жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дёҖгҖҒж•…йҡңжҸҸиҝ°
еҢ—дә¬дёҖ家еҢ»йҷўзҡ„EMC FC AX-4еӯҳеӮЁеҙ©жәғгҖҒraidзҳ«з—ӘгҖӮеҢ—дәҡж•°жҚ®жҒўеӨҚдёӯеҝғжҺҘеҲ°е®ўжҲ·з”өиҜқеҗҺ第дёҖж—¶й—ҙе®үжҺ’е·ҘзЁӢеёҲжҗәеёҰжңҚеҠЎеҷЁиө¶иөҙз”ЁжҲ·зҺ°еңәгҖӮз»ҸиҝҮе·ҘзЁӢеёҲеҲқжЈҖеҸ‘зҺ°еӯҳеӮЁз©әй—ҙз”ұ1TB STATзҡ„зЎ¬зӣҳе…ұ12еқ—з»„жҲҗraid5пјҢе…¶дёӯдёӨеқ—жҳҜзғӯеӨҮзӣҳпјҢзӣ®еүҚи®ҫеӨҮдёӯжңүдёӨеқ—зЎ¬зӣҳжҚҹеқҸдҪҶеҸӘжңүдёҖеқ—зғӯеӨҮзӣҳжҝҖжҙ»жҲҗеҠҹпјҢеӣ жӯӨжӯӨraid5йҳөеҲ—зҳ«з—ӘгҖҒдёҠеұӮlunж— жі•жӯЈеёёдҪҝз”ЁгҖӮе…ҲеҜ№жүҖд»ҘзЈҒзӣҳиҝӣиЎҢзү©зҗҶжЈҖжөӢжІЎжңүеҸ‘зҺ°зү©зҗҶж•…йҡңпјҢеҗҺдҪҝз”ЁеқҸйҒ“жЈҖжөӢе·Ҙе…·иҝӣиЎҢеқҸйҒ“жЈҖжөӢд№ҹжІЎжңүеқҸйҒ“еӯҳеңЁгҖӮ</br>
</br>
дәҢгҖҒеӨҮд»Ҫж•°жҚ®
з”ұдәҺж•°жҚ®жҒўеӨҚе·ҘдҪңзҡ„зү№ж®ҠжҖ§пјҢеңЁж•°жҚ®жҒўеӨҚд№ӢеүҚеҝ…йЎ»еҜ№жүҖжңүеҺҹе§Ӣж•°жҚ®иҝӣиЎҢеӨҮд»ҪпјҢеңЁжң¬ж¬Ўraid5ж•°жҚ®жҒўеӨҚдёӯжҲ‘们дҪҝз”ЁwinhexжҠҠе…ЁйғЁзЈҒзӣҳй•ңеғҸжҲҗж–Ү件пјҢз”ұдәҺжәҗзЈҒзӣҳзҡ„жүҮеҢәеӨ§е°ҸжҳҜ520еӯ—иҠӮпјҢжүҖд»ҘиҝҳйңҖиҰҒдҪҝз”Ёзү№ж®Ҡе·Ҙе…·жҠҠжүҖжңүеӨҮд»Ҫзҡ„ж•°жҚ®еҶҚеҒҡ520 to 512еӯ—иҠӮзҡ„иҪ¬жҚўгҖӮ
</br>
дёүгҖҒж•…йҡңеҲҶжһҗеҸҠжҒўеӨҚиҝҮзЁӢ
1гҖҒеҲҶжһҗж•…йҡңеҺҹеӣ гҖӮз”ұдәҺи®ҫеӨҮдёӯ并дёҚеӯҳеңЁзү©зҗҶж•…йҡңе’ҢеқҸйҒ“пјҢз”ұжӯӨжҺЁж–ӯж•…йҡңеҺҹеӣ жҳҜйғЁеҲҶзЈҒзӣҳиҜ»еҶҷдёҚзЁіе®ҡеҜјиҮҙзҡ„пјҢеӣ дёәEMCжҺ§еҲ¶еҷЁжңүзқҖйқһеёёдёҘж