жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іеҰӮдҪ•еңЁspring bootдёӯй…ҚзҪ®иҜ»еҶҷеҲҶзҰ»пјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
1гҖҒиғҢжҷҜ
дёҖдёӘйЎ№зӣ®дёӯж•°жҚ®еә“жңҖеҹәзЎҖеҗҢж—¶д№ҹжҳҜжңҖдё»жөҒзҡ„жҳҜеҚ•жңәж•°жҚ®еә“пјҢиҜ»еҶҷйғҪеңЁдёҖдёӘеә“дёӯгҖӮеҪ“з”ЁжҲ·йҖҗжёҗеўһеӨҡпјҢеҚ•жңәж•°жҚ®еә“ж— жі•ж»Ўи¶іжҖ§иғҪиҰҒжұӮж—¶пјҢе°ұдјҡиҝӣиЎҢиҜ»еҶҷеҲҶзҰ»ж”№йҖ пјҲйҖӮз”ЁдәҺиҜ»еӨҡеҶҷе°‘пјүпјҢеҶҷж“ҚдҪңдёҖдёӘеә“пјҢиҜ»ж“ҚдҪңеӨҡдёӘеә“пјҢйҖҡеёёдјҡеҒҡдёҖдёӘж•°жҚ®еә“йӣҶзҫӨпјҢејҖеҗҜдё»д»ҺеӨҮд»ҪпјҢдёҖдё»еӨҡд»ҺпјҢд»ҘжҸҗй«ҳиҜ»еҸ–жҖ§иғҪгҖӮеҪ“з”ЁжҲ·жӣҙеӨҡиҜ»еҶҷеҲҶзҰ»д№ҹж— жі•ж»Ўи¶іж—¶пјҢе°ұйңҖиҰҒеҲҶеёғејҸж•°жҚ®еә“дәҶпјҲеҸҜиғҪд»ҘеҗҺдјҡеӯҰд№ жҖҺд№Ҳеј„пјүгҖӮ
жӯЈеёёжғ…еҶөдёӢиҜ»еҶҷеҲҶзҰ»зҡ„е®һзҺ°пјҢйҰ–е…ҲиҰҒеҒҡдёҖдёӘдёҖдё»еӨҡд»Һзҡ„ж•°жҚ®еә“йӣҶзҫӨпјҢеҗҢж—¶иҝҳйңҖиҰҒиҝӣиЎҢж•°жҚ®еҗҢжӯҘгҖӮиҝҷдёҖзҜҮи®°еҪ•еҰӮдҪ•з”Ёmysqlжҗӯе»әдёҖдёӘдёҖдё»еӨҡж¬Ўзҡ„й…ҚзҪ®пјҢдёӢдёҖзҜҮи®°еҪ•д»Јз ҒеұӮйқўеҰӮдҪ•е®һзҺ°иҜ»еҶҷеҲҶзҰ»гҖӮ
2гҖҒжҗӯе»әдёҖдё»еӨҡд»Һж•°жҚ®еә“йӣҶзҫӨ
дё»д»ҺеӨҮд»ҪйңҖиҰҒеӨҡеҸ°иҷҡжӢҹжңәпјҢжҲ‘жҳҜз”Ёwmwareе®Ңж•ҙе…ӢйҡҶеӨҡдёӘе®һдҫӢпјҢжіЁж„ҸзӣҙжҺҘе…ӢйҡҶзҡ„иҷҡжӢҹжңәдјҡеҜјиҮҙжҜҸдёӘж•°жҚ®еә“зҡ„uuidзӣёеҗҢпјҢйңҖиҰҒдҝ®ж”№дёәдёҚеҗҢзҡ„uuidгҖӮдҝ®ж”№ж–№жі•еҸӮиҖғиҝҷдёӘпјҡзӮ№еҮ»и·іиҪ¬гҖӮ
дё»еә“й…ҚзҪ®
дё»ж•°жҚ®еә“пјҲmasterпјүдёӯж–°е»әдёҖдёӘз”ЁжҲ·з”ЁдәҺд»Һж•°жҚ®еә“пјҲslaveпјүиҜ»еҸ–дё»ж•°жҚ®еә“дәҢиҝӣеҲ¶ж—Ҙеҝ—пјҢsqlиҜӯеҸҘеҰӮдёӢпјҡ
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY '123456';#еҲӣе»әз”ЁжҲ· mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';#еҲҶй…Қжқғйҷҗ mysql>flush privileges; #еҲ·ж–°жқғйҷҗ
еҗҢж—¶дҝ®ж”№mysqlй…ҚзҪ®ж–Ү件ејҖеҗҜдәҢиҝӣеҲ¶ж—Ҙеҝ—пјҢж–°еўһйғЁеҲҶеҰӮдёӢпјҡ
[mysqld] server-id=1 log-bin=master-bin log-bin-index=master-bin.index
然еҗҺйҮҚеҗҜж•°жҚ®еә“пјҢдҪҝз”Ёshow master status;иҜӯеҸҘжҹҘзңӢдё»еә“зҠ¶жҖҒпјҢеҰӮдёӢжүҖзӨәпјҡ

д»Һеә“й…ҚзҪ®
еҗҢж ·е…Ҳж–°еўһеҮ иЎҢй…ҚзҪ®пјҡ
