жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚдәҶWebжҠҖжңҜеҰӮдҪ•е®һзҺ°з§»еҠЁзӣ‘жөӢпјҢе…·жңүдёҖе®ҡеҖҹйүҙд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢеҸҜд»ҘеҸӮиҖғдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©е°Ҹзј–еёҰзқҖеӨ§е®¶дёҖиө·дәҶи§ЈдёҖдёӢгҖӮ
WebжҠҖжңҜе®һзҺ°з§»еҠЁзӣ‘жөӢзҡ„д»Ӣз»Қ
з”ұдёҠиҝ°еј•з”ЁиҜӯеҸҘеҸҜеҫ—еҮәвҖң移еҠЁзӣ‘жөӢвҖқйңҖиҰҒд»ҘдёӢиҰҒзҙ пјҡ
дёҖдёӘжӢҘжңүж‘„еғҸеӨҙзҡ„и®Ўз®—жңәз”ЁдәҺеҲӨж–ӯ移еҠЁзҡ„算法移еҠЁеҗҺзҡ„еӨ„зҗҶ
жіЁпјҡжң¬ж–Үж¶үеҸҠзҡ„жүҖжңүжЎҲдҫӢеқҮеҹәдәҺ PC/Mac иҫғж–°зүҲжң¬зҡ„ Chrome / Firefox жөҸи§ҲеҷЁпјҢйғЁеҲҶжЎҲдҫӢйңҖй…ҚеҗҲж‘„еғҸеӨҙе®ҢжҲҗпјҢжүҖжңүжҲӘеӣҫеқҮдҝқеӯҳеңЁжң¬ең°гҖӮ
еҜ№ж–№дёҚжғіе’ҢдҪ иҜҙиҜқпјҢ并еҗ‘дҪ жү”жқҘдёҖдёӘй“ҫжҺҘпјҡ
дҪ“йӘҢй“ҫжҺҘ>>
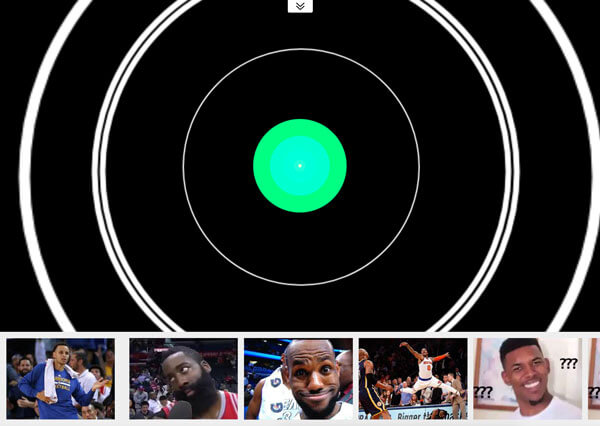
з»јеҗҲжЎҲдҫӢ
иҜҘжЎҲдҫӢжңүд»ҘдёӢдёӨдёӘеҠҹиғҪпјҡ
жӢҚеҘҪ POST еҗҺзҡ„ 1 з§’дјҡиҝӣиЎҢжӢҚз…§йқҷжӯў 1 з§’еҗҺйҹід№җдјҡеҒңжӯўпјҢдә§з”ҹ移еҠЁдјҡжҒўеӨҚж’ӯж”ҫзҠ¶жҖҒ
дёҠиҝ°жЎҲдҫӢд№ҹ许并дёҚиғҪзӣҙжҺҘдҪ“зҺ°еҮәгҖҺ移еҠЁзӣ‘жөӢгҖҸзҡ„е®һйҷ…ж•Ҳжһңе’ҢеҺҹзҗҶпјҢдёӢйқўеҶҚзңӢзңӢиҝҷдёӘжЎҲдҫӢгҖӮ
дҪ“йӘҢй“ҫжҺҘ>>
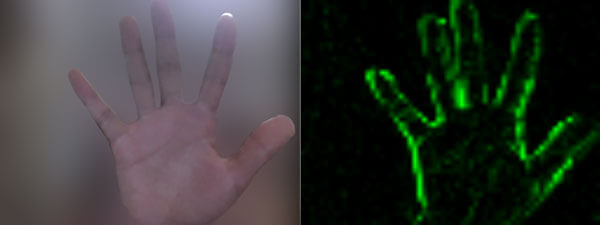
еғҸзҙ е·®ејӮ
жЎҲдҫӢзҡ„е·Ұдҫ§жҳҜи§Ҷйў‘жәҗпјҢиҖҢеҸідҫ§еҲҷжҳҜ移еҠЁеҗҺзҡ„еғҸзҙ еӨ„зҗҶпјҲеғҸзҙ еҢ–гҖҒеҲӨж–ӯ移еҠЁе’ҢеҸӘдҝқз•ҷз»ҝиүІзӯүпјүгҖӮ
еӣ дёәжҳҜеҹәдәҺ Web жҠҖжңҜпјҢжүҖд»Ҙи§Ҷйў‘жәҗйҮҮз”Ё WebRTCпјҢеғҸзҙ еӨ„зҗҶеҲҷйҮҮз”Ё CanvasгҖӮ
и§Ҷйў‘жәҗ
