您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
之前在WSFC基础知识奠基篇曾经为大家介绍过微软WSFC故障转移的过程,我们来重温一下
1.按照要求部署配置群集节点,确保群集服务器利用了冗余技术消除了服务器,网络,存储的单一故障点
2.保证群集内所有节点都可以访问到共享存储
3.群集应用将应用数据写入到群集共享存储
4.管理员新增节点1服务器上面功能角色,新增完成后节点1服务器群集数据库记录新增的角色功能以及相关联的信息,稍后会把信息同步至其它节点2,及群集仲裁磁盘
5.群集节点之间按照预定的心跳检测频率进行全网握手检测
6.节点1出现故障服务器忽然关机,这时节点2心跳检测频率达到阈值,判定节点1已经离线
7.节点2判定节点1已经离线后,会根据已经同步的群集数据库信息,查看节点1服务器当前承载的群集应用,重新将群集应用与关联IP地址,群集磁盘在节点2进行上线
8.客户端正常访问群集名称,使用群集服务,但原有节点1的群集应用,现已由节点2提供,故障转移结束
本篇我们将主要关注与群集故障转移的发生,大家可以看到从第五步开始,群集开始进行运行状况检测,随后以运行状况检查结果,来决定群集节点是否应执行故障转移
这在任何一个高可用群集里面都是必须的,只要群集是高可用性质,那么一定会有一种节点运行状况检测的机制,这种机制可以是ping检测,握手检测,API探测检测,总之我们需要一种机制来准确确保节点的健康与否
针对于节点的运行状况检测机制是否准确,是一个群集的核心,真正可以被使用的群集运行状况检测机制,应该是准确可以反应节点健康与否状态的,同时可以根据实际情况灵活更改健康监测的阈值。
节点的运行状况检测是故障转移里面执行节点故障转移的依据,针对于节点的运行状况检测如果达到了一定阈值,群集就会判定该节点故障,随之会导致节点上面所有承载的群集资源进行failover操作,而failover操作有时又会产生停机时间,因此,群集节点运行状况的检测频率,和决定要进行故障检测的阈值,一定是要进行环境评估的。
群集中健康检测分为两大类,一类是节点检测,一类是资源检测,节点的检测更为简单,不需要置备很多重试逻辑,只要我群集规定的运行状况检测方式,你在规定时间,规定次数里面没有让群集检测到,群集就认为你是出现故障的,无法再提供服务,需要对你进行所有应用的failover
而资源检测相对于节点检测,则更为复杂一些,可以把节点检测理解为外层的检测,针对于一个节点level的检测,如果节点检测失败,则节点上所有资源failover,资源检测则更关注资源级别的运行状况,正如老王在日志排错进阶篇讲解到的,群集里面每个资源都会有自己的resource.dll,群集正常运作过程中,RHS会按照每个资源的resource.dll定义对资源进行lookalive和isalive的检测,针对于每个资源的lookalive和isalive检测方式都会不同,lookalive只是粗略检测,isalive则更为深入,isalive检测的结果会报告给RCM,RCM会再根据资源的故障策略,进行失败重试,在机器上尝试多次启动资源,或把资源转移到其他节点运行。
总结来说,节点的运行状况检测结果,决定了节点上面所有应用是否要被故障转移,资源的运行状况检测结果,决定了单个资源是否要被按照故障策略进行操作。资源检测更为复杂,要根据resource dll定义的检测方法,考虑多种情况,来进行lookalive和isalive的检测。管理员针对一些资源也可以收到设置故障策略,例如不尝试重启,直接出现失败就转移到其他节点,或重启资源尝试三次失败,再转移到其他节点。
