您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关java中的Clojure怎样抽象并发性和共享状态,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
前言
在所有 Java 下一代语言中,Clojure 拥有最激进的并发性机制和功能。Groovy 和 Scala 都为并发性提供了改善的抽象和语法糖的一种组合,而 Clojure 坚持了它始终在 JVM 上提供独一无二的行为的强硬立场。在本期 Java 下一代 中,我将介绍 Clojure 中众多并发性选项的一部分。首先是为 Clojure 中易变的引用提供支撑的基础抽象:epochal 时间模型。
Epochal 事件模型
或许 Clojure 与其他语言最显著的区别与易变的状态和值 密切相关。Clojure 中的值 可以是任何用户感兴趣的数据:数字 42、映射结构 {:first-name "Neal :last-name "Ford"} 或某些更大型的数据结构,比如 Wikipedia。基本来讲,Clojure 语言对待所有值就像其他语言对待数字一样。数字 42 是一个值,您不能重新定义它。但可对该值应用一个函数,返回另一个值。例如,(inc 42) 返回值 43。
在 Java 和其他基于 C 的语言中,变量 同时持有身份和值,这是让并发性在 Java 语言中如此难以实现的因素之一。语言设计人员在线程抽象之前创建了变量抽象,变量的设计没有考虑为并发性增加的复杂性。因为 Java 中的变量假设只有单个线程,所以在多线程环境中,需要像同步块这样麻烦的机制来保护变量。Clojure 的设计人员 Rich Hickey 让交织(complect) 这个古老的词汇恢复了活力(交织这个词被定义为 “缠绕或编织”),用于描述 Java 变量中的设计缺陷。
Clojure 将值 与引用 分开。在 Clojure 世界观中,数据以一系列不变的值的形式存在,如图 1 所示。
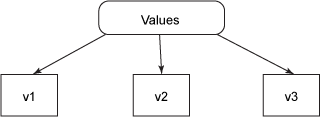
图 1. epochal 时间模型中的值
图 1 显示,像 v1 这样的独立的值表示 42 或 Wikipedia 等数据,使用方框表示。与值独立的是函数,它们获取值作为参数并生成新值,如图 2 所示。
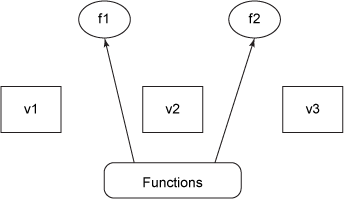
图 2. epochal 时间模型中的函数
图 2 将函数显示为与值独立的圆圈。函数调用会生成新值,使用值作为参数和结果。一连串的值保存在一个引用 中,它表示变量的身份。随着时间的推移,此身份可能指向不同的值(由于函数应用),但身份从不更改,如图 3 中的虚线所示。
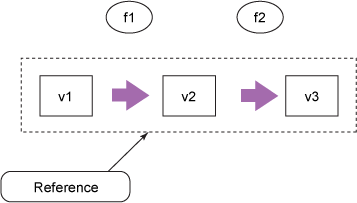
图 3. epochal 时间模型中的引用
在图 3 中,整幅图表示一个引用随时间的变化。虚线是一个引用,它持有其生存期内的一连串的值。可在某个时刻向引用分配一个新的不变值;引用指向的目标可更改,而无需更改该引用。
在引用的生存期中,一个或多个观察者(其他程序、用户界面、任何对该引用持有的值感兴趣的对象)将解除引用它,查看它的值(或许还执行某种操作),如图 4 所示。
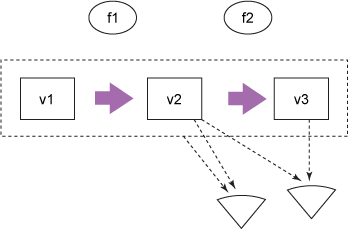
图 4. 解除引用
在图 4 中,观察者(有两种楔形表示)可持有引用本身(由来自虚线引用的箭头表示),或者可解除引用它,检索它的值(由来自该值的箭头表示)。例如,您可能有一个函数,它以一个传递给您的数据库连接作为参数,您进而将该参数传递给一个更低级的持久性函数。在此情况下,您持有该引用,但从不需要它的值;持久性函数可能会解除引用它,以获取它的值来连接到一个数据库。
请注意,图 4 中的观察者不会进行协调 — 它们完全不依赖彼此。此结构使得 Clojure 运行时能够在整个语言中保证了一些有用的属性,比如决不允许读取程序阻塞,这使得读取操作变得非常高效。如果您希望更改一个引用(也就是说,将它指向一个不同的值),可使用 Clojure 的一个 API 来执行更新,这会采用 epochal 时间模型。
