺдёҖж¬ЎеҸ‘йҖҒеҮәеҺ»пјҢиҝҷж ·жҺҘ收方е°ұ收еҲ°дәҶзІҳеҢ…ж•°жҚ®гҖӮ
2пјҢйҰ–е…ҲйңҖиҰҒжҺҢжҸЎдёҖдёӘsocket收еҸ‘ж¶ҲжҒҜзҡ„еҺҹзҗҶ
еҸ‘йҖҒз«ҜеҸҜд»ҘжҳҜ1kпјҢ1kзҡ„еҸ‘йҖҒж•°жҚ®иҖҢжҺҘеҸ—з«Ҝзҡ„еә”з”ЁзЁӢеәҸеҸҜд»Ҙ2kпјҢ2kзҡ„жҸҗеҸ–ж•°жҚ®пјҢеҪ“然д№ҹжңүеҸҜиғҪжҳҜ3kжҲ–иҖ…еӨҡkжҸҗеҸ–ж•°жҚ®пјҢд№ҹе°ұжҳҜиҜҙпјҢеә”з”ЁзЁӢеәҸжҳҜдёҚеҸҜи§Ғзҡ„пјҢеӣ жӯӨTCPеҚҸи®®жҳҜйқўжқҘйӮЈдёӘжөҒзҡ„еҚҸи®®пјҢиҝҷд№ҹжҳҜе®№жҳ“еҮәзҺ°зІҳеҢ…зҡ„еҺҹеӣ иҖҢUDPжҳҜйқўеҗ‘ж— иҝһжҺҘзҡ„еҚҸи®®пјҢжҜҸдёӘUDPж®өйғҪжҳҜдёҖжқЎж¶ҲжҒҜпјҢеә”з”ЁзЁӢеәҸеҝ…йЎ»д»Ҙж¶ҲжҒҜдёәеҚ•дҪҚжҸҗеҸ–ж•°жҚ®пјҢдёҚиғҪдёҖж¬ЎжҸҗеҸ–д»»дёҖеӯ—иҠӮзҡ„ж•°жҚ®пјҢиҝҷдёҖзӮ№е’ҢTCPжҳҜеҫҲеҗҢзҡ„гҖӮжҖҺж ·е®ҡд№үж¶ҲжҒҜе‘ўпјҹи®ӨдёәеҜ№ж–№дёҖж¬ЎжҖ§write/sendзҡ„ж•°жҚ®дёәдёҖдёӘж¶ҲжҒҜпјҢйңҖиҰҒе‘Ҫзҡ„жҳҜеҪ“еҜ№ж–№sendдёҖжқЎдҝЎжҒҜзҡ„ж—¶еҖҷпјҢж— и®әйјҺеҹҺжҖҺд№Ҳж ·еҲҶж®өеҲҶзүҮпјҢTCPеҚҸи®®еұӮдјҡжҠҠжһ„жҲҗж•ҙжқЎж¶ҲжҒҜзҡ„ж•°жҚ®ж®өжҺ’еәҸе®ҢжҲҗеҗҺжүҚе‘ҲзҺ°еңЁеҶ…ж ёзј“еҶІеҢәгҖӮ
дҫӢеҰӮеҹәдәҺTCPзҡ„еҘ—жҺҘеӯ—е®ўжҲ·з«ҜеҫҖжңҚеҠЎеҷЁз«ҜдёҠдј ж–Ү件пјҢеҸ‘йҖҒж—¶ж–Ү件еҶ…е®№жҳҜжҢүз…§дёҖж®өдёҖж®өзҡ„еӯ—иҠӮжөҒеҸ‘йҖҒзҡ„пјҢеңЁжҺҘ收方зңӢжқҘжӣҙз¬ЁдёҚзҹҘйҒ“ж–Ү件зҡ„еӯ—иҠӮжөҒд»ҺдҪ•еҲқејҖе§ӢпјҢеңЁдҪ•еӨ„з»“жқҹгҖӮ
3пјҢзІҳеҢ…зҡ„еҺҹеӣ
3-1 зӣҙжҺҘеҺҹеӣ
жүҖи°“зІҳеҢ…й—®йўҳдё»иҰҒиҝҳжҳҜеӣ дёәжҺҘ收方дёҚзҹҘйҒ“ж¶ҲжҒҜд№Ӣй—ҙзҡ„з•ҢйҷҗпјҢдёҚзҹҘйҒ“дёҖж¬ЎжҖ§жҸҗеҸ–еӨҡе°‘еӯ—иҠӮзҡ„ж•°жҚ®жүҖйҖ жҲҗзҡ„
3-2 ж №жң¬еҺҹеӣ
еҸ‘йҖҒж–№еј•иө·зҡ„зІҳеҢ…жҳҜз”ұTCPеҚҸи®®жң¬иә«йҖ жҲҗзҡ„пјҢTCPдёәжҸҗй«ҳдј иҫ“ж•ҲзҺҮпјҢеҸ‘йҖҒж–№еҫҖеҫҖиҰҒ收йӣҶеҲ°и¶іеӨҹеӨҡзҡ„ж•°жҚ®еҗҺжүҚеҸ‘йҖҒдёҖдёӘTCPж®өгҖӮиӢҘиҝһз»ӯеҮ ж¬ЎйңҖиҰҒsendзҡ„ж•°жҚ®йғҪеҫҲе°‘пјҢйҖҡеёёTCPдјҡж №жҚ® дјҳеҢ–з®—жі• жҠҠиҝҷдәӣж•°жҚ®еҗҲжҲҗдёҖдёӘTCPж®өеҗҺдёҖж¬ЎеҸ‘йҖҒеҮәеҺ»пјҢиҝҷж ·жҺҘ收方е°ұ收еҲ°дәҶзІҳеҢ…ж•°жҚ®гҖӮ
3-3 жҖ»з»“
TCPпјҲtransport control protocolпјҢдј иҫ“жҺ§еҲ¶еҚҸи®®пјүжҳҜйқўеҗ‘иҝһжҺҘзҡ„пјҢйқўеҗ‘жөҒзҡ„пјҢжҸҗдҫӣй«ҳеҸҜйқ жҖ§жңҚеҠЎгҖӮ收еҸ‘дёӨз«ҜпјҲе®ўжҲ·з«Ҝе’ҢжңҚеҠЎеҷЁз«ҜпјүйғҪиҰҒжңүдёҖдёҖжҲҗеҜ№зҡ„socketпјҢеӣ жӯӨпјҢеҸ‘йҖҒз«ҜдёәдәҶе°ҶеӨҡдёӘеҸ‘еҫҖжҺҘ收з«Ҝзҡ„еҢ…пјҢжӣҙжңүж•Ҳзҡ„еҸ‘еҲ°еҜ№ж–№пјҢдҪҝз”ЁдәҶдјҳеҢ–ж–№жі•пјҲNagleз®—жі•пјүпјҢе°ҶеӨҡж¬Ўй—ҙйҡ”иҫғе°Ҹдё”ж•°жҚ®йҮҸе°Ҹзҡ„ж•°жҚ®пјҢеҗҲ并жҲҗдёҖдёӘеӨ§зҡ„ж•°жҚ®еқ—пјҢ然еҗҺиҝӣиЎҢе°ҒеҢ…гҖӮиҝҷж ·пјҢжҺҘ收з«ҜпјҢе°ұйҡҫдәҺеҲҶиҫЁеҮәжқҘдәҶпјҢеҝ…йЎ»жҸҗдҫӣ科еӯҰзҡ„жӢҶеҢ…жңәеҲ¶гҖӮ еҚійқўеҗ‘жөҒзҡ„йҖҡдҝЎжҳҜж— ж¶ҲжҒҜдҝқжҠӨиҫ№з•Ңзҡ„гҖӮ