дёҚдҫқиө– Flash жҲ– SilverlightпјҢжҲ‘们дҪҝз”Ё WebRTC (Web Real-Time Communications) дёӯзҡ„ navigator.getUserMedia() APIпјҢиҜҘ API е…Ғи®ё Web еә”з”ЁиҺ·еҸ–з”ЁжҲ·зҡ„ж‘„еғҸеӨҙдёҺйәҰе…ӢйЈҺжөҒпјҲstreamпјүгҖӮ
зӨәдҫӢд»Јз ҒеҰӮдёӢпјҡ
<!-- иӢҘдёҚеҠ autoplayпјҢеҲҷдјҡеҒңз•ҷеңЁз¬¬дёҖеё§ -->
<video id="video" autoplay></video>
// е…·дҪ“еҸӮж•°еҗ«д№үеҸҜзңӢзӣёе…іж–ҮжЎЈгҖӮ
const constraints = {
audio: false,
video: {
width: 640,
height: 480
}
}
navigator.mediaDevices.getUserMedia(constraints)
.then(stream => {
// е°Ҷи§Ҷйў‘жәҗеұ•зӨәеңЁ video дёӯ
video.srcObject = stream
})
.catch(err => {
console.log(err)
})еҜ№дәҺе…је®№жҖ§й—®йўҳпјҢSafari 11 ејҖе§Ӣж”ҜжҢҒ WebRTC дәҶгҖӮе…·дҪ“еҸҜжҹҘзңӢ caniuseгҖӮ
еғҸзҙ еӨ„зҗҶ
еңЁеҫ—еҲ°и§Ҷйў‘жәҗеҗҺпјҢжҲ‘们е°ұжңүдәҶеҲӨж–ӯзү©дҪ“жҳҜеҗҰ移еҠЁзҡ„зҙ жқҗгҖӮеҪ“然пјҢиҝҷйҮҢ并没жңүйҮҮз”Ёд»Җд№Ҳй«ҳж·ұзҡ„иҜҶеҲ«з®—жі•пјҢеҸӘжҳҜеҲ©з”Ёиҝһз»ӯдёӨеё§жҲӘеӣҫзҡ„еғҸзҙ е·®ејӮжқҘеҲӨж–ӯзү©дҪ“жҳҜеҗҰеҸ‘з”ҹ移еҠЁпјҲдёҘж јжқҘиҜҙпјҢжҳҜз”»йқўзҡ„еҸҳеҢ–пјүгҖӮ
жҲӘеӣҫ
иҺ·еҸ–и§Ҷйў‘жәҗжҲӘеӣҫзҡ„зӨәдҫӢд»Јз Ғпјҡ
const video = document.getElementById('video')
const canvas = document.createElement('canvas')
const ctx = canvas.getContext('2d')
canvas.width = 640
canvas.height = 480
// иҺ·еҸ–и§Ҷйў‘дёӯзҡ„дёҖеё§
function capture () {
ctx.drawImage(video, 0, 0, canvas.width, canvas.height)
// ...е…¶е®ғж“ҚдҪң
}еҫ—еҮәжҲӘеӣҫй—ҙзҡ„е·®ејӮ
