жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еүҚиЁҖ
ambdaеҚіlambdaиЎЁиҫҫејҸпјҢз®Җз§°lambdaгҖӮжң¬иҙЁдёҠжҳҜеҸҜд»Ҙдј йҖ’з»ҷе…¶е®ғеҮҪж•°зҡ„дёҖе°Ҹж®өд»Јз ҒгҖӮжңүдәҶlambdaпјҢеҸҜд»ҘиҪ»жқҫең°жҠҠйҖҡз”Ёд»Јз Ғз»“жһ„жҠҪеҸ–жҲҗеә“еҮҪж•°гҖӮlambdaжңҖеёёи§Ғзҡ„з”ЁйҖ”жҳҜе’ҢйӣҶеҗҲдёҖиө·й…ҚеҗҲгҖӮkotlinз”ҡиҮіиҝҳжӢҘжңүеёҰжҺҘ收иҖ…зҡ„lambdaпјҢиҝҷжҳҜдёҖз§Қзү№ж®Ҡзҡ„lambdaгҖӮ
жң¬ж–ҮжҳҜеҜ№<<kotlinе®һжҲҳ>>дёӯ вҖңlambdaзј–зЁӢвҖқдёҖз« зҡ„жҖ»з»“пјҢдё»иҰҒи®°еҪ•дәҶдёҖдәӣжҲ‘и®ӨдёәжҜ”иҫғйҮҚиҰҒзҡ„зӮ№
еңЁkotlinдёӯеёёи§Ғзҡ„lambdaз”Ёжі•дё»иҰҒз”ұд»ҘдёӢеҮ з§Қпјҡ
lambdaиЎЁиҫҫејҸзҡ„еҹәжң¬иҜӯжі•
дёӢйқўжҳҜдёҖдёӘlambdaиЎЁиҫҫејҸзҡ„еҹәжң¬иҜӯжі•:
{ x:Int, y:Int -> x + y }
lambdaиЎЁиҫҫејҸе§Ӣз»Ҳз”ЁиҠұжӢ¬еҸ·еҢ…еӣҙпјҢе®һеҸӮ并没жңүз”ЁжӢ¬еҸ·жӢ¬иө·жқҘгҖӮз®ӯеӨҙжҠҠе®һеҸӮеҲ—иЎЁе’Ңlambdaзҡ„еҮҪж•°дҪ“йҡ”ејҖ
lambdaдҪңдёәеҮҪж•°зҡ„еҸӮж•°дј йҖ’
еҸҜд»ҘжҠҠlambdaиЎЁиҫҫејҸеӯҳеӮЁеңЁдёҖдёӘеҸҳйҮҸдёӯпјҢжҠҠиҝҷдёӘеҸҳйҮҸеҪ“еҒҡжҷ®йҖҡеҮҪж•°еҜ№еҫ…пјҢд№ҹеҸҜд»ҘзӣҙжҺҘеҶҷдҪңеҮҪж•°еҸӮж•°пјҢжҜ”еҰӮжңүдёҖдёӘintOperatorеҮҪж•°, иҝҷдёӘеҮҪж•°жҺҘ收дёӨдёӘintеҸӮж•°пјҢе’ҢдёҖдёӘеҮҪж•°гҖӮ
fun intOperator(o1: Int, o2: Int, run: (a: Int, b: Int) -> Int) {
run(o1, o2)
}
val sumLambda = { x: Int, y: Int -> x + y }
intOperator(1, 2, sumLambda)
intOperator(1, 2, {x:Int, y:Int -> x + y})
дёҠйқўеҸҜд»ҘзңӢеҲ°пјҢжҲ‘们зӣҙжҺҘжҠҠlambdaеҪ“еҒҡдёҖдёӘеҮҪж•°дј йҖ’дёӘintOperator()дҪңдёәеҸӮж•°гҖӮ
еҰӮжһңlambdaиЎЁиҫҫејҸжҳҜеҮҪж•°и°ғз”Ёзҡ„жңҖеҗҺдёҖдёӘе®һеҸӮпјҢе®ғеҸҜд»Ҙж”ҫеҲ°жӢ¬еҸ·еӨ–иҫ№:
intOperator(1, 2) { x: Int, y: Int -> x + y }