UDPпјҲuser datagram protocolпјҢз”ЁжҲ·ж•°жҚ®жҠҘеҚҸи®®пјүжҳҜж— иҝһжҺҘзҡ„пјҢйқўеҗ‘ж¶ҲжҒҜзҡ„пјҢжҸҗдҫӣй«ҳж•ҲзҺҮжңҚеҠЎгҖӮдёҚдјҡдҪҝз”Ёеқ—зҡ„еҗҲ并дјҳеҢ–з®—жі•пјҢ, з”ұдәҺUDPж”ҜжҢҒзҡ„жҳҜдёҖеҜ№еӨҡзҡ„жЁЎејҸпјҢжүҖд»ҘжҺҘ收з«Ҝзҡ„skbuff(еҘ—жҺҘеӯ—зј“еҶІеҢәпјүйҮҮз”ЁдәҶй“ҫејҸз»“жһ„жқҘи®°еҪ•жҜҸдёҖдёӘеҲ°иҫҫзҡ„UDPеҢ…пјҢеңЁжҜҸдёӘUDPеҢ…дёӯе°ұжңүдәҶж¶ҲжҒҜеӨҙпјҲж¶ҲжҒҜжқҘжәҗең°еқҖпјҢз«ҜеҸЈзӯүдҝЎжҒҜпјүпјҢиҝҷж ·пјҢеҜ№дәҺжҺҘ收з«ҜжқҘиҜҙпјҢе°ұе®№жҳ“иҝӣиЎҢеҢәеҲҶеӨ„зҗҶдәҶгҖӮ еҚійқўеҗ‘ж¶ҲжҒҜзҡ„йҖҡдҝЎжҳҜжңүж¶ҲжҒҜдҝқжҠӨиҫ№з•Ңзҡ„гҖӮ
tcpжҳҜеҹәдәҺж•°жҚ®жөҒзҡ„пјҢдәҺжҳҜ收еҸ‘зҡ„ж¶ҲжҒҜдёҚиғҪдёәз©әпјҢиҝҷе°ұйңҖиҰҒеңЁе®ўжҲ·з«Ҝе’ҢжңҚеҠЎз«ҜйғҪж·»еҠ з©әж¶ҲжҒҜзҡ„еӨ„зҗҶжңәеҲ¶пјҢйҳІжӯўзЁӢеәҸеҚЎдҪҸпјҢиҖҢudpжҳҜеҹәдәҺж•°жҚ®жҠҘзҡ„пјҢеҚідҫҝжҳҜдҪ иҫ“е…Ҙзҡ„жҳҜз©әеҶ…е®№пјҲзӣҙжҺҘеӣһиҪҰпјүпјҢйӮЈд№ҹдёҚжҳҜз©әж¶ҲжҒҜпјҢudpеҚҸи®®дјҡеё®дҪ е°ҒиЈ…дёҠж¶ҲжҒҜеӨҙпјҢе®һйӘҢз•Ҙ
udpзҡ„recvfromжҳҜйҳ»еЎһзҡ„пјҢдёҖдёӘrecvfrom(x)еҝ…йЎ»еҜ№е”ҜдёҖдёҖдёӘsendinto(y),收е®ҢдәҶxдёӘеӯ—иҠӮзҡ„ж•°жҚ®е°ұз®—е®ҢжҲҗ,иӢҘжҳҜy>xж•°жҚ®е°ұдёўеӨұпјҢиҝҷж„Ҹе‘ізқҖudpж №жң¬дёҚдјҡзІҳеҢ…пјҢдҪҶжҳҜдјҡдёўж•°жҚ®пјҢдёҚеҸҜйқ
tcpзҡ„еҚҸи®®ж•°жҚ®дёҚдјҡдёўпјҢжІЎжңү收е®ҢеҢ…пјҢдёӢж¬ЎжҺҘ收пјҢдјҡ继з»ӯдёҠ次继з»ӯжҺҘ收пјҢе·ұз«ҜжҖ»жҳҜеңЁж”¶еҲ°ackж—¶жүҚдјҡжё…йҷӨзј“еҶІеҢәеҶ…е®№гҖӮж•°жҚ®жҳҜеҸҜйқ зҡ„пјҢдҪҶжҳҜдјҡзІҳеҢ…гҖӮ
дәҢпјҢдёӨз§Қжғ…еҶөдёӢдјҡеҸ‘з”ҹзІҳеҢ…пјҡ
1пјҢеҸ‘йҖҒз«ҜйңҖиҰҒзӯүеҲ°жң¬жңәзҡ„зј“еҶІеҢәж»ЎдәҶд»ҘеҗҺжүҚеҸ‘еҮәеҺ»пјҢйҖ жҲҗзІҳеҢ…пјҲеҸ‘йҖҒж•°жҚ®ж—¶й—ҙй—ҙйҡ”еҫҲзҹӯпјҢж•°жҚ®еҫҲе°ҸпјҢpythonдҪҝз”ЁдәҶдјҳеҢ–з®—жі•пјҢеҗҲеңЁдёҖиө·пјҢдә§з”ҹзІҳеҢ…пјү
е®ўжҲ·з«Ҝ
#_*_coding:utf-8_*_
import socket
BUFSIZE=1024
ip_port=('127.0.0.1',8080)
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
res=s.connect_ex(ip_port)
s.send('hello'.encode('utf-8'))
