жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үе®һдҫӢи®Іиҝ°дәҶJavaеә•еұӮеҹәдәҺдәҢеҸүжҗңзҙўж ‘е®һзҺ°йӣҶеҗҲе’Ңжҳ е°„еҠҹиғҪгҖӮеҲҶдә«з»ҷеӨ§е®¶дҫӣеӨ§е®¶еҸӮиҖғпјҢе…·дҪ“еҰӮдёӢпјҡ
еүҚиЁҖпјҡеңЁз¬¬5з« зҡ„зі»еҲ—еӯҰд№ дёӯпјҢе·Із»Ҹе®һзҺ°дәҶе…ідәҺдәҢеҸүжҗңзҙўж ‘зҡ„зӣёе…іж“ҚдҪңпјҢиҜҰжғ…жҹҘзңӢ第5з« еҚіеҸҜгҖӮеңЁжң¬иҠӮдёӯзқҖйҮҚеӯҰд№ дҪҝз”Ёеә•еұӮжҳҜжҲ‘们已з»Ҹе°ҒиЈ…еҘҪзҡ„дәҢеҸүжҗңзҙўж ‘зӣёе…іж“ҚдҪңжқҘе®һзҺ°дёҖдёӘеҹәжң¬зҡ„йӣҶеҗҲпјҲsetпјүиҝҷз§Қж•°жҚ®з»“жһ„гҖӮ
йӣҶеҗҲsetзҡ„зү№жҖ§:
йӣҶеҗҲSetеӯҳеӮЁзҡ„е…ғзҙ жҳҜж— еәҸзҡ„гҖҒдёҚеҸҜйҮҚеӨҚзҡ„гҖӮдёәдәҶиғҪиҫҫеҲ°иҝҷз§Қзү№жҖ§е°ұйңҖиҰҒеҜ»жүҫеҸҜд»ҘдҪңдёәж”Ҝж’‘зҡ„еә•еұӮж•°жҚ®з»“жһ„гҖӮ
иҝҷйҮҢйҖүз”Ёд№ӢеүҚиҮӘе·ұе®һзҺ°зҡ„дәҢеҸүжҗңзҙўж ‘пјҢиҝҷжҳҜз”ұдәҺиҜҘдәҢеҸүж ‘жҳҜдёҚиғҪзӣӣж”ҫйҮҚеӨҚе…ғзҙ зҡ„гҖӮеӣ жӯӨжҲ‘们еҸҜд»ҘдҪҝз”ЁдәҢеҸүжҗңзҙўж ‘иҝҷз§Қеә•еұӮжқҘе®һзҺ°йӣҶеҗҲ(set)гҖӮ
setзӣёе…іеҠҹиғҪ
дәҢеҲҶжҗңзҙўж ‘зҡ„ж·»еҠ ж“ҚдҪңaddпјҡдёҚиғҪзӣӣж”ҫйҮҚеӨҚе…ғзҙ
е…ёеһӢеә”з”Ёпјҡ1.е®ўжҲ·з»ҹи®Ў 2.иҜҚжұҮйҮҸз»ҹи®Ў
/**
* йӣҶеҗҲзҡ„жҺҘеҸЈ
*/
public interface Set<E> {
void add(E e);//ж·»еҠ <вҖ”вҖ”<дёҚиғҪж·»еҠ йҮҚеӨҚе…ғзҙ
void remove(E e);//移йҷӨ
int getSize();//иҺ·еҸ–еӨ§е°Ҹ
boolean isEmpty();//жҳҜеҗҰдёәз©ә
boolean contains(E e);//жҳҜеҗҰеҢ…еҗ«е…ғзҙ
}
Set
//еҹәдәҺBSTдәҢеҲҶжҗңзҙўж ‘е®һзҺ°зҡ„йӣҶеҗҲSet
public class BSTSet<E extends Comparable<E>> implements Set<E> {//е…ғзҙ Eеҝ…йЎ»ж»Ўи¶іеҸҜжҜ”иҫғзҡ„
//еҹәдәҺBSTзұ»зҡ„еҜ№иұЎ
private BST<E> bst;
//жһ„йҖ еҮҪж•°
public BSTSet() {
bst = new BST<>();
}
//иҝ”еӣһйӣҶеҗҲеӨ§е°Ҹ
@Override
public int getSize() {
return bst.size();
}
//иҝ”еӣһйӣҶеҗҲжҳҜеҗҰдёәз©ә
@Override
public boolean isEmpty() {
return bst.isEmpty();
}
//Setж·»еҠ е…ғзҙ
@Override
public void add(E e) {
bst.add(e);
}
//жҳҜеҗҰеҢ…еҗ«е…ғзҙ
@Override
public boolean contains(E e) {
return bst.contains(e);
}
//移йҷӨе…ғзҙ
@Override
public void remove(E e) {
bst.remove(e);
}
}
public static void main(String[] args) {
System.out.println("Pride and Prejudice");
