您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
写个辅助工具的时候需要提取网页里面的某些内容,我这里便把方法告诉大家,希望对大家有所帮助,记得投票给我哦!
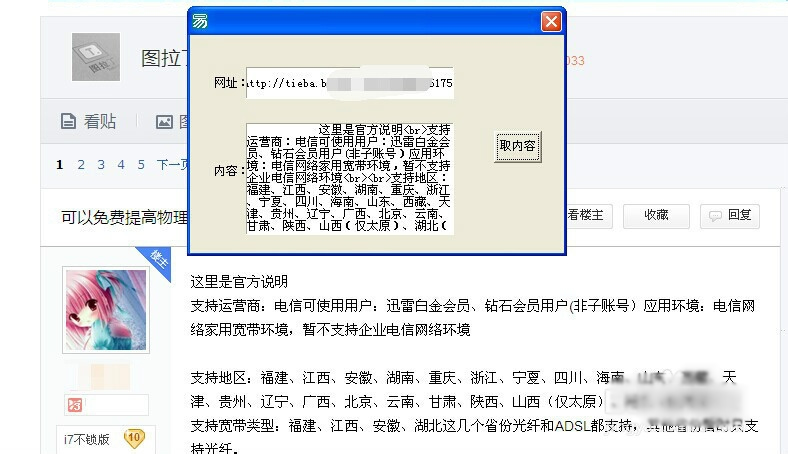
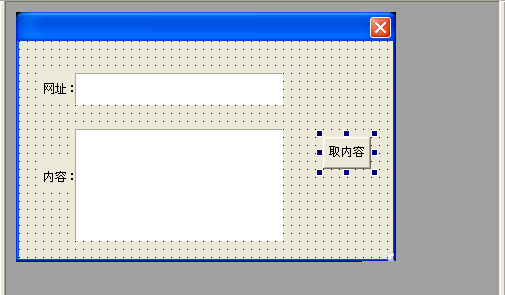
1、在新建的windos窗口程序中画:
两个编辑框、一个按钮。
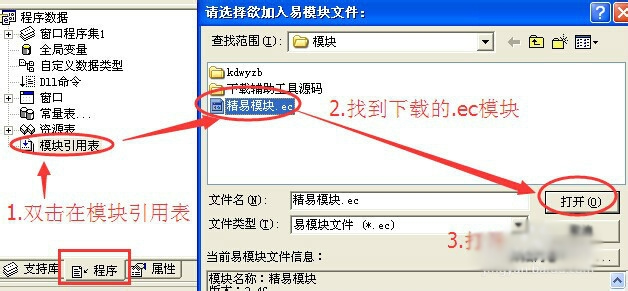
再添加模块如图中三步!
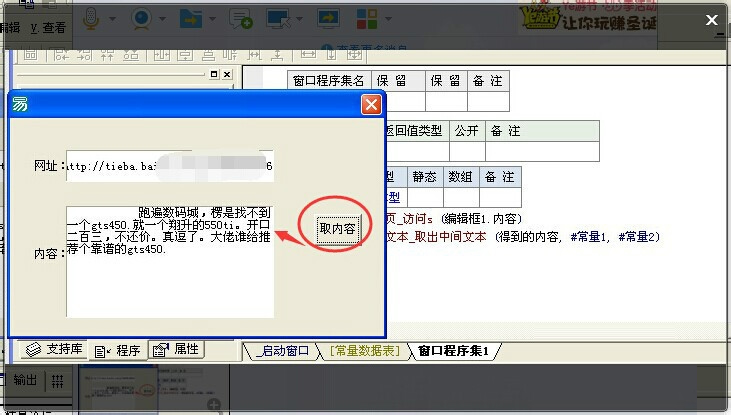
我们来实现,在一个编辑框中输入网址后,点击按钮,然后取到指定内容到编辑框2中。
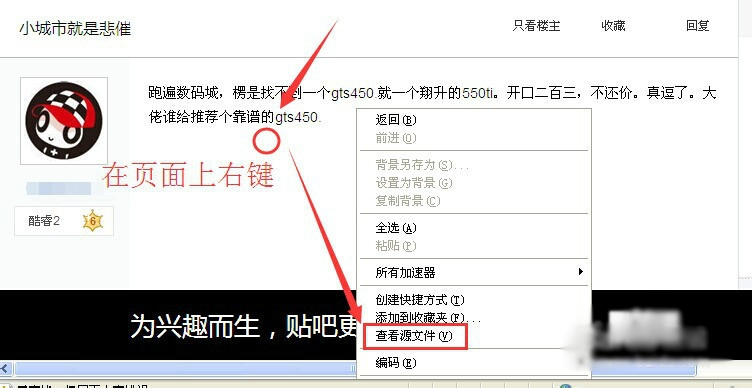
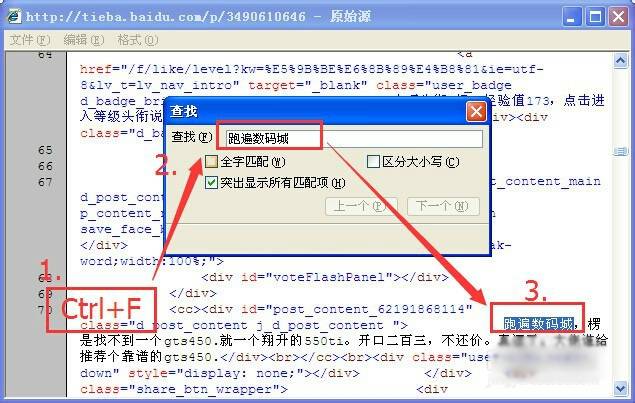
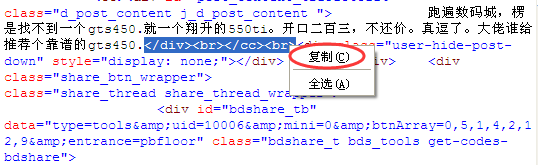