s.send('feng'.encode('utf-8'))жңҚеҠЎз«Ҝ
#_*_coding:utf-8_*_
from socket import *
ip_port=('127.0.0.1',8080)
tcp_socket_server=socket(AF_INET,SOCK_STREAM)
tcp_socket_server.bind(ip_port)
tcp_socket_server.listen(5)
conn,addr=tcp_socket_server.accept()
data1=conn.recv(10)
data2=conn.recv(10)
print('----->',data1.decode('utf-8'))
print('----->',data2.decode('utf-8'))
conn.close()2пјҢжҺҘ收з«ҜдёҚеҸҠж—¶жҺҘеҸ—зј“еҶІеҢәзҡ„еҢ…пјҢйҖ жҲҗеӨҡдёӘеҢ…жҺҘеҸ—пјҲе®ўжҲ·з«ҜеҸ‘йҖҒдёҖж®өж•°жҚ®пјҢжңҚеҠЎз«ҜеҸӘ收дәҶдёҖе°ҸйғЁеҲҶпјҢжңҚеҠЎз«ҜдёӢж¬ЎеҶҚ收зҡ„ж—¶еҖҷиҝҳжҳҜд»Һзј“еҶІеҢәжӢҝдёҠж¬ЎйҒ—з•ҷзҡ„ж•°жҚ®пјҢе°ұдә§з”ҹзІҳеҢ…пјү е®ўжҲ·з«Ҝ
#_*_coding:utf-8_*_
import socket
BUFSIZE=1024
ip_port=('127.0.0.1',8080)
s=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
res=s.connect_ex(ip_port)
s.send('hello feng'.encode('utf-8'))жңҚеҠЎз«Ҝ
#_*_coding:utf-8_*_
from socket import *
ip_port=('127.0.0.1',8080)
tcp_socket_server=socket(AF_INET,SOCK_STREAM)
tcp_socket_server.bind(ip_port)
tcp_socket_server.listen(5)
conn,addr=tcp_socket_server.accept()
data1=conn.recv(2) #дёҖж¬ЎжІЎжңү收е®Ңж•ҙ
data2=conn.recv(10)#дёӢ次收зҡ„ж—¶еҖҷ,дјҡе…ҲеҸ–ж—§зҡ„ж•°жҚ®,然еҗҺеҸ–ж–°зҡ„
print('----->',data1.decode('utf-8'))
print('----->',data2.decode('utf-8'))
conn.close()дёүпјҢзІҳеҢ…е®һдҫӢпјҡ
жңҚеҠЎз«Ҝ
import socket
import subprocess
din=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
ip_port=('127.0.0.1',8080)
din.bind(ip_port)
din.listen(5)
conn,deer=din.accept()
data1=conn.recv(1024)
data2=conn.recv(1024)
print(data1)
print(data2)е®ўжҲ·з«Ҝпјҡ
import socket
import subprocess
din=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
ip_port=('127.0.0.1',8080)
din.connect(ip_port)
din.send('helloworld'.encode('utf-8'))
din.send('sb'.encode('utf-8'))еӣӣпјҢжӢҶеҢ…зҡ„еҸ‘з”ҹжғ…еҶө
еҪ“еҸ‘йҖҒз«Ҝзј“еҶІеҢәзҡ„й•ҝеәҰеӨ§дәҺзҪ‘еҚЎзҡ„MTUж—¶пјҢtcpдјҡе°Ҷиҝҷж¬ЎеҸ‘йҖҒзҡ„ж•°жҚ®жӢҶжҲҗеҮ дёӘж•°жҚ®еҢ…еҸ‘йҖҒиҝҮеҺ»