јзҡ„жЈҖжҹҘзЈҒзӣҳзӯ–з•ҘпјҢеҰӮжһңеҸ‘з”ҹзЈҒзӣҳжҖ§иғҪдёҚзЁіе®ҡзҡ„жғ…еҶөе°ұдјҡиў«EMCжҺ§еҲ¶еҷЁи®Өе®ҡдёәеқҸзӣҳиёўеҮәraidз»„пјҢеҪ“raidз»„дёӯжҺүзәҝзӣҳиҫҫеҲ°raidзә§еҲ«зҡ„е…Ғи®ёжҺүзӣҳжһҒйҷҗпјҢжӯӨraidз»„еҚідёҚеҸҜз”ЁпјҢеҹәдәҺжӯӨraidзҡ„дёҠеұӮlunдёҚеҸҜз”ЁгҖӮеңЁжң¬жЎҲдҫӢдёӯеҸӘжңүдёҖдёӘlunеҲҶй…Қз»ҷsunе°ҸжңәпјҢдёҠеұӮж–Ү件系з»ҹжҳҜZFSгҖӮ</br>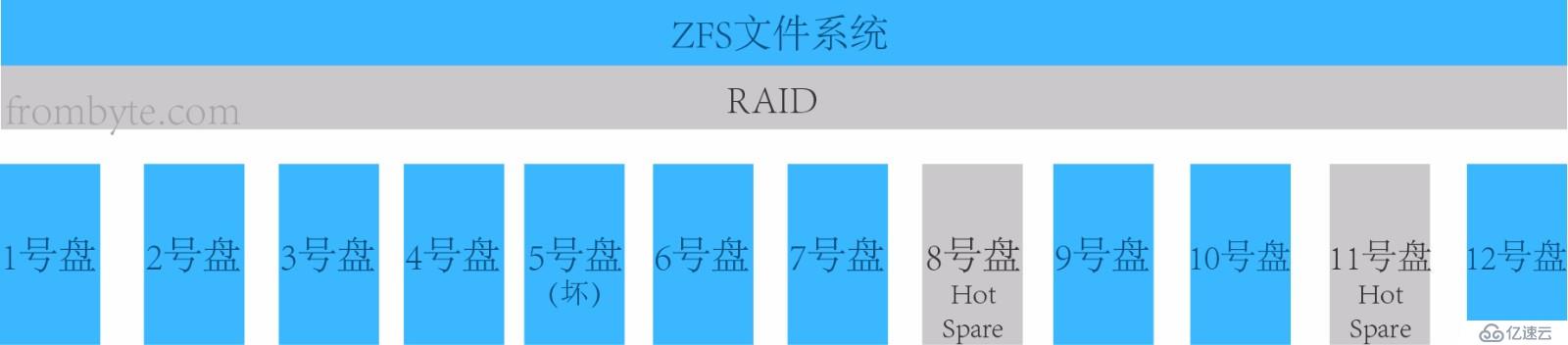
</br>
2гҖҒеҲҶжһҗRAIDз»„з»“жһ„гҖӮEMCеӯҳеӮЁзҡ„LUNйғҪжҳҜеҹәдәҺRAIDз»„зҡ„пјҢеӣ жӯӨйңҖиҰҒе…ҲеҲҶжһҗеә•еұӮRAIDз»„зҡ„дҝЎжҒҜпјҢ然еҗҺж №жҚ®еҲҶжһҗзҡ„дҝЎжҒҜйҮҚжһ„еҺҹе§Ӣзҡ„RAIDз»„гҖӮйҖҡиҝҮеҜ№жүҖжңүзЎ¬зӣҳж•°жҚ®еҲҶжһҗеҸ‘зҺ°8еҸ·зӣҳе’Ң11еҸ·зӣҳе®Ңе…ЁжІЎжңүж•°жҚ®пјҢд»Һз®ЎзҗҶз•ҢйқўдёҠеҸҜд»ҘзңӢеҲ°8еҸ·зӣҳе’Ң11еҸ·зӣҳйғҪеұһдәҺHot SpareпјҢдҪҶ8еҸ·зӣҳзҡ„Hot SpareжӣҝжҚўдәҶ5еҸ·зӣҳзҡ„еқҸзӣҳгҖӮеӣ жӯӨеҸҜд»ҘеҲӨж–ӯиҷҪ然8еҸ·зӣҳзҡ„Hot SpareиҷҪ然жҲҗеҠҹжҝҖжҙ»пјҢдҪҶз”ұдәҺRAIDзә§еҲ«дёәRAID5пјҢжӯӨж—¶RAIDз»„дёӯиҝҳзјәеӨұдёҖеқ—зЎ¬зӣҳпјҢжүҖд»ҘеҜјиҮҙж•°жҚ®жІЎжңүеҗҢжӯҘеҲ°8еҸ·зЎ¬зӣҳдёӯпјҲfrombyte.comпјүгҖӮ继з»ӯеҲҶжһҗе…¶д»–10еқ—зЎ¬зӣҳпјҢеҲҶжһҗж•°жҚ®еңЁзЎ¬зӣҳдёӯеҲҶеёғзҡ„规еҫӢпјҢRAIDжқЎеёҰзҡ„еӨ§е°ҸпјҢд»ҘеҸҠжҜҸеқ—зЈҒзӣҳзҡ„йЎәеәҸгҖӮ
</br>
3гҖҒеҲҶжһҗRAIDз»„жҺүзәҝзӣҳгҖӮж №жҚ®дёҠиҝ°еҲҶжһҗзҡ„RAIDдҝЎжҒҜпјҢе°қиҜ•йҖҡиҝҮеҢ—дәҡиҮӘдё»ејҖеҸ‘зҡ„RAIDиҷҡжӢҹзЁӢеәҸе°ҶеҺҹе§Ӣзҡ„RAIDз»„иҷҡжӢҹеҮәжқҘгҖӮдҪҶз”ұдәҺж•ҙдёӘRAIDз»„дёӯдёҖе…ұжҺүзәҝдёӨеқ—зӣҳпјҢеӣ жӯӨйңҖиҰҒеҲҶжһҗиҝҷдёӨеқ—зЎ¬зӣҳжҺүзәҝзҡ„йЎәеәҸгҖӮд»”з»ҶеҲҶжһҗжҜҸдёҖеқ—зЎ¬зӣҳдёӯзҡ„ж•°жҚ®пјҢеҸ‘зҺ°жңүдёҖеқ—зЎ¬зӣҳеңЁеҗҢдёҖдёӘжқЎеёҰдёҠзҡ„ж•°жҚ®е’Ңе…¶д»–зЎ¬зӣҳжҳҺжҳҫдёҚдёҖж ·пјҢеӣ жӯӨеҲқжӯҘеҲӨж–ӯжӯӨзЎ¬зӣҳеҸҜиғҪжҳҜжңҖе…ҲжҺүзәҝзҡ„пјҢйҖҡиҝҮеҢ—дәҡиҮӘдё»ејҖеҸ‘зҡ„RAIDж ЎйӘҢзЁӢеәҸеҜ№иҝҷдёӘжқЎеёҰеҒҡж ЎйӘҢпјҢеҸ‘зҺ°йҷӨжҺүеҲҡжүҚеҲҶжһҗзҡ„йӮЈеқ—зЎ¬зӣҳеҫ—еҮәзҡ„ж•°жҚ®жҳҜжңҖеҘҪзҡ„пјҢеӣ жӯӨеҸҜд»ҘжҳҺзЎ®жңҖе…ҲжҺүзәҝзҡ„зЎ¬зӣҳдәҶгҖӮ
</br>
4гҖҒеҲҶжһҗRAIDз»„дёӯзҡ„LUNдҝЎжҒҜгҖӮз”ұдәҺLUNжҳҜеҹәдәҺRAIDз»„зҡ„пјҢеӣ жӯӨйңҖиҰҒж №жҚ®дёҠиҝ°еҲҶжһҗзҡ„дҝЎжҒҜе°ҶRAIDз»„йҮҚз»„еҮәжқҘгҖӮ然еҗҺеҲҶжһҗLUNеңЁRAIDз»„дёӯзҡ„еҲҶй…ҚдҝЎжҒҜпјҢд»ҘеҸҠLUNеҲҶй…Қзҡ„ж•°жҚ®еқ—MAPгҖӮз”ұдәҺеә•еұӮеҸӘжңүдёҖдёӘLUNпјҢеӣ жӯӨеҸӘйңҖиҰҒеҲҶжһҗдёҖд»ҪLUNдҝЎжҒҜе°ұOKдәҶгҖӮ然еҗҺж №жҚ®иҝҷдәӣдҝЎжҒҜдҪҝз”ЁеҢ—дәҡraidжҒўеӨҚ(frombyte.com)зЁӢеәҸпјҢи§ЈйҮҠLUNзҡ„ж•°жҚ®MAP并еҜјеҮәLUNзҡ„жүҖжңүж•°жҚ®гҖӮ
</br>
еӣӣгҖҒи§ЈйҮҠZFSж–Ү件系з»ҹ并дҝ®еӨҚ
1гҖҒи§ЈйҮҠZFSж–Ү件系з»ҹгҖӮеҲ©з”ЁеҢ—дәҡж•°жҚ®жҒўеӨҚиҮӘдё»ејҖеҸ‘зҡ„ZFSж–Ү件系з»ҹи§ЈйҮҠзЁӢеәҸеҜ№з”ҹжҲҗзҡ„LUNеҒҡж–Ү件系з»ҹи§ЈйҮҠпјҢеҸ‘зҺ°зЁӢеәҸеңЁи§ЈйҮҠжҹҗдәӣж–Ү件系з»ҹе…ғж–Ү件зҡ„ж—¶еҖҷжҠҘй”ҷгҖӮдәҺжҳҜе®үжҺ’ејҖеҸ‘е·ҘзЁӢеёҲеҜ№зЁӢеәҸеҒҡdebugи°ғиҜ•е№¶еҲҶжһҗзЁӢеәҸжҠҘй”ҷеҺҹеӣ гҖӮжҺҘзқҖе®үжҺ’ж–Ү件系з»ҹе·ҘзЁӢеёҲеҲҶжһҗZFSж–Ү件系з»ҹжҳҜеҗҰеӣ дёәзүҲжң¬еҺҹеӣ пјҢеҜјиҮҙзЁӢеәҸдёҚж”ҜжҢҒгҖӮз»ҸиҝҮй•ҝиҫҫ7е°Ҹж—¶зҡ„еҲҶжһҗдёҺи°ғиҜ•пјҢеҸ‘зҺ°ZFSж–Ү件系з»ҹеӣ еӯҳеӮЁзӘҒ然зҳ«з—ӘеҜјиҮҙе…¶дёӯжҹҗдәӣе…ғж–Ү件жҚҹеқҸпјҢд»ҺиҖҢеҜјиҮҙи§ЈйҮҠZFSж–Ү件系з»ҹзҡ„зЁӢеәҸж— жі•жӯЈеёёи§ЈйҮҠгҖӮ
