您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要为大家展示了“Spark2.3中HA集群的分布式安装示例”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“Spark2.3中HA集群的分布式安装示例”这篇文章吧。
http://spark.apache.org/downloads.html

http://mirrors.hust.edu.cn/apache/
https://mirrors.tuna.tsinghua.edu.cn/apache/
1、Java8安装成功
2、zookeeper安装成功
3、hadoop2.7.5 HA安装成功
4、Scala安装成功(不安装进程也可以启动)
[hadoop@hadoop1 ~]$ lsapps data exam inithive.conf movie spark-2.3.0-bin-hadoop2.7.tgz udf.jar cookies data.txt executions json.txt projects student zookeeper.out course emp hive.sql log sougou temp [hadoop@hadoop1 ~]$ tar -zxvf spark-2.3.0-bin-hadoop2.7.tgz -C apps/
[hadoop@hadoop1 ~]$ cd apps/[hadoop@hadoop1 apps]$ lshadoop-2.7.5 hbase-1.2.6 spark-2.3.0-bin-hadoop2.7 zookeeper-3.4.10 zookeeper.out [hadoop@hadoop1 apps]$ ln -s spark-2.3.0-bin-hadoop2.7/ spark[hadoop@hadoop1 apps]$ ll总用量 36 drwxr-xr-x. 10 hadoop hadoop 4096 3月 23 20:29 hadoop-2.7.5 drwxrwxr-x. 7 hadoop hadoop 4096 3月 29 13:15 hbase-1.2.6 lrwxrwxrwx. 1 hadoop hadoop 26 4月 20 13:48 spark -> spark-2.3.0-bin-hadoop2.7/drwxr-xr-x. 13 hadoop hadoop 4096 2月 23 03:42 spark-2.3.0-bin-hadoop2.7 drwxr-xr-x. 10 hadoop hadoop 4096 3月 23 2017 zookeeper-3.4.10 -rw-rw-r--. 1 hadoop hadoop 17559 3月 29 13:37 zookeeper.out [hadoop@hadoop1 apps]$
(1)进入配置文件所在目录
[hadoop@hadoop1 ~]$ cd apps/spark/conf/[hadoop@hadoop1 conf]$ ll总用量 36 -rw-r--r--. 1 hadoop hadoop 996 2月 23 03:42 docker.properties.template -rw-r--r--. 1 hadoop hadoop 1105 2月 23 03:42 fairscheduler.xml.template -rw-r--r--. 1 hadoop hadoop 2025 2月 23 03:42 log4j.properties.template -rw-r--r--. 1 hadoop hadoop 7801 2月 23 03:42 metrics.properties.template -rw-r--r--. 1 hadoop hadoop 865 2月 23 03:42 slaves.template -rw-r--r--. 1 hadoop hadoop 1292 2月 23 03:42 spark-defaults.conf.template -rwxr-xr-x. 1 hadoop hadoop 4221 2月 23 03:42 spark-env.sh.template [hadoop@hadoop1 conf]$