еҜ№дәҺдёӨеј еӣҫзҡ„еғҸзҙ е·®ејӮпјҢеңЁ еҮ№еҮёе®һйӘҢе®Ө зҡ„ гҖҠвҖңзӯүдёҖдёӢпјҢжҲ‘зў°пјҒвҖқвҖ”вҖ”еёёи§Ғзҡ„2Dзў°ж’һжЈҖжөӢгҖӢ иҝҷзҜҮеҚҡж–ҮдёӯжүҖжҸҗеҸҠзҡ„вҖңеғҸзҙ жЈҖжөӢвҖқзў°ж’һз®—жі•жҳҜи§ЈеҶіеҠһжі•д№ӢдёҖгҖӮиҜҘз®—жі•жҳҜйҖҡиҝҮйҒҚеҺҶдёӨдёӘзҰ»еұҸз”»еёғпјҲoffscreen canvasпјүеҗҢдёҖдҪҚзҪ®зҡ„еғҸзҙ зӮ№зҡ„йҖҸжҳҺеәҰжҳҜеҗҰеҗҢж—¶еӨ§дәҺ 0пјҢжқҘеҲӨж–ӯзў°ж’һдёҺеҗҰгҖӮеҪ“然пјҢиҝҷйҮҢиҰҒж”№дёәгҖҺеҗҢдёҖдҪҚзҪ®зҡ„еғҸзҙ зӮ№жҳҜеҗҰдёҚеҗҢпјҲжҲ–е·®ејӮе°ҸдәҺжҹҗйҳҲеҖјпјүгҖҸжқҘеҲӨж–ӯ移еҠЁдёҺеҗҰгҖӮ
дҪҶдёҠиҝ°ж–№ејҸзЁҚжҳҫйә»зғҰе’ҢдҪҺж•ҲпјҢиҝҷйҮҢжҲ‘们йҮҮз”Ё ctx.globalCompositeOperation = 'difference' жҢҮе®ҡз”»еёғж–°еўһе…ғзҙ пјҲеҚіз¬¬дәҢеј жҲӘеӣҫдёҺ第дёҖеј жҲӘеӣҫпјүзҡ„еҗҲжҲҗж–№ејҸпјҢеҫ—еҮәдёӨеј жҲӘеӣҫзҡ„е·®ејӮйғЁеҲҶгҖӮ
дҪ“йӘҢй“ҫжҺҘ>>
зӨәдҫӢд»Јз Ғпјҡ
function diffTwoImage () {
// и®ҫзҪ®ж–°еўһе…ғзҙ зҡ„еҗҲжҲҗж–№ејҸ
ctx.globalCompositeOperation = 'difference'
// жё…йҷӨз”»еёғ
ctx.clearRect(0, 0, canvas.width, canvas.height)
// еҒҮи®ҫдёӨеј еӣҫеғҸе°әеҜёзӣёзӯү
ctx.drawImage(firstImg, 0, 0)
ctx.drawImage(secondImg, 0, 0)
}
дёӨеј еӣҫзҡ„е·®ејӮ
дҪ“йӘҢдёҠиҝ°жЎҲдҫӢеҗҺпјҢжҳҜеҗҰжңүз§ҚеҪ“е№ҙзҺ©вҖңQQжёёжҲҸгҖҠеӨ§е®¶жқҘжүҫиҢ¬гҖӢвҖқзҡ„ж„ҹи§үгҖӮеҸҰеӨ–пјҢиҝҷдёӘжЎҲдҫӢеҸҜиғҪиҝҳйҖӮз”ЁдәҺд»ҘдёӢдёӨз§Қжғ…еҶөпјҡ
еҪ“дҪ дёҚзҹҘйҒ“и®ҫи®ЎеёҲеүҚеҗҺдёӨж¬Ўз»ҷдҪ зҡ„и®ҫи®ЎзЁҝжңүдҪ•е·®ејӮж—¶
жғіжҹҘзңӢдёӨдёӘжөҸи§ҲеҷЁеҜ№еҗҢдёҖдёӘзҪ‘йЎөзҡ„жёІжҹ“жңүдҪ•е·®ејӮж—¶дҪ•ж—¶дёәдёҖдёӘвҖңеҠЁдҪңвҖқ
