您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要为大家展示了“Tensorflow可视化工具Tensorboard怎么用”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Tensorflow可视化工具Tensorboard怎么用”这篇文章吧。
当使用Tensorflow训练大量深层的神经网络时,我们希望去跟踪神经网络的整个训练过程中的信息,比如迭代的过程中每一层参数是如何变化与分布的,比如每次循环参数更新后模型在测试集与训练集上的准确率是如何的,比如损失值的变化情况,等等。如果能在训练的过程中将一些信息加以记录并可视化得表现出来,是不是对我们探索模型有更深的帮助与理解呢?
Tensorflow官方推出了可视化工具Tensorboard,可以帮助我们实现以上功能,它可以将模型训练过程中的各种数据汇总起来存在自定义的路径与日志文件中,然后在指定的web端可视化地展现这些信息。
1. Tensorboard介绍
1.1 Tensorboard的数据形式
Tensorboard可以记录与展示以下数据形式:
(1)标量Scalars
(2)图片Images
(3)音频Audio
(4)计算图Graph
(5)数据分布Distribution
(6)直方图Histograms
(7)嵌入向量Embeddings
1.2 Tensorboard的可视化过程
(1)首先肯定是先建立一个graph,你想从这个graph中获取某些数据的信息
(2)确定要在graph中的哪些节点放置summary operations以记录信息
使用tf.summary.scalar记录标量
使用tf.summary.histogram记录数据的直方图
使用tf.summary.distribution记录数据的分布图
使用tf.summary.image记录图像数据
….
(3)operations并不会去真的执行计算,除非你告诉他们需要去run,或者它被其他的需要run的operation所依赖。而我们上一步创建的这些summary operations其实并不被其他节点依赖,因此,我们需要特地去运行所有的summary节点。但是呢,一份程序下来可能有超多这样的summary 节点,要手动一个一个去启动自然是及其繁琐的,因此我们可以使用tf.summary.merge_all去将所有summary节点合并成一个节点,只要运行这个节点,就能产生所有我们之前设置的summary data。
(4)使用tf.summary.FileWriter将运行后输出的数据都保存到本地磁盘中
(5)运行整个程序,并在命令行输入运行tensorboard的指令,之后打开web端可查看可视化的结果
2.Tensorboard使用案例
不出所料呢,我们还是使用最基础的识别手写字体的案例~
不过本案例也是先不去追求多美好的模型,只是建立一个简单的神经网络,让大家了解如何使用Tensorboard。
2.1 导入包,定义超参数,载入数据
(1)首先还是导入需要的包:
from __future__ import absolute_import from __future__ import division from __future__ import print_function import argparse import sys import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data
(2)定义固定的超参数,方便待使用时直接传入。如果你问,这个超参数为啥要这样设定,如何选择最优的超参数?这个问题此处先不讨论,超参数的选择在机器学习建模中最常用的方法就是“交叉验证法”。而现在假设我们已经获得了最优的超参数,设置学利率为0.001,dropout的保留节点比例为0.9,最大循环次数为1000.
另外,还要设置两个路径,第一个是数据下载下来存放的地方,一个是summary输出保存的地方。
max_step = 1000 # 最大迭代次数 learning_rate = 0.001 # 学习率 dropout = 0.9 # dropout时随机保留神经元的比例 data_dir = '' # 样本数据存储的路径 log_dir = '' # 输出日志保存的路径
(3)接着加载数据,下载数据是直接调用了tensorflow提供的函数read_data_sets,输入两个参数,第一个是下载到数据存储的路径,第二个one_hot表示是否要将类别标签进行独热编码。它首先回去找制定目录下有没有这个数据文件,没有的话才去下载,有的话就直接读取。所以第一次执行这个命令,速度会比较慢。
mnist = input_data.read_data_sets(data_dir,one_hot=True)
2.2 创建特征与标签的占位符,保存输入的图片数据到summary
(1)创建tensorflow的默认会话:
sess = tf.InteractiveSession()
(2)创建输入数据的占位符,分别创建特征数据x,标签数据y_
在tf.placeholder()函数中传入了3个参数,第一个是定义数据类型为float32;第二个是数据的大小,特征数据是大小784的向量,标签数据是大小为10的向量,None表示不定死大小,到时候可以传入任何数量的样本;第3个参数是这个占位符的名称。
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x-input')
y_ = tf.placeholder(tf.float32, [None, 10], name='y-input')(3)使用tf.summary.image保存图像信息
特征数据其实就是图像的像素数据拉升成一个1*784的向量,现在如果想在tensorboard上还原出输入的特征数据对应的图片,就需要将拉升的向量转变成28 * 28 * 1的原始像素了,于是可以用tf.reshape()直接重新调整特征数据的维度:
将输入的数据转换成[28 * 28 * 1]的shape,存储成另一个tensor,命名为image_shaped_input。
为了能使图片在tensorbord上展示出来,使用tf.summary.image将图片数据汇总给tensorbord。
tf.summary.image()中传入的第一个参数是命名,第二个是图片数据,第三个是最多展示的张数,此处为10张
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)2.3 创建初始化参数的方法,与参数信息汇总到summary的方法
(1)在构建神经网络模型中,每一层中都需要去初始化参数w,b,为了使代码简介美观,最好将初始化参数的过程封装成方法function。
创建初始化权重w的方法,生成大小等于传入的shape参数,标准差为0.1,正态分布的随机数,并且将它转换成tensorflow中的variable返回。
def weight_variable(shape): """Create a weight variable with appropriate initialization.""" initial = tf.truncated_normal(shape, stddev=0.1) return tf.Variable(initial)
创建初始换偏执项b的方法,生成大小为传入参数shape的常数0.1,并将其转换成tensorflow的variable并返回
def bias_variable(shape): """Create a bias variable with appropriate initialization.""" initial = tf.constant(0.1, shape=shape) return tf.Variable(initial)
(2)我们知道,在训练的过程在参数是不断地在改变和优化的,我们往往想知道每次迭代后参数都做了哪些变化,可以将参数的信息展现在tenorbord上,因此我们专门写一个方法来收录每次的参数信息。
def variable_summaries(var):
"""Attach a lot of summaries to a Tensor (for TensorBoard visualization)."""
with tf.name_scope('summaries'):
# 计算参数的均值,并使用tf.summary.scaler记录
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
# 计算参数的标准差
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
# 使用tf.summary.scaler记录记录下标准差,最大值,最小值
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
# 用直方图记录参数的分布
tf.summary.histogram('histogram', var)2.4 构建神经网络层
(1)创建第一层隐藏层
创建一个构建隐藏层的方法,输入的参数有:
input_tensor:特征数据
input_dim:输入数据的维度大小
output_dim:输出数据的维度大小(=隐层神经元个数)
layer_name:命名空间
act=tf.nn.relu:激活函数(默认是relu)
def nn_layer(input_tensor, input_dim, output_dim, layer_name, act=tf.nn.relu):
"""Reusable code for making a simple neural net layer.
