жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©ж•ҙзҗҶд№ӢеүҚеҶҷзҡ„д»Јз ҒпјҢеҸ‘зҺ°еңЁеҒҡж•°жЁЎжңҹй—ҙеҶҷзҡ„з”Ёpythonе®һзҺ°зҡ„йҒ—дј з®—жі•пјҢж„ҹи§үиҝҳжҳҜжҢәжңүж„ҸжҖқзҡ„пјҢе°ұжӢҝеҮәжқҘеҲҶдә«дёҖдёӢгҖӮ
йҰ–е…ҲйҒ—дј з®—жі•жҳҜдёҖз§ҚдјҳеҢ–з®—жі•пјҢйҖҡиҝҮжЁЎжӢҹеҹәеӣ зҡ„дјҳиғңеҠЈжұ°пјҢиҝӣиЎҢи®Ўз®—пјҲе…·дҪ“зҡ„з®—жі•жҖқи·Ҝд»Җд№Ҳзҡ„е°ұдёҚиөҳиҝ°дәҶпјүгҖӮеӨ§иҮҙиҝҮзЁӢеҲҶдёәеҲқе§ӢеҢ–зј–з ҒгҖҒдёӘдҪ“иҜ„д»·гҖҒйҖүжӢ©пјҢдәӨеҸүпјҢеҸҳејӮгҖӮ
йҒ—дј з®—жі•д»Ӣз»Қ
йҒ—дј з®—жі•жҳҜйҖҡиҝҮжЁЎжӢҹеӨ§иҮӘ然дёӯз”ҹзү©иҝӣеҢ–зҡ„еҺҶзЁӢпјҢжқҘи§ЈеҶій—®йўҳзҡ„гҖӮеӨ§иҮӘ然дёӯдёҖдёӘз§ҚзҫӨз»ҸеҺҶиҝҮиӢҘе№Ід»Јзҡ„иҮӘ然йҖүжӢ©еҗҺпјҢеү©дёӢзҡ„з§ҚзҫӨеҝ…е®ҡжҳҜйҖӮеә”зҺҜеўғзҡ„гҖӮжҠҠдёҖдёӘй—®йўҳжүҖжңүзҡ„и§ЈзңӢеҒҡдёҖдёӘз§ҚзҫӨпјҢз»ҸеҺҶиҝҮиӢҘе№Іж¬Ўзҡ„иҮӘ然йҖүжӢ©д»ҘеҗҺпјҢеү©дёӢзҡ„и§ЈдёӯжҳҜжңүй—®йўҳзҡ„жңҖдјҳи§Јзҡ„гҖӮеҪ“然пјҢеҸӘиғҪиҜҙжңүжңҖдјҳи§Јзҡ„жҰӮзҺҮеҫҲеӨ§гҖӮиҝҷйҮҢпјҢжҲ‘们用йҒ—дј з®—жі•жұӮдёҖдёӘеҮҪж•°зҡ„жңҖеӨ§еҖјгҖӮ
f(x) = 10 * sin( 5x ) + 7 * cos( 4x ), 0 <= x <= 10
1гҖҒе°ҶиҮӘеҸҳйҮҸxиҝӣиЎҢзј–з Ғ
еҸ–еҹәеӣ зүҮж®өзҡ„й•ҝеәҰдёә10, еҲҷ10дҪҚдәҢиҝӣеҲ¶дҪҚеҸҜд»ҘиЎЁзӨәзҡ„иҢғеӣҙжҳҜ0еҲ°1023гҖӮеҹәеӣ дёҺиҮӘеҸҳйҮҸиҪ¬еҸҳзҡ„е…¬ејҸжҳҜx = b2d(individual) * 10 / 1023гҖӮжһ„йҖ еҲқе§Ӣзҡ„з§ҚзҫӨpopгҖӮжҜҸдёӘдёӘдҪ“зҡ„еҹәеӣ еҲқе§ӢеҖјжҳҜ[0, 1, 0, 1, 0, 1, 0, 1, 0, 1]
2гҖҒи®Ўз®—зӣ®ж ҮеҮҪж•°еҖј
ж №жҚ®иҮӘеҸҳйҮҸдёҺеҹәеӣ зҡ„иҪ¬еҢ–е…ізі»ејҸпјҢжұӮеҮәжҜҸдёӘдёӘдҪ“зҡ„еҹәеӣ еҜ№еә”зҡ„иҮӘеҸҳйҮҸпјҢ然еҗҺе°ҶиҮӘеҸҳйҮҸд»Је…ҘеҮҪж•°fпјҲxпјүпјҢжұӮеҮәжҜҸдёӘдёӘдҪ“зҡ„зӣ®ж ҮеҮҪж•°еҖјгҖӮ
3гҖҒйҖӮеә”еәҰеҮҪж•°
йҖӮеә”еәҰеҮҪж•°жҳҜз”ЁжқҘиҜ„дј°дёӘдҪ“йҖӮеә”зҺҜеўғзҡ„иғҪеҠӣпјҢжҳҜиҝӣиЎҢиҮӘ然йҖүжӢ©зҡ„дҫқжҚ®гҖӮжң¬йўҳзҡ„йҖӮеә”еәҰеҮҪж•°зӣҙжҺҘе°Ҷзӣ®ж ҮеҮҪж•°еҖјдёӯзҡ„иҙҹеҖјеҸҳжҲҗ0. еӣ дёәжҲ‘们жұӮзҡ„жҳҜжңҖеӨ§еҖјпјҢжүҖд»ҘиҰҒдҪҝзӣ®ж ҮеҮҪж•°еҖјжҳҜиҙҹж•°зҡ„дёӘдҪ“дёҚйҖӮеә”зҺҜеўғпјҢдҪҝе…¶з№Ғж®–еҗҺд»Јзҡ„иғҪеҠӣдёә0.йҖӮеә”еәҰеҮҪж•°зҡ„дҪңз”Ёе°ҶеңЁиҮӘ然йҖүжӢ©дёӯдҪ“зҺ°гҖӮ