з”ұдёҠиҝ°вҖңдёӨеј еӣҫеғҸе·®ејӮвҖқзҡ„жЎҲдҫӢдёӯеҸҜеҫ—пјҡй»‘иүІд»ЈиЎЁиҜҘдҪҚзҪ®дёҠзҡ„еғҸзҙ жңӘеҸ‘з”ҹж”№еҸҳпјҢиҖҢеғҸзҙ и¶ҠжҳҺдә®еҲҷд»ЈиЎЁиҜҘзӮ№зҡ„вҖңеҠЁдҪңвҖқи¶ҠеӨ§гҖӮеӣ жӯӨпјҢеҪ“иҝһз»ӯдёӨеё§жҲӘеӣҫеҗҲжҲҗеҗҺжңүжҳҺдә®зҡ„еғҸзҙ еӯҳеңЁж—¶пјҢеҚідёәдёҖдёӘвҖңеҠЁдҪңвҖқзҡ„дә§з”ҹгҖӮдҪҶдёәдәҶи®©зЁӢеәҸдёҚйӮЈд№ҲвҖңж•Ҹж„ҹвҖқпјҢжҲ‘们еҸҜд»Ҙи®ҫе®ҡдёҖдёӘйҳҲеҖјгҖӮеҪ“жҳҺдә®еғҸзҙ зҡ„дёӘж•°еӨ§дәҺиҜҘйҳҲеҖјж—¶пјҢжүҚи®Өдёәдә§з”ҹдәҶдёҖдёӘвҖңеҠЁдҪңвҖқгҖӮеҪ“然пјҢжҲ‘们д№ҹеҸҜд»Ҙеү”йҷӨвҖңдёҚи¶іеӨҹжҳҺдә®вҖқзҡ„еғҸзҙ пјҢд»Ҙе°ҪеҸҜиғҪйҒҝе…ҚеӨ–з•ҢзҺҜеўғпјҲеҰӮзҒҜе…үзӯүпјүзҡ„еҪұе“ҚгҖӮ
жғіиҰҒиҺ·еҸ– Canvas зҡ„еғҸзҙ дҝЎжҒҜпјҢйңҖиҰҒйҖҡиҝҮ ctx.getImageData(sx, sy, sw, sh)пјҢиҜҘ API дјҡиҝ”еӣһдҪ жүҖжҢҮе®ҡз”»еёғеҢәеҹҹзҡ„еғҸзҙ еҜ№иұЎгҖӮиҜҘеҜ№иұЎеҢ…еҗ« dataгҖҒwidthгҖҒheightгҖӮе…¶дёӯ data жҳҜдёҖдёӘеҗ«жңүжҜҸдёӘеғҸзҙ зӮ№ RGBA дҝЎжҒҜзҡ„дёҖз»ҙж•°з»„пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ

еҗ«жңү RGBA дҝЎжҒҜзҡ„дёҖз»ҙж•°з»„
иҺ·еҸ–еҲ°зү№е®ҡеҢәеҹҹзҡ„еғҸзҙ еҗҺпјҢжҲ‘们е°ұиғҪеҜ№жҜҸдёӘеғҸзҙ иҝӣиЎҢеӨ„зҗҶпјҲеҰӮеҗ„з§Қж»Өй•ңж•ҲжһңпјүгҖӮеӨ„зҗҶе®ҢеҗҺпјҢеҲҷеҸҜйҖҡиҝҮ ctx.putImageData() е°Ҷе…¶жёІжҹ“еңЁжҢҮе®ҡзҡ„ Canvas дёҠгҖӮ
жү©еұ•пјҡз”ұдәҺ Canvas зӣ®еүҚжІЎжңүжҸҗдҫӣвҖңеҺҶеҸІи®°еҪ•вҖқзҡ„еҠҹиғҪпјҢеҰӮйңҖе®һзҺ°вҖңиҝ”еӣһдёҠдёҖжӯҘвҖқж“ҚдҪңпјҢеҲҷеҸҜйҖҡиҝҮ getImageData дҝқеӯҳдёҠдёҖжӯҘж“ҚдҪңпјҢеҪ“йңҖиҰҒж—¶еҲҷеҸҜйҖҡиҝҮ putImageData иҝӣиЎҢеӨҚеҺҹгҖӮ
зӨәдҫӢд»Јз Ғпјҡ
let imageScore = 0
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