(2)复制spark-env.sh.template并重命名为spark-env.sh,并在文件最后添加配置内容
[hadoop@hadoop1 conf]$ cp spark-env.sh.template spark-env.sh[hadoop@hadoop1 conf]$ vi spark-env.sh
export JAVA_HOME=/usr/local/jdk1.8.0_73 #export SCALA_HOME=/usr/share/scala export HADOOP_HOME=/home/hadoop/apps/hadoop-2.7.5 export HADOOP_CONF_DIR=/home/hadoop/apps/hadoop-2.7.5/etc/hadoop export SPARK_WORKER_MEMORY=500m export SPARK_WORKER_CORES=1 export SPARK_DAEMON_JAVA_OPTS="-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181 -Dspark.deploy.zookeeper.dir=/spark"
注:
#export SPARK_MASTER_IP=hadoop1 这个配置要注释掉。
集群搭建时配置的spark参数可能和现在的不一样,主要是考虑个人电脑配置问题,如果memory配置太大,机器运行很慢。
说明:
-Dspark.deploy.recoveryMode=ZOOKEEPER #说明整个集群状态是通过zookeeper来维护的,整个集群状态的恢复也是通过zookeeper来维护的。就是说用zookeeper做了spark的HA配置,Master(Active)挂掉的话,Master(standby)要想变成Master(Active)的话,Master(Standby)就要像zookeeper读取整个集群状态信息,然后进行恢复所有Worker和Driver的状态信息,和所有的Application状态信息;
-Dspark.deploy.zookeeper.url=hadoop1:2181,hadoop2:2181,hadoop3:2181,hadoop4:2181#将所有配置了zookeeper,并且在这台机器上有可能做master(Active)的机器都配置进来;(我用了4台,就配置了4台)-Dspark.deploy.zookeeper.dir=/spark
这里的dir和zookeeper配置文件zoo.cfg中的dataDir的区别???
-Dspark.deploy.zookeeper.dir是保存spark的元数据,保存了spark的作业运行状态;
zookeeper会保存spark集群的所有的状态信息,包括所有的Workers信息,所有的Applactions信息,所有的Driver信息,如果集群
(3)复制slaves.template成slaves
[hadoop@hadoop1 conf]$ cp slaves.template slaves[hadoop@hadoop1 conf]$ vi slaves
添加如下内容
hadoop1 hadoop2 hadoop3 hadoop4
(4)将安装包分发给其他节点
[hadoop@hadoop1 ~]$ cd apps/[hadoop@hadoop1 apps]$ scp -r spark-2.3.0-bin-hadoop2.7/ hadoop2:$PWD[hadoop@hadoop1 apps]$ scp -r spark-2.3.0-bin-hadoop2.7/ hadoop3:$PWD[hadoop@hadoop1 apps]$ scp -r spark-2.3.0-bin-hadoop2.7/ hadoop4:$PWD
创建软连接