[mysqld] server-id=2 relay-log-index=slave-relay-bin.index relay-log=slave-relay-bin
然еҗҺйҮҚеҗҜж•°жҚ®еә“пјҢдҪҝз”ЁеҰӮдёӢиҜӯеҸҘиҝһжҺҘдё»еә“пјҡ
CHANGE MASTER TO MASTER_HOST='192.168.226.5', MASTER_USER='root', MASTER_PASSWORD='123456', MASTER_LOG_FILE='master-bin.000003', MASTER_LOG_POS=154;
жҺҘзқҖиҝҗиЎҢstart slave;ејҖеҗҜеӨҮд»Ҫ,жӯЈеёёжғ…еҶөеҰӮдёӢеӣҫжүҖзӨәпјҡSlave_IO_Runningе’ҢSlave_SQL_RunningйғҪдёәyesгҖӮ
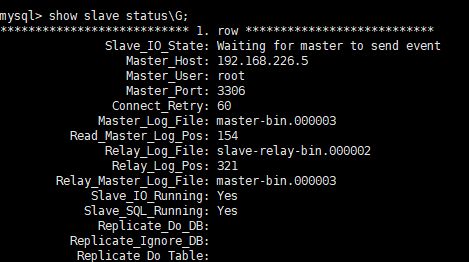
еҸҜд»Ҙз”ЁиҝҷдёӘжӯҘйӘӨејҖеҗҜеӨҡдёӘд»Һеә“гҖӮ
вҖғвҖғй»ҳи®Өжғ…еҶөдёӢеӨҮд»ҪжҳҜдё»еә“зҡ„е…ЁйғЁж“ҚдҪңйғҪдјҡеӨҮд»ҪеҲ°д»Һеә“пјҢе®һйҷ…еҸҜиғҪйңҖиҰҒеҝҪз•Ҙжҹҗдәӣеә“пјҢеҸҜд»ҘеңЁдё»еә“дёӯеўһеҠ еҰӮдёӢй…ҚзҪ®пјҡ
# дёҚеҗҢжӯҘе“Әдәӣж•°жҚ®еә“ binlog-ignore-db = mysql binlog-ignore-db = test binlog-ignore-db = information_schema # еҸӘеҗҢжӯҘе“Әдәӣж•°жҚ®еә“пјҢйҷӨжӯӨд№ӢеӨ–пјҢе…¶д»–дёҚеҗҢжӯҘ binlog-do-db = game
3гҖҒд»Јз ҒеұӮйқўиҝӣиЎҢиҜ»еҶҷеҲҶзҰ»
д»Јз ҒзҺҜеўғжҳҜspringboot+mybatis+druibиҝһжҺҘжұ гҖӮжғіиҰҒиҜ»еҶҷеҲҶзҰ»е°ұйңҖиҰҒй…ҚзҪ®еӨҡдёӘж•°жҚ®жәҗпјҢеңЁиҝӣиЎҢеҶҷж“ҚдҪңжҳҜйҖүжӢ©еҶҷзҡ„ж•°жҚ®жәҗпјҢиҜ»ж“ҚдҪңж—¶йҖүжӢ©иҜ»зҡ„ж•°жҚ®жәҗгҖӮе…¶дёӯжңүдёӨдёӘе…ій”®зӮ№пјҡ
еҰӮдҪ•еҲҮжҚўж•°жҚ®жәҗ
еҰӮдҪ•ж №жҚ®дёҚеҗҢзҡ„ж–№жі•йҖүжӢ©жӯЈзЎ®зҡ„ж•°жҚ®жәҗ
1)гҖҒеҰӮдҪ•еҲҮжҚўж•°жҚ®жәҗ
йҖҡеёёз”Ёspringbootж—¶йғҪжҳҜдҪҝз”Ёе®ғзҡ„й»ҳи®Өй…ҚзҪ®пјҢеҸӘйңҖиҰҒеңЁй…ҚзҪ®ж–Ү件дёӯе®ҡд№үеҘҪиҝһжҺҘеұһжҖ§е°ұиЎҢдәҶпјҢдҪҶжҳҜзҺ°еңЁжҲ‘们йңҖиҰҒиҮӘе·ұжқҘй…ҚзҪ®дәҶпјҢspringжҳҜж”ҜжҢҒеӨҡж•°жҚ®жәҗзҡ„пјҢеӨҡдёӘdatasourceж”ҫеңЁдёҖдёӘHashMapTargetDataSourceдёӯпјҢйҖҡиҝҮdertermineCurrentLookupKeyиҺ·еҸ–keyжқҘи§үе®ҡиҰҒдҪҝз”Ёе“ӘдёӘж•°жҚ®жәҗгҖӮеӣ жӯӨжҲ‘们зҡ„зӣ®ж Үе°ұеҫҲжҳҺзЎ®дәҶпјҢе»әз«ӢеӨҡдёӘdatasourceж”ҫеҲ°TargetDataSourceдёӯпјҢеҗҢж—¶йҮҚеҶҷdertermineCurrentLookupKeyж–№жі•жқҘеҶіе®ҡдҪҝз”Ёе“ӘдёӘkeyгҖӮ
2)гҖҒеҰӮдҪ•йҖүжӢ©ж•°жҚ®жәҗ
