您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍Spring Cloud中Hystrix功能的示例分析,文中介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
一、概述
在微服务架构中,我们将系统拆分成了很多服务单元,各单元的应用间通过服务注册与订阅的方式互相依赖。由于每个单元都在不同的进程中运行,依赖通过远程调用的方式执行,这样就有可能因为网络原因或是依赖服务自身间题出现调用故障或延迟,而这些问题会直接导致调用方的对外服务也出现延迟,若此时调用方的请求不断增加,最后就会因等待出现故障的依赖方响应形成任务积压,最终导致自身服务的瘫痪。
所以我们引入了断路器,类似于物理上的电路,当电流过载时,就断开电路,就是我们俗称的“跳闸”。同理,服务间的调用也是如此,当不断的出现服务延迟、故障等影响到系统性能的调用,就把这个服务调用切断!
Spring Cloud Hystrix 实现了断路器、线程隔离等一系列服务保护功能。它也是基于 Netflix 的开源框架 Hystrix 实现的,该框架的目标在于通过控制那些访问远程系统、服务和第三方库的节点,从而对延迟和故障提供更强大的容错能力。Hystrix 具备服务降级、服务熔断、线程和信号隔离、请求缓存、请求合并以及服务监控等强大功能。
二、Hystrix 工作流程
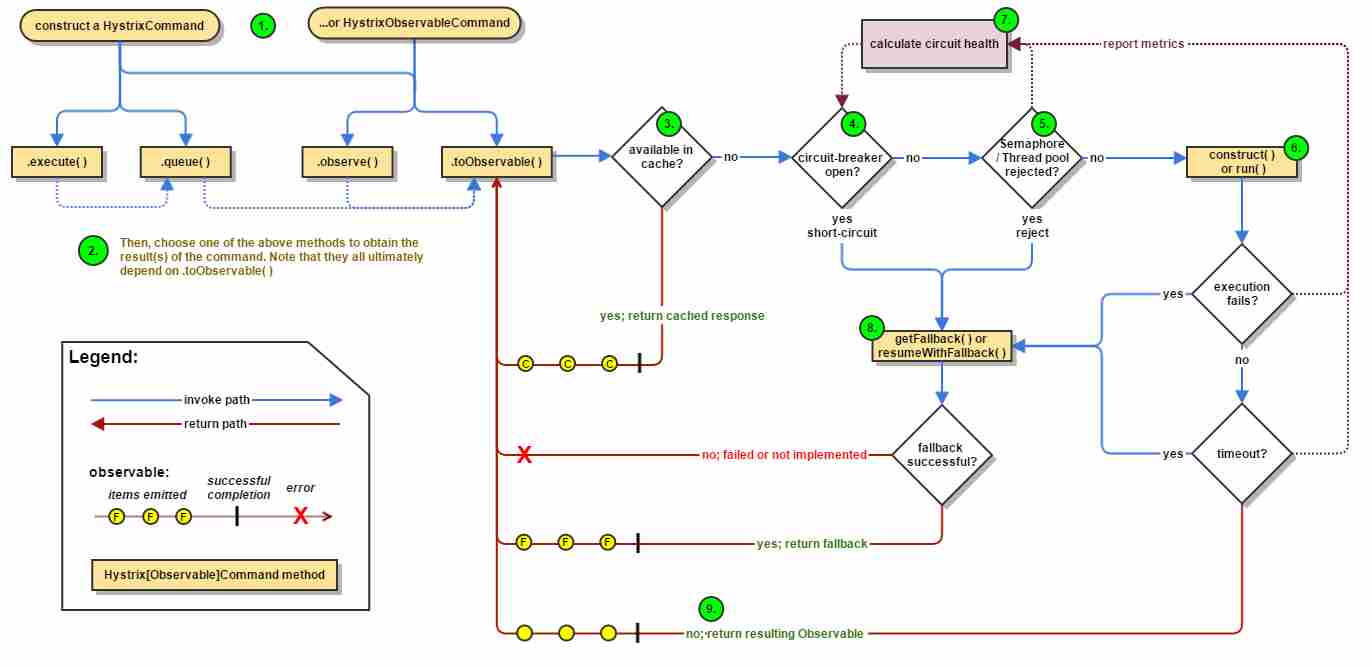
1.创建 HystrixCommand(用在依赖的服务返回单个操作结果的时候) 或 HystrixObserableCommand(用在依赖的服务返回多个操作结果的时候) 对象。
2.命令执行。其中 HystrixComand 实现了下面前两种执行方式;而 HystrixObservableCommand 实现了后两种执行方式:
execute():同步执行,从依赖的服务返回一个单一的结果对象, 或是在发生错误的时候抛出异常。
queue():异步执行, 直接返回 一个Future对象, 其中包含了服务执行结束时要返回的单一结果对象。
observe():返回 Observable 对象,它代表了操作的多个结果,它是一个 Hot Obserable(不论 "事件源" 是否有 "订阅者",都会在创建后对事件进行发布,所以对于 Hot Observable 的每一个 "订阅者" 都有可能是从 "事件源" 的中途开始的,并可能只是看到了整个操作的局部过程)。
toObservable(): 同样会返回 Observable 对象,也代表了操作的多个结果,但它返回的是一个Cold Observable(没有 "订阅者" 的时候并不会发布事件,而是进行等待,直到有 "订阅者" 之后才发布事件,所以对于 Cold Observable 的订阅者,它可以保证从一开始看到整个操作的全部过程)。
3.若当前命令的请求缓存功能是被启用的, 并且该命令缓存命中, 那么缓存的结果会立即以 Observable 对象的形式 返回。
4.检查断路器是否为打开状态。如果断路器是打开的,那么Hystrix不会执行命令,而是转接到 fallback 处理逻辑(第 8 步);如果断路器是关闭的,检查是否有可用资源来执行命令(第 5 步)。
5.线程池/请求队列/信号量是否占满。如果命令依赖服务的专有线程池和请求队列,或者信号量(不使用线程池的时候)已经被占满, 那么 Hystrix 也不会执行命令, 而是转接到 fallback 处理逻辑(第8步)。
6.Hystrix 会根据我们编写的方法来决定采取什么样的方式去请求依赖服务。
HystrixCommand.run() :返回一个单一的结果,或者抛出异常。
HystrixObservableCommand.construct(): 返回一个Observable 对象来发射多个结果,或通过 onError 发送错误通知。
7.Hystrix会将 "成功"、"失败"、"拒绝"、"超时" 等信息报告给断路器, 而断路器会维护一组计数器来统计这些数据。断路器会使用这些统计数据来决定是否要将断路器打开,来对某个依赖服务的请求进行 "熔断/短路"。
8.当命令执行失败的时候, Hystrix 会进入 fallback 尝试回退处理, 我们通常也称该操作为 "服务降级"。而能够引起服务降级处理的情况有下面几种:
第4步: 当前命令处于"熔断/短路"状态,断路器是打开的时候。
第5步: 当前命令的线程池、 请求队列或 者信号量被占满的时候。
第6步:HystrixObservableCommand.construct() 或 HystrixCommand.run() 抛出异常的时候。
9.当Hystrix命令执行成功之后, 它会将处理结果直接返回或是以Observable 的形式返回。
tips:如果我们没有为命令实现降级逻辑或者在降级处理逻辑中抛出了异常, Hystrix 依然会返回一个 Observable 对象, 但是它不会发射任何结果数据, 而是通过 onError 方法通知命令立即中断请求,并通过onError()方法将引起命令失败的异常发送给调用者。
三、Hystrix 熔断保护机制
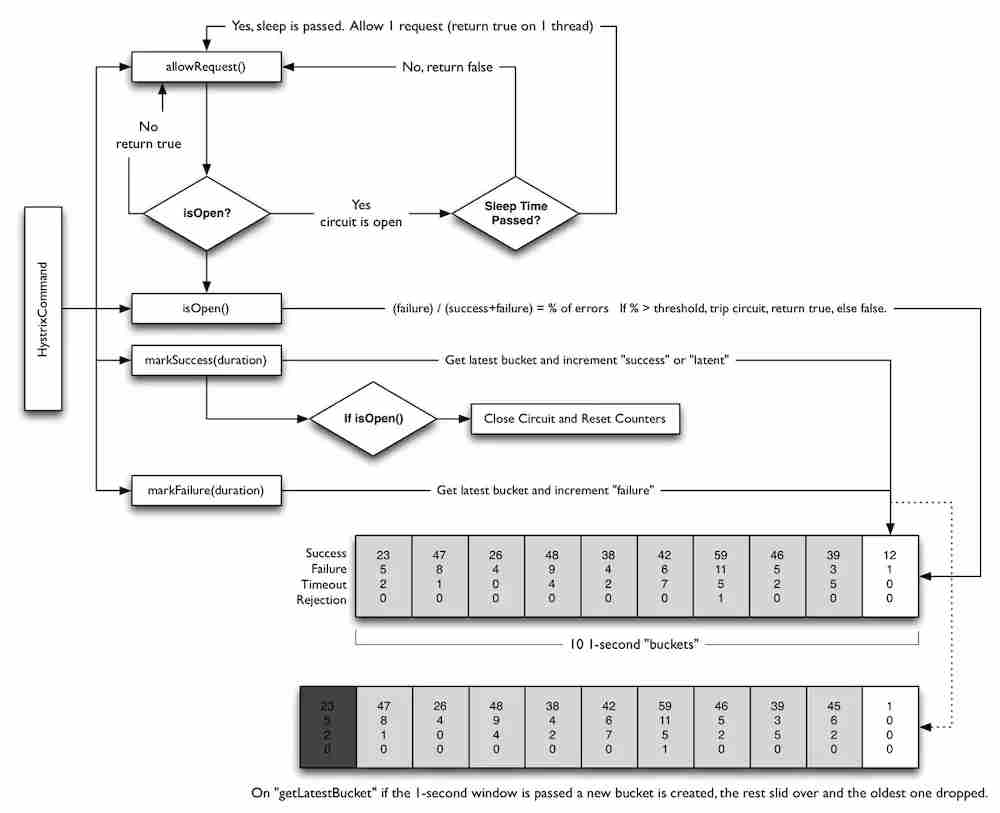
1.假设大量的请求数量超过了 HystrixCommandProperties.circuitBreakerRequestVolumeThreshold() 的阈值,熔断器将会从关闭状态变成打开状态;
2.假设依赖调用失败的百分比超过了 HystrixCommandProperties.circuitBreakerErrorThresholdPercentage() 的阈值,熔断器将会从关闭状态变成打开状态;
3.在熔断器处于打开状态的期间,所有对这个依赖进行的调用都会短路,即不进行真正的依赖调用,返回失败;
在等待(冷却)的时间超过 HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds() 的值后,熔断器将处于半开的状态,将允许单个请求去调用依赖,如果这次的依赖调用还是失败,熔断器状态将再次变成打开,这个打开状态持续时间是
4.HystrixCommandProperties.circuitBreakerSleepWindowInMilliseconds() 配置的值;如果这次的依赖调用成功,熔断器状态将变成关闭,后续依赖调用可正常执行。
四、Hystrix 依赖隔离机制
线程池隔离
Hystrix 则使用“舱壁模式”实现线程池的隔离,它会为每一个依赖服务创建 一个独立的线程池,这样就算某个依赖服务出现延迟过高的情况,也只是对该依赖服务的调用产生影响,而不会拖慢其他的依赖服务。缺点是涉及到线程切换的性能损耗,但是官方给出的结果是性能损耗是可以接受的。
信号量隔离
信号量隔离可实现对依赖调用最高并发请求数的限制,每次依赖调用都会先判断信号量是否达到阈值,如果达到极限值则拒绝调用。信号量的开销远比线程池的开销小,但是它不能设置超时和实现异步访问。所以,只有在依赖服务是足够可靠的情况下才使用信号量 。以下是两种配置信号量隔离的方式:
Setter 方式
HystrixCommand.Setter setter = HystrixCommand.Setter
.withGroupKey(HystrixCommandGroupKey.Factory.asKey("strGroupCommand"))
.andCommandKey(HystrixCommandKey.Factory.asKey("strCommand"))
.andThreadPoolKey(HystrixThreadPoolKey.Factory.asKey("strThreadPool"));
// 配置信号量隔离
HystrixCommandProperties.Setter commandPropertiesSetter = HystrixCommandProperties.Setter().withExecutionIsolationStrategy(HystrixCommandProperties.ExecutionIsolationStrategy.SEMAPHORE);
setter.andCommandPropertiesDefaults(commandPropertiesSetter);注解方式
@HystrixCommand(fallbackMethod = "fallbackMethod",
commandProperties = {
// 设置隔离策略,THREAD 表示线程池 SEMAPHORE:信号池隔离
@HystrixProperty(name = "execution.isolation.strategy", value = "THREAD"),
// 当隔离策略选择信号池隔离的时候,用来设置信号池的大小(最大并发数)
@HystrixProperty(name = "execution.isolation.semaphore.maxConcurrentRequests", value = "10"),
}
)五、hystrix 实战