[hadoop@hadoop2 ~]$ cd apps/[hadoop@hadoop2 apps]$ lshadoop-2.7.5 hbase-1.2.6 spark-2.3.0-bin-hadoop2.7 zookeeper-3.4.10 [hadoop@hadoop2 apps]$ ln -s spark-2.3.0-bin-hadoop2.7/ spark[hadoop@hadoop2 apps]$ ll总用量 16 drwxr-xr-x 10 hadoop hadoop 4096 3月 23 20:29 hadoop-2.7.5 drwxrwxr-x 7 hadoop hadoop 4096 3月 29 13:15 hbase-1.2.6 lrwxrwxrwx 1 hadoop hadoop 26 4月 20 19:26 spark -> spark-2.3.0-bin-hadoop2.7/drwxr-xr-x 13 hadoop hadoop 4096 4月 20 19:24 spark-2.3.0-bin-hadoop2.7drwxr-xr-x 10 hadoop hadoop 4096 3月 21 19:31 zookeeper-3.4.10 [hadoop@hadoop2 apps]$
所有节点均要配置
[hadoop@hadoop1 spark]$ vi ~/.bashrc
#Spark export SPARK_HOME=/home/hadoop/apps/spark export PATH=$PATH:$SPARK_HOME/bin
保存并使其立即生效
[hadoop@hadoop1 spark]$ source ~/.bashrc
所有节点均要执行
[hadoop@hadoop1 ~]$ zkServer.sh startZooKeeper JMX enabled by default Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg Starting zookeeper ... STARTED [hadoop@hadoop1 ~]$ zkServer.sh statusZooKeeper JMX enabled by default Using config: /home/hadoop/apps/zookeeper-3.4.10/bin/../conf/zoo.cfg Mode: follower[hadoop@hadoop1 ~]$
任意一个节点执行即可
[hadoop@hadoop1 ~]$ start-dfs.sh
在一个节点上执行
[hadoop@hadoop1 ~]$ cd apps/spark/sbin/[hadoop@hadoop1 sbin]$ start-all.sh
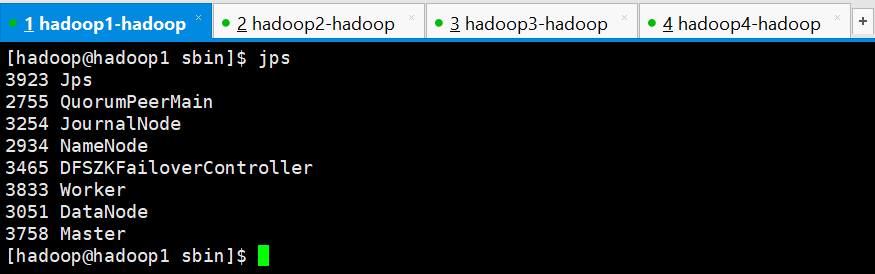
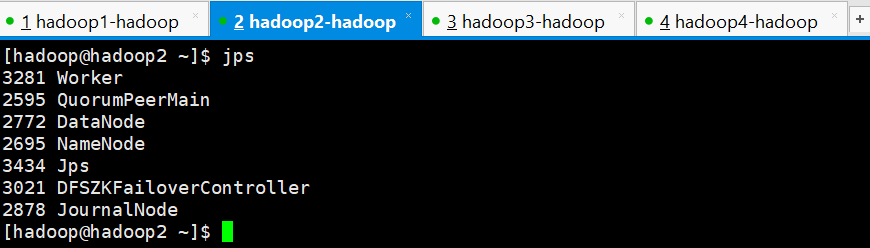
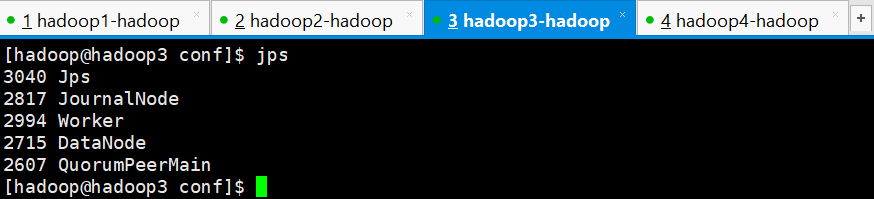
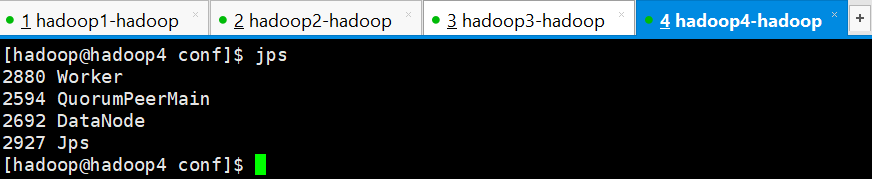
查看进程发现spark集群只有hadoop1成功启动了Master进程,其他3个节点均没有启动成功,需要手动启动,进入到/home/hadoop/apps/spark/sbin目录下执行以下命令,3个节点都要执行
[hadoop@hadoop2 ~]$ cd ~/apps/spark/sbin/ [hadoop@hadoop2 sbin]$ start-master.sh
Master进程和Worker进程都以启动成功
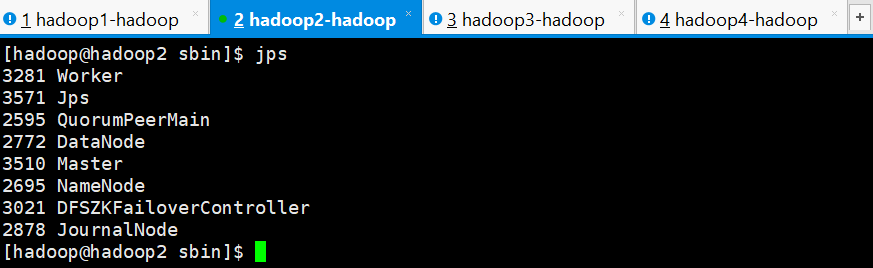
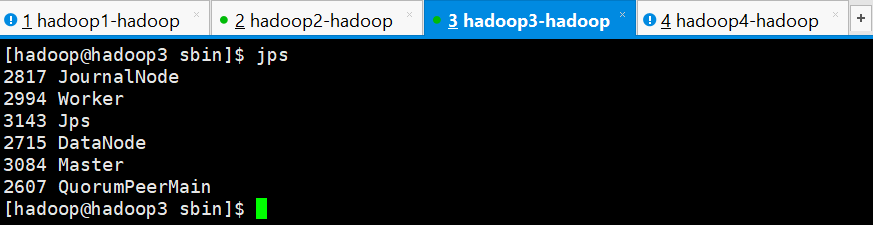
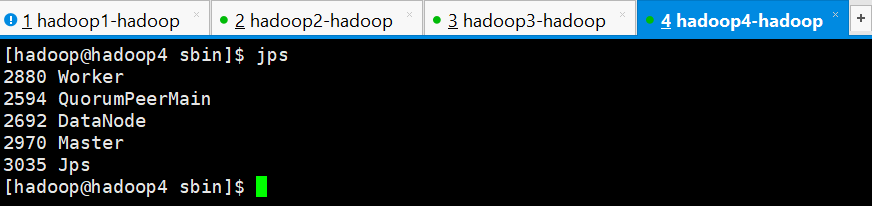
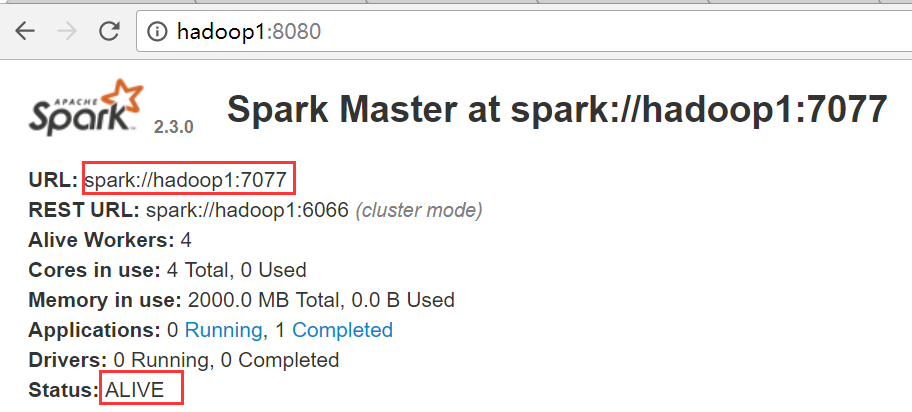
hadoop1是ALIVE状态,hadoop2、hadoop3和hadoop4均是STANDBY状态
hadoop1节点
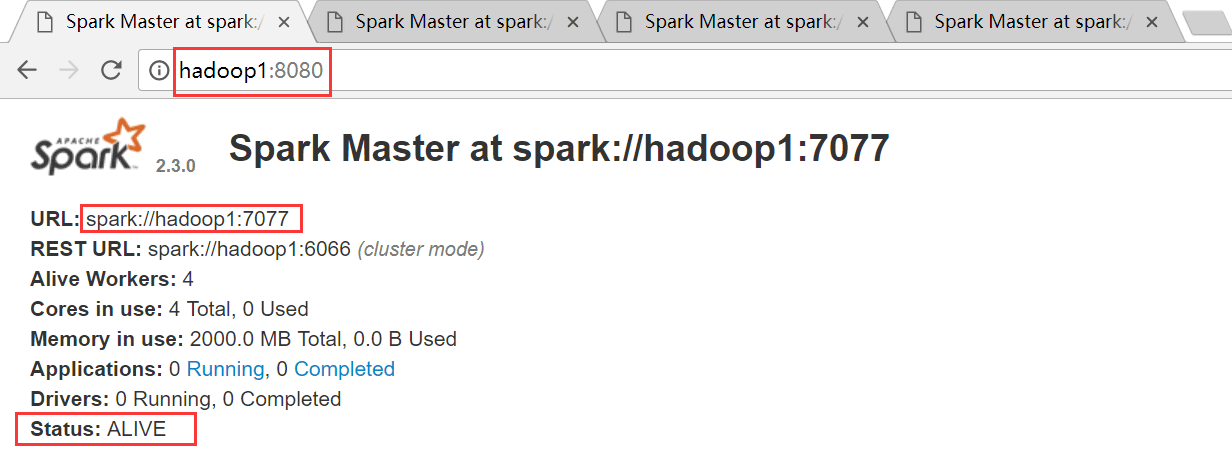
hadoop2节点
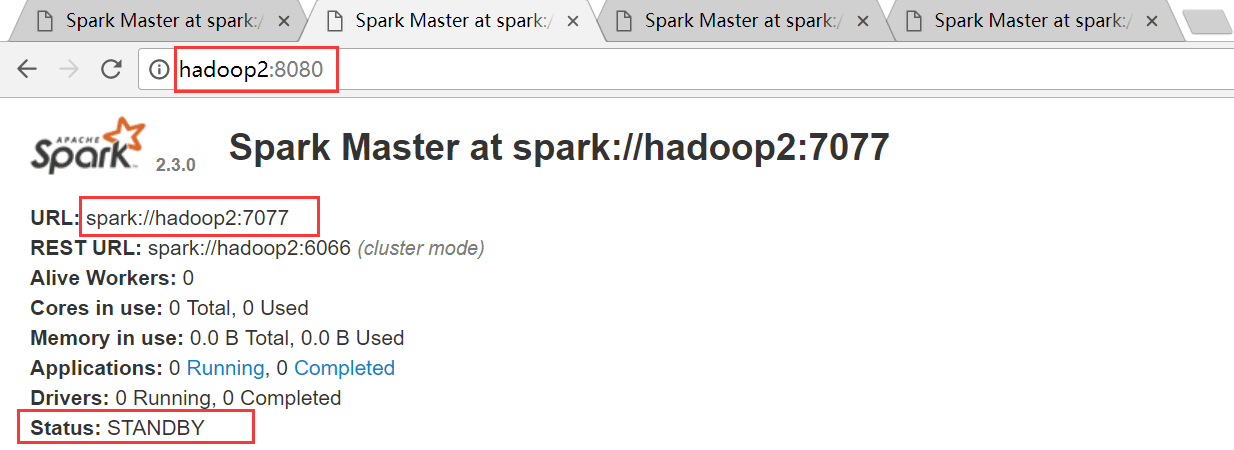
hadoop3
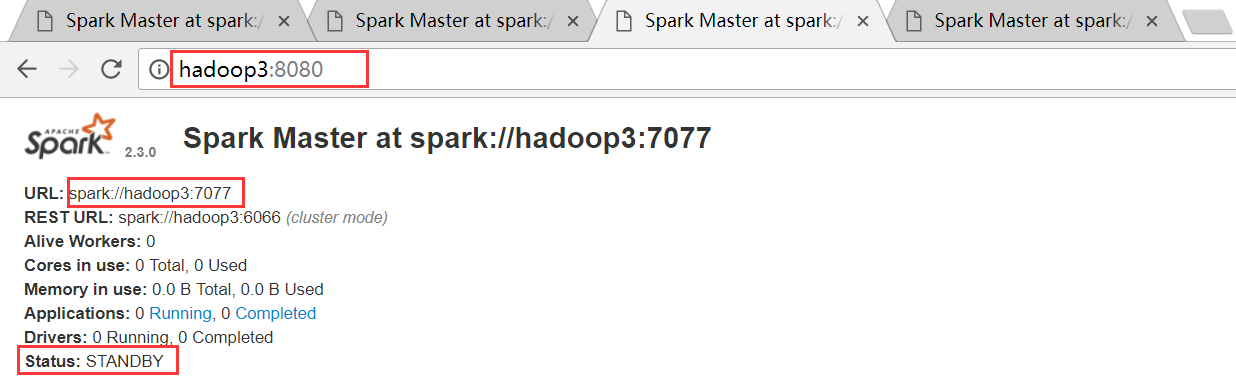
hadoop4
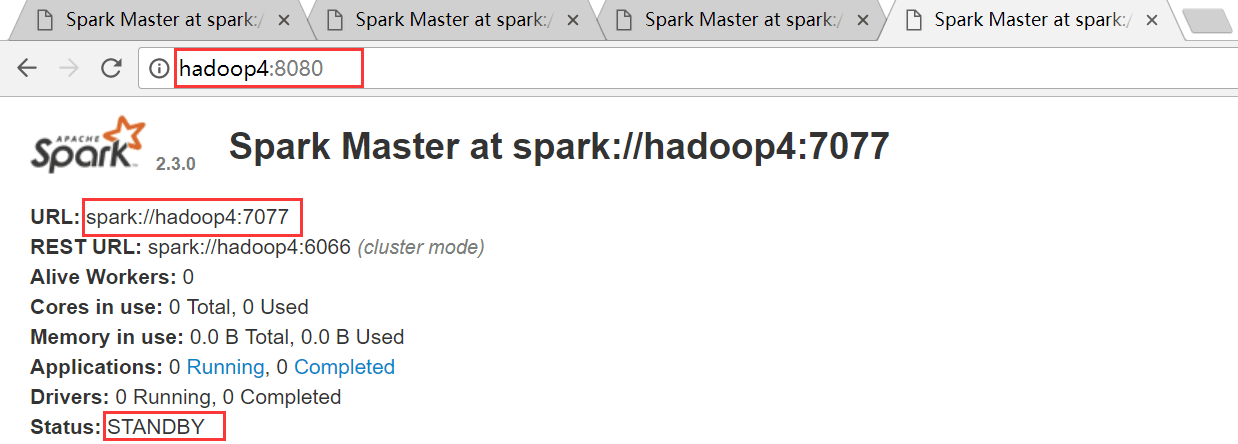