иЎҘе……й—®йўҳдёҖпјҡдёәдҪ•tcpжҳҜеҸҜйқ дј иҫ“пјҢudpжҳҜдёҚеҸҜйқ дј иҫ“
е…ідәҺtcpдј иҫ“иҜ·еҸӮиҖғпјҡ https://www.jb51.net/network/176867.html
tcpеңЁж•°жҚ®дј иҫ“ж—¶пјҢеҸ‘йҖҒз«Ҝе…ҲжҠҠж•°жҚ®еҸ‘йҖҒеҲ°иҮӘе·ұзҡ„зј“еӯҳдёӯпјҢ然еҗҺеҚҸи®®жҺ§еҲ¶е°Ҷзј“еӯҳдёӯзҡ„ж•°жҚ®еҸ‘еҫҖеҜ№з«ҜпјҢеҜ№з«Ҝиҝ”еӣһдёҖдёӘack=1пјҢеҸ‘йҖҒз«ҜеҲҷжё…зҗҶзј“еӯҳдёӯзҡ„ж•°жҚ®пјҢеҜ№з«Ҝиҝ”еӣһack=0пјҢеҲҷйҮҚж–°еҸ‘йҖҒж•°жҚ®пјҢжүҖд»ҘtcpжҳҜеҸҜйқ зҡ„
иҖҢudpеҸ‘йҖҒж•°жҚ®пјҢеҜ№з«ҜжҳҜдёҚдјҡиҝ”еӣһзЎ®и®ӨдҝЎжҒҜзҡ„пјҢеӣ жӯӨдёҚеҸҜйқ
иЎҘе……й—®йўҳдәҢпјҡsendпјҲеӯ—иҠӮжөҒпјүе’Ңrecv(1024пјүеҸҠsendallжҳҜд»Җд№Ҳж„ҸжҖқпјҹ
recvйҮҢжҢҮе®ҡзҡ„1024ж„ҸжҖқжҳҜд»Һзј“еӯҳйҮҢдёҖж¬ЎжӢҝеҮә1024дёӘеӯ—иҠӮзҡ„ж•°жҚ®
sendзҡ„еӯ—иҠӮжөҒжҳҜе…Ҳж”ҫе…Ҙе·ұз«Ҝзј“еӯҳпјҢ然еҗҺз”ұеҚҸи®®жҺ§еҲ¶е°Ҷзј“еӯҳеҶ…е®№еҸ‘еҫҖеҜ№з«ҜпјҢеҰӮжһңеӯ—иҠӮжөҒеӨ§е°ҸеӨ§дәҺзј“еӯҳеү©дҪҷз©әй—ҙпјҢйӮЈд№Ҳж•°жҚ®дёўеӨұпјҢз”Ёsendallе°ұдјҡеҫӘзҺҜи°ғз”ЁsendпјҢж•°жҚ®дёҚдјҡдёўеӨұгҖӮ
дә”пјҢзІҳеҢ…й—®йўҳеҰӮдҪ•и§ЈеҶіпјҹ
й—®йўҳзҡ„ж №жәҗеңЁдәҺпјҢжҺҘ收з«ҜдёҚзҹҘйҒ“еҸ‘йҖҒз«Ҝе°ҶиҰҒдј йҖҒзҡ„еӯ—иҠӮжөҒзҡ„й•ҝеәҰпјҢжүҖд»Ҙи§ЈеҶізІҳеҢ…зҡ„ж–№жі•е°ұжҳҜеӣҙз»•пјҢеҰӮдҪ•и®©еҸ‘йҖҒз«ҜеңЁеҸ‘йҖҒж•°жҚ®еүҚпјҢжҠҠиҮӘе·ұе°ҶиҰҒеҸ‘йҖҒзҡ„еӯ—иҠӮжөҒжҖ»еӨ§е°Ҹи®©жҺҘ收з«ҜзҹҘжҷ“пјҢ然еҗҺжҺҘ收з«ҜжқҘдёҖдёӘжӯ»еҫӘзҺҜжҺҘ收е®ҢжүҖжңүж•°жҚ®гҖӮ
5-1 з®ҖеҚ•зҡ„и§ЈеҶіж–№жі•пјҲд»ҺиЎЁйқўи§ЈеҶіпјүпјҡ
еңЁе®ўжҲ·з«ҜеҸ‘йҖҒдёӢиҫ№ж·»еҠ дёҖдёӘж—¶й—ҙзқЎзң пјҢе°ұеҸҜд»ҘйҒҝе…ҚзІҳеҢ…зҺ°иұЎгҖӮеңЁжңҚеҠЎз«ҜжҺҘ收зҡ„ж—¶еҖҷд№ҹиҰҒиҝӣиЎҢж—¶й—ҙзқЎзң пјҢжүҚиғҪжңүж•Ҳзҡ„йҒҝе…ҚзІҳеҢ…жғ…еҶөгҖӮ
е®ўжҲ·з«Ҝпјҡ
#е®ўжҲ·з«Ҝ
import socket
import time
import subprocess
din=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
ip_port=('127.0.0.1',8080)
din.connect(ip_port)
din.send('helloworld'.encode('utf-8'))
time.sleep(3)
din.send('sb'.encode('utf-8'))жңҚеҠЎз«Ҝпјҡ
#жңҚеҠЎз«Ҝ
import socket
import time
import subprocess
din=socket.socket(socket.AF_INET,socket.SOCK_STREAM)
ip_port=('127.0.0.1',8080)
din.bind(ip_port)
din.listen(5)
conn,deer=din.accept()
data1=conn.recv(1024)