4гҖҒиҮӘ然йҖүжӢ©
иҮӘ然йҖүжӢ©зҡ„жҖқжғідёҚеҶҚиөҳиҝ°пјҢж“ҚдҪңдҪҝз”ЁиҪ®зӣҳиөҢз®—жі•гҖӮе…¶е…·дҪ“жӯҘйӘӨпјҡ
еҒҮи®ҫз§ҚзҫӨдёӯе…ұ5дёӘдёӘдҪ“пјҢйҖӮеә”еәҰеҮҪж•°и®Ўз®—еҮәжқҘзҡ„дёӘдҪ“йҖӮеә”жҖ§еҲ—иЎЁжҳҜfitvalue = [1 ,3, 0, 2, 4] пјҢtotalvalue = 10 пјҢ еҰӮжһңе°Ҷfitvalueз”»еҲ°еңҶзӣҳдёҠпјҢеҖјзҡ„еӨ§е°ҸиЎЁзӨәеңЁеңҶзӣҳдёҠзҡ„йқўз§ҜгҖӮеңЁиҪ¬еҠЁиҪ®зӣҳзҡ„иҝҮзЁӢдёӯпјҢеҚ•дёӘжЁЎеқ—зҡ„йқўз§Ҝи¶ҠеӨ§еҲҷиў«йҖүдёӯзҡ„жҰӮзҺҮи¶ҠеӨ§гҖӮйҖүжӢ©зҡ„ж–№жі•жҳҜе°ҶfitvalueиҪ¬еҢ–дёә[1 пјҢ 4 пјҢ4 , 6 пјҢ10], fitvalue / totalvalue = [0.1 , 0.4 , 0.4 , 0.6 , 1.0] . 然еҗҺдә§з”ҹ5дёӘ0-1д№Ӣй—ҙзҡ„йҡҸжңәж•°пјҢе°ҶйҡҸжңәж•°д»Һе°ҸеҲ°еӨ§жҺ’еәҸпјҢеҒҮеҰӮжҳҜ[0.05 , 0.2 , 0.7 , 0.8 ,0.9]пјҢеҲҷе°Ҷ0еҸ·дёӘдҪ“гҖҒ1еҸ·дёӘдҪ“гҖҒ4еҸ·дёӘдҪ“гҖҒ4еҸ·дёӘдҪ“гҖҒ4еҸ·дёӘдҪ“жӢ·иҙқеҲ°ж–°з§ҚзҫӨдёӯгҖӮиҮӘ然йҖүжӢ©зҡ„з»“жһңдҪҝз§ҚзҫӨжӣҙз¬ҰеҗҲжқЎд»¶дәҶгҖӮ
5гҖҒз№Ғж®–
еҒҮи®ҫдёӘдҪ“aгҖҒbзҡ„еҹәеӣ жҳҜ
a = [1, 0, 0, 0, 0, 1, 1, 1, 0, 0]
b = [0, 0, 0, 1, 1, 0, 1, 1, 1, 1]
иҝҷдёӨдёӘдёӘдҪ“еҸ‘з”ҹеҹәеӣ дәӨжҚўзҡ„жҰӮзҺҮpc = 0.6.еҰӮжһңиҰҒеҸ‘з”ҹеҹәеӣ дәӨжҚўпјҢеҲҷдә§з”ҹдёҖдёӘйҡҸжңәж•°pointиЎЁзӨәеҹәеӣ дәӨжҚўзҡ„дҪҚзҪ®пјҢеҒҮи®ҫpoint = 4,еҲҷпјҡ
a = [1, 0, 0, 0, 0, 1, 1, 1, 0, 0]
b = [0, 0, 0, 1, 1, 0, 1, 1, 1, 1]
дәӨжҚўеҗҺдёәпјҡ
a = [1, 0, 0, 0, 1, 0, 1, 1, 1, 1]
b = [0, 0, 0, 1, 0, 1, 1, 1, 0, 0]
6гҖҒзӘҒеҸҳ
йҒҚеҺҶжҜҸдёҖдёӘдёӘдҪ“пјҢеҹәеӣ зҡ„жҜҸдёҖдҪҚеҸ‘з”ҹзӘҒеҸҳпјҲ0еҸҳдёә1,1еҸҳдёә0пјүзҡ„жҰӮзҺҮдёә0.001.зӘҒеҸҳеҸҜд»ҘеўһеҠ и§Јз©әй—ҙ
д»Ҙзӣ®ж ҮејҸеӯҗ y = 10 * sin(5x) + 7 * cos(4x)дёәдҫӢпјҢи®Ўз®—е…¶жңҖеӨ§еҖј