手动干掉hadoop1上面的Master进程,观察是否会自动进行切换
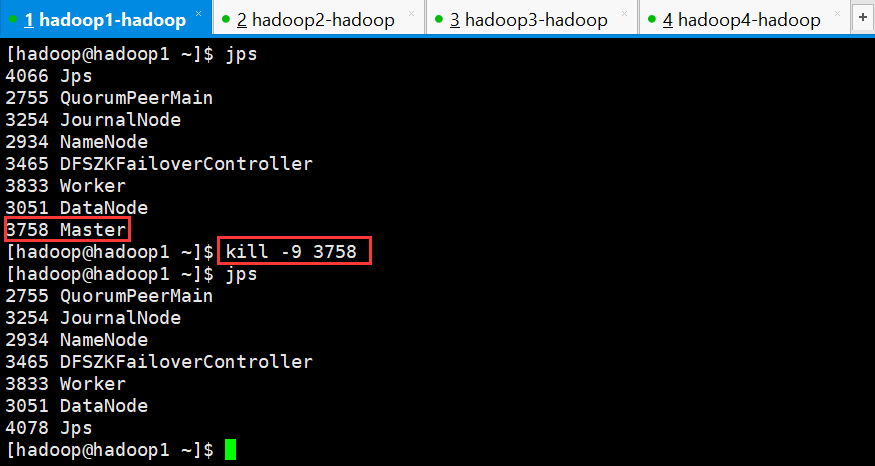
干掉hadoop1上的Master进程之后,再次查看web界面
hadoo1节点,由于Master进程被干掉,所以界面无法访问
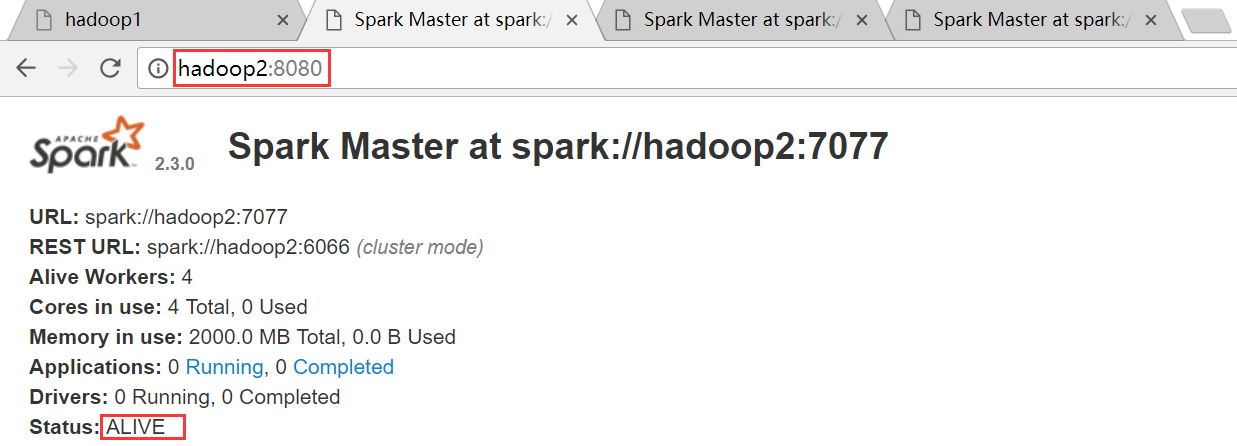
hadoop2节点,Master被干掉之后,hadoop2节点上的Master成功篡位成功,成为ALIVE状态
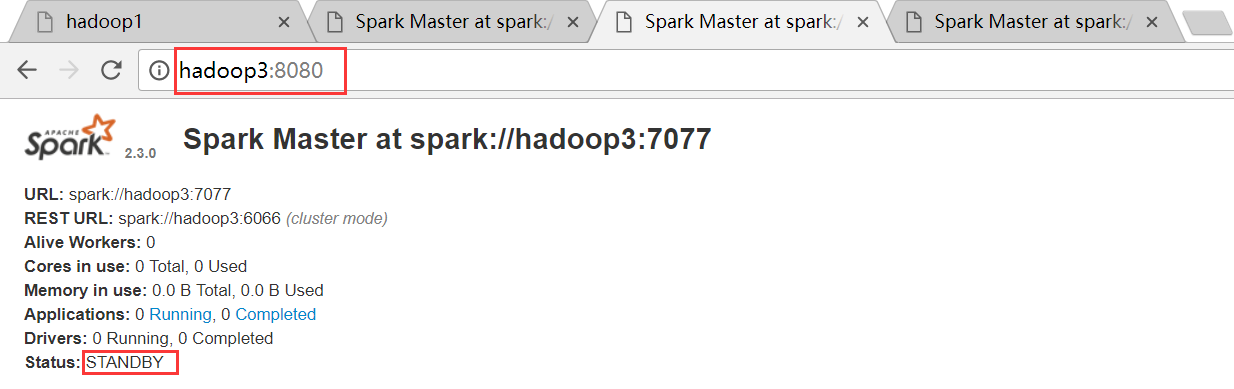
hadoop3节点
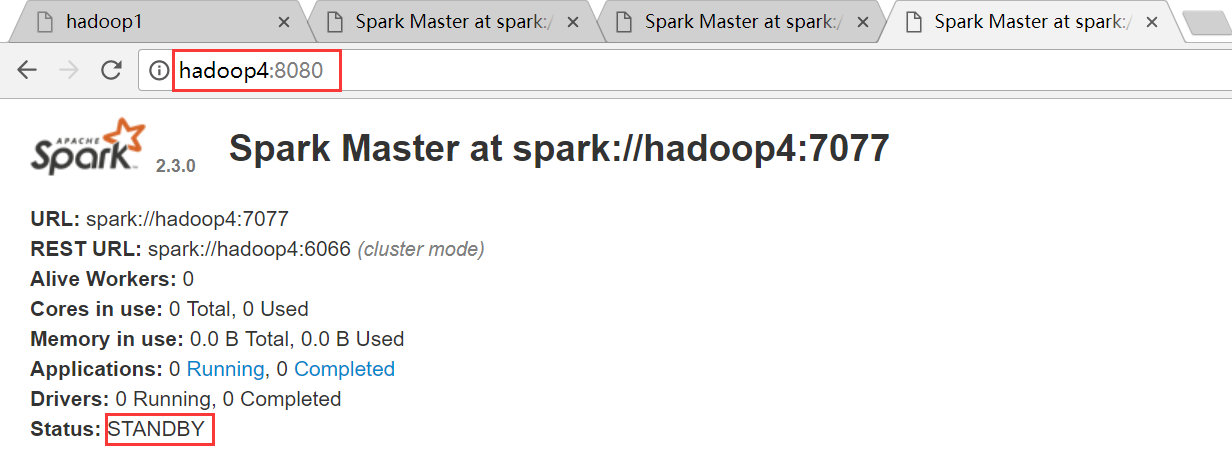
hadoop4节点
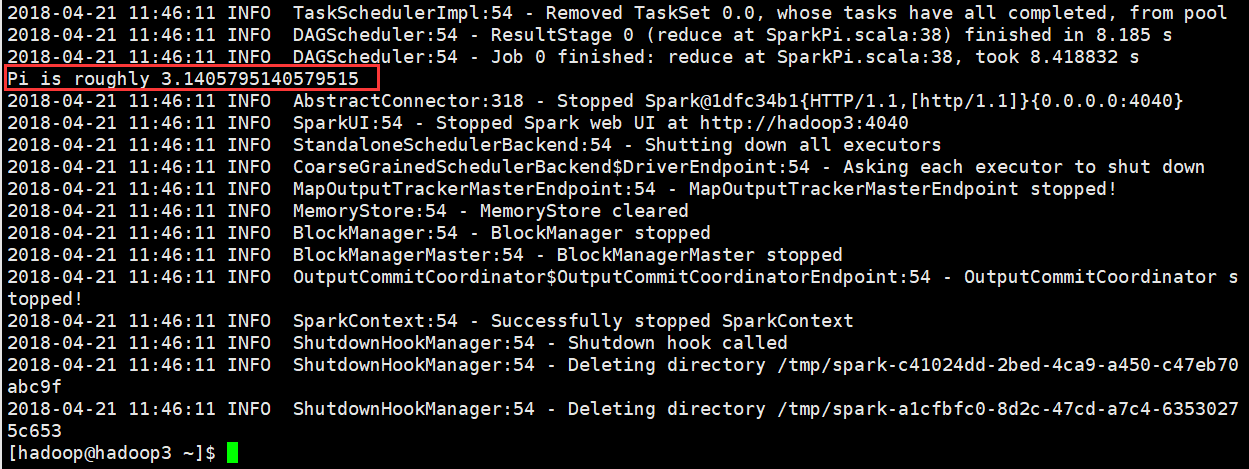
[hadoop@hadoop3 ~]$ /home/hadoop/apps/spark/bin/spark-submit \ > --class org.apache.spark.examples.SparkPi \ > --master spark://hadoop1:7077 \ > --executor-memory 500m \ > --total-executor-cores 1 \ > /home/hadoop/apps/spark/examples/jars/spark-examples_2.11-2.3.0.jar \ > 100
其中的spark://hadoop1:7077是下图中的地址
运行结果
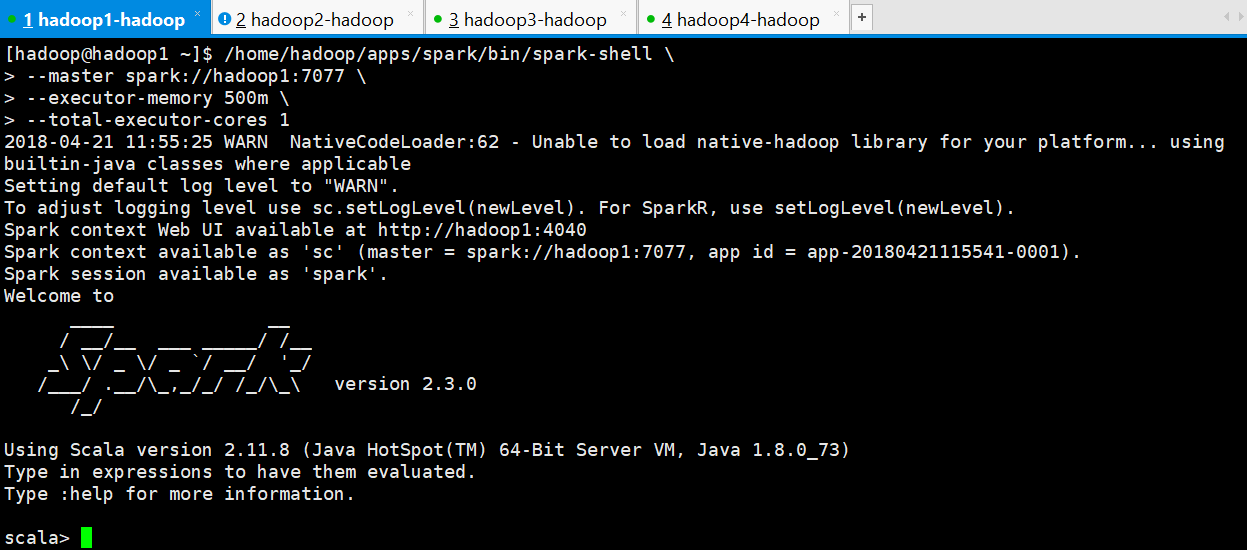
[hadoop@hadoop1 ~]$ /home/hadoop/apps/spark/bin/spark-shell \> --master spark://hadoop1:7077 \> --executor-memory 500m \> --total-executor-cores 1
参数说明:
--master spark://hadoop1:7077 指定Master的地址
--executor-memory 500m:指定每个worker可用内存为500m
--total-executor-cores 1: 指定整个集群使用的cup核数为1个
注意:
如果启动spark shell时没有指定master地址,但是也可以正常启动spark shell和执行spark shell中的程序,其实是启动了spark的local模式,该模式仅在本机启动一个进程,没有与集群建立联系。
Spark Shell中已经默认将SparkContext类初始化为对象sc。用户代码如果需要用到,则直接应用sc即可
Spark Shell中已经默认将SparkSQl类初始化为对象spark。用户代码如果需要用到,则直接应用spark即可
(1)编写一个hello.txt文件并上传到HDFS上的spark目录下
[hadoop@hadoop1 ~]$ vi hello.txt [hadoop@hadoop1 ~]$ hadoop fs -mkdir -p /spark [hadoop@hadoop1 ~]$ hadoop fs -put hello.txt /spark
hello.txt的内容如下
you,jump i,jump you,jump i,jump jump
(2)在spark shell中用scala语言编写spark程序
scala> sc.textFile("/spark/hello.txt").flatMap(_.split(",")).map((_,1)).reduceByKey(_+_).saveAsTextFile("/spark/out")说明:
sc是SparkContext对象,该对象是提交spark程序的入口
textFile("/spark/hello.txt")是hdfs中读取数据
flatMap(_.split(" "))先map再压平
map((_,1))将单词和1构成元组
reduceByKey(_+_)按照key进行reduce,并将value累加
saveAsTextFile("/spark/out")将结果写入到hdfs中
(3)使用hdfs命令查看结果