дәӢеҠЎдёҖиҲ¬жҳҜжіЁи§ЈеңЁServiceеұӮзҡ„пјҢеӣ жӯӨеңЁејҖе§ӢиҝҷдёӘserviceж–№жі•и°ғз”Ёж—¶иҰҒзЎ®е®ҡж•°жҚ®жәҗпјҢжңүд»Җд№ҲйҖҡз”Ёж–№жі•иғҪеӨҹеңЁејҖе§Ӣжү§иЎҢдёҖдёӘж–№жі•еүҚеҒҡж“ҚдҪңе‘ўпјҹзӣёдҝЎдҪ е·Із»ҸжғіеҲ°дәҶйӮЈе°ұжҳҜеҲҮйқў гҖӮжҖҺд№ҲеҲҮжңүдёӨз§ҚеҠһжі•пјҡ
жіЁи§ЈејҸпјҢе®ҡд№үдёҖдёӘеҸӘиҜ»жіЁи§ЈпјҢиў«иҜҘж•°жҚ®ж ҮжіЁзҡ„ж–№жі•дҪҝз”ЁиҜ»еә“
ж–№жі•еҗҚпјҢж №жҚ®ж–№жі•еҗҚеҶҷеҲҮзӮ№пјҢжҜ”еҰӮgetXXXз”ЁиҜ»еә“пјҢsetXXXз”ЁеҶҷеә“
3)гҖҒд»Јз Ғзј–еҶҷ
aгҖҒзј–еҶҷй…ҚзҪ®ж–Ү件пјҢй…ҚзҪ®дёӨдёӘж•°жҚ®жәҗдҝЎжҒҜ
еҸӘжңүеҝ…еЎ«дҝЎжҒҜпјҢе…¶д»–йғҪжңүй»ҳи®Өи®ҫзҪ®
mysql: datasource: #иҜ»еә“ж•°зӣ® num: 1 type-aliases-package: com.example.dxfl.dao mapper-locations: classpath:/mapper/*.xml config-location: classpath:/mybatis-config.xml write: url: jdbc:mysql://192.168.226.5:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true username: root password: 123456 driver-class-name: com.mysql.jdbc.Driver read: url: jdbc:mysql://192.168.226.6:3306/test?useUnicode=true&characterEncoding=utf-8&useSSL=true username: root password: 123456 driver-class-name: com.mysql.jdbc.Driver
bгҖҒзј–еҶҷDbContextHolderзұ»
иҝҷдёӘзұ»з”ЁжқҘи®ҫзҪ®ж•°жҚ®еә“зұ»еҲ«пјҢе…¶дёӯжңүдёҖдёӘThreadLocalз”ЁжқҘдҝқеӯҳжҜҸдёӘзәҝзЁӢзҡ„жҳҜдҪҝз”ЁиҜ»еә“пјҢиҝҳжҳҜеҶҷеә“гҖӮд»Јз ҒеҰӮдёӢпјҡ
/**
* Description иҝҷйҮҢеҲҮжҚўиҜ»/еҶҷжЁЎејҸ
* еҺҹзҗҶжҳҜеҲ©з”ЁThreadLocalдҝқеӯҳеҪ“еүҚзәҝзЁӢжҳҜеҗҰеӨ„дәҺиҜ»жЁЎејҸпјҲйҖҡиҝҮејҖе§ӢREAD_ONLYжіЁи§ЈеңЁејҖе§Ӣж“ҚдҪңеүҚи®ҫзҪ®жЁЎејҸдёәиҜ»жЁЎејҸпјҢ
* ж“ҚдҪңз»“жқҹеҗҺжё…йҷӨиҜҘж•°жҚ®пјҢйҒҝе…ҚеҶ…еӯҳжі„жјҸпјҢеҗҢж—¶д№ҹдёәдәҶеҗҺз»ӯеңЁиҜҘзәҝзЁӢиҝӣиЎҢеҶҷж“ҚдҪң时任然дёәиҜ»жЁЎејҸ
* @author fxb
* @date 2018-08-31
*/
public class DbContextHolder {
private static Logger log = LoggerFactory.getLogger(DbContextHolder.class);
public static final String WRITE = "write";
public static final String READ = "read";
private static ThreadLocal<String> contextHolder= new ThreadLocal<>();