It does a matrix multiply, bias add, and then uses relu to nonlinearize.
It also sets up name scoping so that the resultant graph is easy to read,
and adds a number of summary ops.
"""
# 设置命名空间
with tf.name_scope(layer_name):
# 调用之前的方法初始化权重w,并且调用参数信息的记录方法,记录w的信息
with tf.name_scope('weights'):
weights = weight_variable([input_dim, output_dim])
variable_summaries(weights)
# 调用之前的方法初始化权重b,并且调用参数信息的记录方法,记录b的信息
with tf.name_scope('biases'):
biases = bias_variable([output_dim])
variable_summaries(biases)
# 执行wx+b的线性计算,并且用直方图记录下来
with tf.name_scope('linear_compute'):
preactivate = tf.matmul(input_tensor, weights) + biases
tf.summary.histogram('linear', preactivate)
# 将线性输出经过激励函数,并将输出也用直方图记录下来
activations = act(preactivate, name='activation')
tf.summary.histogram('activations', activations)
# 返回激励层的最终输出
return activations调用隐层创建函数创建一个隐藏层:输入的维度是特征的维度784,神经元个数是500,也就是输出的维度。
hidden1 = nn_layer(x, 784, 500, 'layer1')
(2)创建一个dropout层,,随机关闭掉hidden1的一些神经元,并记录keep_prob
with tf.name_scope('dropout'):
keep_prob = tf.placeholder(tf.float32)
tf.summary.scalar('dropout_keep_probability', keep_prob)
dropped = tf.nn.dropout(hidden1, keep_prob)(3)创建一个输出层,输入的维度是上一层的输出:500,输出的维度是分类的类别种类:10,激活函数设置为全等映射identity.(暂且先别使用softmax,会放在之后的损失函数中一起计算)
y = nn_layer(dropped, 500, 10, 'layer2', act=tf.identity)
2.5 创建损失函数
使用tf.nn.softmax_cross_entropy_with_logits来计算softmax并计算交叉熵损失,并且求均值作为最终的损失值。
with tf.name_scope('loss'):
# 计算交叉熵损失(每个样本都会有一个损失)
diff = tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y)
with tf.name_scope('total'):
# 计算所有样本交叉熵损失的均值
cross_entropy = tf.reduce_mean(diff)
tf.summary.scalar('loss', cross_entropy)2.6 训练,并计算准确率
(1)使用AdamOptimizer优化器训练模型,最小化交叉熵损失
with tf.name_scope('train'):
train_step = tf.train.AdamOptimizer(learning_rate).minimize(
cross_entropy)(2)计算准确率,并用tf.summary.scalar记录准确率
with tf.name_scope('accuracy'):
with tf.name_scope('correct_prediction'):
# 分别将预测和真实的标签中取出最大值的索引,弱相同则返回1(true),不同则返回0(false)
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
with tf.name_scope('accuracy'):
# 求均值即为准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)2.7 合并summary operation, 运行初始化变量
将所有的summaries合并,并且将它们写到之前定义的log_dir路径
# summaries合并 merged = tf.summary.merge_all() # 写到指定的磁盘路径中 train_writer = tf.summary.FileWriter(log_dir + '/train', sess.graph) test_writer = tf.summary.FileWriter(log_dir + '/test') # 运行初始化所有变量 tf.global_variables_initializer().run()
2.8 准备训练与测试的两个数据,循环执行整个graph进行训练与评估
(1)现在我们要获取之后要喂人的数据.
如果是train==true,就从mnist.train中获取一个batch样本,并且设置dropout值;
如果是不是train==false,则获取minist.test的测试数据,并且设置keep_prob为1,即保留所有神经元开启。
def feed_dict(train):
"""Make a TensorFlow feed_dict: maps data onto Tensor placeholders."""