[hadoop@hadoop2 ~]$ hadoop fs -cat /spark/out/p* (jump,5) (you,2) (i,2) [hadoop@hadoop2 ~]$

成功启动zookeeper集群、HDFS集群、YARN集群
[hadoop@hadoop1 bin]$ spark-shell --master yarn --deploy-mode client
报错如下:
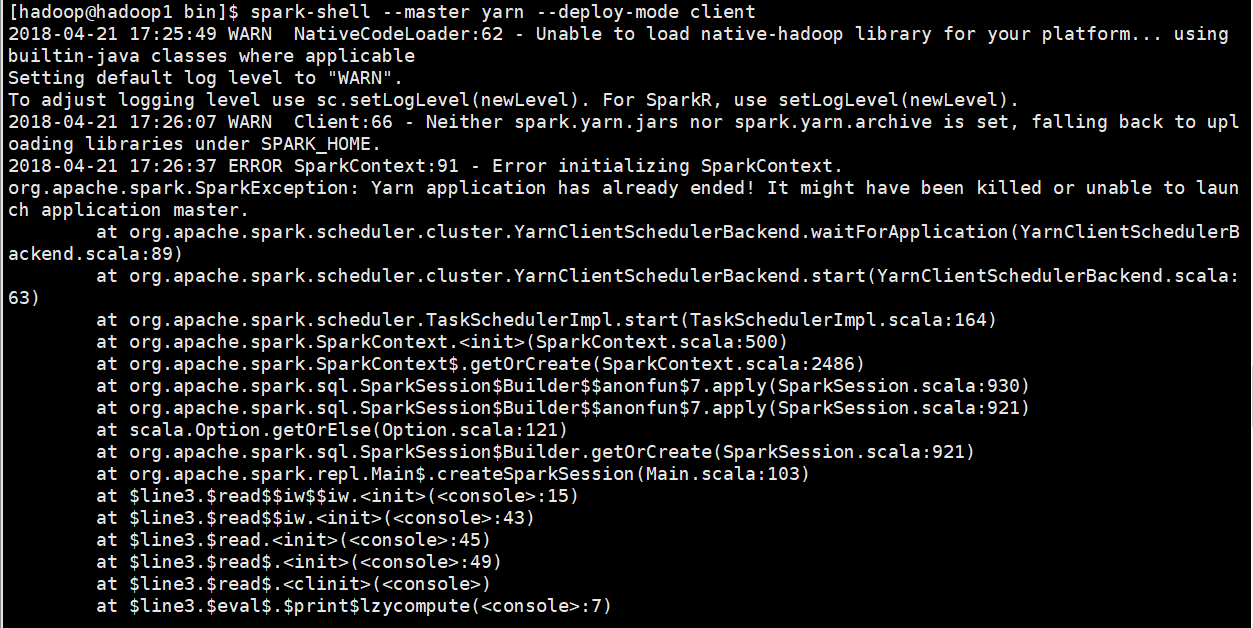
报错原因:内存资源给的过小,yarn直接kill掉进程,则报rpc连接失败、ClosedChannelException等错误。
解决方法:
先停止YARN服务,然后修改yarn-site.xml,增加如下内容
<property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> <description>Whether virtual memory limits will be enforced for containers</description> </property> <property> <name>yarn.nodemanager.vmem-pmem-ratio</name> <value>4</value> <description>Ratio between virtual memory to physical memory when setting memory limits for containers</description> </property>
将新的yarn-site.xml文件分发到其他Hadoop节点对应的目录下,最后在重新启动YARN。
重新执行以下命令启动spark on yarn
[hadoop@hadoop1 hadoop]$ spark-shell --master yarn --deploy-mode client
启动成功
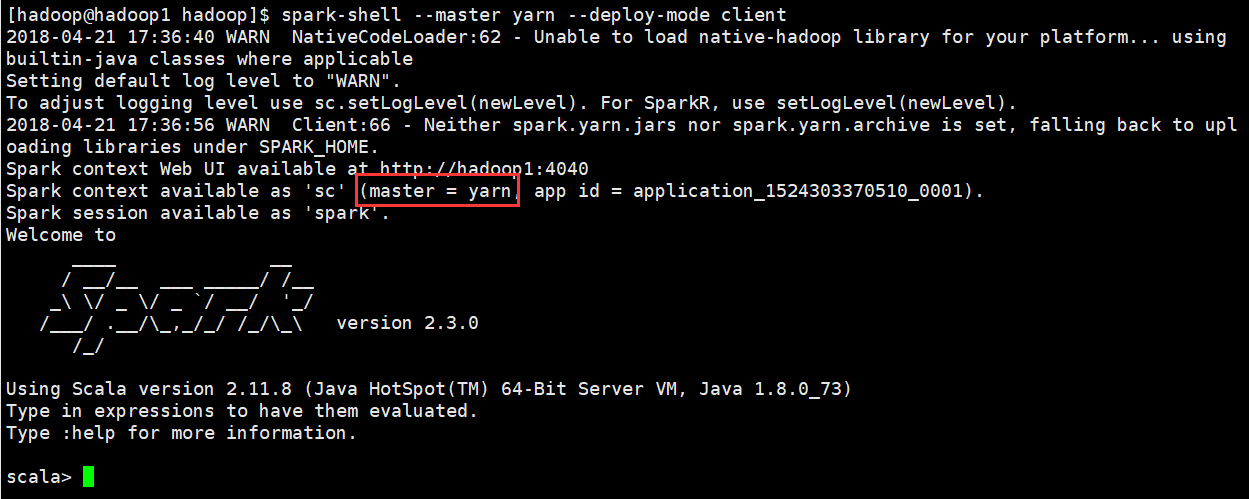
打开YARN WEB页面:http://hadoop4:8088
可以看到Spark shell应用程序正在运行
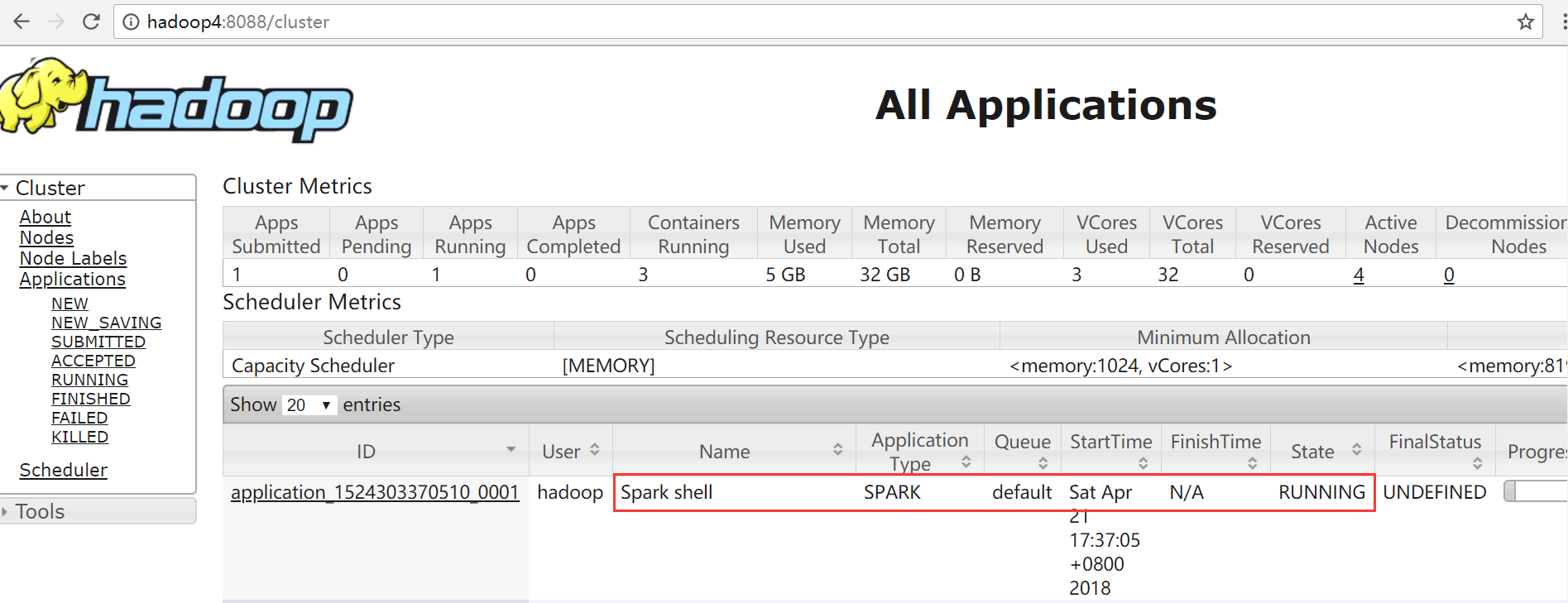
单击ID号链接,可以看到该应用程序的详细信息
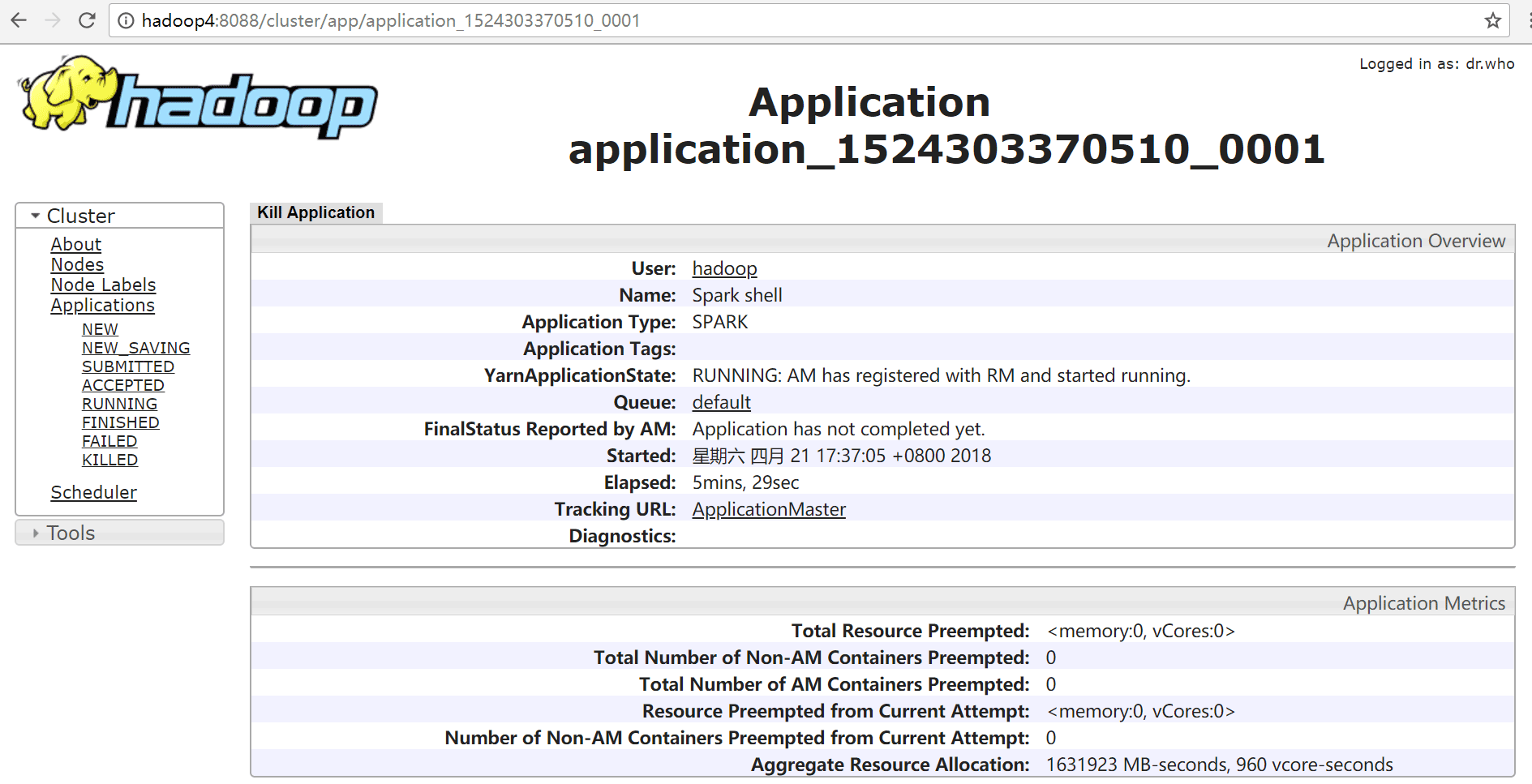
单击“ApplicationMaster”链接
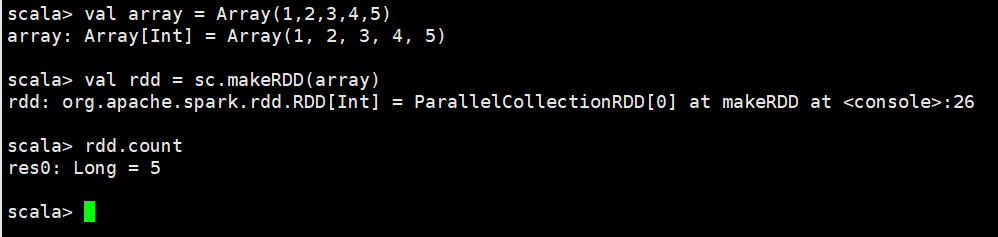
scala> val array = Array(1,2,3,4,5) array: Array[Int] = Array(1, 2, 3, 4, 5) scala> val rdd = sc.makeRDD(array) rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:26 scala> rdd.count res0: Long = 5 scala>
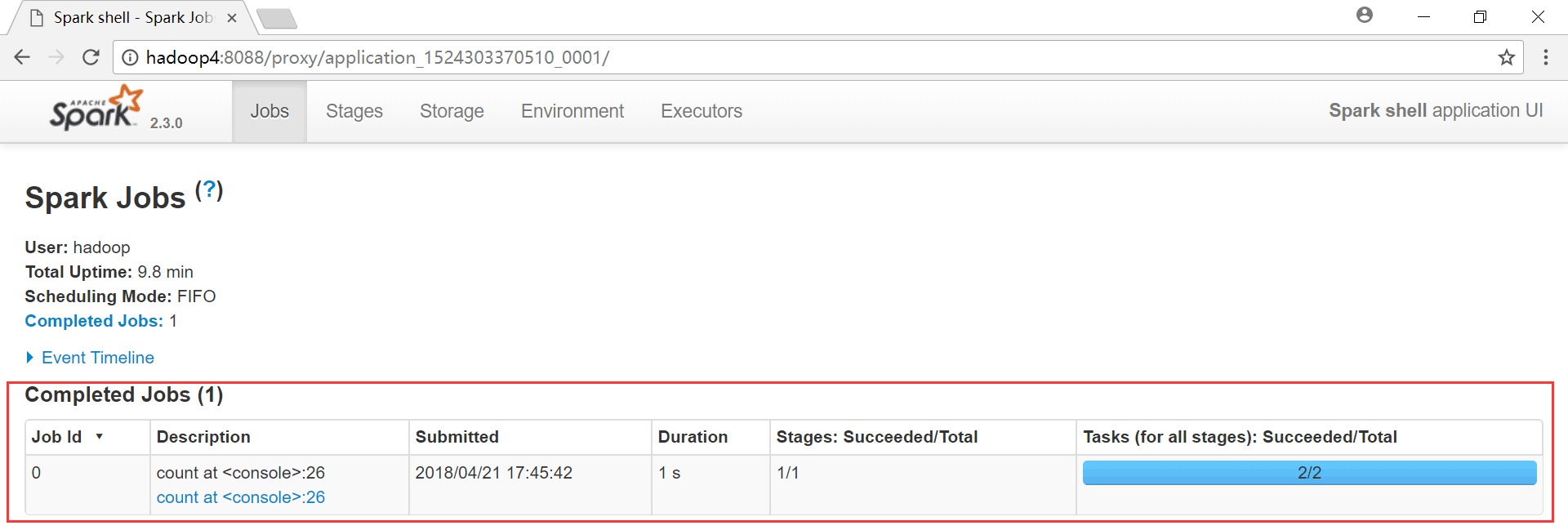
再次查看YARN的web界面
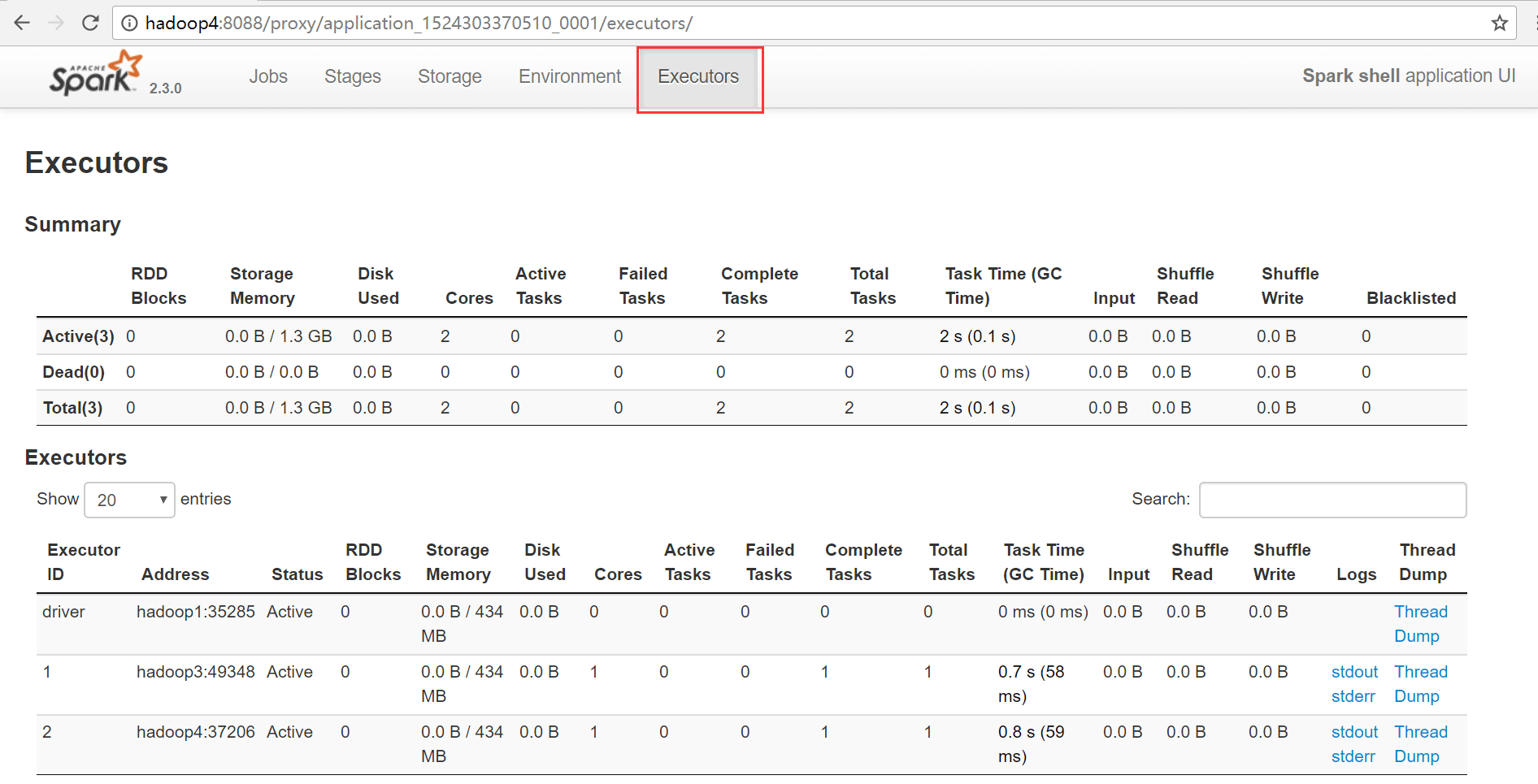
查看executors
[hadoop@hadoop1 ~]$ spark-submit --class org.apache.spark.examples.SparkPi \ > --master yarn \ > --deploy-mode cluster \ > --driver-memory 500m \ > --executor-memory 500m \ > --executor-cores 1 \ > /home/hadoop/apps/spark/examples/jars/spark-examples_2.11-2.3.0.jar \ > 10
执行过程