epochal 时间模型为整个 Clojure 中的引用更新提供了支持。因为运行时控制所有更新,所以它可防御线程冲突,开发人员在不太复杂的语言中必须争用线程。
Clojure 拥有广泛的方式来更新引用,具体依赖于您想要何种特征。接下来,我将讨论两种方式:简单的原子 和复杂的软件事务内存。
原子
Clojure 中的原子 是对数据一个原子部分的引用,无论该部分有多大。您创建一个 atom 并初始化它,然后应用一个突变函数。这里,我为一个原子创建了一个称为 counter 的引用,将它初始化为 0。如果我希望将引用更新到一个新值,我可使用 (swap!) 这样的函数,它原子化地为该引用换入一个新值:
(def counter (atom 0)) (swap! counter + 10)
根据 Clojure 中的惯例,突变函数的名称以一个感叹号结尾。(swap!) 函数接受该引用、要应用的函数(在本例中为 + 运算符)和任何其他参数。
Clojure 原子持有任何大小的数据,而不只是原始值。例如,我可围绕一个 person 映射创建一个原子引用,并使用 map 函数更新它。使用 (create-person) 函数(未显示),我在一个原子中创建一个 person 记录,然后使用 (swap!) 和 (assoc ) 更新该引用,这会更新一个映射关联:
(def person (atom (create-person))) (swap! person assoc :name "John")
原子还会通过 (compare-and-set!) 函数,使用原子实现一个通用的乐观锁定模式:
(compare-and-set! a 0 42) => false (compare-and-set! a 1 7) = true
(compare-and-set!) 函数接受 3 个参数:原子引用、想要的现有值和新值。如果原子的值与想要的值不匹配,更新不会发生,函数会返回 false。
Clojure 有各种各样的机制都遵循引用语义。例如,promise(是一种不同的引用)承诺在以后提供一个值。这里,我创建对一个名为 number-later 的 promise 的引用。此代码不会生成任何值,就像它对最终会这么做的承诺一样。调用 (deliver ) 函数时,一个值会绑定到 number-later:
(def number-later (promise)) (deliver number-later 42)
尽管此示例使用了 Clojure 中的 futures 库,但引用语义与简单的原子保持一致。
软件事务内存
没有其他任何 Clojure 特性获得了比软件事务内存 (STM) 更多的关注,这是 Clojure 以 Java 语言封装垃圾收集的方式来封装并发性的内部机制。换句话说,您可编写高性能的多线程 Clojure 应用程序,而从不考虑同步块、死锁、线程库等。
Clojure 封装并发性的方式是,通过 STM 控制引用的所有突变。更新一个引用(惟一的易变抽象)时,必须在一个事务中执行,以使 Clojure 运行时能够管理更新。考虑一个经典的银行问题:向一个帐户中存款,同时向另一个帐户贷款。清单 1 显示了一个简单的 Clojure 解决方案。
清单 1. 银行交易
(defn transfer [from to amount] (dosync (alter from - amount) (alter to + amount)))
在 清单 1 中,我定义了一个 (transfer ) 函数,它接受 3 个参数:from 和 to 帐户 — 二者都是引用 — 以及金额。我从 from 帐户中减去该金额,将它添加到 to 帐户中,但此操作必须与 (dosync ) 事务一起发生。如果我在事务块的外部尝试一个 (alter ) 调用,更新会失败并抛出一个 IllegalStateException:
(alter from - 1) =>> IllegalStateException No transaction running