public static void setDbType(String dbType) {
if (dbType == null) {
log.error("dbTypeдёәз©ә");
throw new NullPointerException();
}
log.info("и®ҫзҪ®dbTypeдёәпјҡ{}",dbType);
contextHolder.set(dbType);
}
public static String getDbType() {
return contextHolder.get() == null ? WRITE : contextHolder.get();
}
public static void clearDbType() {
contextHolder.remove();
}
}cгҖҒйҮҚеҶҷdetermineCurrentLookupKeyж–№жі•
springеңЁејҖе§ӢиҝӣиЎҢж•°жҚ®еә“ж“ҚдҪңж—¶дјҡйҖҡиҝҮиҝҷдёӘж–№жі•жқҘеҶіе®ҡдҪҝз”Ёе“ӘдёӘж•°жҚ®еә“пјҢеӣ жӯӨжҲ‘们еңЁиҝҷйҮҢи°ғз”ЁдёҠйқўDbContextHolderзұ»зҡ„getDbType()ж–№жі•иҺ·еҸ–еҪ“еүҚж“ҚдҪңзұ»еҲ«,еҗҢж—¶еҸҜиҝӣиЎҢиҜ»еә“зҡ„иҙҹиҪҪеқҮиЎЎпјҢд»Јз ҒеҰӮдёӢпјҡ
public class MyAbstractRoutingDataSource extends AbstractRoutingDataSource {
@Value("${mysql.datasource.num}")
private int num;
private final Logger log = LoggerFactory.getLogger(this.getClass());
@Override
protected Object determineCurrentLookupKey() {
String typeKey = DbContextHolder.getDbType();
if (typeKey == DbContextHolder.WRITE) {
log.info("дҪҝз”ЁдәҶеҶҷеә“");
return typeKey;
}
//дҪҝз”ЁйҡҸжңәж•°еҶіе®ҡдҪҝз”Ёе“ӘдёӘиҜ»еә“
int sum = NumberUtil.getRandom(1, num);
log.info("дҪҝз”ЁдәҶиҜ»еә“{}", sum);
return DbContextHolder.READ + sum;
}
}dгҖҒзј–еҶҷй…ҚзҪ®зұ»
з”ұдәҺиҰҒиҝӣиЎҢиҜ»еҶҷеҲҶзҰ»пјҢдёҚиғҪеҶҚз”Ёspringbootзҡ„й»ҳи®Өй…ҚзҪ®пјҢжҲ‘们йңҖиҰҒжүӢеҠЁжқҘиҝӣиЎҢй…ҚзҪ®гҖӮйҰ–е…Ҳз”ҹжҲҗж•°жҚ®жәҗпјҢдҪҝз”Ё@ConfigurPropertiesиҮӘеҠЁз”ҹжҲҗж•°жҚ®жәҗпјҡ
/**
* еҶҷж•°жҚ®жәҗ
*
* @Primary ж Үеҝ—иҝҷдёӘ Bean еҰӮжһңеңЁеӨҡдёӘеҗҢзұ» Bean еҖҷйҖүж—¶пјҢиҜҘ Bean дјҳе…Ҳиў«иҖғиҷ‘гҖӮ
* еӨҡж•°жҚ®жәҗй…ҚзҪ®зҡ„ж—¶еҖҷжіЁж„ҸпјҢеҝ…йЎ»иҰҒжңүдёҖдёӘдё»ж•°жҚ®жәҗпјҢз”Ё @Primary ж Үеҝ—иҜҘ Bean
*/
@Primary
@Bean
@ConfigurationProperties(prefix = "mysql.datasource.write")
public DataSource writeDataSource() {
return new DruidDataSource();