[hadoop@hadoop1 ~]$ spark-submit --class org.apache.spark.examples.SparkPi \ > --master yarn \ > --deploy-mode cluster \ > --driver-memory 500m \ > --executor-memory 500m \ > --executor-cores 1 \ > /home/hadoop/apps/spark/examples/jars/spark-examples_2.11-2.3.0.jar \ > 10 2018-04-21 17:57:32 WARN NativeCodeLoader:62 - Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 2018-04-21 17:57:34 INFO ConfiguredRMFailoverProxyProvider:100 - Failing over to rm2 2018-04-21 17:57:34 INFO Client:54 - Requesting a new application from cluster with 4 NodeManagers 2018-04-21 17:57:34 INFO Client:54 - Verifying our application has not requested more than the maximum memory capability of the cluster (8192 MB per container) 2018-04-21 17:57:34 INFO Client:54 - Will allocate AM container, with 884 MB memory including 384 MB overhead 2018-04-21 17:57:34 INFO Client:54 - Setting up container launch context for our AM 2018-04-21 17:57:34 INFO Client:54 - Setting up the launch environment for our AM container 2018-04-21 17:57:34 INFO Client:54 - Preparing resources for our AM container 2018-04-21 17:57:36 WARN Client:66 - Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME. 2018-04-21 17:57:39 INFO Client:54 - Uploading resource file:/tmp/spark-93bd68c9-85de-482e-bbd7-cd2cee60e720/__spark_libs__8262081479435245591.zip -> hdfs://myha01/user/hadoop/.sparkStaging/application_1524303370510_0005/__spark_libs__8262081479435245591.zip 2018-04-21 17:57:44 INFO Client:54 - Uploading resource file:/home/hadoop/apps/spark/examples/jars/spark-examples_2.11-2.3.0.jar -> hdfs://myha01/user/hadoop/.sparkStaging/application_1524303370510_0005/spark-examples_2.11-2.3.0.jar 2018-04-21 17:57:44 INFO Client:54 - Uploading resource file:/tmp/spark-93bd68c9-85de-482e-bbd7-cd2cee60e720/__spark_conf__2498510663663992254.zip -> hdfs://myha01/user/hadoop/.sparkStaging/application_1524303370510_0005/__spark_conf__.zip 2018-04-21 17:57:44 INFO SecurityManager:54 - Changing view acls to: hadoop 