жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
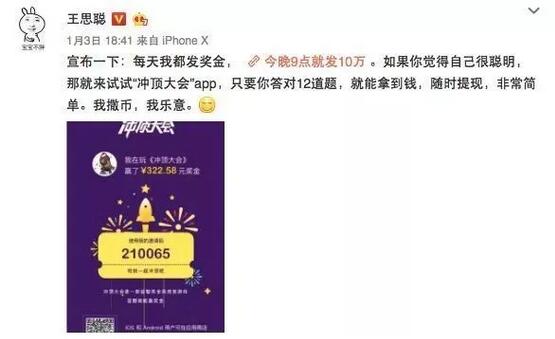
2018е№ҙ1жңҲ3ж—ҘпјҢзҺӢжҖқиҒӘиў«иҝ«еҠЁз”ЁиҮӘе·ұзҡ„еҫ®еҚҡпјҢдёәдёҖдёӘиҜһз”ҹдёҚеҲ°10еӨ©зҡ„Appжү“дәҶе№ҝе‘ҠпјҢвҖңжҜҸеӨ©жҲ‘йғҪеҸ‘еҘ–йҮ‘пјҢд»Ҡжҷҡ9зӮ№е°ұеҸ‘10дёҮвҖқгҖӮеҜ№д»–иҖҢиЁҖпјҢиҝҷеӨ©зҡ„еҫ®еҚҡ并йқһз”ҹж—Ҙе®ҙдјҡпјҢиҖҢжҳҜжҲҳеңәгҖӮзҺӢжҖқиҒӘзҡ„дёҖеҲҷеҫ®еҚҡејҖеҗҜдәҶвҖңе…Ёж°‘з«һзӯ”вҖқзұ»APPзҡ„зҲҶзәўд№Ӣи·ҜгҖӮ
дёҖж—¶й—ҙпјҢзӣҙж’ӯе·ЁеӨҙ们йғҪи·ҹдёҠвҖңзҺӢж Ўй•ҝвҖқзҡ„иҠӮеҘҸпјҢвҖңеҶІйЎ¶еӨ§дјҡвҖқд№ӢеӨ–пјҢжҳ е®ўж——дёӢзҡ„вҖңиҠқеЈ«и¶…дәәвҖқгҖҒд»Ҡж—ҘеӨҙжқЎж——дёӢзҡ„вҖңзҷҫдёҮиӢұйӣ„вҖқе’ҢиҠұжӨ’зӣҙж’ӯж——дёӢзҡ„вҖңзҷҫдёҮдҪңжҲҳвҖқзә·зә·дә®зӣёпјҢжҜҸеӨ©зӢӮж’’зҷҫдёҮзҺ°йҮ‘гҖӮ
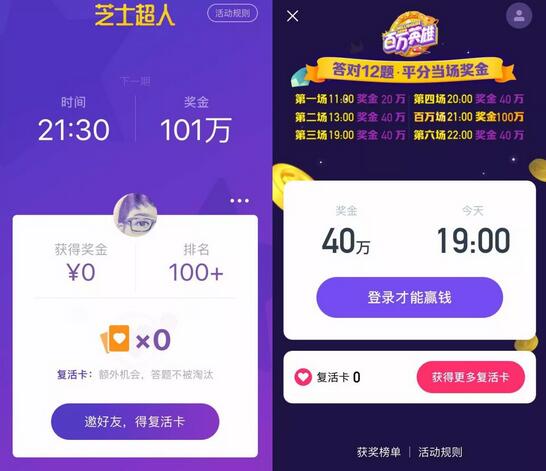
вҖңеҶІйЎ¶еӨ§дјҡвҖқгҖҒвҖңиҠқеЈ«и¶…дәәвҖқгҖҒвҖңзҷҫдёҮиӢұйӣ„вҖқзӯүзҹҘиҜҶз«һзӯ”жёёжҲҸзҒ«дәҶпјҢеҘ–йҮ‘ж•°йўқд№ҹд»ҺжңҖеҲқзҡ„дәәж°‘еёҒ5дёҮгҖҒ10дёҮж¶ЁеҲ°дәҶ100дёҮгҖҒ101дёҮгҖӮ
дёәдәҶиғҪеӨҹе…ЁйғЁзӯ”еҜ№12йҒ“йўҳпјҢе№іеҲҶж•°йўқеҰӮжӯӨеәһеӨ§зҡ„еҘ–йҮ‘жұ пјҢеҸӮиөӣиҖ…ејҖе§Ӣжғіж–№и®ҫжі•жҸҗй«ҳиҮӘе·ұзӯ”йўҳзҡ„жӯЈзЎ®зҺҮгҖӮ
жӯЈеҰӮиҠӮзӣ®дё»жҢҒдәәд»Ӣз»Қзҡ„дёҖж ·пјҢи®ёеӨҡзӯ”йўҳиҖ…ејҖе§ӢеҜ»жүҫиә«иҫ№зҡ„жңӢеҸӢе…ұеҗҢзӯ”йўҳпјҢд»ҘжұӮиҰҶзӣ–еҲ°жӣҙеӨҡзұ»еһӢзҡ„зҹҘиҜҶзӮ№пјҢжҸҗй«ҳйҖҡе…ізҡ„еҮ зҺҮгҖӮ
еҗ„з§Қеҗ„ж ·зҡ„еҫ®дҝЎгҖҒQQзӯ”йўҳзҫӨиҜһз”ҹпјҢжҜҸдёӘдәәйғҪеңЁзҫӨиҒҠйҮҢеҲҶдә«иҮӘе·ұи®ӨдёәжӯЈзЎ®зҡ„зӯ”жЎҲгҖӮ
и®©дҪ зҢңдёҚеҲ°зҡ„жҳҜпјҢзӯ”йўҳжёёжҲҸеұ…然д№ҹжңүеӨ–жҢӮпјҒ