在过去单个资源的RHS检测失败,可能还会影响到其它群集资源,2008之后,大多数程序都已经被隔离到单独的RHS进程中进行检测,因此很少会出现单个资源检测影响到其它资源的场景。
节点运行状况检测结果影响面更大,资源运行状况检测影响面只是单个资源。大家只需要这样记住就可以了
介绍了一些基本的理论之后,我们再来专注于节点的运行状况检测
在WSFC 2012时×××始,微软针对于节点的运行状况发生了改变,不再简单的执行一个ping操作,而是会执行一个真正的握手
例如,当前群集里面有2个节点,默认情况下他们每间隔一秒做一次全网检测,每个节点与节点之前都会进行检测,如果这次握手检测为节点1发起,实际上它会执行一个握手,通过UDP 3343端口发送134byte的检测信号,询问节点2你在吗,节点回复,我在,那么你呢,你在吗,节点1回复我也在。到这里一个检测结束,WSFC的节点运行状况检测,是每隔一秒,会在所有节点之间都执行这种运行状况检测,确保没有节点会被遗漏,节点运行状况检测主要是通过UDP 3343端口
那么进行这个UDP 3343端口的检测,是在群集里面那块网卡进行呢,答案是所有已被勾选用于群集通信的网络,在WSFC 2008时代之后,群集只有三种网络类型,分别是
0 无群集通信
1 启用客户端和群集通信
3 仅用作群集通信
默认情况下,在我们创建群集,或添加群集时,群集内部会有一个网络拓扑生成器来帮我们自动去启发网卡的群集网络类型,生成群集内网络通信拓扑。
例如
如果检测到网卡上面跑了ISCSI Initiator,那么自动启发它为类型0无群集通信,确保存储网络只用来交换存储数据
如果检测到网卡上面配置了网关,那么拓扑生成器会以为你这块卡是要与外面客户端通信提供服务的,因此会自动把设置了网关的网卡设置为群集网络类型3
如果检测到网卡上面没有设置网关,那么拓扑生成器会以为你这块卡只是要做内部群集通信的,不需要对外提供服务,会被设置为群集群集网络类型1
需要注意,群集里面群集通信这种流量下面会做三件事
1.执行群集内所有节点的运行状况全网检测
2.执行群集数据库的更新同步
3.执行群集CSV元数据的同步
这三种操作都对网络质量的要求极高,尤其是CSV元数据和群集数据库,如果因为网络质量不好,频繁丢包,会导致群集数据库更新慢,可能会体现为操作执行下去很久返回结果,或CSV操作写入数据效率低下
因此建议对于群集网络类型3的群集网卡,规划好网络质量,确保不会出现丢包现象,默认情况下针对于这三种流量会由群集网络类型3的网卡来做,如果一旦群集网络类型3的网卡失败,那么群集会通过网络拓扑生成器重新规划流量群集通信流量由网络类型1执行,但一定不会让网络类型0执行。
群集网络类型3的网卡我们通常需要额外配置一些东西,例如不要设置网卡DNS 服务器、WINS 服务器或默认网关,取消群集类型3网卡DNS注册,禁用Netbios,调整网卡顺序,让群集类型1网卡最前,确保群集类型3网卡在后面,这些设置大都是为了确保故障转移后,应用联机DNS可以直接快速使用群集类型1进行注册,确保出站网络连接时始终是网络类型1优先级最高,确保访问AD进行身份验证时对外网卡优先级最高,在WSFC 2012之后对于网卡顺序开始变得不再重要,WSFC 2016时代已经取消了网卡访问顺序设置,因此大部分场景只需要去掉群集类型3网卡的DNS和Netbios注册即可
如果WSFC 2016群集是依赖于AD的群集,例如基于域验证的SQL Server群集,您担心不设计网卡顺序,当进行AD域验证时万一挑选由群集类型3网卡进行,会因为网卡联系不到AD而超时,影响依赖于AD的群集应用程序性能,那么您可以选择通过Powwershell命令修改网卡接口度量值,以达到以前控制网卡顺序优先级的目的