time.sleep(4)
data2=conn.recv(1024)
print(data1)
print(data2)дёҠйқўи§ЈеҶіж–№жі•иӮҜе®ҡдјҡеҮәзҺ°еҫҲеӨҡзә°жјҸпјҢеӣ дёәдҪ дёҚзҹҘйҒ“д»Җд№Ҳж—¶еҖҷдј иҫ“е®ҢпјҢж—¶й—ҙжҡӮеҒңзҡ„й•ҝзҹӯйғҪдјҡжңүй—®йўҳпјҢй•ҝзҡ„иҜқж•ҲзҺҮдҪҺпјҢзҹӯзҡ„иҜқдёҚеҗҲйҖӮпјҢжүҖд»Ҙиҝҷз§Қж–№жі•жҳҜдёҚеҗҲйҖӮзҡ„гҖӮ
5-2 жҷ®йҖҡзҡ„и§ЈеҶіж–№жі•пјҲд»Һж №жң¬зңӢй—®йўҳпјүпјҡ
й—®йўҳзҡ„ж №жәҗеңЁдәҺпјҢжҺҘ收з«ҜдёҚзҹҘйҒ“еҸ‘йҖҒз«Ҝе°ҶиҰҒдј йҖҒзҡ„еӯ—иҠӮжөҒзҡ„й•ҝеәҰпјҢжүҖд»Ҙи§ЈеҶізІҳеҢ…зҡ„ж–№жі•е°ұжҳҜеӣҙз»•пјҢеҰӮдҪ•и®©еҸ‘йҖҒз«ҜеңЁеҸ‘йҖҒж•°жҚ®еүҚпјҢжҠҠиҮӘе·ұе°ҶиҰҒеҸ‘йҖҒзҡ„еӯ—иҠӮжөҒжҖ»еӨ§е°Ҹи®©жҺҘ收з«ҜзҹҘжҷ“пјҢ然еҗҺжҺҘ收з«ҜжқҘдёҖдёӘжӯ»еҫӘзҺҜжҺҘ收е®ҢжүҖжңүж•°жҚ®
дёәеӯ—иҠӮжөҒеҠ дёҠиҮӘе®ҡд№үеӣәе®ҡй•ҝеәҰжҠҘеӨҙпјҢжҠҘеӨҙдёӯеҢ…еҗ«еӯ—иҠӮжөҒй•ҝеәҰпјҢ然еҗҺдҫқж¬ЎsendеҲ°еҜ№з«ҜпјҢеҜ№з«ҜеңЁжҺҘеҸ—ж—¶пјҢе…Ҳд»Һзј“еӯҳдёӯеҸ–еҮәе®ҡй•ҝзҡ„жҠҘеӨҙпјҢ然еҗҺеҶҚеҸ–зңҹжҳҜж•°жҚ®гҖӮ
дҪҝз”ЁstructжЁЎеқ—еҜ№жү“еҢ…зҡ„й•ҝеәҰдёәеӣәе®ҡ4дёӘеӯ—иҠӮжҲ–иҖ…е…«дёӘеӯ—иҠӮпјҢstruct.pack.formatеҸӮж•°жҳҜвҖңiвҖқж—¶пјҢеҸӘиғҪжү“еҢ…й•ҝеәҰдёә10зҡ„ж•°еӯ—пјҢйӮЈд№ҲиҝҳеҸҜд»Ҙе…Ҳе°Ҷй•ҝеәҰиҪ¬еҢ–дёәjsonеӯ—з¬ҰдёІпјҢеҶҚжү“еҢ…гҖӮ
жҷ®йҖҡзҡ„е®ўжҲ·з«Ҝ
# _*_ coding: utf-8 _*_
import socket
import struct
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',8880)) #иҝһжҺҘжңҚ
while True:
# еҸ‘收ж¶ҲжҒҜ
cmd = input('иҜ·дҪ иҫ“е…Ҙе‘Ҫд»Ө>>пјҡ').strip()
if not cmd:continue
phone.send(cmd.encode('utf-8')) #еҸ‘йҖҒ
#е…Ҳ收жҠҘеӨҙ
header_struct = phone.recv(4) #收еӣӣдёӘ
unpack_res = struct.unpack('i',header_struct)
total_size = unpack_res[0] #жҖ»й•ҝеәҰ
#еҗҺ收数жҚ®
recv_size = 0
total_data=b''
while recv_size<total_size: #еҫӘзҺҜзҡ„收
recv_data = phone.recv(1024) #1024еҸӘжҳҜдёҖдёӘжңҖеӨ§зҡ„йҷҗеҲ¶
recv_size+=len(recv_data) #
total_data+=recv_data #
print('иҝ”еӣһзҡ„ж¶ҲжҒҜпјҡ%s'%total_data.decode('gbk'))
phone.close()жҷ®йҖҡзҡ„жңҚеҠЎз«Ҝ
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #д№°жүӢжңә
phone.bind(('127.0.0.1',8880)) #з»‘е®ҡжүӢжңәеҚЎ
phone.listen(5) #йҳ»еЎһзҡ„жңҖеӨ§ж•°
print('start runing.....')
