您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、简介
1、消息传输流程
Kafka is a distributed,partitioned,replicated commit logservice。它提供了类似于JMS的特性,但是在设计实现上完全不同,此外它并不是JMS规范的实现。kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer,此外kafka集群有多个kafka实例组成,每个实例(server)成为broker。无论是kafka集群,还是producer和consumer都依赖于zookeeper来保证系统可用性集群保存一些meta信息。


Producer即生产者,向Kafka集群发送消息,在发送消息之前,会对消息进行分类,即Topic,上图展示了两个producer发送了分类为topic1的消息,另外一个发送了topic2的消息。
Topic即主题,通过对消息指定主题可以将消息分类,消费者可以只关注自己需要的Topic中的消息
Consumer即消费者,消费者通过与kafka集群建立长连接的方式,不断地从集群中拉取消息,然后可以对这些消息进行处理。
2、Topics/logs
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。

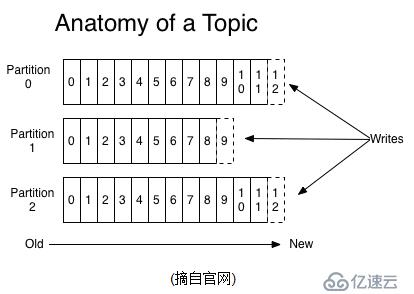
谈到kafka的存储,就不得不提到分区,即partitions,创建一个topic时,同时可以指定分区数目,分区数越多,其吞吐量也越大,但是需要的资源也越多,同时也会导致更高的不可用性,kafka在接收到生产者发送的消息之后,会根据均衡策略将消息存储到不同的分区中。
kafka服务器消息存储策略如图

kafka和JMS(Java Message Service)实现(activeMQ)不同的是:即使消息被消费,消息仍然不会被立即删除.日志文件将会根据broker中的配置要求,保留一定的时间之后删除;比如log文件保留2天,那么两天后,文件会被清除,无论其中的消息是否被消费.kafka通过这种简单的手段,来释放磁盘空间,以及减少消息消费之后对文件内容改动的磁盘IO开支.
对于consumer而言,它需要保存消费消息的offset,对于offset的保存和使用,有consumer来控制;当consumer正常消费消息时,offset将会"线性"的向前驱动,即消息将依次顺序被消费.事实上consumer可以使用任意顺序消费消息,它只需要将offset重置为任意值..(offset将会保存在zookeeper中,参见下文)
kafka集群几乎不需要维护任何consumer和producer状态信息,这些信息有zookeeper保存;因此producer和consumer的客户端实现非常轻量级,它们可以随意离开,而不会对集群造成额外的影响.
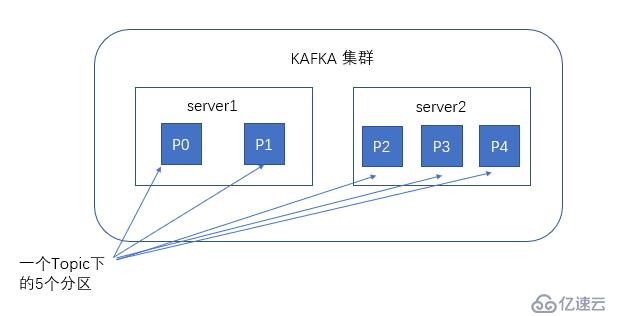
partitions的设计目的有多个.最根本原因是kafka基于文件存储.通过分区,可以将日志内容分散到多个server上,来避免文件尺寸达到单机磁盘的上限,每个partiton都会被当前server(kafka实例)保存;可以将一个topic切分多任意多个partitions,来消息保存/消费的效率.此外越多的partitions意味着可以容纳更多的consumer,有效提升并发消费的能力.(具体原理参见下文).
3、Distribution(分布)
一个Topic的多个partitions,被分布在kafka集群中的多个server上;每个server(kafka实例)负责partitions中消息的读写操作;此外kafka还可以配置partitions需要备份的个数(replicas),每个partition将会被备份到多台机器上,以提高可用性.
基于replicated方案,那么就意味着需要对多个备份进行调度;每个partition都有一个server为"leader";leader负责所有的读写操作,如果leader失效,那么将会有其他follower来接管(成为新的leader);follower只是单调的和leader跟进,同步消息即可..由此可见作为leader的server承载了全部的请求压力,因此从集群的整体考虑,有多少个partitions就意味着有多少个"leader",kafka会将"leader"均衡的分散在每个实例上,来确保整体的性能稳定.
Producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等.
Consumers
本质上kafka只支持Topic.每个consumer属于一个consumer group;反过来说,每个group中可以有多个consumer.发送到Topic的消息,只会被订阅此Topic的每个group中的一个consumer消费.
如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡.
如果所有的consumer都具有不同的group,那这就是"发布-订阅";消息将会广播给所有的消费者.
在kafka中,一个partition中的消息只会被group中的一个consumer消费;每个group中consumer消息消费互相独立;我们可以认为一个group是一个"订阅"者,一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以消费多个partitions中的消息.kafka只能保证一个partition中的消息被某个consumer消费时,消息是顺序的.事实上,从Topic角度来说,消息仍不是有序的.
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息.
Guarantees
1) 发送到partitions中的消息将会按照它接收的顺序追加到日志中
2) 对于消费者而言,它们消费消息的顺序和日志中消息顺序一致.
3) 如果Topic的"replicationfactor"为N,那么允许N-1个kafka实例失效。
与生产者的交互