if train:
xs, ys = mnist.train.next_batch(100)
k = dropout
else:
xs, ys = mnist.test.images, mnist.test.labels
k = 1.0
return {x: xs, y_: ys, keep_prob: k}(2)开始训练模型。
每隔10步,就进行一次merge, 并打印一次测试数据集的准确率,然后将测试数据集的各种summary信息写进日志中。
每隔100步,记录原信息
其他每一步时都记录下训练集的summary信息并写到日志中。
for i in range(max_steps):
if i % 10 == 0: # 记录测试集的summary与accuracy
summary, acc = sess.run([merged, accuracy], feed_dict=feed_dict(False))
test_writer.add_summary(summary, i)
print('Accuracy at step %s: %s' % (i, acc))
else: # 记录训练集的summary
if i % 100 == 99: # Record execution stats
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, train_step],
feed_dict=feed_dict(True),
options=run_options,
run_metadata=run_metadata)
train_writer.add_run_metadata(run_metadata, 'step%03d' % i)
train_writer.add_summary(summary, i)
print('Adding run metadata for', i)
else: # Record a summary
summary, _ = sess.run([merged, train_step], feed_dict=feed_dict(True))
train_writer.add_summary(summary, i)
train_writer.close()
test_writer.close()2.9 执行程序,tensorboard生成可视化