while True: #й“ҫжҺҘеҫӘзҺҜ
coon,addr = phone.accept()# зӯүеҫ…жҺҘз”өиҜқ
print(coon,addr)
while True: #йҖҡдҝЎеҫӘзҺҜ
# 收еҸ‘ж¶ҲжҒҜ
cmd = coon.recv(1024) #жҺҘ收зҡ„жңҖеӨ§ж•°
print('жҺҘ收зҡ„жҳҜпјҡ%s'%cmd.decode('utf-8'))
#еӨ„зҗҶиҝҮзЁӢ
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #ж ҮеҮҶиҫ“еҮә
stderr=subprocess.PIPE #ж ҮеҮҶй”ҷиҜҜ
)
stdout = res.stdout.read()
stderr = res.stderr.read()
#е…ҲеҸ‘жҠҘеӨҙ(иҪ¬жҲҗеӣәе®ҡй•ҝеәҰзҡ„bytesзұ»еһӢпјҢйӮЈд№ҲжҖҺд№ҲиҪ¬е‘ўпјҹе°ұз”ЁеҲ°дәҶstructжЁЎеқ—)
#len(stdout) + len(stderr)#з»ҹи®Ўж•°жҚ®зҡ„й•ҝеәҰ
header = struct.pack('i',len(stdout)+len(stderr))#еҲ¶дҪңжҠҘеӨҙ
coon.send(header)
#еҶҚеҸ‘е‘Ҫд»Өзҡ„з»“жһң
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()5-3 дјҳеҢ–зүҲзҡ„и§ЈеҶіж–№жі•пјҲд»Һж №жң¬и§ЈеҶій—®йўҳпјү
дјҳеҢ–зҡ„и§ЈеҶізІҳеҢ…й—®йўҳзҡ„жҖқи·Ҝе°ұжҳҜжңҚеҠЎз«Ҝе°ҶжҠҘеӨҙдҝЎжҒҜиҝӣиЎҢдјҳеҢ–пјҢеҜ№иҰҒеҸ‘йҖҒзҡ„еҶ…е®№з”Ёеӯ—е…ёиҝӣиЎҢжҸҸиҝ°пјҢйҰ–е…Ҳеӯ—е…ёдёҚиғҪзӣҙжҺҘиҝӣиЎҢзҪ‘з»ңдј иҫ“пјҢйңҖиҰҒиҝӣиЎҢеәҸеҲ—еҢ–иҪ¬жҲҗjsonж јејҸеҢ–еӯ—з¬ҰдёІпјҢ然еҗҺиҪ¬жҲҗbytesж јејҸжңҚеҠЎз«ҜиҝӣиЎҢеҸ‘йҖҒпјҢеӣ дёәbytesж јејҸзҡ„jsonеӯ—з¬ҰдёІй•ҝеәҰдёҚжҳҜеӣәе®ҡзҡ„пјҢжүҖд»ҘиҰҒз”ЁstructжЁЎеқ—е°Ҷbytesж јејҸзҡ„jsonеӯ—з¬ҰдёІй•ҝеәҰеҺӢзј©жҲҗеӣәе®ҡй•ҝеәҰпјҢеҸ‘йҖҒз»ҷе®ўжҲ·з«ҜпјҢе®ўжҲ·з«ҜиҝӣиЎҢжҺҘеҸ—пјҢеҸҚи§Је°ұдјҡеҫ—еҲ°е®Ңж•ҙзҡ„ж•°жҚ®еҢ…гҖӮ
з»ҲжһҒзүҲзҡ„е®ўжҲ·з«Ҝ
# _*_ coding: utf-8 _*_
import socket
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM)
phone.connect(('127.0.0.1',8080)) #иҝһжҺҘжңҚеҠЎеҷЁ
while True:
# еҸ‘收ж¶ҲжҒҜ
cmd = input('иҜ·дҪ иҫ“е…Ҙе‘Ҫд»Ө>>пјҡ').strip()
if not cmd:continue
phone.send(cmd.encode('utf-8')) #еҸ‘йҖҒ
#е…Ҳ收жҠҘеӨҙзҡ„й•ҝеәҰ
header_len = struct.unpack('i',phone.recv(4))[0] #еҗ§bytesзұ»еһӢзҡ„еҸҚи§Ј
#еңЁж”¶жҠҘеӨҙ
header_bytes = phone.recv(header_len) #收иҝҮжқҘзҡ„д№ҹжҳҜbytesзұ»еһӢ
header_json = header_bytes.decode('utf-8') #жӢҝеҲ°jsonж јејҸзҡ„еӯ—е…ё
header_dic = json.loads(header_json) #еҸҚеәҸеҲ—еҢ–жӢҝеҲ°еӯ—е…ёдәҶ
total_size = header_dic['total_size'] #е°ұжӢҝеҲ°ж•°жҚ®зҡ„жҖ»й•ҝеәҰдәҶ
#жңҖеҗҺ收数жҚ®
recv_size = 0
total_data=b''
while recv_size<total_size: #еҫӘзҺҜзҡ„收
recv_data = phone.recv(1024) #1024еҸӘжҳҜдёҖдёӘжңҖеӨ§зҡ„йҷҗеҲ¶
recv_size+=len(recv_data) #жңүеҸҜиғҪжҺҘ收зҡ„дёҚжҳҜ1024дёӘеӯ—иҠӮпјҢжҲ–и®ёжҜ”1024еӨҡе‘ўпјҢ
# йӮЈд№ҲжҺҘ收зҡ„ж—¶еҖҷе°ұжҺҘ收дёҚе…ЁпјҢжүҖд»ҘиҝҳиҰҒеҠ дёҠжҺҘ收зҡ„йӮЈдёӘй•ҝеәҰ
total_data+=recv_data #жңҖз»Ҳзҡ„з»“жһң
print('иҝ”еӣһзҡ„ж¶ҲжҒҜпјҡ%s'%total_data.decode('gbk'))
phone.close()з»ҲжһҒзүҲзҡ„жңҚеҠЎз«Ҝ
# _*_ coding: utf-8 _*_
import socket
import subprocess
import struct
import json
phone = socket.socket(socket.AF_INET,socket.SOCK_STREAM) #д№°жүӢжңә
phone.setsockopt(socket.SOL_SOCKET,socket.SO_REUSEADDR,1)
phone.bind(('127.0.0.1',8080)) #з»‘е®ҡжүӢжңәеҚЎ
phone.listen(5) #йҳ»еЎһзҡ„жңҖеӨ§ж•°
print('start runing.....')