const r = rgba[i] / 3
const g = rgba[i + 1] / 3
const b = rgba[i + 2] / 3
const pixelScore = r + g + b
// еҰӮжһңиҜҘеғҸзҙ и¶іеӨҹжҳҺдә®
if (pixelScore >= PIXEL_SCORE_THRESHOLD) {
imageScore++
}
}
// еҰӮжһңжҳҺдә®зҡ„еғҸзҙ ж•°йҮҸж»Ўи¶ідёҖе®ҡжқЎд»¶
if (imageScore >= IMAGE_SCORE_THRESHOLD) {
// дә§з”ҹдәҶ移еҠЁ
}еңЁдёҠиҝ°жЎҲдҫӢдёӯпјҢдҪ д№ҹи®ёдјҡжіЁж„ҸеҲ°з”»йқўжҳҜгҖҺз»ҝиүІгҖҸзҡ„гҖӮе…¶е®һпјҢжҲ‘们еҸӘйңҖе°ҶжҜҸдёӘеғҸзҙ зҡ„зәўе’Ңи“қи®ҫзҪ®дёә 0пјҢеҚіе°Ҷ RGBA зҡ„ r = 0; b = 0 еҚіеҸҜгҖӮиҝҷж ·е°ұдјҡеғҸз”өеҪұзҡ„жҹҗдәӣй•ңеӨҙдёҖж ·пјҢеўһеҠ дәҶ科жҠҖж„ҹе’ҢзҘһз§ҳж„ҹгҖӮ
дҪ“йӘҢең°еқҖ>>
const rgba = imageData.data
for (let i = 0; i < rgba.length; i += 4) {
rgba[i] = 0 // red
rgba[i + 2] = 0 // blue
}
ctx.putImageData(imageData, 0, 0)
е°Ҷ RGBA дёӯзҡ„ R е’Ң B зҪ®дёә 0
и·ҹиёӘвҖң移еҠЁзү©дҪ“вҖқ
жңүдәҶжҳҺдә®зҡ„еғҸзҙ еҗҺпјҢжҲ‘们е°ұиҰҒжүҫеҮәе…¶ x еқҗж Үзҡ„жңҖе°ҸеҖјдёҺ y еқҗж Үзҡ„жңҖе°ҸеҖјпјҢд»ҘиЎЁзӨәи·ҹиёӘзҹ©еҪўзҡ„е·ҰдёҠи§’гҖӮеҗҢзҗҶпјҢx еқҗж Үзҡ„жңҖеӨ§еҖјдёҺ y еқҗж Үзҡ„жңҖеӨ§еҖјеҲҷиЎЁзӨәи·ҹиёӘзҹ©еҪўзҡ„еҸідёӢи§’гҖӮиҮіжӯӨпјҢжҲ‘们е°ұиғҪз»ҳеҲ¶еҮәдёҖдёӘиғҪеҢ…еӣҙжүҖжңүжҳҺдә®еғҸзҙ зҡ„зҹ©еҪўпјҢд»ҺиҖҢе®һзҺ°и·ҹиёӘ移еҠЁзү©дҪ“зҡ„ж•ҲжһңгҖӮ
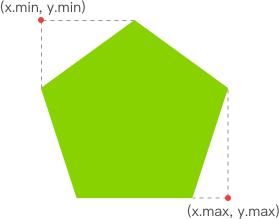
жүҫеҮәи·ҹиёӘзҹ©еҪўзҡ„е·ҰдёҠи§’е’ҢеҸідёӢи§’
дҪ“йӘҢй“ҫжҺҘ>>
зӨәдҫӢд»Јз Ғпјҡ
function processDiff (imageData) {
const rgba = imageData.data
let score = 0