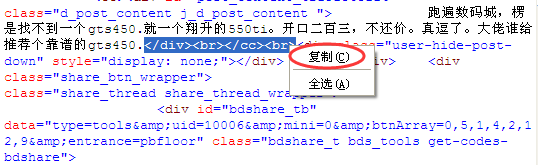
2、比如我们来取百度某贴吧一个帖子内的内容!如下图中的“跑遍数码城,XXXXX”。
我们在该页面上右键---->查看网页源码(或查看源文件)。
3、在打开的源文件内容中按CTRL+F组合键查找“跑遍数码城”,我们只要一个开文中一部分就行了!找到对应的文字后,我们找到和网页中完全对应的那部分代码。
PS:可能会出现几个被找到的内容,但是只要找到你需要取的那段全部对应部分就行。
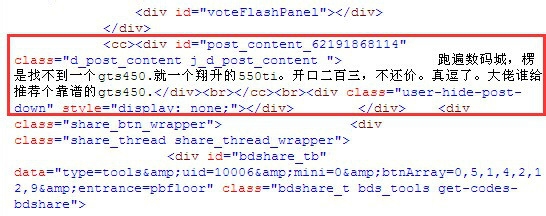
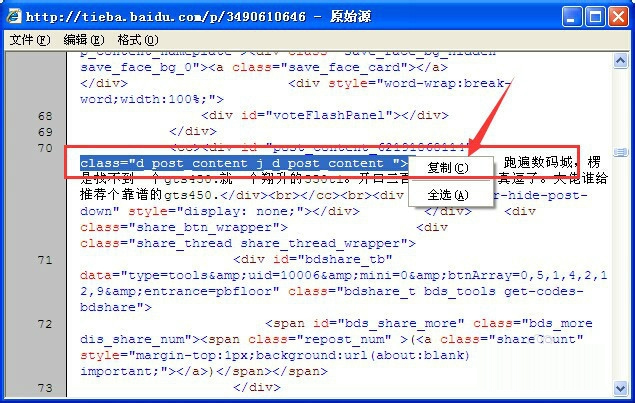
4、复制正文中的前面的部分代码,不要复制太多的内容,待会我们用正文前的内容找到中间的内容。
然后在易语言中新建一个文本常量,把复制到的内容粘贴到“常量值”里面去。
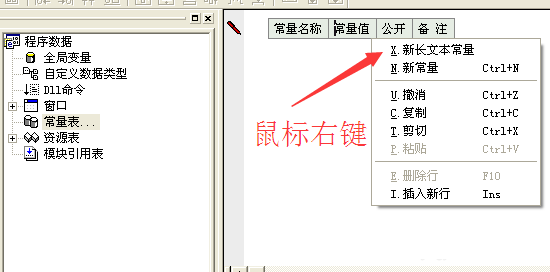
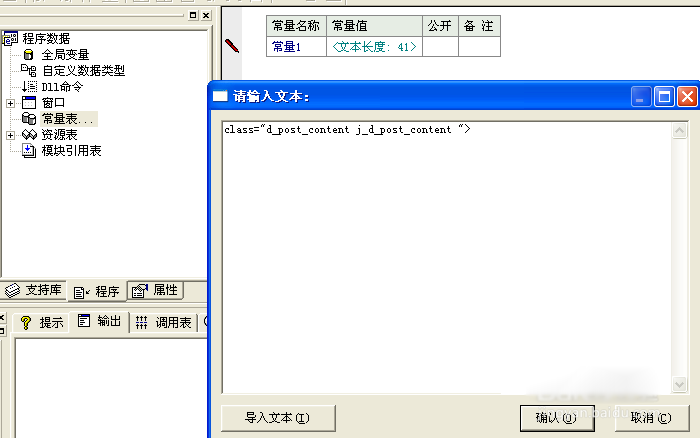