</br>
2гҖҒдҝ®еӨҚZFSж–Ү件系з»ҹгҖӮд»ҘдёҠеҲҶжһҗжҳҺзЎ®дәҶZFSж–Ү件系з»ҹеӣ еӯҳеӮЁзҳ«з—ӘеҜјиҮҙйғЁеҲҶж–Ү件系з»ҹе…ғж–Ү件жҚҹеқҸпјҢеӣ жӯӨйңҖиҰҒеҜ№иҝҷдәӣжҚҹеқҸзҡ„ж–Ү件系з»ҹе…ғж–Ү件еҒҡдҝ®еӨҚжүҚиғҪжӯЈеёёи§ЈжһҗZFSж–Ү件系з»ҹгҖӮеҲҶжһҗжҚҹеқҸзҡ„е…ғж–Ү件еҸ‘зҺ°пјҢеӣ еҪ“еҲқZFSж–Ү件жӯЈеңЁиҝӣиЎҢIOж“ҚдҪңзҡ„еҗҢж—¶еӯҳеӮЁзҳ«з—ӘпјҢеҜјиҮҙйғЁеҲҶж–Ү件系з»ҹе…ғж–Ү件没жңүжӣҙж–°д»ҘеҸҠжҚҹеқҸгҖӮдәәе·ҘеҜ№иҝҷдәӣжҚҹеқҸзҡ„е…ғж–Ү件иҝӣиЎҢжүӢе·Ҙдҝ®еӨҚпјҢдҝқиҜҒZFSж–Ү件系з»ҹиғҪеӨҹжӯЈеёёи§ЈжһҗгҖӮ
</br>
дә”гҖҒеҜјеҮә并йӘҢиҜҒж•°жҚ®
еҲ©з”ЁзЁӢеәҸеҜ№дҝ®еӨҚеҘҪзҡ„ZFSж–Ү件系з»ҹеҒҡи§ЈжһҗпјҢи§ЈжһҗжүҖжңүж–Ү件иҠӮзӮ№еҸҠзӣ®еҪ•з»“жһ„гҖӮз”ұдәҺж•°жҚ®йғҪжҳҜж–Үжң¬зұ»еһӢеҸҠDCMеӣҫзүҮпјҢйңҖиҰҒжҗӯе»әеӨӘеӨҡзҡ„зҺҜеўғгҖӮз”ұз”ЁжҲ·ж–№е·ҘзЁӢеёҲжҢҮзӮ№жҹҗдәӣж•°жҚ®иҝӣиЎҢйӘҢиҜҒпјҢйӘҢиҜҒз»“жһңйғҪжІЎжңүй—®йўҳпјҢж•°жҚ®еқҮе®Ңж•ҙгҖӮ
</br>
е…ӯгҖҒж•°жҚ®жҒўеӨҚз»“и®ә
з”ұдәҺж•…йҡңеҸ‘з”ҹеҗҺдҝқеӯҳзҺ°еңәзҺҜеўғиүҜеҘҪпјҢжІЎз”ЁеҒҡзӣёе…іеҚұйҷ©зҡ„ж“ҚдҪңпјҢеҜ№еҗҺжңҹзҡ„ж•°жҚ®жҒўеӨҚжңүеҫҲеӨ§зҡ„её®еҠ©гҖӮж•ҙдёӘж•°жҚ®жҒўеӨҚиҝҮзЁӢдёӯиҷҪ然йҒҮеҲ°еҘҪеӨҡжҠҖжңҜ瓶йўҲпјҢдҪҶд№ҹйғҪдёҖдёҖи§ЈеҶігҖӮжңҖз»ҲеңЁйў„жңҹзҡ„ж—¶й—ҙеҶ…е®ҢжҲҗж•ҙдёӘж•°жҚ®жҒўеӨҚпјҢжҒўеӨҚзҡ„ж•°жҚ®з”ЁжҲ·ж–№д№ҹзӣёеҪ“ж»Ўж„ҸгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