生产者在向kafka集群发送消息的时候,可以通过指定分区来发送到指定的分区中,也可以通过指定均衡策略来将消息发送到不同的分区中,如果不指定,就会采用默认的随机均衡策略,将消息随机的存储到不同的分区中
与消费者的交互

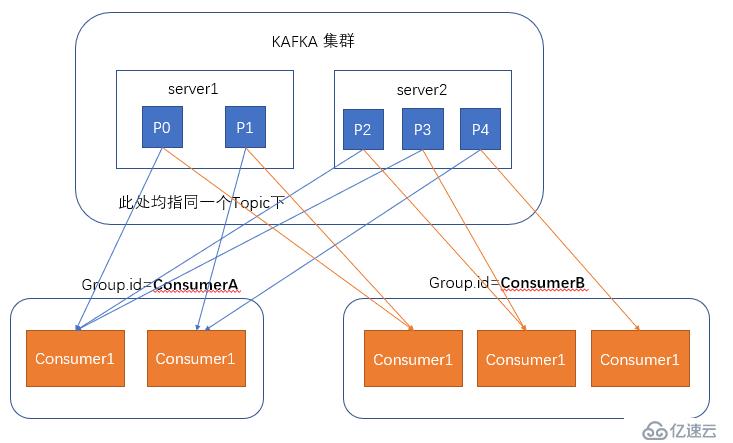
在消费者消费消息时,kafka使用offset来记录当前消费的位置,在kafka的设计中,可以有多个不同的group来同时消费同一个topic下的消息,如图,我们有两个不同的group同时消费,他们的的消费的记录位置offset各不项目,不互相干扰。
对于一个group而言,消费者的数量不应该多余分区的数量,因为在一个group中,每个分区至多只能绑定到一个消费者上,即一个消费者可以消费多个分区,一个分区只能给一个消费者消费
因此,若一个group中的消费者数量大于分区数量的话,多余的消费者将不会收到任何消息。
二、使用场景
1、Messaging
对于一些常规的消息系统,kafka是个不错的选择;partitons/replication和容错,可以使kafka具有良好的扩展性和性能优势.不过到目前为止,我们应该很清楚认识到,kafka并没有提供JMS中的"事务性""消息传输担保(消息确认机制)""消息分组"等企业级特性;kafka只能使用作为"常规"的消息系统,在一定程度上,尚未确保消息的发送与接收绝对可靠(比如,消息重发,消息发送丢失等)
2、Websit activity tracking
kafka可以作为"网站活性跟踪"的最佳工具;可以将网页/用户操作等信息发送到kafka中.并实时监控,或者离线统计分析等
3、Log Aggregation
kafka的特性决定它非常适合作为"日志收集中心";application可以将操作日志"批量""异步"的发送到kafka集群中,而不是保存在本地或者DB中;kafka可以批量提交消息/压缩消息等,这对producer端而言,几乎感觉不到性能的开支.此时consumer端可以使hadoop等其他系统化的存储和分析系统.
三、设计原理
kafka的设计初衷是希望作为一个统一的信息收集平台,能够实时的收集反馈信息,并需要能够支撑较大的数据量,且具备良好的容错能力。
1、持久性
2、性能
3、生产者
4、消费者
5、消息传送机制
6、复制备份
7、日志
8、分配
四、主要配置
1、Broker配置


2、Consumer主要配置


3、Producer主要配置


五、kafka集群搭建步骤
1、系统环境
主机名 | 系统 | zookeeper版本 | IP |
master | CentOS7.4 | 3.4.12 | 192.168.56.129 |
slave1 | CentOS7.4 | 3.4.12 | 192.168.56.130 |
slave2 | CentOS7.4 | 3.4.12 | 192.168.56.131 |
2、暂时关闭防火墙和selinux
3、软件下载
下载地址:http://kafka.apache.org/downloads.html
备注:下载最新的二进制tgz包