SpringBoot 版本号:2.1.6.RELEASE
SpringCloud 版本号:Greenwich.RELEASE
1. pom.xml
<dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-netflix-hystrix</artifactId> </dependency>
2. 在 SpringBoot 的启动类上引入 @EnableCircuitBreaker 注解,开启断路器功能。
3. 上面 hystrix 工作原理中提到断路器有四种执行方式:
execute() - 同步执行
@HystrixCommand(fallbackMethod = "fallbackMethod")
public String strConsumer() {
ResponseEntity<String> result = restTemplate.getForEntity("http://cloud-eureka-client/hello", String.class);
return result.getBody();
}fallbackMethod —— 回调方法,在服务调用异常、断路器打开、线程池/请求队列/信号量占满时会走回调逻辑。必须和服务方法定义在同一个类中,对修饰符没有特定的要求,定义为 private、 protected、 public 均可。
queue() - 异步执行
@HystrixCommand(fallbackMethod = "fallbackMethod", ignoreExceptions = {IllegalAccessException.class})
public Future<String> asyncStrConsumer() {
Future<String> asyncResult = new AsyncResult<String>() {
@Override
public String invoke() {
ResponseEntity<String> result = restTemplate.getForEntity("http://cloud-eureka-client/hello", String.class);
return result.getBody();
}
};
return asyncResult;
}ignoreExceptions 表示抛出该异常时不走降级回调逻辑,忽略此异常。
observe () 执行方式
@HystrixCommand(observableExecutionMode = ObservableExecutionMode.EAGER)
protected Observable<String> construct() {
ResponseEntity<String> result = restTemplate.getForEntity("http://cloud-eureka-client/hello", String.class);
return Observable.just(result.getBody());
}toObservable() 执行方式
@HystrixCommand(observableExecutionMode = ObservableExecutionMode.LAZY)
protected Observable<String> construct() {
ResponseEntity<String> result = restTemplate.getForEntity("http://cloud-eureka-client/hello", String.class);
return Observable.just(result.getBody());
}4. 命令名称、分组以及线程池划分
Hystrix 会根据组来组织和统计命令的告警、仪表盘等信息。
默认情况下,Hystrix 会让相同组名的命令使用同一个线程池。
通常情况下,尽量通过 HystrixThreadPoolKey 的方式来指定线程池的划分,而不是通过组名的默认方式实现划分,因为多个不同的命令可能从业务逻辑上来看属于同一个组,但是往往从实现本身上需要跟其他命令进行隔离。
@HystrixCommand(fallbackMethod = "fallbackMethod", groupKey = "strGroupCommand", commandKey = "strCommand", threadPoolKey = "strThreadPool")