}иҜ»ж•°жҚ®жәҗзұ»дјјпјҢжіЁж„ҸжңүеӨҡе°‘дёӘиҜ»еә“е°ұиҰҒи®ҫзҪ®еӨҡе°‘дёӘиҜ»ж•°жҚ®жәҗпјҢBeanеҗҚдёәread+еәҸеҸ·гҖӮ
然еҗҺи®ҫзҪ®ж•°жҚ®жәҗпјҢдҪҝз”Ёзҡ„жҳҜжҲ‘们д№ӢеүҚеҶҷзҡ„MyAbstractRoutingDataSourceзұ»
/**
* и®ҫзҪ®ж•°жҚ®жәҗи·Ҝз”ұпјҢйҖҡиҝҮиҜҘзұ»дёӯзҡ„determineCurrentLookupKeyеҶіе®ҡдҪҝз”Ёе“ӘдёӘж•°жҚ®жәҗ
*/
@Bean
public AbstractRoutingDataSource routingDataSource() {
MyAbstractRoutingDataSource proxy = new MyAbstractRoutingDataSource();
Map<Object, Object> targetDataSources = new HashMap<>(2);
targetDataSources.put(DbContextHolder.WRITE, writeDataSource());
targetDataSources.put(DbContextHolder.READ+"1", read1());
proxy.setDefaultTargetDataSource(writeDataSource());
proxy.setTargetDataSources(targetDataSources);
return proxy;
}жҺҘзқҖйңҖиҰҒи®ҫзҪ®sqlSessionFactory
/**
* еӨҡж•°жҚ®жәҗйңҖиҰҒиҮӘе·ұи®ҫзҪ®sqlSessionFactory
*/
@Bean
public SqlSessionFactory sqlSessionFactory() throws Exception {
SqlSessionFactoryBean bean = new SqlSessionFactoryBean();
bean.setDataSource(routingDataSource());
ResourcePatternResolver resolver = new PathMatchingResourcePatternResolver();
// е®һдҪ“зұ»еҜ№еә”зҡ„дҪҚзҪ®
bean.setTypeAliasesPackage(typeAliasesPackage);
// mybatisзҡ„XMLзҡ„й…ҚзҪ®
bean.setMapperLocations(resolver.getResources(mapperLocation));
bean.setConfigLocation(resolver.getResource(configLocation));
return bean.getObject();
}жңҖеҗҺиҝҳеҫ—й…ҚзҪ®дёӢдәӢеҠЎпјҢеҗҰеҲҷдәӢеҠЎдёҚз”ҹж•Ҳ
/**
* и®ҫзҪ®дәӢеҠЎпјҢдәӢеҠЎйңҖиҰҒзҹҘйҒ“еҪ“еүҚдҪҝз”Ёзҡ„жҳҜе“ӘдёӘж•°жҚ®жәҗжүҚиғҪиҝӣиЎҢдәӢеҠЎеӨ„зҗҶ
*/
@Bean
public DataSourceTransactionManager dataSourceTransactionManager() {
return new DataSourceTransactionManager(routingDataSource());
}4)гҖҒйҖүжӢ©ж•°жҚ®жәҗ
еӨҡж•°жҚ®жәҗй…ҚзҪ®еҘҪдәҶпјҢдҪҶжҳҜд»Јз ҒеұӮйқўеҰӮдҪ•йҖүжӢ©йҖүжӢ©ж•°жҚ®жәҗе‘ўпјҹиҝҷйҮҢд»Ӣз»ҚдёӨз§ҚеҠһжі•пјҡ
aгҖҒжіЁи§ЈејҸ