йҰ–е…ҲжҳҜеҲқе§ӢеҢ–пјҢеҢ…жӢ¬е…·дҪ“иҰҒи®Ўз®—зҡ„ејҸеӯҗгҖҒз§ҚзҫӨж•°йҮҸгҖҒжҹ“иүІдҪ“й•ҝеәҰгҖҒдәӨй…ҚжҰӮзҺҮгҖҒеҸҳејӮжҰӮзҺҮзӯүгҖӮ并且иҰҒеҜ№еҹәеӣ еәҸеҲ—иҝӣиЎҢеҲқе§ӢеҢ–
pop_size = 500 # з§ҚзҫӨж•°йҮҸ max_value = 10 # еҹәеӣ дёӯе…Ғи®ёеҮәзҺ°зҡ„жңҖеӨ§еҖј chrom_length = 10 # жҹ“иүІдҪ“й•ҝеәҰ pc = 0.6 # дәӨй…ҚжҰӮзҺҮ pm = 0.01 # еҸҳејӮжҰӮзҺҮ results = [[]] # еӯҳеӮЁжҜҸдёҖд»Јзҡ„жңҖдјҳи§ЈпјҢNдёӘдәҢе…ғз»„ fit_value = [] # дёӘдҪ“йҖӮеә”еәҰ fit_mean = [] # е№іеқҮйҖӮеә”еәҰ pop = geneEncoding(pop_size, chrom_length)
е…¶дёӯgenEncodeingжҳҜиҮӘе®ҡд№үзҡ„дёҖдёӘз®ҖеҚ•йҡҸжңәз”ҹжҲҗеәҸеҲ—зҡ„еҮҪж•°пјҢе…·дҪ“е®һзҺ°еҰӮдёӢ
def geneEncoding(pop_size, chrom_length): pop = [[]] for i in range(pop_size): temp = [] for j in range(chrom_length): temp.append(random.randint(0, 1)) pop.append(temp) return pop[1:]
зј–з Ғе®ҢжҲҗд№ӢеҗҺе°ұжҳҜиҰҒиҝӣиЎҢдёӘдҪ“иҜ„д»·пјҢдёӘдҪ“иҜ„д»·дё»иҰҒжҳҜи®Ўз®—еҗ„дёӘзј–з ҒеҮәжқҘзҡ„listзҡ„еҖјд»ҘеҸҠеҜ№еә”еёҰе…Ҙзӣ®ж ҮејҸеӯҗзҡ„еҖјгҖӮе…¶е®һзј–з ҒеҮәжқҘзҡ„е°ұжҳҜдёҖе Ҷ2иҝӣеҲ¶listгҖӮиҝҷдәӣ2иҝӣеҲ¶listжҜҸдёӘйғҪд»ЈиЎЁдәҶдёҖдёӘж•°гҖӮе…¶еҖјзҡ„и®Ўз®—ж–№ејҸдёәиҪ¬жҚўдёә10иҝӣеҲ¶пјҢ然еҗҺйҷӨд»Ҙ2зҡ„еәҸеҲ—й•ҝеәҰж¬Ўж–№еҮҸдёҖпјҢд№ҹе°ұжҳҜе…ЁдёҖlistзҡ„еҚҒиҝӣеҲ¶еҮҸдёҖгҖӮж №жҚ®иҝҷдёӘ规еҲҷе°ұиғҪи®Ўз®—еҮәжүҖжңүlistзҡ„еҖје’ҢеёҰе…ҘиҰҒи®Ўз®—ејҸеӯҗдёӯзҡ„еҖјпјҢд»Јз ҒеҰӮдёӢ
# 0.0 coding:utf-8 0.0 # и§Јз Ғ并计算еҖј import math def decodechrom(pop, chrom_length): temp = [] for i in range(len(pop)): t = 0 for j in range(chrom_length): t += pop[i][j] * (math.pow(2, j)) temp.append(t) return temp def calobjValue(pop, chrom_length, max_value): temp1 = [] obj_value = [] temp1 = decodechrom(pop, chrom_length) for i in range(len(temp1)): x = temp1[i] * max_value / (math.pow(2, chrom_length) - 