配置命令如下,度量值越低优先级越高
Set-NetIPInterface -InterfaceAlias“LAN”-InterfaceMetric 1
Set-NetIPInterface -InterfaceAlias“CLUS”-InterfaceMetric 2
Set-NetIPInterface -InterfaceAlias“ISCSI”-InterfaceMetric 3
如果群集应用不依赖于AD,或群集部署为工作组模型,那么完全没必要进行设置。
针对于我们本文提到的节点运行状况检测,会由NetFT这个组件进行构建检测拓扑,NetFT通常指的是Failover Cluster Virtual Adapter,当我们安装群集之后,在设备管理器里面显示隐藏设备可以看到有这样一个虚拟网络适配器,用ipconfig /all也可以看到这块网卡,但是并没有配置IP地址,这个群集虚拟网络适配器的主要作用是帮助我们构建一个群集中网络通信的高可用拓扑,例如,我们群集节点与节点之间要进行心跳检测,每隔一段时间,NetFT就会去帮我们重新构建这个拓扑,例如节点1和节点2,分别有两块网卡,一块专用于群集网络,一块用于群集网络+管理网络,那么当NetFT检测到如果专用的群集网络不能执行心跳检测,就会动态切换至另外一块网卡帮助我们进行心跳检测,NetFT的功能主要就是帮助管理员自动构建群集先有的通信拓扑,在最大程度的帮我们确保群集网络都可以正常的通信。
我们已经知道了节点运行状况检测是基于UDP 3343端口发起的实际握手检测,但是每隔多少秒检测一次,检测的时间和阈值,是可以进行配置修改的。最终,我们是要结合实际场景来修改更为合适的阈值。
例如,如果场景的需求是要求应用必须达到高可用,节点和应用非常重要一定不能出现问题,没有瞬时中断的情况,网络状况非常好,那么我们就可以设置节点检测严格一些,例如每隔一秒检测一次,五次检测失败,就标记节点为故障状态,故障转移上面所有的资源应用。
如果场景就是避免不了瞬时中断的情况,例如客户的网卡就是不太稳定 会忽然断掉又马上好了,系统很慢,检测信号maybe不会那么快响应,这时候您也可以把检测阈值设置的宽松一些,例如针对这种瞬时中断的场景,设置当20次检测失败时才触发故障转移操作
微软的建议首先是检测时间不要更改,始终保持每隔一秒进行一次全网心跳检测,其次是检测失败次数不要改的过于宽松,最长建议设置为20次,如果设置的超过20次,设置次数过多,会导致应用宕机很久才会被发现,延迟宕机时间,上面所有应用都会受到影响,因此微软建议宽松的阈值最高为20次。
其实更改这样一个节点检测的阈值很简单,一条命令的事情,但更多的是我们要思考应用的运行状况,来选择最适合的阈值
如果说您的环境,对于应用的可用性要求的很严格,一旦节点出现问题,应用需要立刻被故障转移到其它节点上,且您的环境中网络质量很高,不会出现丢包,瞬时中断的情况,那么您可以设置检测阈值为5或10,这样带来的好处是应用始终在最可靠的节点运行,只要应用当前运作节点5次检测lost,立刻failover到其它节点,但随之带来的问题是,一定要确保网络环境无瞬时中断,一旦出现瞬时中断的情况,应用会频繁的进行failover,因此设置检测阈值严格的前提,一定是对于应用可用性要求严格,网络环境足够稳定。
