您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
(以下讨论,针对32位的计算机系统。。)
问:int型数据占几个字节?答:4字节。地球上这个群体的人都知道。
再问:这4个字节,即32个二进制位,又是何存储?这就进入计算机的“底层”了。这个事情,学习程序设计的童鞋,可以懂。
存储的方式,和我们拍脑袋想得不太一样,概括一下,就是低位在前,高位在后。
本文直观一些,看懂以下程序中数据的存储,也便知道这个安排。
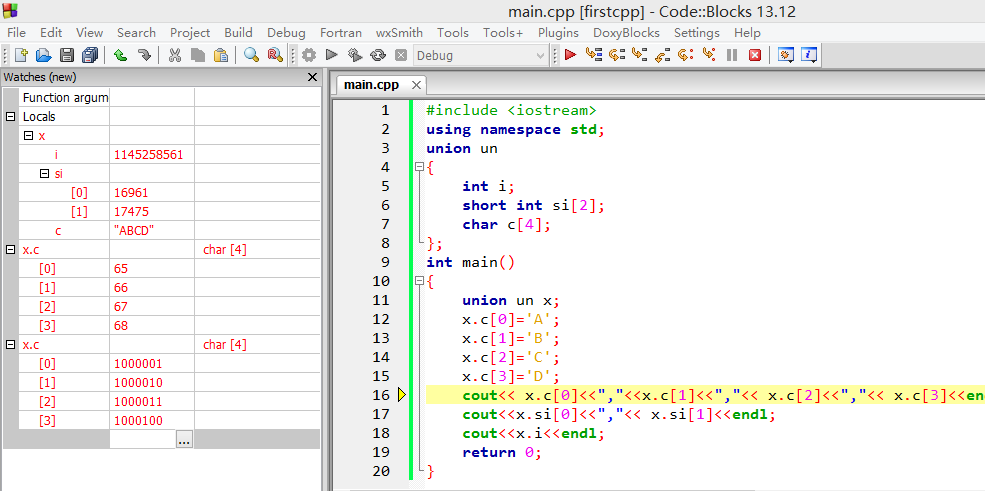
(源程序,及在watch窗口中用多种方式看x.c的方法,见文后附件。)
在程序中,由于联合体存储的特点,变量x占4个字节。我们可以从3个角度观察这4个字节:(1) 整体看,是一个int型数据;(2) 分成2部分看,是两个短整型数据;(3) 分成4部分看,是4个单字节的数据。
但无论怎么看,就是这4个字节。无论用哪种形式操作数据,使用的也就是这4个字节。联合体为我们提供了从不同的角度使用这4个字节的方式。
x.c[0]到x.c[3]的值分别为65\66\67\68,这好理解。
x.si[0]占的2字节,与x.c[0]和x.c[1]相同。验证一下:16961=66×256+65(66是'B'的ACSII值,65是'A'的ASCII值,是字符的存储形式)。注意,这里体现存储数据时低位在前,高位在后,低位是65,高位是66。正如十进制数98中,高位是9,低位是8,所以98=9×10+8一样。因为是高位,所以乘以位权10,表示9这个符号代表的其实是90。66×256,是因为存储66(‘B')的那一个字节的位置,比存储65(‘A')的那一个字节的位置高8位,所以乘以2的8次方,即256。
概括讲,存储2字节的16961时,其低8位,是65,在前(x.c[0]),而其高8位,是66,在后(x.c[1])。低位在前,高位在后。
请自行验证:17475=68×256+67,体现低位在前,高位在后。(x.si[0]占的2字节,与x.c[2]和x.c[3]相同)
再请验证:1145258561=17475×256×256+16961,也体现低位在前,高位在后。(x.i占的4字节,与x.si[0]和x.si[1]相同)
再请验证:1145258561=68×256×256×256+67×256×256+66×256+65。同样的道理。
换种写法,是1145258561=(((68×256+67)×256+66)×256+65。
再看截图,品味低位在前,高位在后。
这样安排的道理,在以后的关于“计算机的原理”的有关专业课中会接触到。
附1:本文源程序
#include <iostream>
using namespace std;
union un
{
int i;
short int si[2];
char c[4];
};
int main()
{
union un x;
x.c[0]='A';
x.c[1]='B';
x.c[2]='C';
x.c[3]='D';
cout<< x.c[0]<<","<<x.c[1]<<","<< x.c[2]<<","<< x.c[3]<<endl;
cout<<x.si[0]<<","<< x.si[1]<<endl;
cout<<x.i<<endl;
return 0;
}
附2:在watch窗口中用多种方式看x.c的方法
在watch窗口中,除自动显示的局部变量的值,还可以自行输入表达式跟踪。
方法是,直接在表格中写下表达式,如图中,x.c,其他任意。
输入表达式后,在上面点右键,会有几个选项,点properties…(属性),然后就是如下的窗口:
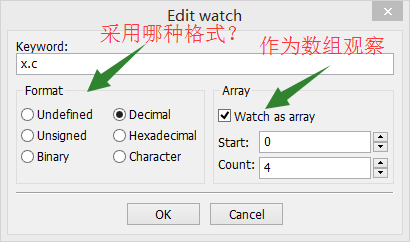
任性地多角度观察吧!
总结
以上就是这篇文章的全部内容了,希望本文的内容对大家的学习或者工作具有一定的参考学习价值,谢谢大家对亿速云的支持。如果你想了解更多相关内容请查看下面相关链接
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。