1) obj_value.append(10 * math.sin(5 * x) + 7 * math.cos(4 * x)) return obj_value
жңүдәҶе…·дҪ“зҡ„еҖје’ҢеҜ№еә”зҡ„еҹәеӣ еәҸеҲ—пјҢ然еҗҺиҝӣиЎҢдёҖж¬Ўж·ҳжұ°пјҢзӣ®зҡ„жҳҜж·ҳжұ°жҺүдёҖдәӣдёҚеҸҜиғҪзҡ„еқҸеҖјгҖӮиҝҷйҮҢз”ұдәҺжҳҜи®Ўз®—жңҖеӨ§еҖјпјҢдәҺжҳҜе°ұж·ҳжұ°иҙҹеҖје°ұеҘҪдәҶ
# 0.0 coding:utf-8 0.0 # ж·ҳжұ°пјҲеҺ»йҷӨиҙҹеҖјпјү def calfitValue(obj_value): fit_value = [] c_min = 0 for i in range(len(obj_value)): if(obj_value[i] + c_min > 0): temp = c_min + obj_value[i] else: temp = 0.0 fit_value.append(temp) return fit_value
然еҗҺе°ұжҳҜиҝӣиЎҢйҖүжӢ©пјҢиҝҷжҳҜж•ҙдёӘйҒ—дј з®—жі•жңҖж ёеҝғзҡ„йғЁеҲҶгҖӮйҖүжӢ©е®һйҷ…дёҠжЁЎжӢҹз”ҹзү©йҒ—дј иҝӣеҢ–зҡ„дјҳиғңеҠЈжұ°пјҢи®©дјҳз§Җзҡ„дёӘдҪ“е°ҪеҸҜиғҪеӯҳжҙ»пјҢи®©е·®зҡ„дёӘдҪ“е°ҪеҸҜиғҪзҡ„ж·ҳжұ°гҖӮдёӘдҪ“зҡ„еҘҪеқҸжҳҜеҸ–еҶідәҺдёӘдҪ“йҖӮеә”еәҰгҖӮдёӘдҪ“йҖӮеә”еәҰи¶Ҡй«ҳпјҢи¶Ҡе®№жҳ“иў«з•ҷдёӢпјҢдёӘдҪ“йҖӮеә”еәҰи¶ҠдҪҺи¶Ҡе®№жҳ“иў«ж·ҳжұ°гҖӮе…·дҪ“зҡ„д»Јз ҒеҰӮдёӢ
# 0.0 coding:utf-8 0.0 # йҖүжӢ© import random def sum(fit_value): total = 0 for i in range(len(fit_value)): total += fit_value[i] return total def cumsum(fit_value): for i in range(len(fit_value)-2, -1, -1): t = 0 j = 0 while(j <= i): t += fit_value[j] j += 1 fit_value[i] = t fit_value[len(fit_value)-1] = 1 def selection(pop, fit_value): newfit_value = [] # йҖӮеә”еәҰжҖ»е’Ң total_fit = sum(fit_value) for i in range(len(fit_value)): newfit_value.append(fit_value[i] / total_fit) # и®Ўз®—зҙҜи®ЎжҰӮзҺҮ cumsum(newfit_value) ms = [] pop_len = len(pop) for i in range(pop_len): ms.append(random.random()) ms.sort() fitin = 0 newin = 0 newpop = pop # иҪ¬иҪ®зӣҳйҖүжӢ©жі• while newin < pop_len: if(ms[newin] < newfit_value[fitin]): newpop[newin] = pop[fitin] newin = newin + 1 else: fitin = fitin + 1 pop = newpop
д»ҘдёҠд»Јз Ғдё»иҰҒиҝӣиЎҢдәҶ3дёӘж“ҚдҪңпјҢйҰ–е…ҲжҳҜи®Ўз®—дёӘдҪ“йҖӮеә”еәҰжҖ»е’ҢпјҢ然еҗҺеңЁи®Ўз®—еҗ„иҮӘзҡ„зҙҜз§ҜйҖӮеә”еәҰгҖӮиҝҷдёӨжӯҘйғҪеҘҪзҗҶи§ЈпјҢдё»иҰҒжҳҜ第дёүжӯҘпјҢиҪ¬иҪ®зӣҳйҖүжӢ©жі•гҖӮиҝҷдёҖжӯҘйҰ–е…ҲжҳҜз”ҹжҲҗеҹәеӣ жҖ»ж•°дёӘ0-1зҡ„е°Ҹж•°пјҢ然еҗҺеҲҶеҲ«е’Ңеҗ„дёӘеҹәеӣ зҡ„зҙҜз§ҜдёӘдҪ“йҖӮеә”еәҰиҝӣиЎҢжҜ”иҫғгҖӮеҰӮжһңзҙҜз§ҜдёӘдҪ“йҖӮеә”еәҰеӨ§дәҺйҡҸжңәж•°еҲҷиҝӣиЎҢдҝқз•ҷпјҢеҗҰеҲҷе°ұж·ҳжұ°гҖӮиҝҷдёҖеқ—зҡ„ж ёеҝғжҖқжғіеңЁдәҺпјҡдёҖдёӘеҹәеӣ зҡ„дёӘдҪ“йҖӮеә”еәҰи¶Ҡй«ҳпјҢд»–жүҖеҚ жҚ®зҡ„зҙҜи®ЎйҖӮеә”еәҰз©әйҡҷе°ұи¶ҠеӨ§пјҢд№ҹе°ұжҳҜиҜҙд»–и¶Ҡе®№жҳ“иў«дҝқз•ҷдёӢжқҘгҖӮ
йҖүжӢ©е®ҢеҗҺе°ұжҳҜиҝӣиЎҢдәӨй…Қе’ҢеҸҳејӮпјҢиҝҷдёӘдёӨдёӘжӯҘйӘӨеҫҲеҘҪзҗҶи§ЈгҖӮе°ұжҳҜеҜ№еҹәеӣ еәҸеҲ—иҝӣиЎҢж”№еҸҳпјҢеҸӘдёҚиҝҮж”№еҸҳзҡ„ж–№ејҸдёҚдёҖж ·
дәӨй…Қпјҡ
# 0.0 coding:utf-8 0.0 # дәӨй…Қ import random def crossover(pop, pc): pop_len = len(pop) for i in range(pop_len - 1): if(random.random() < pc): cpoint = random.randint(0,len(pop[0])) temp1 = [] temp2 = [] temp1.extend(pop[i][0:cpoint]) temp1.extend(pop[i+1][cpoint:len(pop[i])]) temp2.extend(pop[i+1][0:cpoint]) temp2.extend(pop[i][cpoint:len(pop[i])]) pop[i] = temp1 pop[i+1] = temp2
еҸҳејӮпјҡ
# 0.0 coding:utf-8 0.0
# еҹәеӣ зӘҒеҸҳ
import random
def mutation(pop, pm):
px = len(pop)
py = len(pop[0])
for i in range(px):
if(random.random() < pm):
mpoint = random.randint(0, py-1)
if(pop[i][mpoint] == 1):
pop[i][mpoint] = 0
else:
pop[i][mpoint] = 1
ж•ҙдёӘйҒ—дј з®—жі•зҡ„е®һзҺ°е®ҢжҲҗдәҶпјҢжҖ»зҡ„и°ғз”Ёе…ҘеҸЈд»Јз ҒеҰӮдёӢ
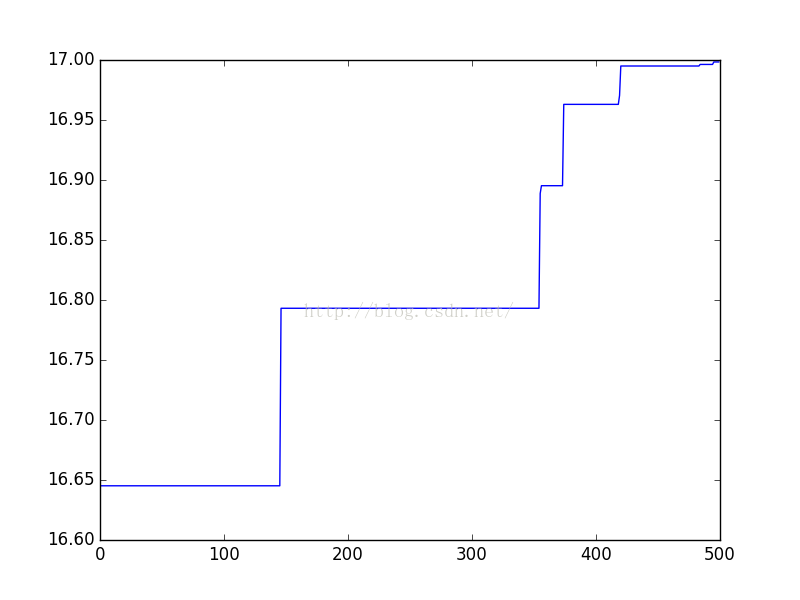