(1)运行整个程序,在程序中定义的summary node就会将要记录的信息全部保存在指定的logdir路径中了,训练的记录会存一份文件,测试的记录会存一份文件。
(2)进入linux命令行,运行以下代码,等号后面加上summary日志保存的路径(在程序第一步中就事先自定义了)
tensorboard --logdir=
执行命令之后会出现一条信息,上面有网址,将网址在浏览器中打开就可以看到我们定义的可视化信息了。:
Starting TensorBoard 41 on port 6006 (You can navigate to http://127.0.1.1:6006)
将http://127.0.1.1:6006在浏览器中打开,成功的话如下:
于是我们可以从这个web端看到所有程序中定义的可视化信息了。
2.10 Tensorboard Web端解释
看到最上面橙色一栏的菜单,分别有7个栏目,都一一对应着我们程序中定义信息的类型。
(1)SCALARS
展示的是标量的信息,我程序中用tf.summary.scalars()定义的信息都会在这个窗口。
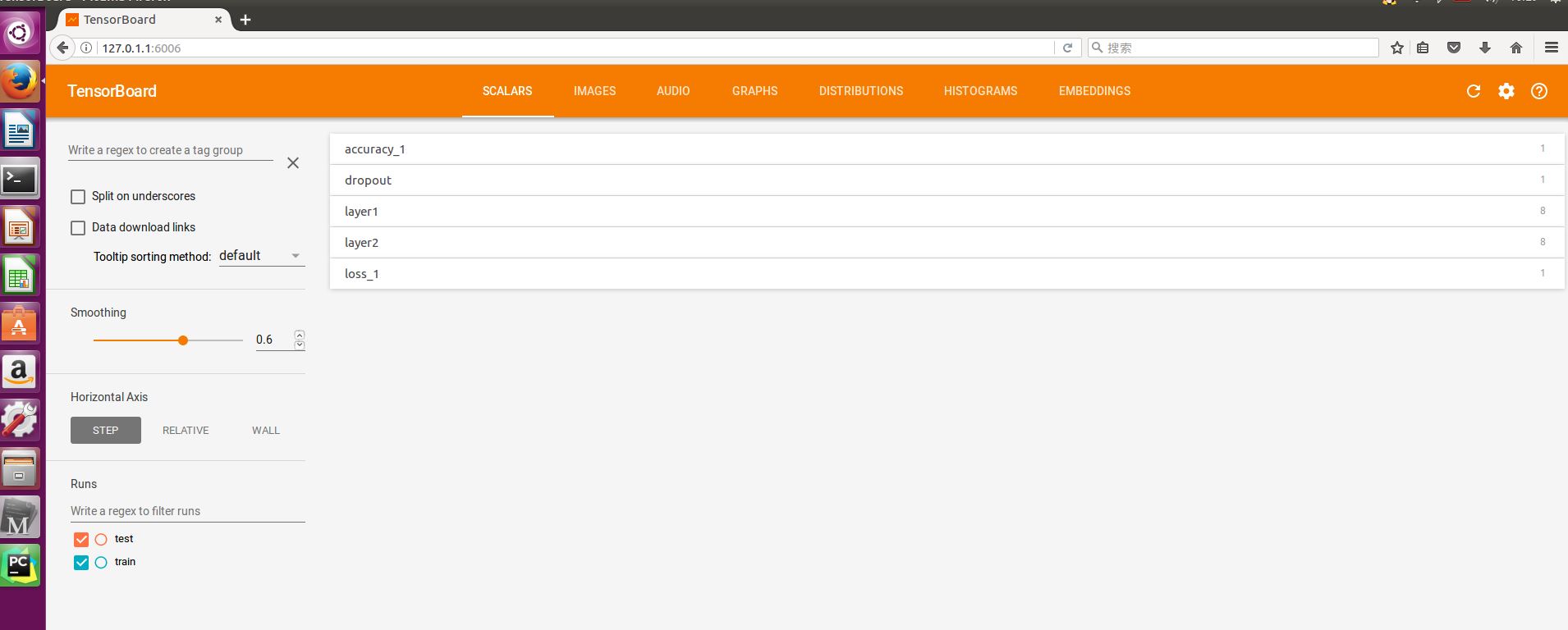
回顾本文程序中定义的标量有:准确率accuracy,dropout的保留率,隐藏层中的参数信息,已经交叉熵损失。这些都在SCLARS窗口下显示出来了。
点开accuracy,红线表示test集的结果,蓝线表示train集的结果,可以看到随着循环次数的增加,两者的准确度也在通趋势增加,值得注意的是,在0到100次的循环中准确率快速激增,100次之后保持微弱地上升趋势,直达1000次时会到达0.967左右
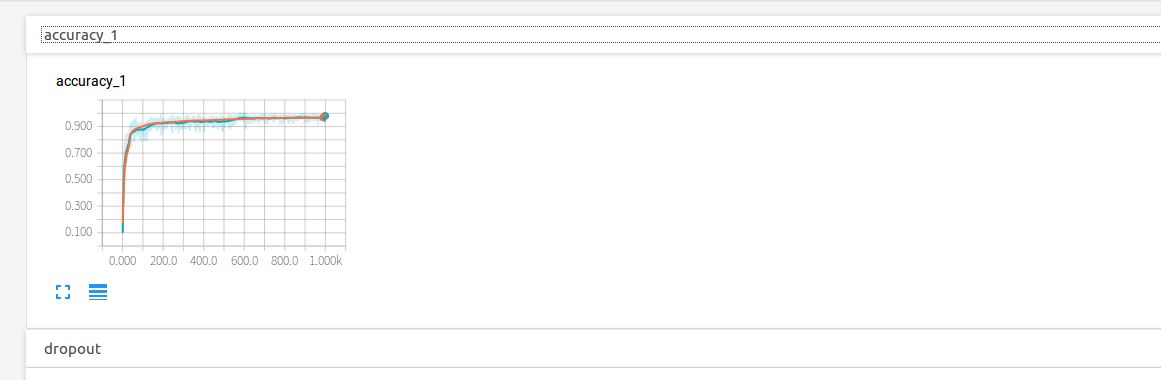
点开dropout,红线表示的测试集上的保留率始终是1,蓝线始终是0.9
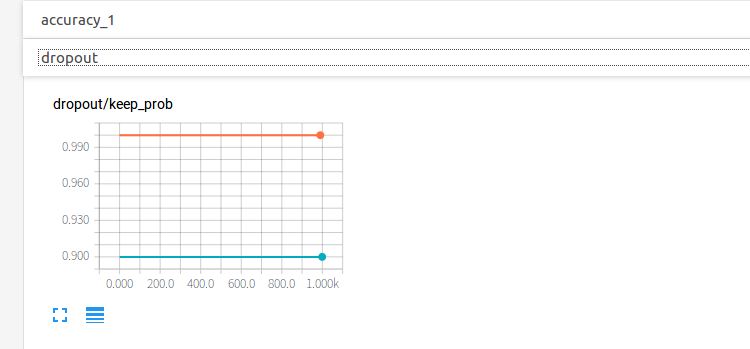
点开layer1,查看第一个隐藏层的参数信息。
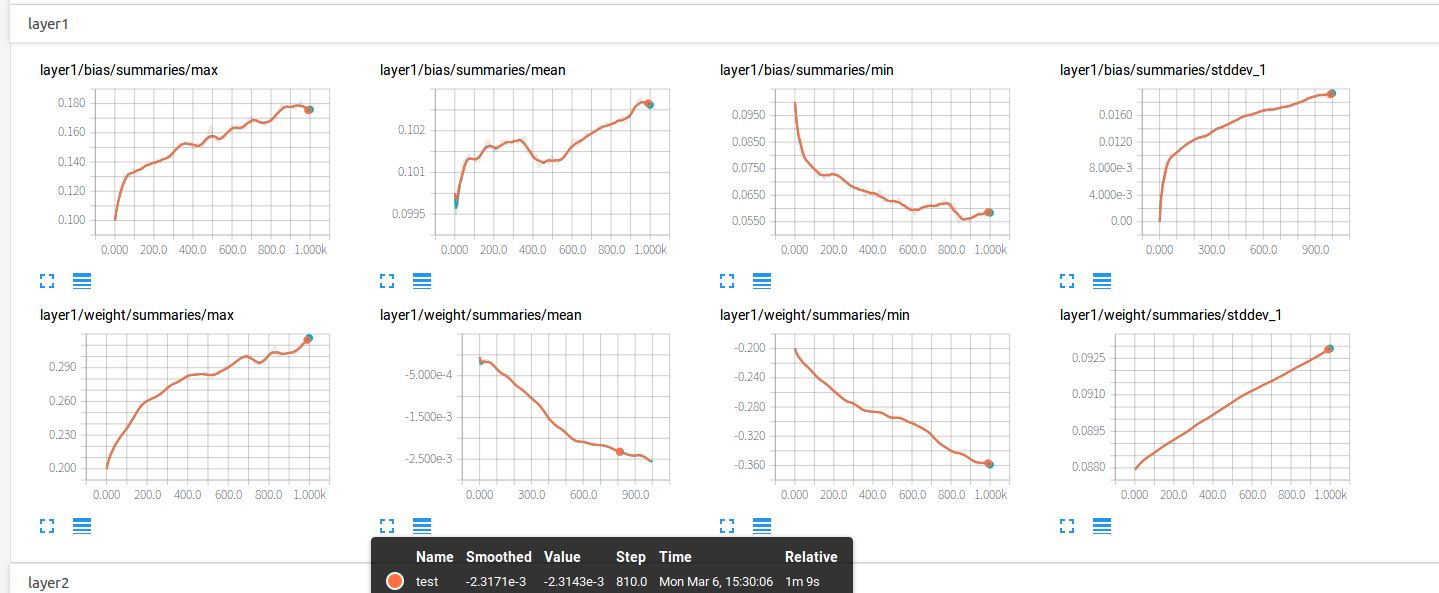
以上,第一排是偏执项b的信息,随着迭代的加深,最大值越来越大,最小值越来越小,与此同时,也伴随着方差越来越大,这样的情况是我们愿意看到的,神经元之间的参数差异越来越大。因为理想的情况下每个神经元都应该去关注不同的特征,所以他们的参数也应有所不同。