public String strConsumer(@CacheKey Long id) {
ResponseEntity<String> result = restTemplate.getForEntity("http://cloud-eureka-client/hello", String.class);
return result.getBody();
}groupKey 默认是类名,commandKey 默认是方法名 ,threadPoolKey 默认和 groupKey 一致。
5. 请求缓存和请求合并
5.1 请求缓存
缓存的作用和好处,真的是无需多言了。请求缓存,顾名思义,就是将对同一个 key 的请求结果,缓存下来。那么下次对这个 key 的请求,数据就直接在缓存中返回,减少响应时间;
在 Hystrix 中使用缓存,主要是三个注解:@CacheResult、@CacheKey、@CacheRemove
@CacheResult:用来标记请求结果应该被缓存,必须与 @HystrixCommand 一起使用。
@CacheKey:用来修饰方法参数,表示缓存的 key 名,优先级高于 @CacheResult 设置的 key 名。
@CacheRemove:当数据更新的时候,为了数据的一致性,我们需要使缓存失效。@CacheRemove 就是用来标记请求结果的缓存失效(commandKey 是必填参数,表示要失效的缓存 key)。
@CacheResult(cacheKeyMethod = "getCacheKey")
@HystrixCommand(fallbackMethod = "fallbackMethod")
public String strConsumer(@CacheKey Long id) {
ResponseEntity<String> result = restTemplate.getForEntity("http://cloud-eureka-client/hello", String.class);
return result.getBody();
}5.2 请求合并
微服务架构中的依赖通常通过远程调用实现,而远程调用中最常见的问题就是通信消耗与连接数占用。
在高并发的情况之下,因通信次数的增加,总的通信时间消耗将会变得不那么理想。同时,因为依赖服务的线程池资源有限,将出现排队等待与响应延迟的清况。为了优化这两个问题,Hystrix 提供了 HystrixCollapser 来实现请求的合并,以减少通信消耗和线程数的占用。
@RestController
public class UserConsumer {
@Autowired
private UserService userService;
/**
* 通过 id 获取用户接口
*
* @param id
* @return
*/
@HystrixCollapser(batchMethod = "getByIds", collapserProperties = {
// 10ms 内的请求合并为一次批量请求
@HystrixProperty(name = "timerDelayInMilliseconds", value = "10"),
// 批处理过程中是否开启缓存
@HystrixProperty(name = "requestCache.enabled", value = "10"),
})
public String getById(Long id) {
return userService.getUserById(id);
}
/**
* 通过 ids 批量获取用户信息接口
*
* @param ids id 集合
* @return
*/
@HystrixCommand
public Set<String> getByIds(List<Long> ids) {
return userService.getUserByIds(ids);
}
}虽然通过请求合并可以减少请求的数量以缓解依赖服务线程池的资源,但是在使用的时候也需要注意它所带来的额外开销:用于请求合并的延迟时间窗会使得依赖服务的请求延迟增高。
是否开启缓存合并,我们一般考虑下面两个因素:
如果依赖服务的请求命令本身是一个高延迟的命令,那么可以使用请求合并器,因为高延迟,时间窗的时间消耗显得微不足道了。
如果一个时间窗内只有1-2个请求,那么这样的依赖服务不适合使用请求合并器。这种情况不但不能提升系统性能,反而会成为系统瓶颈;相反,如果一个时间窗内具有很高的并发量,并且服务提供方也实现了批量处理接口,那么使用请求合并器可以有效减少网络连接数量并极大提升系统吞吐量。