在 清单 1 中,(alter ) 函数仍然遵守 epochal 时间模型,但使用 STM 来确保两个操作都完成或都未完成。为此,STM — 非常像一个数据库服务器 — 临时重试阻塞的操作,所以您的更新函数在更新之外不应有任何副作用。例如,如果您的函数还写入一个日志,由于不断重试,您可能会看到多个日志条目。STM 还会随未解决事务的时长增长而逐步提高它们的优先级,显示数据库引擎中的其他更常见的行为。
STM 的使用很简单,但底层机制很复杂。从名称可以看出,STM 是一个事务系统。STM 实现了 ACID 事务标准的 ACI 部分:所有更改都是原子性、一致 和隔离的。ACID 的耐久 部分在这里不适用,因为 STM 在内存中操作。很少看到将像 STM 这样的高性能机制内置于一种语言的核心中;Haskell 是惟一认真实现了 STM 的另一种主流语言 — 不要奇怪,因为 Haskell(像 Clojure 一样)非常喜欢不变性。(.NET 生态系统曾尝试构建一个 STM 管理器,但最终放弃了,因为处理事务和不变性变得太复杂了。)
缩减程序(reducer)和数字分类
如果不讨论 上一期 中的数字分类器问题的替代实现,并行性介绍都是不完整的。清单 2 显示了一个没有并行性的原子版本。
清单 2. Clojure 中的数字分类器
(defn classify [num] (let [facts (->> (range 1 (inc num)) (filter #(= 0 (rem num %)))) sum (reduce + facts) aliquot-sum (- sum num)] (cond (= aliquot-sum num) :perfect (> aliquot-sum num) :abundant (< aliquot-sum num) :deficient)))
清单 2 中的分类器版本浓缩为单个函数,它返回一个 Clojure 关键字(由一个前导冒号表示)。(let ) 块使我能够建立局部绑定。为了确定因数,我使用 thread-last 运算符来过滤数字范围,让代码更有序。sum 和 aliquot-sum 的计算都很简单;一个数字的真因数和 是它的因数之和减去它本身,这使我的比较代码更简单。该函数的最后一行是 (cond ) 语句,它针对计算的值来计算 aliquot-sum,返回合适的关键字枚举。此代码的一个有趣之处是,我以前的实现中的方法在这个版本中折叠为简单的赋值。在计算足够简单和简洁时,您通常需要创建的函数更少。
Clojure 包含一个称为 缩减程序 的强大的并发性库。(有关缩减程序库的开发过程的解释 — 包括为利用最新的 JVM 原生的 fork/join 工具而进行的优化 — 是一个吸引人的故事。)缩减程序库提供了常见运算的就地替换,比如 map、filter 和 reduce,使这些预算能够自动利用多个线程。例如,将标准的 (map ) 替换为 (r/map )(r/ 是缩减程序的命名空间),会导致您的映射操作自动被运行时并行化。
清单 3 给出了一个利用了缩减程序的数字分类器版本。
清单 3. 使用了缩减程序库的分类器
(ns pperfect.core (:require [clojure.core.reducers :as r])) (defn classify-with-reducer [num] (let [facts (->> (range 1 (inc num)) (r/filter #(= 0 (rem num %)))) sum (r/reduce + facts) aliquot-sum (- sum num)] (cond (= aliquot-sum num) :perfect (> aliquot-sum num) :abundant (< aliquot-sum num) :deficient)))
必须仔细观察,才能找出 清单 2 和 清单 3 之间的区别。惟一的区别是引入了缩减程序命名空间和别名,向 filter 和 reduce 都添加了 r/。借助这些细微的更改,我的过滤和缩减操作现在可自动使用多个线程。
关于“java中的Clojure怎样抽象并发性和共享状态”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。