第二排是权值w的信息,同理,最大值,最小值,标准差也都有与b相同的趋势,神经元之间的差异越来越明显。w的均值初始化的时候是0,随着迭代其绝对值也越来越大。
点开layer2
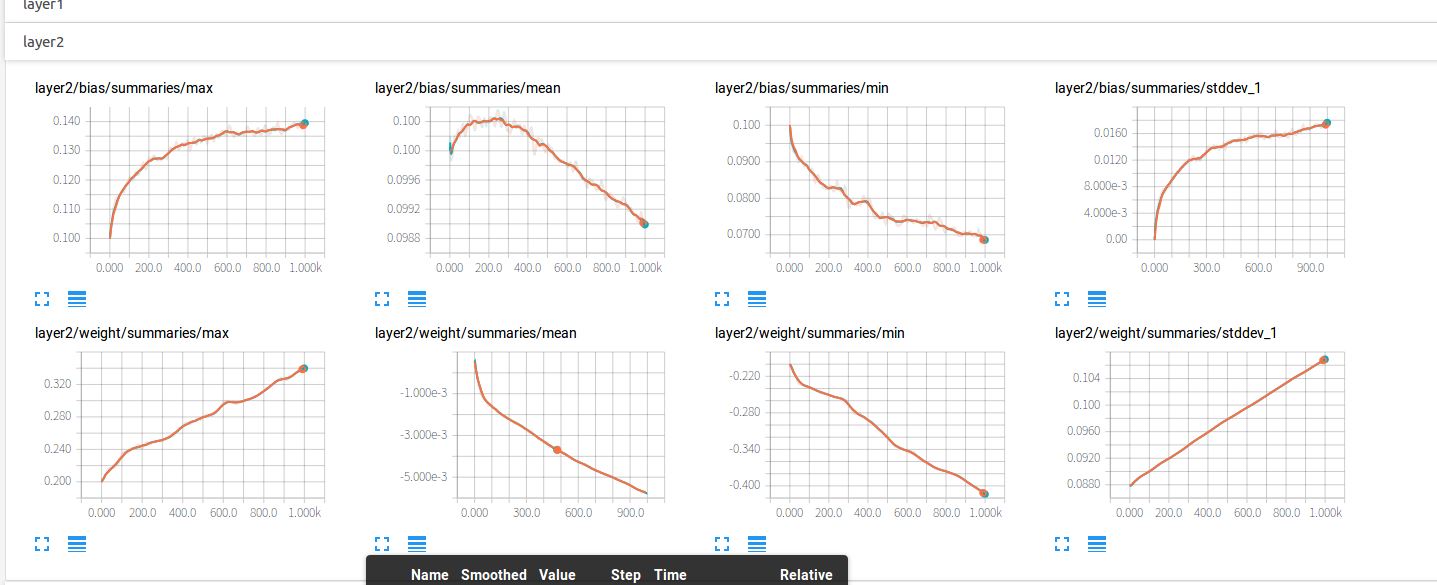
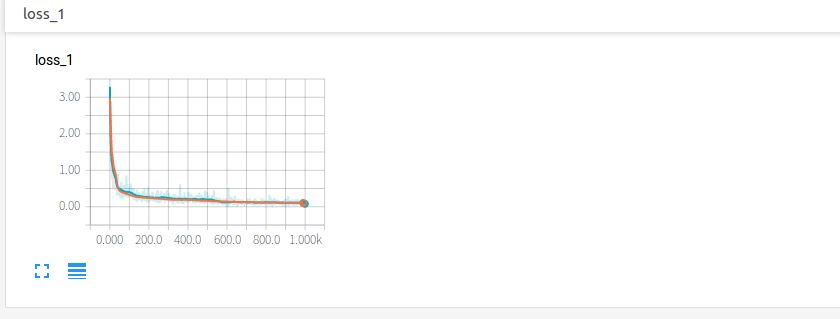
点开loss,可见损失的降低趋势。
(2)IMAGES
在程序中我们设置了一处保存了图像信息,就是在转变了输入特征的shape,然后记录到了image中,于是在tensorflow中就会还原出原始的图片了:
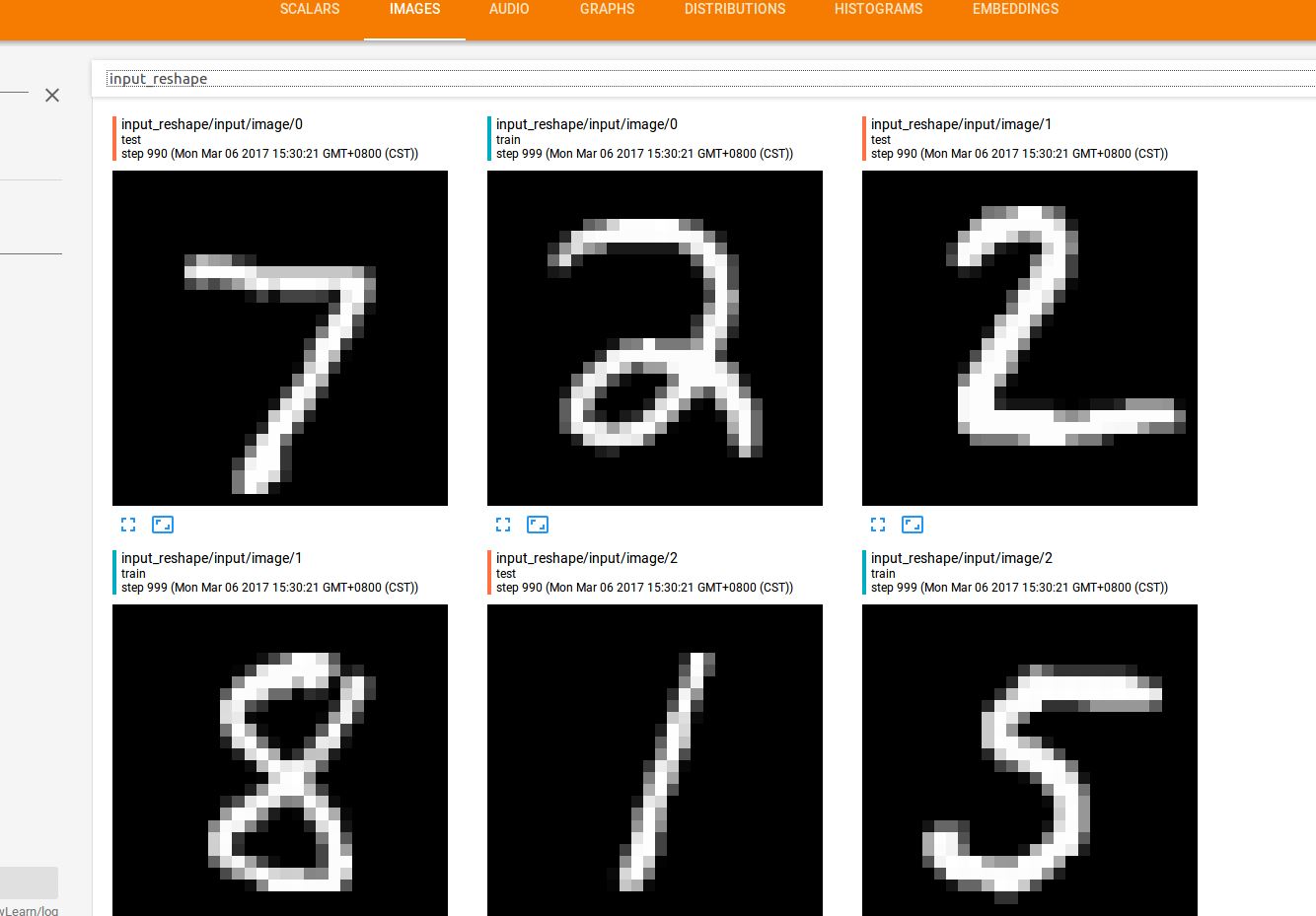
整个窗口总共展现了10张图片(根据代码中的参数10)
(3)AUDIO
这里展示的是声音的信息,但本案例中没有涉及到声音的。
(4)GRAPHS
这里展示的是整个训练过程的计算图graph,从中我们可以清洗地看到整个程序的逻辑与过程。
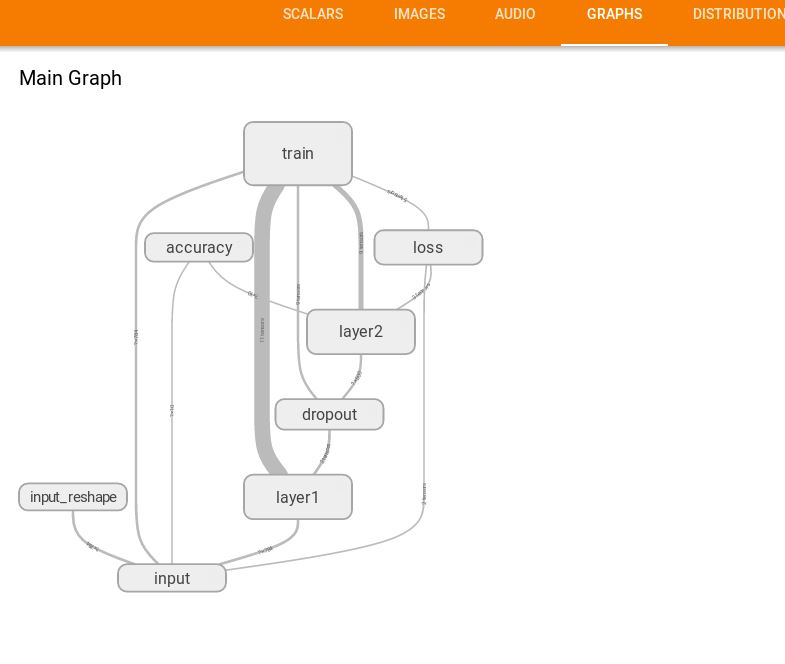