йҰ–е…Ҳе®ҡд№үдёҖдёӘеҸӘиҜ»жіЁи§ЈпјҢиў«иҝҷдёӘжіЁи§Јж–№жі•дҪҝз”ЁиҜ»еә“пјҢе…¶д»–дҪҝз”ЁеҶҷеә“пјҢеҰӮжһңйЎ№зӣ®жҳҜдёӯйҖ”ж”№йҖ жҲҗиҜ»еҶҷеҲҶзҰ»еҸҜдҪҝз”ЁиҝҷдёӘж–№жі•пјҢж— йңҖдҝ®ж”№дёҡеҠЎд»Јз ҒпјҢеҸӘиҰҒеңЁеҸӘиҜ»зҡ„serviceж–№жі•дёҠеҠ дёҖдёӘжіЁи§ЈеҚіеҸҜгҖӮ
@Target({ElementType.METHOD,ElementType.TYPE})
@Retention(RetentionPolicy.RUNTIME)
public @interface ReadOnly {
}然еҗҺеҶҷдёҖдёӘеҲҮйқўжқҘеҲҮжҚўж•°жҚ®дҪҝз”Ёе“Әз§Қж•°жҚ®жәҗпјҢйҮҚеҶҷgetOrderдҝқиҜҒжң¬еҲҮйқўдјҳе…Ҳзә§й«ҳдәҺдәӢеҠЎеҲҮйқўдјҳе…Ҳзә§пјҢеңЁеҗҜеҠЁзұ»еҠ дёҠ@EnableTransactionManagement(order = 10),дёәдәҶд»Јз ҒеҰӮдёӢпјҡ
@Aspect
@Component
public class ReadOnlyInterceptor implements Ordered {
private static final Logger log= LoggerFactory.getLogger(ReadOnlyInterceptor.class);
@Around("@annotation(readOnly)")
public Object setRead(ProceedingJoinPoint joinPoint,ReadOnly readOnly) throws Throwable{
try{
DbContextHolder.setDbType(DbContextHolder.READ);
return joinPoint.proceed();
}finally {
//жё…жҘҡDbTypeдёҖж–№йқўдёәдәҶйҒҝе…ҚеҶ…еӯҳжі„жјҸпјҢжӣҙйҮҚиҰҒзҡ„жҳҜйҒҝе…ҚеҜ№еҗҺз»ӯеңЁжң¬зәҝзЁӢдёҠжү§иЎҢзҡ„ж“ҚдҪңдә§з”ҹеҪұе“Қ
DbContextHolder.clearDbType();
log.info("жё…йҷӨthreadLocal");
}
}
@Override
public int getOrder() {
return 0;
}
}bгҖҒж–№жі•еҗҚејҸ
иҝҷз§Қж–№жі•дёҚи®ёиҰҒжіЁи§ЈпјҢдҪҶжҳҜйңҖиҰҒдәӢеҠЎеҗҚз§°жҢүдёҖе®ҡ规еҲҷзј–еҶҷпјҢ然еҗҺйҖҡиҝҮеҲҮйқўжқҘи®ҫзҪ®ж•°жҚ®еә“зұ»еҲ«пјҢжҜ”еҰӮsetXXXи®ҫзҪ®дёәеҶҷгҖҒgetXXXи®ҫзҪ®дёәиҜ»пјҢд»Јз ҒжҲ‘е°ұдёҚеҶҷдәҶпјҢеә”иҜҘйғҪзҹҘйҒ“жҖҺд№ҲеҶҷгҖӮ
4гҖҒжөӢиҜ•
зј–еҶҷеҘҪд»Јз ҒжқҘиҜ•иҜ•з»“жһңеҰӮдҪ•пјҢдёӢйқўжҳҜиҝҗиЎҢжҲӘеӣҫпјҡ

springbootдёҖз§Қе…Ёж–°зҡ„зј–зЁӢ规иҢғпјҢе…¶и®ҫи®Ўзӣ®зҡ„жҳҜз”ЁжқҘз®ҖеҢ–ж–°Springеә”з”Ёзҡ„еҲқе§Ӣжҗӯе»әд»ҘеҸҠејҖеҸ‘иҝҮзЁӢпјҢSpringBootд№ҹжҳҜдёҖдёӘжңҚеҠЎдәҺжЎҶжһ¶зҡ„жЎҶжһ¶пјҢжңҚеҠЎиҢғеӣҙжҳҜз®ҖеҢ–й…ҚзҪ®ж–Ү件гҖӮ
д»ҘдёҠе°ұжҳҜеҰӮдҪ•еңЁspring bootдёӯй…ҚзҪ®иҜ»еҶҷеҲҶзҰ»пјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