//ж–°е»әдёҖдёӘArrayListеӯҳж”ҫеҚ•иҜҚ
ArrayList<String> words1=new ArrayList<>();
//йҖҡиҝҮиҝҷдёӘж–№жі•е°Ҷд№ҰдёӯжүҖд»ҘеҚ•иҜҚеӯҳе…Ҙword1дёӯ
FileOperation.readFile("pride-and-prejudice.txt",words1);
System.out.println("Total words : "+words1.size());
BSTSet<String> set1=new BSTSet<>();
//еўһејәforеҫӘзҺҜпјҢе®ҡдёҖдёӘеӯ—з¬ҰдёІwordеҺ»йҒҚеҺҶwords
//еә•еұӮзҡ„иҜқдјҡжҠҠArrayList words1дёӯзҡ„еҖјдёҖдёӘдёҖдёӘзҡ„иөӢеҖјз»ҷword
for(String word:words1)
set1.add(word);//дёҚж·»еҠ йҮҚеӨҚе…ғзҙ
System.out.println("Total different words : "+set1.getSize());
System.out.println("-------------------");
System.out.println("Pride and Prejudice");
//ж–°е»әдёҖдёӘArrayListеӯҳж”ҫеҚ•иҜҚ
ArrayList<String> words2=new ArrayList<>();
//йҖҡиҝҮиҝҷдёӘж–№жі•е°Ҷд№ҰдёӯжүҖд»ҘеҚ•иҜҚеӯҳе…Ҙword1дёӯ
FileOperation.readFile("a-tale-of-two-cities.txt",words2);
System.out.println("Total words : "+words2.size());
BSTSet<String> set2=new BSTSet<>();
//еўһејәforеҫӘзҺҜпјҢе®ҡдёҖдёӘеӯ—з¬ҰдёІwordеҺ»йҒҚеҺҶwords
//еә•еұӮзҡ„иҜқдјҡжҠҠArrayList words1дёӯзҡ„еҖјдёҖдёӘдёҖдёӘзҡ„иөӢеҖјз»ҷword
for(String word:words2)
set2.add(word);//дёҚж·»еҠ йҮҚеӨҚе…ғзҙ
System.out.println("Total different words : "+set2.getSize());
}
з»“жһңпјҡ
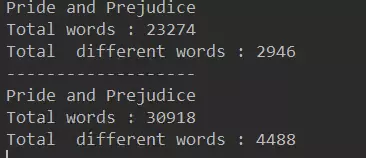
иҝҷйҮҢйңҖиҰҒиҜҙжҳҺдёҖдёӢе°ұжҳҜе…ідәҺжҲ‘们з»ҹи®Ўзҡ„еҚ•иҜҚж•°еҸӘиҖғиҷ‘дәҶжҜҸдёӘеҚ•иҜҚз»„жҲҗзҡ„дёҚз”ЁпјҢ并没жңүеҜ№еҚ•иҜҚзҡ„зү№ж®ҠеҪўејҸеҒҡеҢәеҲҶгҖӮ
еңЁдёӢдёҖе°ҸиҠӮдёӯ继з»ӯеӯҰд№ гҖҗйӣҶеҗҲе’Ңжҳ е°„--йӣҶеҗҲSet->еә•еұӮеҹәдәҺй“ҫиЎЁе®һзҺ°гҖ‘гҖӮ
жәҗз Ғең°еқҖ https://github.com/FelixBin/dataStructure/tree/master/src/SetPart
жӣҙеӨҡе…ідәҺjavaз®—жі•зӣёе…іеҶ…е®№ж„ҹе…ҙи¶Јзҡ„иҜ»иҖ…еҸҜжҹҘзңӢжң¬з«ҷдё“йўҳпјҡгҖҠJavaж•°жҚ®з»“жһ„дёҺз®—жі•ж•ҷзЁӢгҖӢгҖҒгҖҠJavaж“ҚдҪңDOMиҠӮзӮ№жҠҖе·§жҖ»з»“гҖӢгҖҒгҖҠJavaж–Ү件дёҺзӣ®еҪ•ж“ҚдҪңжҠҖе·§жұҮжҖ»гҖӢе’ҢгҖҠJavaзј“еӯҳж“ҚдҪңжҠҖе·§жұҮжҖ»гҖӢ
еёҢжңӣжң¬ж–ҮжүҖиҝ°еҜ№еӨ§е®¶javaзЁӢеәҸи®ҫи®ЎжңүжүҖеё®еҠ©гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