如果说您的环境,网络质量不高,确实会存在瞬时中断,检测信号有时不会及时响应,那么您可以选择设置检测阈值宽松一些,最高建议设置到20次信号丢失,再进行故障转移,这是个微软的最佳实践。设置检测阈值宽松,带来的好处是,确保节点正常情况下不会被故障转移,容许20次信号检测失败,maybe是因为节点距离远,或者有瞬时中断的情况。带来的坏处是,如果设置的阈值过于宽松,将会延迟宕机时间,例如,如果节点确实宕机了,但是却在60次检测后才触发故障转移,原本5次检测后就该故障转移的,因此这额外的55次检测的过程就是额外的宕机时间。
对于设置节点检测阈值宽松这件事情,一个层面是解决跨子网检测的情况,例如北京2节点,广州2节点,这样一个四节点跨地域跨子网的群集,由于网络链路过于复杂,5次检测有时确实会因为网络链路而导致检测失败,触发故障转移,因此您应该调整他们的检测阈值,但最多不要超过20,另外一点,调整检测阈值宽松,也是为了应对瞬时中断的问题,如果网络环境质量不高,不够稳定,会出现无法避免的丢包,但又不想频繁的故障转移,那么也可以调整检测阈值为20。
针对于瞬时中断的情况,WSFC 2016里面已经有了新的技术,即VM弹性,默认情况下该功能被开启,对于虚拟化群集来讲,微软默认认为环境会存在瞬时中断的问题,因此对于虚拟机资源新增了两个状态,如果240秒内出现瞬时故障,则节点进入隔离状态,虚拟机会处于无监视状态,虚拟机仍然可以正常运行或暂停。如果1小时内节点三次被隔离,则群集认为节点存在问题,需要被彻底排查,因此会被置为检疫状态,实时迁移所有虚拟机到其它节点,到达7200秒时间之前,检疫节点会被排查,不会正常加入群集。
WSFC 2016里面的VM弹性技术,主要提出的是一种新的思路,微软知道对于虚拟化群集瞬时中断比较多,经常因为网络质量而导致故障转移,所以新增了隔离到检疫到正常修复加入的流程。但是这项功能仅针对于VM资源有效,且默认的隔离时间过长,如果要使用这项功能,首先你需要了解它,老王在前面博客有详细写,然后需要调整这些阈值,240秒,3次隔离进检疫,检疫7200秒。如果不想要这项功能,也可以直接关闭。则群集又回到以前完全参照运行状况检测阈值设定进行故障转移,需要注意,运行状况检测针对于节点生效,一旦运行状况检测阈值达到,所有节点资源将会被failover,而VM弹×××,则隔离状态下,只有虚拟机会被置为未监视状态。因此大家可以根据实际场景选择要是用的功能。
OK,涉及到的理论都讲清楚了,接下来看操作命令就简单多了
调整运行状况检测阈值涉及到的参数如下
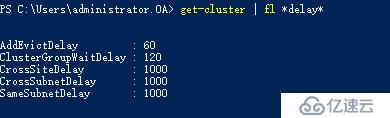
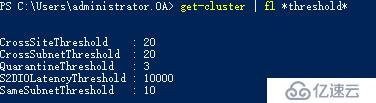
Delay为检测频率,Threshold为我们说的检测阈值
除了下表中列出的,在2012时代还有一种情况,即节点添加Hyper-V角色作为Hyper-V群集,那么SameSubnetThreshold会被自动设置为10,CrossSubnetThreshold会被自动设置为20,猜想可能是因为微软考虑Hyper-V上面虚拟机可能很多,5会导致频繁故障转移,故障转移时间也较长,而且也考虑到瞬时中断情况,因此虚拟化场景下,10和20为最佳
| 参数 | WSFC2012R2 | WSFC2016 | 最大值 |
| SameSubnetDelay | 1秒 | 1秒 | 2秒 |
| SameSubnetThreshold | 5心跳 | 10个心跳 | 120心跳 |
| CrossSubnetDelay | 1秒 | 1秒 | 4秒 |
| CrossSubnetThreshold | 5心跳 | 20个心跳 | 120心跳 |
| CrossSiteDelay | NA | 1秒 | 4秒 |