6. HystrixCommand 属性介绍
@HystrixCommand(fallbackMethod = "fallbackMethod", groupKey = "strGroupCommand", commandKey = "strCommand", threadPoolKey = "strThreadPool",
commandProperties = {
// 设置隔离策略,THREAD 表示线程池 SEMAPHORE:信号池隔离
@HystrixProperty(name = "execution.isolation.strategy", value = "THREAD"),
// 当隔离策略选择信号池隔离的时候,用来设置信号池的大小(最大并发数)
@HystrixProperty(name = "execution.isolation.semaphore.maxConcurrentRequests", value = "10"),
// 配置命令执行的超时时间
@HystrixProperty(name = "execution.isolation.thread.timeoutinMilliseconds", value = "10"),
// 是否启用超时时间
@HystrixProperty(name = "execution.timeout.enabled", value = "true"),
// 执行超时的时候是否中断
@HystrixProperty(name = "execution.isolation.thread.interruptOnTimeout", value = "true"),
// 执行被取消的时候是否中断
@HystrixProperty(name = "execution.isolation.thread.interruptOnCancel", value = "true"),
// 允许回调方法执行的最大并发数
@HystrixProperty(name = "fallback.isolation.semaphore.maxConcurrentRequests", value = "10"),
// 服务降级是否启用,是否执行回调函数
@HystrixProperty(name = "fallback.enabled", value = "true"),
// 是否启用断路器
@HystrixProperty(name = "circuitBreaker.enabled", value = "true"),
// 该属性用来设置在滚动时间窗中,断路器熔断的最小请求数。例如,默认该值为 20 的时候,如果滚动时间窗(默认10秒)内仅收到了19个请求, 即使这19个请求都失败了,断路器也不会打开。
@HystrixProperty(name = "circuitBreaker.requestVolumeThreshold", value = "20"),
// 该属性用来设置在滚动时间窗中,表示在滚动时间窗中,在请求数量超过 circuitBreaker.requestVolumeThreshold 的情况下,如果错误请求数的百分比超过50, 就把断路器设置为 "打开" 状态,否则就设置为 "关闭" 状态。
@HystrixProperty(name = "circuitBreaker.errorThresholdPercentage", value = "50"),
// 该属性用来设置当断路器打开之后的休眠时间窗。 休眠时间窗结束之后,会将断路器置为 "半开" 状态,尝试熔断的请求命令,如果依然失败就将断路器继续设置为 "打开" 状态,如果成功就设置为 "关闭" 状态。
@HystrixProperty(name = "circuitBreaker.sleepWindowinMilliseconds", value = "5000"),
// 断路器强制打开
@HystrixProperty(name = "circuitBreaker.forceOpen", value = "false"),
// 断路器强制关闭
@HystrixProperty(name = "circuitBreaker.forceClosed", value = "false"),
// 滚动时间窗设置,该时间用于断路器判断健康度时需要收集信息的持续时间
@HystrixProperty(name = "metrics.rollingStats.timeinMilliseconds", value = "10000"),