# 0.0 coding:utf-8 0.0 import matplotlib.pyplot as plt import math from calobjValue import calobjValue from calfitValue import calfitValue from selection import selection from crossover import crossover from mutation import mutation from best import best from geneEncoding import geneEncoding print 'y = 10 * math.sin(5 * x) + 7 * math.cos(4 * x)' # и®Ўз®—2иҝӣеҲ¶еәҸеҲ—д»ЈиЎЁзҡ„ж•°еҖј def b2d(b, max_value, chrom_length): t = 0 for j in range(len(b)): t += b[j] * (math.pow(2, j)) t = t * max_value / (math.pow(2, chrom_length) - 1) return t pop_size = 500 # з§ҚзҫӨж•°йҮҸ max_value = 10 # еҹәеӣ дёӯе…Ғи®ёеҮәзҺ°зҡ„жңҖеӨ§еҖј chrom_length = 10 # жҹ“иүІдҪ“й•ҝеәҰ pc = 0.6 # дәӨй…ҚжҰӮзҺҮ pm = 0.01 # еҸҳејӮжҰӮзҺҮ results = [[]] # еӯҳеӮЁжҜҸдёҖд»Јзҡ„жңҖдјҳи§ЈпјҢNдёӘдәҢе…ғз»„ fit_value = [] # дёӘдҪ“йҖӮеә”еәҰ fit_mean = [] # е№іеқҮйҖӮеә”еәҰ # pop = [[0, 1, 0, 1, 0, 1, 0, 1, 0, 1] for i in range(pop_size)] pop = geneEncoding(pop_size, chrom_length) for i in range(pop_size): obj_value = calobjValue(pop, chrom_length, max_value) # дёӘдҪ“иҜ„д»· fit_value = calfitValue(obj_value) # ж·ҳжұ° best_individual, best_fit = best(pop, fit_value) # 第дёҖдёӘеӯҳеӮЁжңҖдјҳзҡ„и§Ј, 第дәҢдёӘеӯҳеӮЁжңҖдјҳеҹәеӣ results.append([best_fit, b2d(best_individual, max_value, chrom_length)]) selection(pop, fit_value) # ж–°з§ҚзҫӨеӨҚеҲ¶ crossover(pop, pc) # дәӨй…Қ mutation(pop, pm) # еҸҳејӮ results = results[1:] results.sort() X = [] Y = [] for i in range(500): X.append(i) t = results[i][0] Y.append(t) plt.plot(X, Y) plt.show()
жңҖеҗҺи°ғз”ЁдәҶдёҖдёӢmatplotlibеҢ…пјҢжҠҠ500д»ЈжңҖдјҳи§Јзҡ„еҸҳеҢ–и¶ӢеҠҝиЎЁзҺ°еҮәжқҘгҖӮ
е®Ңж•ҙд»Јз ҒеҸҜд»ҘеңЁgithub жҹҘзңӢ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