let pixelScore = 0
let motionBox = 0
// йҒҚеҺҶж•ҙдёӘ canvas зҡ„еғҸзҙ пјҢд»ҘжүҫеҮәжҳҺдә®зҡ„зӮ№
for (let i = 0; i < rgba.length; i += 4) {
pixelScore = (rgba[i] + rgba[i+1] + rgba[i+2]) / 3
// иӢҘиҜҘеғҸзҙ и¶іеӨҹжҳҺдә®
if (pixelScore >= 80) {
score++
coord = calcCoord(i)
motionBox = calcMotionBox(montionBox, coord.x, coord.y)
}
}
return {
score,
motionBox
}
}
// еҫ—еҲ°е·ҰдёҠи§’е’ҢеҸідёӢи§’дёӨдёӘеқҗж ҮеҖј
function calcMotionBox (curMotionBox, x, y) {
const motionBox = curMotionBox || {
x: { min: coord.x, max: x },
y: { min: coord.y, max: y }
}
motionBox.x.min = Math.min(motionBox.x.min, x)
motionBox.x.max = Math.max(motionBox.x.max, x)
motionBox.y.min = Math.min(motionBox.y.min, y)
motionBox.y.max = Math.max(motionBox.y.max, y)
return motionBox
}
// imageData.data жҳҜдёҖдёӘеҗ«жңүжҜҸдёӘеғҸзҙ зӮ№ rgba дҝЎжҒҜзҡ„дёҖз»ҙж•°з»„гҖӮ
// иҜҘеҮҪж•°жҳҜе°ҶдёҠиҝ°дёҖз»ҙж•°з»„зҡ„д»»ж„ҸдёӢж ҮиҪ¬дёә (x,y) дәҢз»ҙеқҗж ҮгҖӮ
function calcCoord(i) {
return {
x: (i / 4) % diffWidth,
y: Math.floor((i / 4) / diffWidth)
}
}еңЁеҫ—еҲ°и·ҹиёӘзҹ©еҪўзҡ„е·ҰдёҠи§’е’ҢеҸідёӢи§’зҡ„еқҗж ҮеҖјеҗҺпјҢйҖҡиҝҮ ctx.strokeRect(x, y, width, height) API з»ҳеҲ¶еҮәзҹ©еҪўеҚіеҸҜгҖӮ
ctx.lineWidth = 6 ctx.strokeRect( diff.motionBox.x.min + 0.5, diff.motionBox.y.min + 0.5, diff.motionBox.x.max - diff.motionBox.x.min, diff.motionBox.y.max - diff.motionBox.y.min )