4、搭建zookeeper集群
备注:小伙伴可以参考上一篇文章即可
5、kafka集群
5.1、根据上面的zookeeper集群服务器,把kafka上传到/home下
5.2、解压
[root@master home]# tar -zxvf kafka_2.12-2.0.0.tgz
[root@master home]# mv kafka_2.12-2.0.0 kafka01
5.3、配置文件
[root@master home]# cd /home/kafka01/config/
备注:server.properties文件里的broker.id,log.dirs,zookeeper.connect必须根据实际情况进行修改,其他项根据需要自行斟酌,master配置如下:
broker.id=1
port=9091
num.network.threads=2
num.io.threads=2
socket.send.buffer.bytes=1048576
socket.receive.buffer.bytes=1048576
socket.request.max.bytes=104857600
log.dirs=/var/log/kafka/kafka-logs
num.partitions=2
log.flush.interval.messages=10000
log.flush.interval.ms=1000
log.retention.hours=168
#log.retention.bytes=1073741824
log.segment.bytes=536870912
num.replica.fetchers=2
log.cleanup.interval.mins=10
zookeeper.connect=192.168.56.129:2181,192.168.56.130:2181,192.168.56.131:2181
zookeeper.connection.timeout.ms=1000000
kafka.metrics.polling.interval.secs=5
kafka.metrics.reporters=kafka.metrics.KafkaCSVMetricsReporter
kafka.csv.metrics.dir=/tmp/kafka_metrics
kafka.csv.metrics.reporter.enabled=false
5.4、启动服务(master)----前提是三个节点的zookeeper已启动
[root@master kafka01]# ./bin/kafka-server-start.sh config/server.properties &

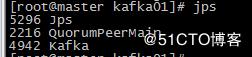
补充:
问题:&可以使程序在后台运行,但一旦断开ssh终端,后台Java程序也会终止。
解决办法:使用shell脚本启动
[root@master kafka01]# cat start.sh
#!/bin/bash
cd /home/kafka01/
./bin/kafka-server-start.sh config/server.properties &
exit
授权,运行即可
[root@master kafka01]#chmod +x start.sh
5.5、配置slave1和slave2
slave1配置如下:
broker.id=2
port=9092
log.dirs=/var/log/kafka
zookeeper.connect=192.168.56.129:2181,192.168.56.130:2181,192.168.56.131:2181
启动即可

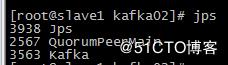


slave2配置如下:
broker.id=3
port=9093
log.dirs=/var/log/kafka
zookeeper.connect=192.168.56.129:2181,192.168.56.130:2181,192.168.56.131:2181
启动即可


6、测试
Kafka通过topic对同一类的数据进行管理,同一类的数据使用同一个topic可以在处理数据时更加的便捷
6.1、创建一个Topic
[root@master kafka01]# bin/kafka-topics.sh --create --zookeeper 192.168.56.129:2181 --replication-factor 1 --partitions 1 --topic test
查看
[root@master kafka01]# bin/kafka-topics.sh --list --zookeeper 192.168.56.129:2181


6.2、创建一个消息消费者
[root@master kafka01]# bin/kafka-console-consumer.sh --bootstrap-server 192.168.56.129:9091 --topic test --from-beginning


消费者创建完成之后,因为还没有发送任何数据,因此这里在执行后没有打印出任何数据
不过别着急,不要关闭这个终端,打开一个新的终端,接下来我们创建第一个消息生产者
6.3、创建一个消息生产者
在kafka解压目录打开一个新的终端,输入
[root@master kafka01]# bin/kafka-console-producer.sh --broker-list 192.168.56.129:9091 --topic test


在发送完消息之后,可以回到我们的消息消费者终端中,可以看到,终端中已经打印出了我们刚才发送的消息

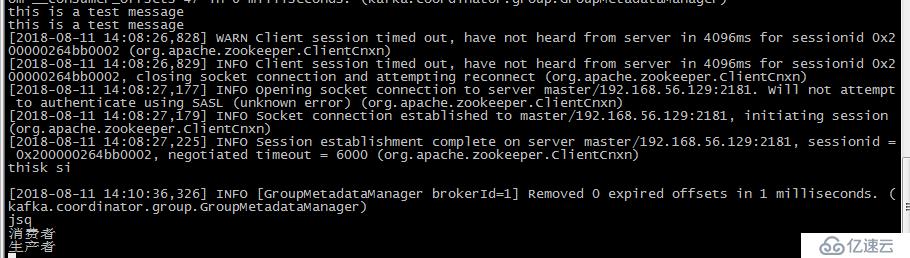
zookeeper查看topic


到此即可,共同进步之路!!!!!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。