еҰӮжһңlambdaиЎЁиҫҫејҸжҳҜеҮҪж•°зҡ„е”ҜдёҖе®һеҸӮж—¶пјҢиҝҳеҸҜд»ҘеҺ»жҺүи°ғз”Ёд»Јз Ғдёӯзҡ„з©әжӢ¬еҸ·еҜ№
жҜ”еҰӮдёӢйқўиҝҷдёӘдҫӢеӯҗ
fun myPrint(lambda: () -> Unit) {
lambda()
}
myPrint{
print("a")
}
зңҒз•ҘlambdaеҸӮж•°зұ»еһӢ并дҪҝз”Ёй»ҳи®ӨеҸӮж•°еҗҚз§°
еңЁkotlinдёӯеҰӮжһңlambdaеҸӮж•°зҡ„зұ»еһӢеҸҜд»Ҙиў«жҺЁеҜјеҮәжқҘпјҢжҲ‘们е°ұдёҚйңҖиҰҒжҳҫзӨәеЈ°жҳҺе®ғпјҢжҜ”еҰӮжҲ‘们常用зҡ„еә“еҮҪж•° map:
listOf("1", "2", "3").map{
//
}
еңЁиҝҷдёӘд»Јз ҒдёӯдҪҝз”ЁдәҶй»ҳи®ӨеҸӮж•°дҪҝз”Ёitд»ЈжӣҝгҖӮеңЁkotlinдёӯпјҢеҰӮжһңеҪ“еүҚдёҠдёӢж–Үжңҹжңӣзҡ„жҳҜеҸӘжңүдёҖдёӘеҸӮж•°зҡ„lambdaдё”иҝҷдёӘеҸӮж•°зҡ„зұ»еһӢеҸҜд»ҘжҺЁж–ӯеҮәжқҘпјҢе°ұдјҡз”ҹжҲҗиҝҷдёӘеҗҚз§°гҖӮ
е…Ғи®ёеңЁlambdaеҶ…йғЁи®ҝй—®йқһfinalеҸҳйҮҸз”ҡиҮідҝ®ж”№д»–们
еңЁjavaдёӯжҲ‘们жҳҜзҹҘйҒ“зҡ„пјҡеҢҝеҗҚеҶ…йғЁзұ»дёҚиғҪи®ҝй—®йқһfinalеҸҳйҮҸпјҢдҪҶеңЁkotlinдёӯеҸҜд»Ҙ:
fun main(args: Array<String>) {
var count = 0
listOf("1", "2", "3").forEach{
count++
}
print(count)
}
е…¶е®һеҜ№дәҺkotlinжқҘиҜҙпјҢеҰӮжһңеңЁlambadдёӯеј•з”ЁйқһfinalеҸҳйҮҸпјҢе®ғзҡ„еҖјдјҡиў«е°ҒиЈ…иө·жқҘпјҢ并且дјҡе’Ңlambdaд»Јз ҒдёҖеқ—еӯҳеӮЁгҖӮ
еҪ“然еҜ№дәҺејӮжӯҘд»Јз ҒжҲ–иҖ…дәӢ件е“Қеә”еӣһи°ғиҝҷдёӘжҳҜж— ж•Ҳзҡ„гҖӮ
жҲҗе‘ҳеј•з”Ё
еңЁдёҠйқўжҲ‘们зҹҘйҒ“еҸҜд»ҘзӣҙжҺҘжҠҠlambdaеҪ“еҒҡеҮҪж•°зҡ„еҸӮж•°дј йҖ’з»ҷдёҖдёӘеҮҪж•°пјҢдҪҶжҳҜеҰӮжһңеҪ“еҒҡеҸӮж•°дј йҖ’зҡ„д»Јз Ғе·Із»Ҹиў«е®ҡд№үжҲҗдәҶеҮҪж•°йӮЈжҖҺд№ҲеҠһе‘ўпјҹ
еңЁkotlinдёӯеҸҜд»ҘдҪҝз”Ё::жҠҠеҮҪж•°иҪ¬жҚўжҲҗдёҖдёӘеҖјпјҢд»ҺиҖҢдј йҖ’з»ҷеҮҪж•°гҖӮиҝҷйҮҢжҜ”еҰӮжңүдёҖдёӘPersonзұ»пјҢд»–жңүдёҖдёӘsayеҮҪж•°пјҢжҲ‘们еҸҜд»Ҙиҝҷж ·иҺ·еҫ—иҝҷдёӘеҮҪж•°зҡ„еј•з”Ёпјҡ
val sayQuote = Person::say