иҝҷжҳҜзҗҶжғіж•ҲжһңпјҢе®һйҷ…ж•ҲжһңиҜ·жү“ејҖ дҪ“йӘҢй“ҫжҺҘ
жү©еұ•пјҡдёәд»Җд№ҲдёҠиҝ°з»ҳеҲ¶зҹ©еҪўзҡ„д»Јз Ғдёӯзҡ„
xгҖҒyиҰҒеҠ0.5е‘ўпјҹдёҖеӣҫиғңеҚғиЁҖпјҡ
жҖ§иғҪзј©е°Ҹе°әеҜё
еңЁдёҠдёҖдёӘз« иҠӮжҸҗеҲ°пјҢжҲ‘们йңҖиҰҒйҖҡиҝҮеҜ№ Canvas жҜҸдёӘеғҸзҙ иҝӣиЎҢеӨ„зҗҶпјҢеҒҮи®ҫ Canvas зҡ„е®Ҫдёә 640пјҢй«ҳдёә 480пјҢйӮЈд№Ҳе°ұйңҖиҰҒйҒҚеҺҶ 640 * 480 = 307200 дёӘеғҸзҙ гҖӮиҖҢеңЁзӣ‘жөӢж•ҲжһңеҸҜжҺҘеҸ—зҡ„еүҚжҸҗдёӢпјҢжҲ‘们еҸҜд»Ҙе°ҶйңҖиҰҒиҝӣиЎҢеғҸзҙ еӨ„зҗҶзҡ„ Canvas зј©е°Ҹе°әеҜёпјҢеҰӮзј©е°Ҹ 10 еҖҚгҖӮиҝҷж ·йңҖиҰҒйҒҚеҺҶзҡ„еғҸзҙ ж•°йҮҸе°ұйҷҚдҪҺ 100 еҖҚпјҢд»ҺиҖҢжҸҗеҚҮжҖ§иғҪгҖӮ
дҪ“йӘҢең°еқҖ>>
зӨәдҫӢд»Јз Ғпјҡ
const motionCanvas // еұ•зӨәз»ҷз”ЁжҲ·зңӢ const backgroundCanvas // offscreen canvas иғҢеҗҺеӨ„зҗҶж•°жҚ® motionCanvas.width = 640 motionCanvas.height = 480 backgroundCanvas.width = 64 backgroundCanvas.height = 48

е°әеҜёзј©е°Ҹ 10 еҖҚ
е®ҡж—¶еҷЁ
жҲ‘们йғҪзҹҘйҒ“пјҢеҪ“жёёжҲҸд»ҘгҖҺжҜҸз§’60её§гҖҸиҝҗиЎҢж—¶жүҚиғҪдҝқиҜҒдёҖе®ҡзҡ„дҪ“йӘҢгҖӮдҪҶеҜ№дәҺжҲ‘们зӣ®еүҚзҡ„жЎҲдҫӢжқҘиҜҙпјҢеё§зҺҮ并дёҚжҳҜжҲ‘们иҝҪжұӮзҡ„第дёҖдҪҚгҖӮеӣ жӯӨпјҢжҜҸ 100 жҜ«з§’пјҲе…·дҪ“ж•°еҖјеҸ–еҶідәҺе®һйҷ…жғ…еҶөпјүеҸ–еҪ“еүҚеё§дёҺеүҚдёҖеё§иҝӣиЎҢжҜ”иҫғеҚіеҸҜгҖӮ
еҸҰеӨ–пјҢеӣ дёәжҲ‘们зҡ„еҠЁдҪңдёҖиҲ¬е…·жңүиҝһиҙҜжҖ§пјҢжүҖд»ҘеҸҜеҸ–иҜҘиҝһиҙҜеҠЁдҪңдёӯе№…еәҰжңҖеӨ§зҡ„пјҲеҚівҖңеҲҶж•°вҖқжңҖй«ҳпјүжҲ–жңҖеҗҺдёҖеё§еҠЁдҪңиҝӣиЎҢеӨ„зҗҶеҚіеҸҜпјҲеҰӮеӯҳеӮЁеҲ°жң¬ең°жҲ–еҲҶдә«еҲ°жңӢеҸӢеңҲпјүгҖӮ
延伸