while True: #й“ҫжҺҘеҫӘзҺҜ
coon,addr = phone.accept()# зӯүеҫ…жҺҘз”өиҜқ
print(coon,addr)
while True: #йҖҡдҝЎеҫӘзҺҜ
# 收еҸ‘ж¶ҲжҒҜ
cmd = coon.recv(1024) #жҺҘ收зҡ„жңҖеӨ§ж•°
print('жҺҘ收зҡ„жҳҜпјҡ%s'%cmd.decode('utf-8'))
#еӨ„зҗҶиҝҮзЁӢ
res = subprocess.Popen(cmd.decode('utf-8'),shell = True,
stdout=subprocess.PIPE, #ж ҮеҮҶиҫ“еҮә
stderr=subprocess.PIPE #ж ҮеҮҶй”ҷиҜҜ
)
stdout = res.stdout.read()
stderr = res.stderr.read()
# еҲ¶дҪңжҠҘеӨҙ
header_dic = {
'total_size': len(stdout)+len(stderr), # жҖ»е…ұзҡ„еӨ§е°Ҹ
'filename': None,
'md5': None
}
header_json = json.dumps(header_dic) #еӯ—з¬ҰдёІзұ»еһӢ
header_bytes = header_json.encode('utf-8') #иҪ¬жҲҗbytesзұ»еһӢ(дҪҶжҳҜй•ҝеәҰжҳҜеҸҜеҸҳзҡ„)
#е…ҲеҸ‘жҠҘеӨҙзҡ„й•ҝеәҰ
coon.send(struct.pack('i',len(header_bytes))) #еҸ‘йҖҒеӣәе®ҡй•ҝеәҰзҡ„жҠҘеӨҙ
#еҶҚеҸ‘жҠҘеӨҙ
coon.send(header_bytes)
#жңҖеҗҺеҸ‘е‘Ҫд»Өзҡ„з»“жһң
coon.send(stdout)
coon.send(stderr)
coon.close()
phone.close()е…ӯпјҢstructжЁЎеқ—
дәҶи§ЈcиҜӯиЁҖзҡ„дәәпјҢдёҖе®ҡдјҡзҹҘйҒ“structз»“жһ„дҪ“еңЁcиҜӯиЁҖдёӯзҡ„дҪңз”ЁпјҢе®ғе®ҡд№үдәҶдёҖз§Қз»“жһ„пјҢйҮҢйқўеҢ…еҗ«дёҚеҗҢзұ»еһӢзҡ„ж•°жҚ®(int,char,boolзӯүзӯү)пјҢж–№дҫҝеҜ№жҹҗдёҖз»“жһ„еҜ№иұЎиҝӣиЎҢеӨ„зҗҶгҖӮиҖҢеңЁзҪ‘з»ңйҖҡдҝЎеҪ“дёӯпјҢеӨ§еӨҡдј йҖ’зҡ„ж•°жҚ®жҳҜд»ҘдәҢиҝӣеҲ¶жөҒпјҲbinary dataпјүеӯҳеңЁзҡ„гҖӮеҪ“дј йҖ’еӯ—з¬ҰдёІж—¶пјҢдёҚеҝ…жӢ…еҝғеӨӘеӨҡзҡ„й—®йўҳпјҢиҖҢеҪ“дј йҖ’иҜёеҰӮintгҖҒcharд№Ӣзұ»зҡ„еҹәжң¬ж•°жҚ®зҡ„ж—¶еҖҷпјҢе°ұйңҖиҰҒжңүдёҖз§ҚжңәеҲ¶е°Ҷжҹҗдәӣзү№е®ҡзҡ„з»“жһ„дҪ“зұ»еһӢжү“еҢ…жҲҗдәҢиҝӣеҲ¶жөҒзҡ„еӯ—з¬Ұ串然еҗҺеҶҚзҪ‘з»ңдј иҫ“пјҢиҖҢжҺҘ收з«Ҝд№ҹеә”иҜҘеҸҜд»ҘйҖҡиҝҮжҹҗз§ҚжңәеҲ¶иҝӣиЎҢи§ЈеҢ…иҝҳеҺҹеҮәеҺҹе§Ӣзҡ„з»“жһ„дҪ“ж•°жҚ®гҖӮpythonдёӯзҡ„structжЁЎеқ—е°ұжҸҗдҫӣдәҶиҝҷж ·зҡ„жңәеҲ¶пјҢиҜҘжЁЎеқ—зҡ„дё»иҰҒдҪңз”Ёе°ұжҳҜеҜ№pythonеҹәжң¬зұ»еһӢеҖјдёҺз”Ёpythonеӯ—з¬ҰдёІж јејҸиЎЁзӨәзҡ„C structзұ»еһӢй—ҙзҡ„иҪ¬еҢ–пјҲThis module performs conversions between Python values and C structs represented as Python strings.пјүгҖӮstuctжЁЎеқ—жҸҗдҫӣдәҶеҫҲз®ҖеҚ•зҡ„еҮ дёӘеҮҪж•°пјҢдёӢйқўеҶҷеҮ дёӘдҫӢеӯҗгҖӮ
1пјҢеҹәжң¬зҡ„packе’Ңunpack
structжҸҗдҫӣз”Ёformat specifierж–№ејҸеҜ№ж•°жҚ®иҝӣиЎҢжү“еҢ…е’Ңи§ЈеҢ…пјҲPacking and UnpackingпјүгҖӮдҫӢеҰӮ:
#иҜҘжЁЎеқ—еҸҜд»ҘжҠҠдёҖдёӘзұ»еһӢпјҢеҰӮж•°еӯ—пјҢиҪ¬жҲҗеӣәе®ҡй•ҝеәҰзҡ„bytesзұ»еһӢ
import struct
# res = struct.pack('i',12345)
# print(res,len(res),type(res)) #й•ҝеәҰжҳҜ4
res2 = struct.pack('i',12345111)
print(res2,len(res2),type(res2)) #й•ҝеәҰд№ҹжҳҜ4
unpack_res =struct.unpack('i',res2)