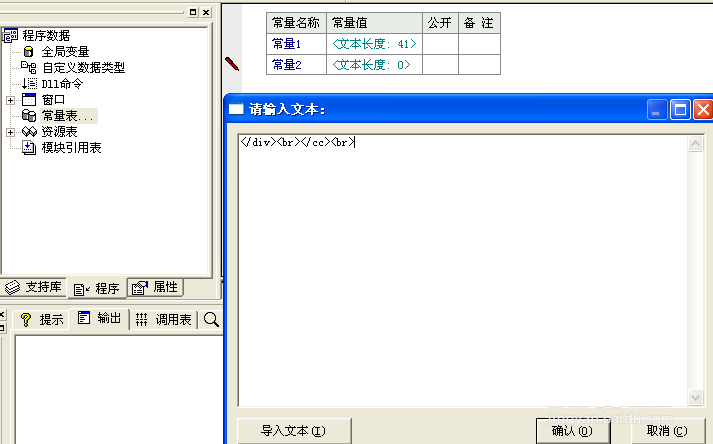
5、然后我们去复制正文后面的一小段代码,同样新建一个文本常量,然后粘贴到常量值里面去。
6、此时我们回到编程程序中,点击按钮,在生成的“_按钮1_被单击”子程序下面新建一个文本型变量“得到的内容”,然后输入以下代码:
得到的内容 = 网页_访问s (编辑框1.内容)编辑框2.内容 = 文本_取出中间文本 (得到的内容, #常量1, #常量2)
PS:第一行是把把编辑框中的网址打开后得到的网页源码赋值给“得到的内容”这个文本变量。
第二行则是对“得到的文本”进行取中间文本操作,文本_取出中间文本()是一个程序!它能取出中间内容的程序!
7、最后我们把程序调试运行一下,点击按钮“取内容”,是不是成功了呢?打开其他帖子取也是有效的,只要你取前后代码是正确的!
如果你是需要网页的源码,只要使用程序“ 网页_访问s()”,就然后把它赋值输出就OK了。当然!括号里面要有网页地址!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。