| CrossSiteThreshold | NA | 20个心跳 | 120心跳 |
在WSFC 2016之前,当我们要调整节点运行状况检测阈值时只有相同子网和跨子网,这四个选项可以设置,CrossSite是新增的功能
这里的Site是依据我们通过定义故障域,定义出来的站点为基准,因此跨站点心跳检测可以被归置到站点感知功能下
在WSFC 2016中,如果我们分别对这三种场景,同子网,跨子网,跨站点进行了设置,不同的场景下它们的生效优先级也不一样
如果集群节点在同一个站点和相同的子网中,则相同子网的阈值生效
如果集群节点在同一个站点和两个不同的子网中,则跨子网阈值生效
如果集群节点位于不同的站点和不同的子网中,则跨站点阈值将覆盖跨子网阈值
如果集群节点位于不同的站点和相同的子网中,则跨站点阈值将覆盖相同子网的阈值
这里和之前最大的不同点,在于多了不同站点的概念,如果你定了节点在不同站点,那么群集就会认为,他们之间离得很远,需要被应用不同站点的检测阈值,那怕它们在同一个子网
这很适合stretch vlan的场景,即有的群集节点虽然离得很远,但是存在同一个子网下,因此你没办法控制,说其它节点对于这个远程节点要进行比较宽松的信号检测,因为都在一个子网,所以只会被应用SameSubnetThreshold,但这个节点上面也会承载应用,如果就是因为网络链路过长,或瞬时中断,导致信号检测失准,发生故障转移,那我们也没办法控制,最终只能要求更改子网,但在WSFC 2016,我们可以把该节点逻辑定义到另外一个Site,这样,虽然还是同子网,但是一旦对于远程节点进行运行状况检测,会应用上跨Site的宽松检测策略
#获取WSFC节点运行状况检测相关设置
Get-Cluster | fl *delay*
Get-Cluster | fl *threshold*
#调整同子网心跳检测阈值为15
(Get-Cluster).SamSubnetThreshold = 15

#调整跨子网心跳检测阈值为15
(Get-Cluster).CrossSubnetThreshold = 15

当前环境继续延续上篇博客,HV01 HV02 属于北京站点,HV03, HV04属于上海站点
查看ClusterLog,可以看到由NETFT构建的运行状况检测拓扑
针对于同子网同站点,应用SamSubnetThteshold检测策略

针对于不同子网跨站点,应用CrossSiteThteshold检测策略

针对相同子网不同Site,应用CrossSiteThteshold检测策略
#手动移动HV01至上海站点

再次查看发现从18.0.0.9 到 18.0.0.10 已经应用CrossSiteThteshold检测标准!
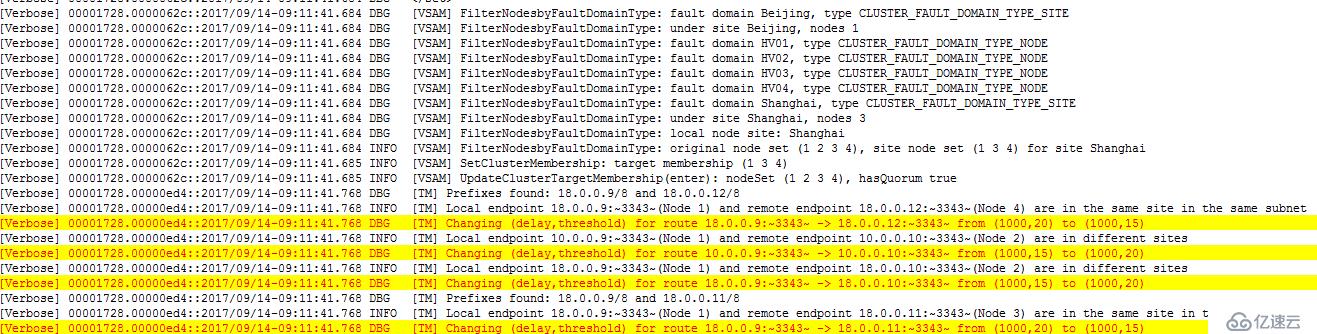
针对不同子网,但其中一个节点退出Site,应用跨Site节点检测策略
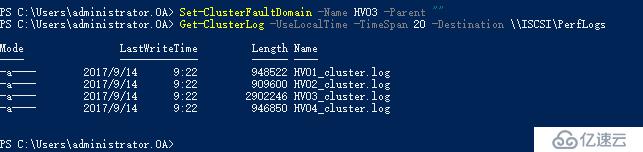

针对相同站点,但其中一个节点移动为跨子网,应用跨子网节点检测策略
移动HV01回北京站点

修改HV01为上海子网IP
查看ClusterLog发现其它节点到HV01节点的运行状况检测已经应用CrossSubnetThreshold
一旦18.0.0.0网段无法通过心跳检测,NetFT会重新路由其它网络进行运行状况检测,这时一旦选择了跨子网的网段,又在同一个Site,那么将会应用跨子网的运行状况检测策略。


免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。