иҝҷз§ҚиЎЁиҫҫејҸеҸ«еҒҡжҲҗе‘ҳеј•з”ЁпјҢеҜ№дәҺйЎ¶еұӮеҮҪж•°еҸҜд»ҘзӣҙжҺҘ ::say,жқҘиҺ·еҫ—иҝҷдёӘеҮҪж•°зҡ„еј•з”ЁгҖӮ
еёёз”Ёзҡ„еә“еҮҪж•°
еҜ№дәҺйӣҶеҗҲпјҢkotlinжҸҗдҫӣдәҶдё°еҜҢзҡ„еә“еҮҪж•°дҫҝдәҺжҲ‘们дҪҝз”ЁпјҢеҜ№дәҺиҝҷдәӣеҮҪж•°иҝҷйҮҢжҲ‘们еҸӘд»Ӣз»ҚдёҖдәӣе…ій”®зӮ№гҖӮ
filterдёҺmap
filterеҮҪж•°дјҡйҒҚеҺҶйӣҶеҗҲ并йҖүеҮәеә”з”Ёз»ҷе®ҡlambdaеҗҺдјҡиҝ”еӣһtrueзҡ„йӮЈдәӣе…ғзҙ , йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢиҝ”еӣһзҡ„жҳҜдёҖдёӘж–°зҡ„йӣҶеҗҲ
val newList = listOf(1, 2, 3, 4).filter{ it % 2 == 0}
mapеҮҪж•°еҜ№йӣҶеҗҲдёӯзҡ„жҜҸдёҖдёӘе…ғзҙ еә”з”Ёз»ҷе®ҡзҡ„еҮҪ数并жҠҠз»“жһң收йӣҶеҲ°дёҖдёӘж–°йӣҶеҗҲдёӯ
val newList = listOf(1, 2, 3, 4).map{ it.toSting() }
allгҖҒanyгҖҒcountгҖҒfind
count дёҺ size
еңЁдёҖдәӣжғ…еҶөдёӢдҪҝз”ЁcountиҰҒй«ҳж•ҲдәҺsizeпјҢ жҜ”еҰӮз»ҹи®ЎйӣҶеҗҲдёӯжңүеӨҡе°‘дёӘеҒ¶ж•°:
listOf(1, 2, 3, 4, 5).count({it % 2 == 0})
listOf(1, 2, 3, 4, 5).filter({it % 2 == 0}).size
дёҠйқўдёӨз§ҚеҒҡжі•йғҪеҸҜд»Ҙе®һзҺ°иҝҷдёӘйңҖжұӮпјҢдёҚиҝҮfilterдјҡеҲӣе»әдёҖдёӘж–°зҡ„йӣҶеҗҲпјҢиҖҢ countж–№жі•еҸӘдјҡи·ҹиёӘеҢ№й…Қе…ғзҙ зҡ„ж•°йҮҸпјҢдёҚе…іеҝғе…ғзҙ жң¬иә«гҖӮ
е…¶д»–иҝҳжңү groupBy/flatMap/flattenпјҢиҝҷйҮҢдёҚз»Ҷи®ІдәҶгҖӮ
жғ°жҖ§йӣҶеҗҲж“ҚдҪң : еәҸеҲ—
еңЁиҜҙд»Җд№ҲжҳҜжғ°жҖ§йӣҶеҗҲж“ҚдҪңд№ӢеүҚпјҢжҲ‘们е…ҲжқҘзңӢдёҖдёӢйқһжғ°жҖ§йӣҶеҗҲж“ҚдҪңmapдёҺfilter, д»ҘиҺ·еҸ–姓еҗҚдёәAејҖеӨҙзҡ„дәәзҡ„еҗҚеӯ—дёәдҫӢ:
peoples.map{it.name}.filter{it.startWith("A")}
жҲ‘们иҰҒзҹҘйҒ“filterе’ҢmapйғҪдјҡиҝ”еӣһдёҖдёӘеҲ—иЎЁжқҘдҝқеӯҳз»“жһңпјҢеҰӮжһңpeoplesиҝҷдёӘйӣҶеҗҲе…ғзҙ йқһеёёеӨҡзҡ„иҜқпјҢйӮЈдә§з”ҹзҡ„иҝҷдёӘдёӯй—ҙйӣҶеҗҲе°ұйқһеёёеӨ§пјҢ并且иҝҷдёӘй“ҫејҸи°ғз”ЁдјҡйқһеёёдҪҺж•ҲгҖӮ
дёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳkotlinеј•е…ҘдәҶ жғ°жҖ§йӣҶеҗҲ:еәҸеҲ—, еәҸеҲ—дёӯзҡ„е…ғзҙ зҡ„жұӮеҖјжҳҜжғ°жҖ§зҡ„пјҢдёҚйңҖиҰҒеҲӣе»әйӣҶеҗҲжқҘдҝқеӯҳдёӯй—ҙз»“жһңпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁеәҸеҲ—жқҘи§ЈеҶідёҠйқўзҡ„й—®йўҳ:
peoples.asSequence().map{it.name}.filter{it.startWith("A")}.toList()
еәҸеҲ—зҡ„ж“ҚдҪң
еәҸеҲ—зҡ„ж“ҚдҪңеҲҶдёәдёӨзұ»пјҡдёӯй—ҙе’Ңжң«з«Ҝж“ҚдҪң, д»ҘдёҠйқўйӮЈдёӘдҫӢеӯҗдёәдҫӢ:
peoples.asSequence().map{it.name}.filter{it.startWith("A")}.toList()
mapгҖҒfilterйғҪжҳҜдёӯй—ҙж“ҚдҪңпјҢtoListдёәжң«з«Ҝж“ҚдҪңгҖӮдёҖж¬Ўдёӯй—ҙж“ҚдҪңиҝ”еӣһзҡ„жҳҜеҸҰдёҖдёӘеәҸеҲ—пјҢиҝҷдёӘж–°еәҸеҲ—зҹҘйҒ“еҰӮдҪ•еҸҳжҚўеҺҹе§ӢеәҸеҲ—дёӯзҡ„е…ғзҙ пјҢиҖҢдёҖж¬Ўжң«з«Ҝж“ҚдҪңиҝ”еӣһзҡ„жҳҜдёҖдёӘз»“жһңпјҢиҝҷдёӘз»“жһңеҸҜиғҪжҳҜйӣҶеҗҲгҖҒе…ғзҙ гҖҒж•°еӯ—зӯүгҖӮ
еәҸеҲ—дёӯдёӯй—ҙж“ҚдҪңзҡ„и®Ўз®—йғҪжҳҜз”ұжң«з«Ҝж“ҚдҪңи§ҰеҸ‘зҡ„гҖӮ
жҲ‘们еҸҜд»ҘдҪҝз”Ёжү©еұ•еҮҪж•°asSequenceжҠҠд»»ж„ҸйӣҶеҗҲиҪ¬жҚўжҲҗеәҸеҲ—пјҢи°ғз”ЁtoListжқҘеҒҡеҸҚеҗ‘иҪ¬жҚў
жҲ‘们жқҘеҜ№жҜ”дёҖдёӢдёҠйқўдёӨз§Қж–№жі•:
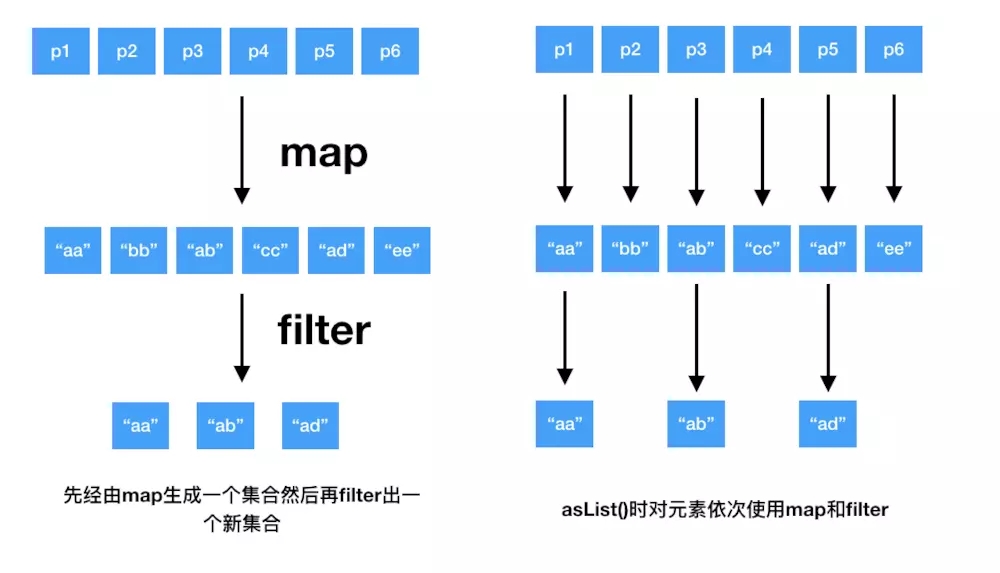
жғ°жҖ§йӣҶеҗҲ.png
еҸҜд»ҘзңӢеҲ°пјҢдҪҝз”ЁеәҸеҲ—дјҡжҳҺжҳҫжҜ”зӣҙжҺҘдҪҝз”Ёmapе’ҢfilterжқҘе®ҢжҲҗиҝҷдёӘд»»еҠЎж•ҲзҺҮжӣҙй«ҳ
жіЁж„ҸеҜ№дәҺж··еҗҲmap/filterпјҢиҝҷз§Қж“ҚдҪңж—¶пјҢеҰӮжһңиў«ж“ҚдҪңйӣҶеҗҲжҜ”иҫғе°ҸпјҢжҳҜдёҚйңҖиҰҒдҪҝз”ЁеәҸеҲ—зҡ„гҖӮиҮідәҺеәҸеҲ—еҰӮдҪ•жүӢеҠЁеҲӣе»әпјҢиҝҷйҮҢдёҚеҒҡз»Ҷ究
kotlinдёҺJavaеҮҪж•°ејҸжҺҘеҸЈ
еҮҪж•°ејҸжҺҘеҸЈжҳҜжҢҮеёҰжңүдёҖдёӘжҠҪиұЎж–№жі•зҡ„жҺҘеҸЈпјҢеңЁjava apiдёӯжҜ”еҰӮRunnableгҖҒCallableзