жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еңЁе…¬еҸёеҒҡеҲҶеёғејҸж·ұзҪ‘зҲ¬иҷ«пјҢжҗӯе»әдәҶдёҖеҘ—зЁіе®ҡзҡ„д»ЈзҗҶжұ жңҚеҠЎпјҢдёәдёҠеҚғдёӘзҲ¬иҷ«жҸҗдҫӣжңүж•Ҳзҡ„д»ЈзҗҶпјҢдҝқиҜҒеҗ„дёӘзҲ¬иҷ«жӢҝеҲ°зҡ„йғҪжҳҜеҜ№еә”зҪ‘з«ҷжңүж•Ҳзҡ„д»ЈзҗҶIPпјҢд»ҺиҖҢдҝқиҜҒзҲ¬иҷ«еҝ«йҖҹзЁіе®ҡзҡ„иҝҗиЎҢпјҢеҪ“然еңЁе…¬еҸёеҒҡзҡ„дёңиҘҝдёҚиғҪејҖжәҗеҮәжқҘгҖӮдёҚиҝҮе‘ўпјҢй—ІжҡҮж—¶й—ҙжүӢз—’пјҢжүҖд»Ҙе°ұжғіеҲ©з”ЁдёҖдәӣе…Қиҙ№зҡ„иө„жәҗжҗһдёҖдёӘз®ҖеҚ•зҡ„д»ЈзҗҶжұ жңҚеҠЎгҖӮ
1гҖҒй—®йўҳ
д»ЈзҗҶIPд»ҺдҪ•иҖҢжқҘпјҹ
еҲҡиҮӘеӯҰзҲ¬иҷ«зҡ„ж—¶еҖҷжІЎжңүд»ЈзҗҶIPе°ұеҺ»иҘҝеҲәгҖҒеҝ«д»ЈзҗҶд№Ӣзұ»жңүе…Қиҙ№д»ЈзҗҶзҡ„зҪ‘з«ҷеҺ»зҲ¬пјҢиҝҳжҳҜжңүдёӘеҲ«д»ЈзҗҶиғҪз”ЁгҖӮеҪ“然пјҢеҰӮжһңдҪ жңүжӣҙеҘҪзҡ„д»ЈзҗҶжҺҘеҸЈд№ҹеҸҜд»ҘиҮӘе·ұжҺҘе…ҘгҖӮ
е…Қиҙ№д»ЈзҗҶзҡ„йҮҮйӣҶд№ҹеҫҲз®ҖеҚ•пјҢж— йқһе°ұжҳҜпјҡи®ҝй—®йЎөйқўйЎөйқў вҖ”> жӯЈеҲҷ/xpathжҸҗеҸ– вҖ”> дҝқеӯҳ
еҰӮдҪ•дҝқиҜҒд»ЈзҗҶиҙЁйҮҸпјҹ
еҸҜд»ҘиӮҜе®ҡе…Қиҙ№зҡ„д»ЈзҗҶIPеӨ§йғЁеҲҶйғҪжҳҜдёҚиғҪз”Ёзҡ„пјҢдёҚ然еҲ«дәәдёәд»Җд№ҲиҝҳжҸҗдҫӣд»ҳиҙ№зҡ„(дёҚиҝҮдәӢе®һжҳҜеҫҲеӨҡд»ЈзҗҶе•Ҷзҡ„д»ҳиҙ№IPд№ҹдёҚзЁіе®ҡпјҢд№ҹжңүеҫҲеӨҡжҳҜдёҚиғҪз”Ё)гҖӮжүҖд»ҘйҮҮйӣҶеӣһжқҘзҡ„д»ЈзҗҶIPдёҚиғҪзӣҙжҺҘдҪҝз”ЁпјҢеҸҜд»ҘеҶҷжЈҖжөӢзЁӢеәҸдёҚж–ӯзҡ„еҺ»з”Ёиҝҷдәӣд»ЈзҗҶи®ҝй—®дёҖдёӘзЁіе®ҡзҡ„зҪ‘з«ҷпјҢзңӢжҳҜеҗҰеҸҜд»ҘжӯЈеёёдҪҝз”ЁгҖӮиҝҷдёӘиҝҮзЁӢеҸҜд»ҘдҪҝз”ЁеӨҡзәҝзЁӢжҲ–ејӮжӯҘзҡ„ж–№ејҸпјҢеӣ дёәжЈҖжөӢд»ЈзҗҶжҳҜдёӘеҫҲж…ўзҡ„иҝҮзЁӢгҖӮ
йҮҮйӣҶеӣһжқҘзҡ„д»ЈзҗҶеҰӮдҪ•еӯҳеӮЁпјҹ
иҝҷйҮҢдёҚеҫ—дёҚжҺЁиҚҗдёҖдёӘй«ҳжҖ§иғҪж”ҜжҢҒеӨҡз§Қж•°жҚ®з»“жһ„зҡ„NoSQLж•°жҚ®еә“SSDBпјҢз”ЁдәҺд»ЈзҗҶRedisгҖӮж”ҜжҢҒйҳҹеҲ—гҖҒhashгҖҒsetгҖҒk-vеҜ№пјҢж”ҜжҢҒTзә§еҲ«ж•°жҚ®гҖӮжҳҜеҒҡеҲҶеёғејҸзҲ¬иҷ«еҫҲеҘҪдёӯй—ҙеӯҳеӮЁе·Ҙе…·гҖӮ
еҰӮдҪ•и®©зҲ¬иҷ«жӣҙз®ҖеҚ•зҡ„дҪҝз”Ёиҝҷдәӣд»ЈзҗҶпјҹ
зӯ”жЎҲиӮҜе®ҡжҳҜеҒҡжҲҗжңҚеҠЎе’ҜпјҢpythonжңүиҝҷд№ҲеӨҡзҡ„webжЎҶжһ¶пјҢйҡҸдҫҝжӢҝдёҖдёӘжқҘеҶҷдёӘapiдҫӣзҲ¬иҷ«и°ғз”ЁгҖӮиҝҷж ·жңүеҫҲеӨҡеҘҪеӨ„пјҢжҜ”еҰӮпјҡеҪ“зҲ¬иҷ«еҸ‘зҺ°д»ЈзҗҶдёҚиғҪдҪҝз”ЁеҸҜд»Ҙдё»еҠЁйҖҡиҝҮapiеҺ»deleteд»ЈзҗҶIPпјҢеҪ“зҲ¬иҷ«еҸ‘зҺ°д»ЈзҗҶжұ IPдёҚеӨҹз”Ёж—¶еҸҜд»Ҙдё»еҠЁеҺ»refreshд»ЈзҗҶжұ гҖӮиҝҷж ·жҜ”жЈҖжөӢзЁӢеәҸжӣҙеҠ йқ и°ұгҖӮ
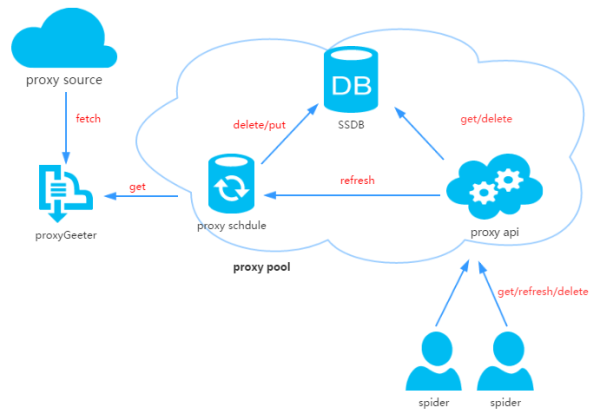
2гҖҒд»ЈзҗҶжұ и®ҫи®Ў
д»ЈзҗҶжұ з”ұеӣӣйғЁеҲҶз»„жҲҗ:
ProxyGetter:
д»ЈзҗҶиҺ·еҸ–жҺҘеҸЈпјҢзӣ®еүҚжңү5дёӘе…Қиҙ№д»ЈзҗҶжәҗпјҢжҜҸи°ғз”ЁдёҖж¬Ўе°ұдјҡжҠ“еҸ–иҝҷдёӘ5дёӘзҪ‘з«ҷзҡ„жңҖж–°д»ЈзҗҶж”ҫе…ҘDBпјҢеҸҜиҮӘиЎҢж·»еҠ йўқеӨ–зҡ„д»ЈзҗҶиҺ·еҸ–жҺҘеҸЈпјӣ
DB:
з”ЁдәҺеӯҳж”ҫд»ЈзҗҶIPпјҢзҺ°еңЁжҡӮж—¶еҸӘж”ҜжҢҒSSDBгҖӮиҮідәҺдёәд»Җд№ҲйҖүжӢ©SSDBпјҢеӨ§е®¶еҸҜд»ҘеҸӮиҖғиҝҷзҜҮж–Үз« ,дёӘдәәи§үеҫ—SSDBжҳҜдёӘдёҚй”ҷзҡ„Redisжӣҝд»Јж–№жЎҲпјҢеҰӮжһңдҪ жІЎжңүз”ЁиҝҮSSDBпјҢе®үиЈ…иө·жқҘд№ҹеҫҲз®ҖеҚ•пјҢеҸҜд»ҘеҸӮиҖғиҝҷйҮҢпјӣ
Schedule:
и®ЎеҲ’д»»еҠЎз”ЁжҲ·е®ҡж—¶еҺ»жЈҖжөӢDBдёӯзҡ„д»ЈзҗҶеҸҜз”ЁжҖ§пјҢеҲ йҷӨдёҚеҸҜз”Ёзҡ„д»ЈзҗҶгҖӮеҗҢж—¶д№ҹдјҡдё»еҠЁйҖҡиҝҮProxyGetterеҺ»иҺ·еҸ–жңҖж–°д»ЈзҗҶж”ҫе…ҘDBпјӣ
ProxyApi:
д»ЈзҗҶжұ зҡ„еӨ–йғЁжҺҘеҸЈпјҢз”ұдәҺзҺ°еңЁиҝҷд№Ҳд»ЈзҗҶжұ еҠҹиғҪжҜ”иҫғз®ҖеҚ•пјҢиҠұдёӨдёӘе°Ҹж—¶зңӢдәҶдёӢFlaskпјҢж„үеҝ«зҡ„еҶіе®ҡз”ЁFlaskжҗһе®ҡгҖӮеҠҹиғҪжҳҜз»ҷзҲ¬иҷ«жҸҗдҫӣget/delete/refreshзӯүжҺҘеҸЈпјҢж–№дҫҝзҲ¬иҷ«зӣҙжҺҘдҪҝз”ЁгҖӮ
3гҖҒд»Јз ҒжЁЎеқ—
Pythonдёӯй«ҳеұӮж¬Ўзҡ„ж•°жҚ®з»“жһ„,еҠЁжҖҒзұ»еһӢе’ҢеҠЁжҖҒз»‘е®ҡ,дҪҝеҫ—е®ғйқһеёёйҖӮеҗҲдәҺеҝ«йҖҹеә”з”ЁејҖеҸ‘,д№ҹйҖӮеҗҲдәҺдҪңдёәиғ¶ж°ҙиҜӯиЁҖиҝһжҺҘе·Іжңүзҡ„иҪҜ件йғЁд»¶гҖӮз”ЁPythonжқҘжҗһиҝҷдёӘд»ЈзҗҶIPжұ д№ҹеҫҲз®ҖеҚ•пјҢд»Јз ҒеҲҶдёә6дёӘжЁЎеқ—пјҡ
Api:
apiжҺҘеҸЈзӣёе…ід»Јз ҒпјҢзӣ®еүҚapiжҳҜз”ұFlaskе®һзҺ°пјҢд»Јз Ғд№ҹйқһеёёз®ҖеҚ•гҖӮе®ўжҲ·з«ҜиҜ·жұӮдј з»ҷFlaskпјҢFlaskи°ғз”ЁProxyManagerдёӯзҡ„е®һзҺ°пјҢеҢ…жӢ¬get/delete/refresh/get_allпјӣ
DB:
ж•°жҚ®еә“зӣёе…ід»Јз ҒпјҢзӣ®еүҚж•°жҚ®еә“жҳҜйҮҮз”ЁSSDBгҖӮд»Јз Ғз”Ёе·ҘеҺӮжЁЎејҸе®һзҺ°пјҢж–№дҫҝж—ҘеҗҺжү©еұ•е…¶д»–зұ»еһӢж•°жҚ®еә“пјӣ
Manager:
get/delete/refresh/get_allзӯүжҺҘеҸЈзҡ„е…·дҪ“е®һзҺ°зұ»пјҢзӣ®еүҚд»ЈзҗҶжұ еҸӘиҙҹиҙЈз®ЎзҗҶproxyпјҢж—ҘеҗҺеҸҜиғҪдјҡжңүжӣҙеӨҡеҠҹиғҪпјҢжҜ”еҰӮд»ЈзҗҶе’ҢзҲ¬иҷ«зҡ„з»‘е®ҡпјҢд»ЈзҗҶе’ҢиҙҰеҸ·зҡ„з»‘е®ҡзӯүзӯүпјӣ
ProxyGetter:
д»ЈзҗҶиҺ·еҸ–зҡ„зӣёе…ід»Јз ҒпјҢзӣ®еүҚжҠ“еҸ–дәҶеҝ«д»ЈзҗҶгҖҒд»ЈзҗҶ66гҖҒжңүд»ЈзҗҶгҖҒиҘҝеҲәд»ЈзҗҶгҖҒguobanjiaиҝҷдёӘдә”дёӘзҪ‘з«ҷзҡ„е…Қиҙ№д»ЈзҗҶпјҢз»ҸжөӢиҜ•иҝҷдёӘ5дёӘзҪ‘з«ҷжҜҸеӨ©жӣҙж–°зҡ„еҸҜз”Ёд»ЈзҗҶеҸӘжңүе…ӯдёғеҚҒдёӘпјҢеҪ“然д№ҹж”ҜжҢҒиҮӘе·ұжү©еұ•д»ЈзҗҶжҺҘеҸЈпјӣ
Schedule:
е®ҡж—¶д»»еҠЎзӣёе…ід»Јз ҒпјҢзҺ°еңЁеҸӘжҳҜе®һзҺ°е®ҡж—¶еҺ»еҲ·ж–°д»Јз ҒпјҢ并йӘҢиҜҒеҸҜз”Ёд»ЈзҗҶпјҢйҮҮз”ЁеӨҡиҝӣзЁӢж–№ејҸпјӣ
Util:
еӯҳж”ҫдёҖдәӣе…¬е…ұзҡ„жЁЎеқ—ж–№жі•жҲ–еҮҪж•°пјҢеҢ…еҗ«GetConfig:иҜ»еҸ–й…ҚзҪ®ж–Ү件config.iniзҡ„зұ»пјҢConfigParse: йӣҶжҲҗйҮҚеҶҷConfigParserзҡ„зұ»пјҢдҪҝе…¶еҜ№еӨ§е°ҸеҶҷж•Ҹж„ҹпјҢ Singleton:е®һзҺ°еҚ•дҫӢпјҢLazyProperty:е®һзҺ°зұ»еұһжҖ§жғ°жҖ§и®Ўз®—гҖӮзӯүзӯүпјӣ
е…¶д»–ж–Ү件:
й…ҚзҪ®ж–Ү件:Config.ini,ж•°жҚ®еә“й…ҚзҪ®е’Ңд»ЈзҗҶиҺ·еҸ–жҺҘеҸЈй…ҚзҪ®пјҢеҸҜд»ҘеңЁGetFreeProxyдёӯж·»еҠ ж–°зҡ„д»ЈзҗҶиҺ·еҸ–ж–№жі•пјҢ并еңЁConfig.iniдёӯжіЁеҶҢеҚіеҸҜдҪҝз”Ёпјӣ
4гҖҒе®үиЈ…
дёӢиҪҪд»Јз Ғ:
Python
git clone git@github.com:jhao104/proxy_pool.git жҲ–иҖ…зӣҙжҺҘеҲ°https://github.com/jhao104/proxy_pool дёӢиҪҪzipж–Ү件 git clone git@github.com:jhao104/proxy_pool.git жҲ–иҖ…зӣҙжҺҘеҲ°https://github.com/jhao104/proxy_pool дёӢиҪҪzipж–Ү件
е®үиЈ…дҫқиө–:
Python
pip install -r requirements.txt pip install -r requirements.txt
еҗҜеҠЁ:
Python
йңҖиҰҒеҲҶеҲ«еҗҜеҠЁе®ҡж—¶д»»еҠЎе’Ңapi еҲ°Config.iniдёӯй…ҚзҪ®дҪ зҡ„SSDB еҲ°Scheduleзӣ®еҪ•дёӢ: >>>python ProxyRefreshSchedule.py еҲ°Apiзӣ®еҪ•дёӢ: >>>python ProxyApi.py йңҖиҰҒеҲҶеҲ«еҗҜеҠЁе®ҡж—¶д»»еҠЎе’Ңapi еҲ°Config.iniдёӯй…ҚзҪ®дҪ зҡ„SSDB еҲ°Scheduleзӣ®еҪ•дёӢ: >>>python ProxyRefreshSchedule.py еҲ°Apiзӣ®еҪ•дёӢ: >>>python ProxyApi.py
5гҖҒдҪҝз”Ё
е®ҡж—¶д»»еҠЎеҗҜеҠЁеҗҺпјҢдјҡйҖҡиҝҮд»ЈзҗҶиҺ·еҸ–ж–№жі•fetchжүҖжңүд»ЈзҗҶж”ҫе…Ҙж•°жҚ®еә“并йӘҢиҜҒгҖӮжӯӨеҗҺй»ҳи®ӨжҜҸ20еҲҶй’ҹдјҡйҮҚеӨҚжү§иЎҢдёҖж¬ЎгҖӮе®ҡж—¶д»»еҠЎеҗҜеҠЁеӨ§жҰӮдёҖдёӨеҲҶй’ҹеҗҺпјҢдҫҝеҸҜеңЁSSDBдёӯзңӢеҲ°еҲ·ж–°еҮәжқҘзҡ„еҸҜз”Ёзҡ„д»ЈзҗҶпјҡ
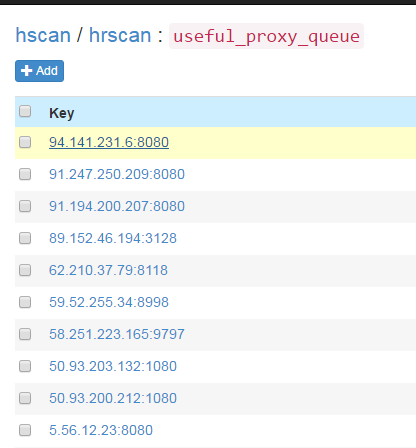
useful_proxy
еҗҜеҠЁProxyApi.pyеҗҺеҚіеҸҜеңЁжөҸи§ҲеҷЁдёӯдҪҝз”ЁжҺҘеҸЈиҺ·еҸ–д»ЈзҗҶпјҢдёҖдёӢжҳҜжөҸи§ҲеҷЁдёӯзҡ„жҲӘеӣҫ:
indexйЎөйқў:
getйЎөйқўпјҡ
get_allйЎөйқўпјҡ

зҲ¬иҷ«дёӯдҪҝз”ЁпјҢеҰӮжһңиҰҒеңЁзҲ¬иҷ«д»Јз ҒдёӯдҪҝз”Ёзҡ„иҜқпјҢ еҸҜд»Ҙе°ҶжӯӨapiе°ҒиЈ…жҲҗеҮҪж•°зӣҙжҺҘдҪҝз”ЁпјҢдҫӢеҰӮ:
Python
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/").content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/").content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
6гҖҒжңҖеҗҺ
ж—¶й—ҙд»“дҝғпјҢеҠҹиғҪе’Ңд»Јз ҒйғҪжҜ”иҫғз®ҖйҷӢпјҢд»ҘеҗҺжңүж—¶й—ҙеҶҚж”№иҝӣгҖӮе–ңж¬ўзҡ„еңЁgithubдёҠз»ҷдёӘstarгҖӮж„ҹи°ўпјҒ
githubйЎ№зӣ®ең°еқҖпјҡhttps://github.com/jhao104/proxy_pool
жҖ»з»“
д»ҘдёҠжүҖиҝ°жҳҜе°Ҹзј–з»ҷеӨ§е®¶д»Ӣз»Қзҡ„PythonзҲ¬иҷ«д»ЈзҗҶжұ жңҚеҠЎпјҢеёҢжңӣеҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңеӨ§е®¶жңүд»»дҪ•з–‘й—®иҜ·з»ҷжҲ‘з•ҷиЁҖпјҢе°Ҹзј–дјҡеҸҠж—¶еӣһеӨҚеӨ§е®¶зҡ„гҖӮеңЁжӯӨд№ҹйқһеёёж„ҹи°ўеӨ§е®¶еҜ№дәҝйҖҹдә‘зҪ‘з«ҷзҡ„ж”ҜжҢҒпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