2018-04-21 17:57:44 INFO SecurityManager:54 - Changing modify acls to: hadoop 2018-04-21 17:57:44 INFO SecurityManager:54 - Changing view acls groups to: 2018-04-21 17:57:44 INFO SecurityManager:54 - Changing modify acls groups to: 2018-04-21 17:57:44 INFO SecurityManager:54 - SecurityManager: authentication disabled; ui acls disabled; users with view permissions: Set(hadoop); groups with view permissions: Set(); users with modify permissions: Set(hadoop); groups with modify permissions: Set() 2018-04-21 17:57:44 INFO Client:54 - Submitting application application_1524303370510_0005 to ResourceManager 2018-04-21 17:57:44 INFO YarnClientImpl:273 - Submitted application application_1524303370510_0005 2018-04-21 17:57:45 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:45 INFO Client:54 - client token: N/A diagnostics: N/A ApplicationMaster host: N/A ApplicationMaster RPC port: -1 queue: default start time: 1524304664749 final status: UNDEFINED tracking URL: http://hadoop4:8088/proxy/application_1524303370510_0005/ user: hadoop 2018-04-21 17:57:46 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:47 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:48 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:49 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:50 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:51 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:52 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:53 INFO Client:54 - Application report for application_1524303370510_0005 (state: ACCEPTED) 2018-04-21 17:57:54 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:57:54 INFO Client:54 - client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.123.104 ApplicationMaster RPC port: 0 queue: default start time: 1524304664749 final status: UNDEFINED tracking URL: http://hadoop4:8088/proxy/application_1524303370510_0005/ user: hadoop 2018-04-21 17:57:55 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:57:56 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:57:57 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:57:58 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:57:59 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:00 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:01 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:02 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:03 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:04 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:05 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:06 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:07 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:08 INFO Client:54 - Application report for application_1524303370510_0005 (state: RUNNING) 2018-04-21 17:58:09 INFO Client:54 - Application report for application_1524303370510_0005 (state: FINISHED) 2018-04-21 17:58:09 INFO Client:54 - client token: N/A diagnostics: N/A ApplicationMaster host: 192.168.123.104 ApplicationMaster RPC port: 0 queue: default start time: 1524304664749 final status: SUCCEEDED tracking URL: http://hadoop4:8088/proxy/application_1524303370510_0005/ user: hadoop 2018-04-21 17:58:09 INFO Client:54 - Deleted staging directory hdfs://myha01/user/hadoop/.sparkStaging/application_1524303370510_0005 2018-04-21 17:58:09 INFO ShutdownHookManager:54 - Shutdown hook called 2018-04-21 17:58:09 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-93bd68c9-85de-482e-bbd7-cd2cee60e720 2018-04-21 17:58:09 INFO ShutdownHookManager:54 - Deleting directory /tmp/spark-06de6905-8067-4f1e-a0a0-bc8a51daf535 [hadoop@hadoop1 ~]$
以上是“Spark2.3中HA集群的分布式安装示例”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。