print(unpack_res) #(12345111,)
# print(unpack_res[0]) #12345111д»Јз ҒдёӯпјҢйҰ–е…Ҳе®ҡд№үдәҶдёҖдёӘе…ғз»„ж•°жҚ®пјҢеҢ…еҗ«intгҖҒstringгҖҒfloatдёүз§Қж•°жҚ®зұ»еһӢпјҢ然еҗҺе®ҡд№үдәҶstructеҜ№иұЎпјҢ并еҲ¶е®ҡдәҶformatвҖҳI3sf'пјҢI иЎЁзӨәintпјҢ3sиЎЁзӨәдёүдёӘеӯ—з¬Ұй•ҝеәҰзҡ„еӯ—з¬ҰдёІпјҢf иЎЁзӨә floatгҖӮжңҖеҗҺйҖҡиҝҮstructзҡ„packе’ҢunpackиҝӣиЎҢжү“еҢ…е’Ңи§ЈеҢ…гҖӮйҖҡиҝҮиҫ“еҮәз»“жһңеҸҜд»ҘеҸ‘зҺ°пјҢvalueиў«packд№ӢеҗҺпјҢиҪ¬еҢ–дёәдәҶдёҖж®өдәҢиҝӣеҲ¶еӯ—иҠӮдёІпјҢиҖҢunpackеҸҜд»ҘжҠҠиҜҘеӯ—иҠӮдёІеҶҚиҪ¬жҚўеӣһдёҖдёӘе…ғз»„пјҢдҪҶжҳҜеҖјеҫ—жіЁж„Ҹзҡ„жҳҜеҜ№дәҺfloatзҡ„зІҫеәҰеҸ‘з”ҹдәҶж”№еҸҳпјҢиҝҷжҳҜз”ұдёҖдәӣжҜ”еҰӮж“ҚдҪңзі»з»ҹзӯүе®ўи§Ӯеӣ зҙ жүҖеҶіе®ҡзҡ„гҖӮжү“еҢ…д№ӢеҗҺзҡ„ж•°жҚ®жүҖеҚ з”Ёзҡ„еӯ—иҠӮж•°дёҺCиҜӯиЁҖдёӯзҡ„structеҚҒеҲҶзӣёдјјгҖӮ
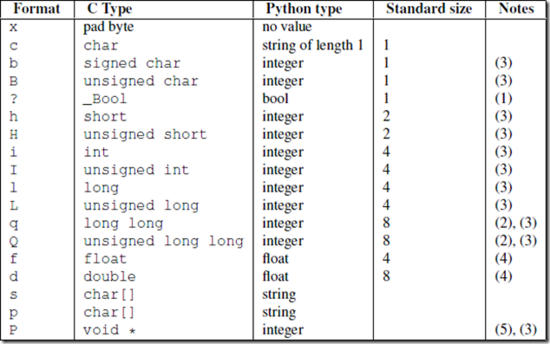
2,е®ҡд№үformatеҸҜд»ҘеҸӮз…§е®ҳж–№apiжҸҗдҫӣзҡ„еҜ№з…§иЎЁпјҡ
3пјҢеҹәжң¬з”Ёжі•
import json,struct
#еҒҮи®ҫйҖҡиҝҮе®ўжҲ·з«ҜдёҠдј 1T:1073741824000зҡ„ж–Ү件a.txt
#дёәйҒҝе…ҚзІҳеҢ…,еҝ…йЎ»иҮӘе®ҡеҲ¶жҠҘеӨҙ
header={'file_size':1073741824000,'file_name':'/a/b/c/d/e/a.txt','md5':'8f6fbf8347faa4924a76856701edb0f3'} #1Tж•°жҚ®,ж–Ү件и·Ҝеҫ„е’Ңmd5еҖј
#дёәдәҶиҜҘжҠҘеӨҙиғҪдј йҖҒ,йңҖиҰҒеәҸеҲ—еҢ–并且иҪ¬дёәbytes
head_bytes=bytes(json.dumps(header),encoding='utf-8') #еәҸеҲ—еҢ–并иҪ¬жҲҗbytes,з”ЁдәҺдј иҫ“
#дёәдәҶи®©е®ўжҲ·з«ҜзҹҘйҒ“жҠҘеӨҙзҡ„й•ҝеәҰ,з”Ёstruckе°ҶжҠҘеӨҙй•ҝеәҰиҝҷдёӘж•°еӯ—иҪ¬жҲҗеӣәе®ҡй•ҝеәҰ:4дёӘеӯ—иҠӮ
head_len_bytes=struct.pack('i',len(head_bytes)) #иҝҷ4дёӘеӯ—иҠӮйҮҢеҸӘеҢ…еҗ«дәҶдёҖдёӘж•°еӯ—,иҜҘж•°еӯ—жҳҜжҠҘеӨҙзҡ„й•ҝеәҰ
#е®ўжҲ·з«ҜејҖе§ӢеҸ‘йҖҒ
conn.send(head_len_bytes) #е…ҲеҸ‘жҠҘеӨҙзҡ„й•ҝеәҰ,4дёӘbytes
conn.send(head_bytes) #еҶҚеҸ‘жҠҘеӨҙзҡ„еӯ—иҠӮж јејҸ
conn.sendall(ж–Ү件еҶ…е®№) #然еҗҺеҸ‘зңҹе®һеҶ…е®№зҡ„еӯ—иҠӮж јејҸ
#жңҚеҠЎз«ҜејҖе§ӢжҺҘ收
head_len_bytes=s.recv(4) #е…Ҳ收жҠҘеӨҙ4дёӘbytes,еҫ—еҲ°жҠҘеӨҙй•ҝеәҰзҡ„еӯ—иҠӮж јејҸ
x=struct.unpack('i',head_len_bytes)[0] #жҸҗеҸ–жҠҘеӨҙзҡ„й•ҝеәҰ
head_bytes=s.recv(x) #жҢүз…§жҠҘеӨҙй•ҝеәҰx,收еҸ–жҠҘеӨҙзҡ„bytesж јејҸ
header=json.loads(json.dumps(header)) #жҸҗеҸ–жҠҘеӨҙ
#жңҖеҗҺж №жҚ®жҠҘеӨҙзҡ„еҶ…е®№жҸҗеҸ–зңҹе®һзҡ„ж•°жҚ®,жҜ”еҰӮ
real_data_len=s.recv(header['file_size'])
s.recv(real_data_len)ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒе…ідәҺвҖңpythonдёӯsocketзҪ‘з»ңзј–зЁӢд№ӢзІҳеҢ…зҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢи®©еӨ§е®¶еҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°еҗ§пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