单击某个节点,可以查看属性,输入,输出等信息
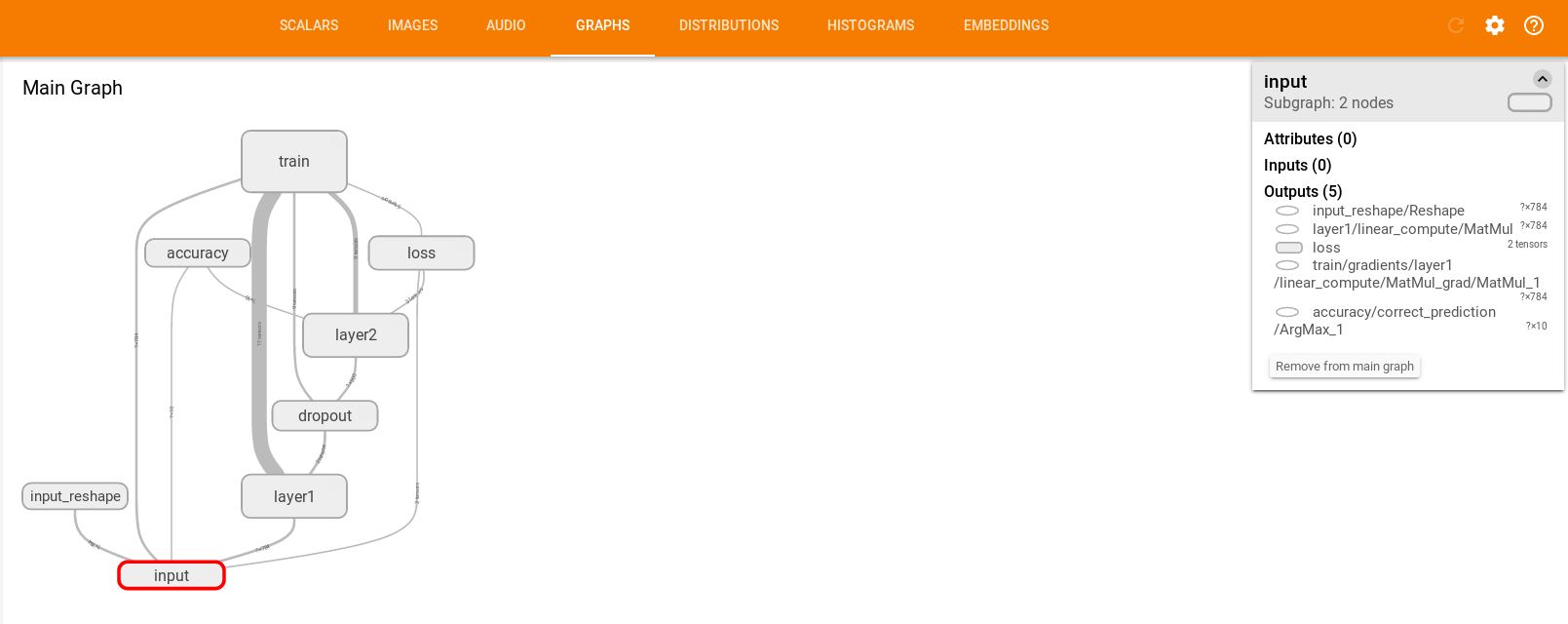
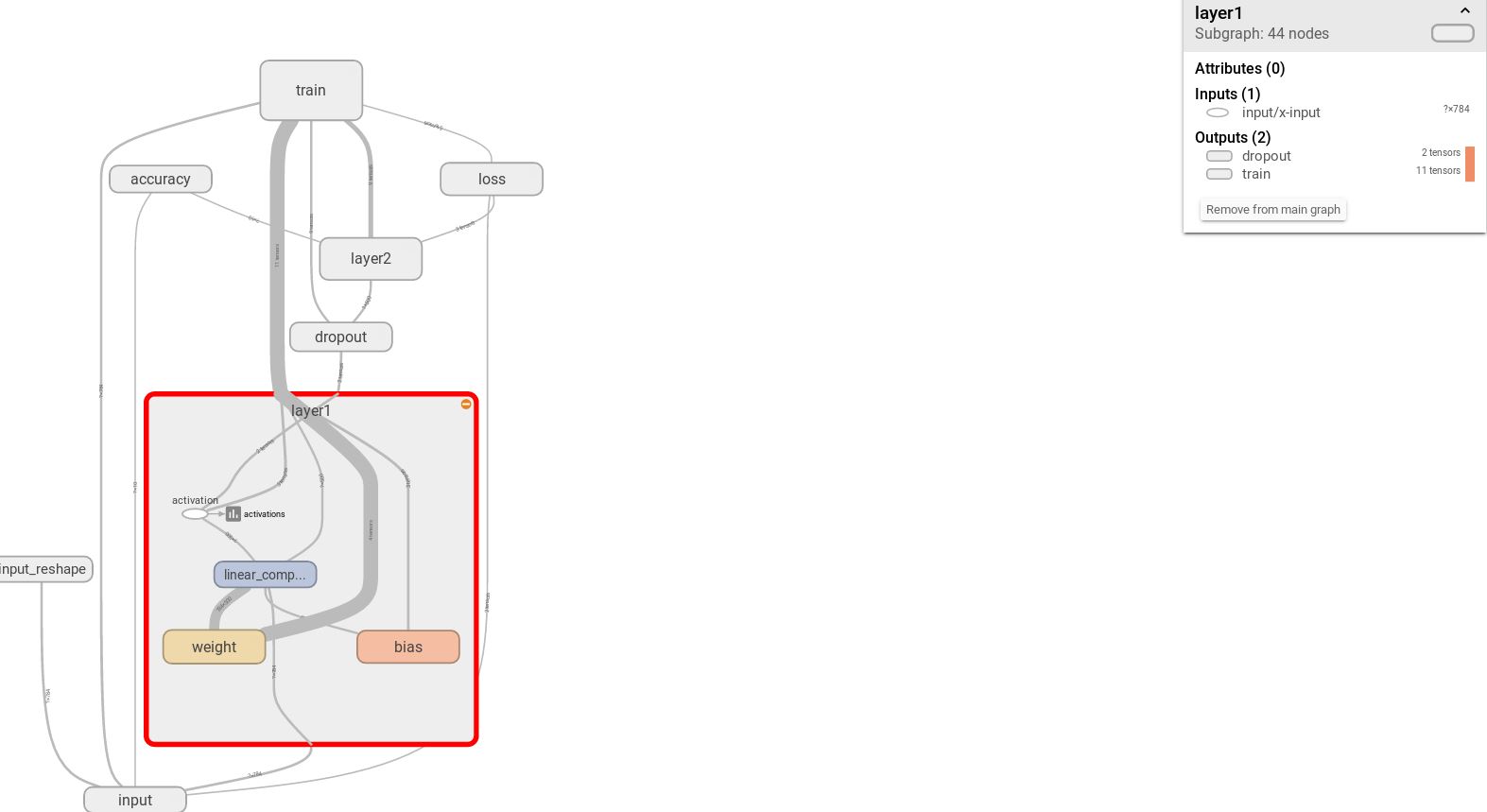
单击节点上的“+”字样,可以看到该节点的内部信息。
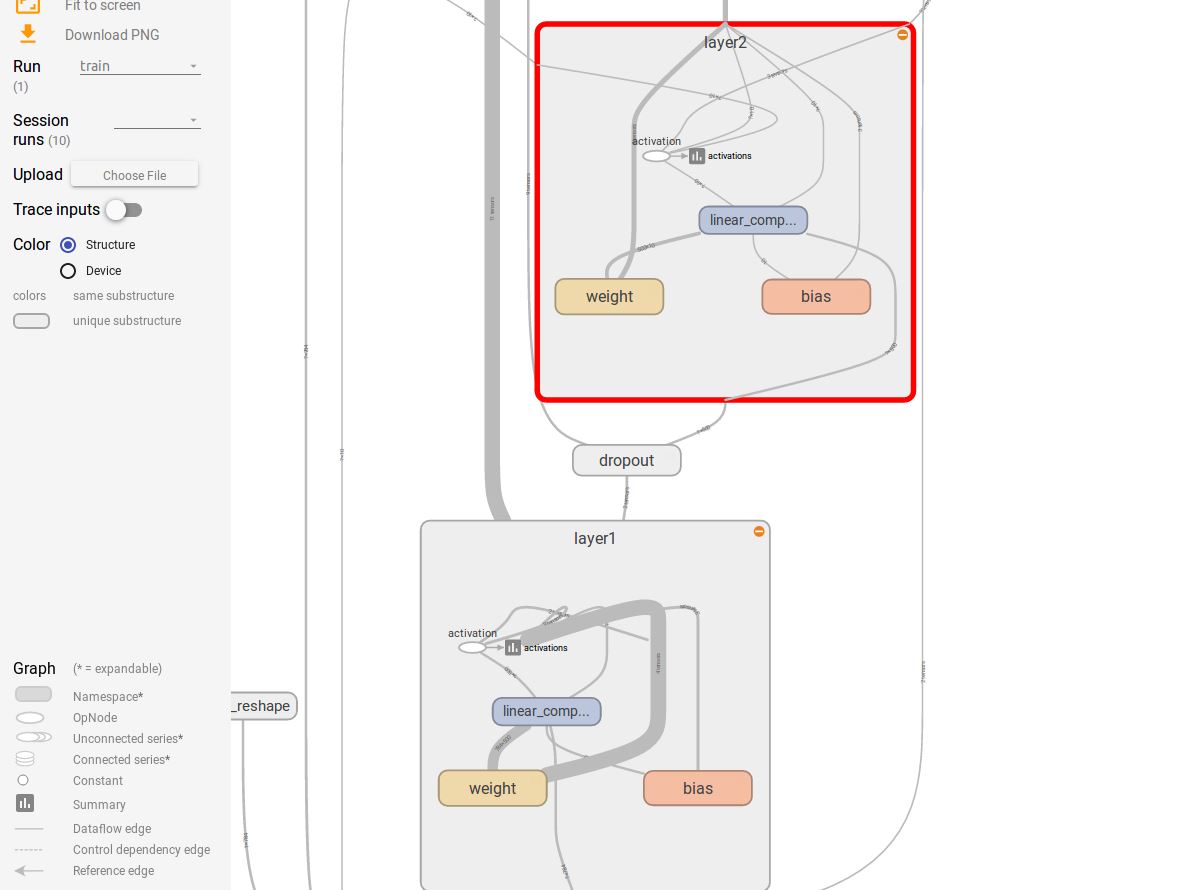
另外还可以选择图像颜色的两者模型,基于结构的模式,相同的节点会有同样的颜色,基于预算硬件的,同一个硬件上的会有相同颜色。
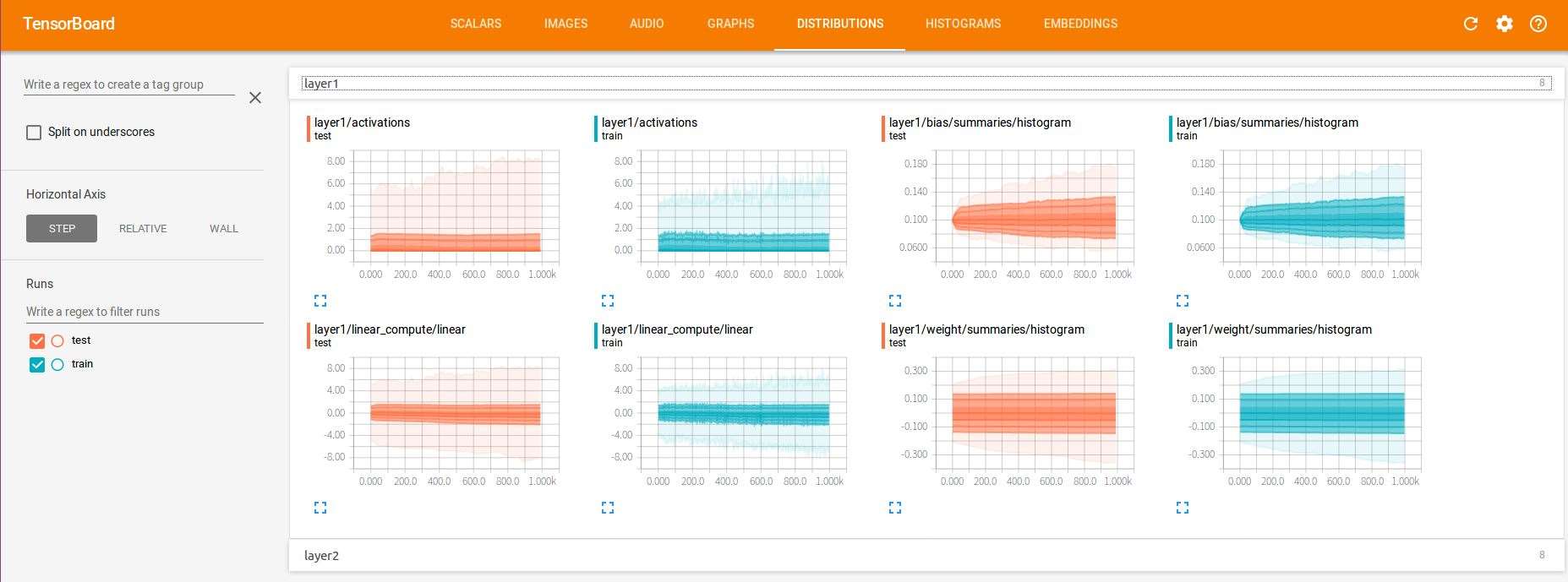
(5)DISTRIBUTIONS
这里查看的是神经元输出的分布,有激活函数之前的分布,激活函数之后的分布等。
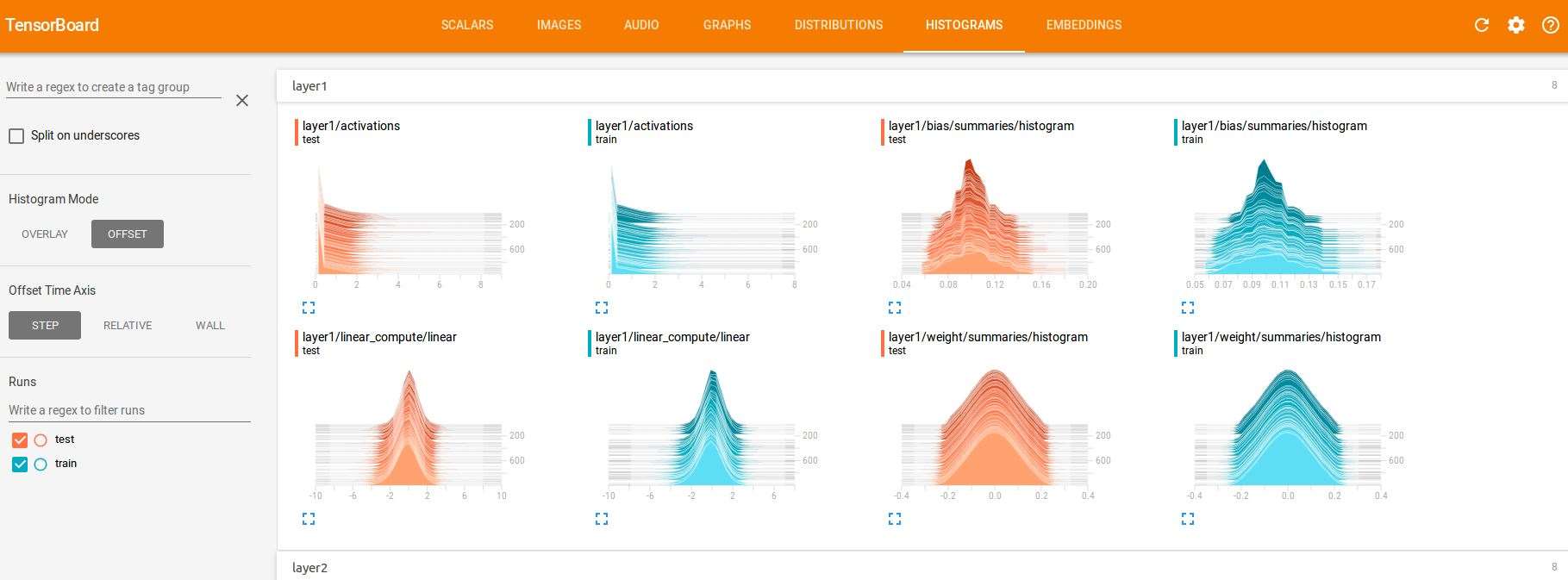
(6)HISTOGRAMS
也可以看以上数据的直方图
以上是“Tensorflow可视化工具Tensorboard怎么用”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。