дёәдәҶиғҪеӨҹе…ЁйғЁзӯ”еҜ№12йҒ“йўҳпјҢе№іеҲҶж•°йўқеҰӮжӯӨеәһеӨ§зҡ„еҘ–йҮ‘жұ пјҢеҸӮиөӣиҖ…ејҖе§Ӣжғіж–№и®ҫжі•жҸҗй«ҳиҮӘе·ұзӯ”йўҳзҡ„жӯЈзЎ®зҺҮгҖӮ
е·Із»ҸжңүзЁӢеәҸе‘ҳи®ҫи®ЎдәҶвҖңиҫ…еҠ©зЁӢеәҸвҖқпјҢз”ЁдәҺеҝ«йҖҹжЈҖзҙўзӯ”жЎҲгҖӮ
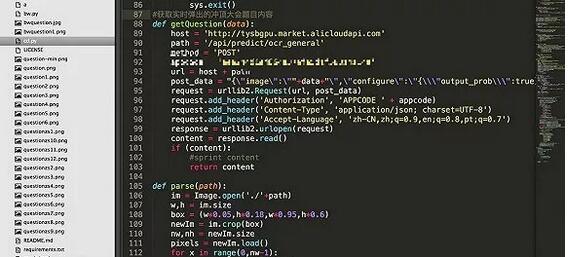
иҝҷдёӘз”ЁPythonзЁӢеәҸеҸҜд»Ҙдҝ®еүӘ并иҜҶеҲ«еӣҫзүҮдёӯзҡ„ж–Үеӯ—еҶ…е®№пјҲй—®йўҳе’ҢйҖүйЎ№пјүпјҢ然еҗҺйҖҡиҝҮзҷҫеәҰиҝӣиЎҢжҗңзҙўе…ій”®еӯ—еҮәзҺ°зҡ„ж¬Ўж•°пјҢжңҖеҗҺе°Ҷз»ҹи®Ўзҡ„дҝЎжҒҜеұ•зӨәеҮәжқҘгҖӮиҝҷж ·дёҖжқҘпјҢзӯ”йўҳиҖ…е°ұеҸҜд»Ҙж №жҚ®з»ҹи®Ўж•°жҚ®жқҘйҖүжӢ©зӣёеә”зҡ„зӯ”жЎҲпјҢжһҒеӨ§жҸҗй«ҳдәҶзӯ”йўҳзҡ„жӯЈзЎ®зҺҮгҖӮ
йӮЈд№ҲзЁӢеәҸе‘ҳеҲ°еә•еә”иҜҘеҰӮдҪ•зҺ©е‘ўпјҹ
йҰ–е…Ҳз”Ё WDA жқҘиҺ·еҸ–еұҸ幕жҲӘеӣҫгҖӮWDA жң¬жҳҜ Facebook ејҖеҸ‘зҡ„дёҖеҘ— iOS жөӢиҜ•жЎҶжһ¶пјҢеүҚеҮ еӨ©зңӢи§ҒеӨ§е®¶йғҪз”ЁжқҘеҒҡеҫ®дҝЎвҖңи·ідёҖи·івҖқзҡ„еӨ–жҢӮпјҢдҫҝзү№ж„ҸеҺ»дәҶи§ЈдәҶдёҖдёӢпјҢеҸ‘зҺ°д№ҹиғҪз”ЁеңЁеҶІйЎ¶еӨ§дјҡдёҠгҖӮ
д№ӢеҗҺ crop еҮәйўҳзӣ®жүҖеңЁзҡ„дҪҚзҪ®пјҲеҸҜиғҪйңҖиҰҒйҖӮй…ҚжүӢжңәеұҸ幕пјүпјҢ然еҗҺи°ғз”ЁејҖж”ҫзҡ„ OCR жҺҘеҸЈиҜ»еҸ–еҮәж–Үеӯ—ж–Үжң¬пјҢжңҖеҗҺи°ғз”Ёжҗңзҙўеј•ж“ҺпјҢе°ұеҸҜд»ҘиҫҫеҲ°д№ӢеүҚ gif еӣҫзҡ„ж•ҲжһңгҖӮиҝҷеҘ—зҺҜеўғжҳҜ iOS + MacпјҢеҰӮжһңжҳҜе®үеҚ“еә”иҜҘжңүжӣҙж–№дҫҝзҡ„ж–№жі•гҖӮ
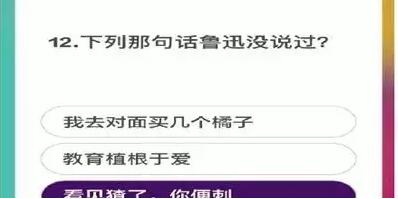
е…¶е®һжңҖеҲқзҡ„жғіжі•жҳҜеёҢжңӣжҗңзҙў+йҖүжӢ©зӯ”жЎҲе…ЁйғЁиҮӘеҠЁеҢ–е®ҢжҲҗзҡ„пјҢжҖқи·ҜжҳҜ OCR йўҳзӣ®е’ҢеҖҷйҖүзӯ”жЎҲпјҢз»„жҲҗдёүдёӘз»„еҗҲжү”еҲ°зҷҫеәҰжҲ–и°·жӯҢйҮҢжҗңзҙўпјҢ然еҗҺе“ӘдёӘз»„еҗҲзҡ„з»“жһңеҮәзҺ°ж¬Ўж•°жңҖеӨҡе°ұйҖүжӢ©е“ӘдёӘгҖӮиҜ•дәҶеҮ дёӘй—®йўҳеҗҺеҸ‘зҺ°е№¶дёҚжҳҜиҝҷж ·пјҢжҜ”еҰӮдёҠйқўеӣҫзүҮзҡ„вҖңйӘҶй©јзҡ„й©јеі°жҳҜеӯҳеӮЁд»Җд№Ҳзҡ„пјҹвҖқпјҢеҸҜиғҪеӨҡж•°дәәйғҪдјҡи®ӨдёәжҳҜж°ҙпјҢеӣ жӯӨеҮәзҺ°зҡ„ж¬Ўж•°жңҖеӨҡпјҢе…¶е®һжҳҜй”ҷиҜҜзӯ”жЎҲгҖӮ
жңҖеҗҺиҝҳжңүдёӨдёӘз—ӣзӮ№пјҡ
е…Қиҙ№ OCR жҺҘеҸЈи°ғз”Ёж¬Ўж•°жңүйҷҗпјҢжүҖд»ҘдёҚиғҪдёҖзӣҙеҺ»жҲӘеұҸиҜҶеҲ«пјҢеҸӘиғҪзӯүйўҳзӣ®еҮәзҺ°ж—¶иҝҗиЎҢзЁӢеәҸгҖӮ
е®ҳж–№д№ҹеҫҲеҘ—и·ҜпјҢжңүзҡ„й—®йўҳжҳҜжІЎжі•жҗңзҙўзҡ„гҖӮжҜ”еҰӮиҝҷз§Қпјҡ
жңҖеҗҺйҷ„дёҠд»Јз Ғпјҡ
# python3
import wda
import io
import urllib.parse
import webbrowser
import requests
import time
import base64
from PIL import Image
c = wda.Client()
# зҷҫеәҰOCR API
api_key = ''
api_secret = ''
token = ''
while True:
time.sleep(0.5)
c.screenshot('1.png')
im = Image.open("./1.png")
region = im.crop((75, 315, 1167, 789)) # iPhone 7P
imgByteArr = io.BytesIO()
region.save(imgByteArr, format='PNG')
image_data = imgByteArr.getvalue()
base64_data = base64.b64encode(image_data)
r = requests.post('https://aip.baidubce.com/rest/2.0/ocr/v1/general_basic',
params={'access_token': token}, data={'image': base64_data})
result = ''
for i in r.json()['words_result']:
result += i['words']
result = urllib.parse.quote(result)
webbrowser.open('https://baidu.com/s?wd='+result)
break
пјҲд»Јз ҒжқҘжәҗпјҡhttps://livc.io/blog/204пјү
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