иҮіжӯӨпјҢз”Ё Web жҠҖжңҜе®һзҺ°з®Җжҳ“зҡ„вҖң移еҠЁзӣ‘жөӢвҖқж•Ҳжһңе·Іеҹәжң¬и®Іиҝ°е®ҢжҜ•гҖӮз”ұдәҺз®—жі•гҖҒи®ҫеӨҮзӯүеӣ зҙ зҡ„йҷҗеҲ¶пјҢиҜҘж•ҲжһңеҸӘиғҪд»Ҙ 2D з”»йқўдёәеҹәзЎҖжқҘеҲӨж–ӯзү©дҪ“жҳҜеҗҰеҸ‘з”ҹвҖң移еҠЁвҖқгҖӮиҖҢеҫ®иҪҜзҡ„ XboxгҖҒзҙўе°јзҡ„ PSгҖҒд»»еӨ©е Ӯзҡ„ Wii зӯүжёёжҲҸи®ҫеӨҮдёҠзҡ„дҪ“ж„ҹжёёжҲҸеҲҷдҫқиө–дәҺ硬件гҖӮд»Ҙеҫ®иҪҜзҡ„ Kinect дёәдҫӢпјҢе®ғдёәејҖеҸ‘иҖ…жҸҗдҫӣдәҶеҸҜи·ҹиёӘжңҖеӨҡе…ӯдёӘе®Ңж•ҙйӘЁйӘје’ҢжҜҸдәә 25 дёӘе…іиҠӮзӯүејәеӨ§еҠҹиғҪгҖӮеҲ©з”ЁиҝҷдәӣиҜҰз»Ҷзҡ„дәәдҪ“еҸӮж•°пјҢжҲ‘们е°ұиғҪе®һзҺ°еҗ„з§Қйҡ”з©әзҡ„гҖҺжүӢеҠҝж“ҚдҪңгҖҸпјҢеҰӮз”»еңҲеңҲиҜ…е’’жҹҗдәәгҖӮ
дёӢйқўеҮ дёӘжҳҜйҖҡиҝҮ Web дҪҝз”Ё Kinect зҡ„еә“пјҡ
DepthJSпјҡд»ҘжөҸи§ҲеҷЁжҸ’件еҪўејҸжҸҗдҫӣж•°жҚ®и®ҝй—®гҖӮ
Node-Kinect2пјҡ д»Ҙ Nodejs жҗӯе»әжңҚеҠЎеҷЁз«ҜпјҢжҸҗдҫӣж•°жҚ®жҜ”иҫғе®Ңж•ҙпјҢе®һдҫӢиҫғеӨҡгҖӮ
ZigFuпјҡж”ҜжҢҒ H5гҖҒU3DгҖҒFlashпјҢAPIиҫғдёәе®Ңж•ҙгҖӮ
Kinect-HTML5пјҡKinect-HTML5 з”Ё C# жҗӯе»әжңҚеҠЎз«ҜпјҢжҸҗдҫӣиүІеҪ©ж•°жҚ®гҖҒж·ұеәҰж•°жҚ®е’ҢйӘЁйӘјж•°жҚ®гҖӮ
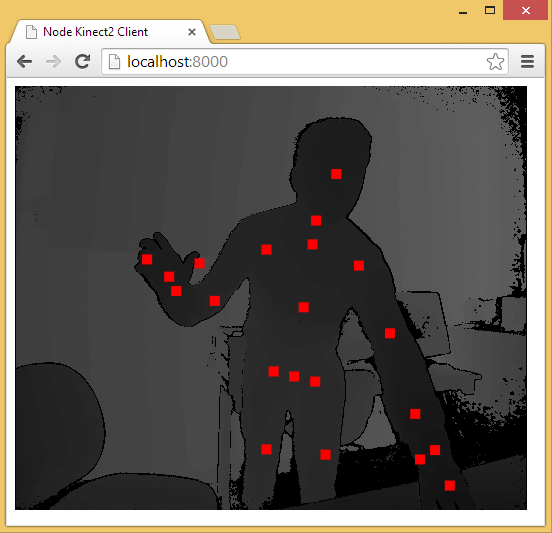
йҖҡиҝҮ Node-Kinect2 иҺ·еҸ–йӘЁйӘјж•°жҚ®
ж„ҹи°ўдҪ иғҪеӨҹи®Өзңҹйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« пјҢеёҢжңӣе°Ҹзј–еҲҶдә«зҡ„вҖңWebжҠҖжңҜеҰӮдҪ•е®һзҺ°з§»еҠЁзӣ‘жөӢвҖқиҝҷзҜҮж–Үз« еҜ№еӨ§е®¶жңүеё®еҠ©пјҢеҗҢж—¶д№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘пјҢе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶзӯүзқҖдҪ жқҘеӯҰд№ !
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