// 该属性用来设置滚动时间窗统计指标信息时划分"桶"的数量,断路器在收集指标信息的时候会根据设置的时间窗长度拆分成多个 "桶" 来累计各度量值,每个"桶"记录了一段时间内的采集指标。
// 比如 10 秒内拆分成 10 个"桶"收集这样,所以 timeinMilliseconds 必须能被 numBuckets 整除。否则会抛异常
@HystrixProperty(name = "metrics.rollingStats.numBuckets", value = "10"),
// 该属性用来设置对命令执行的延迟是否使用百分位数来跟踪和计算。如果设置为 false, 那么所有的概要统计都将返回 -1。
@HystrixProperty(name = "metrics.rollingPercentile.enabled", value = "false"),
// 该属性用来设置百分位统计的滚动窗口的持续时间,单位为毫秒。
@HystrixProperty(name = "metrics.rollingPercentile.timeInMilliseconds", value = "60000"),
// 该属性用来设置百分位统计滚动窗口中使用 “ 桶 ”的数量。
@HystrixProperty(name = "metrics.rollingPercentile.numBuckets", value = "60000"),
// 该属性用来设置在执行过程中每个 “桶” 中保留的最大执行次数。如果在滚动时间窗内发生超过该设定值的执行次数,
// 就从最初的位置开始重写。例如,将该值设置为100, 滚动窗口为10秒,若在10秒内一个 “桶 ”中发生了500次执行,
// 那么该 “桶” 中只保留 最后的100次执行的统计。另外,增加该值的大小将会增加内存量的消耗,并增加排序百分位数所需的计算时间。
@HystrixProperty(name = "metrics.rollingPercentile.bucketSize", value = "100"),
// 该属性用来设置采集影响断路器状态的健康快照(请求的成功、 错误百分比)的间隔等待时间。
@HystrixProperty(name = "metrics.healthSnapshot.intervalinMilliseconds", value = "500"),
// 是否开启请求缓存
@HystrixProperty(name = "requestCache.enabled", value = "true"),
// HystrixCommand的执行和事件是否打印日志到 HystrixRequestLog 中
@HystrixProperty(name = "requestLog.enabled", value = "true"),
},
threadPoolProperties = {
// 该参数用来设置执行命令线程池的核心线程数,该值也就是命令执行的最大并发量
@HystrixProperty(name = "coreSize", value = "10"),
// 该参数用来设置线程池的最大队列大小。当设置为 -1 时,线程池将使用 SynchronousQueue 实现的队列,否则将使用 LinkedBlockingQueue 实现的队列。
@HystrixProperty(name = "maxQueueSize", value = "-1"),
// 该参数用来为队列设置拒绝阈值。 通过该参数, 即使队列没有达到最大值也能拒绝请求。
// 该参数主要是对 LinkedBlockingQueue 队列的补充,因为 LinkedBlockingQueue 队列不能动态修改它的对象大小,而通过该属性就可以调整拒绝请求的队列大小了。
@HystrixProperty(name = "queueSizeRejectionThreshold", value = "5"),
}
)
public String strConsumer() {
ResponseEntity<String> result = restTemplate.getForEntity("http://cloud-eureka-client/hello", String.class);
return result.getBody();
}以上是“Spring Cloud中Hystrix功能的示例分析”这篇文章的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。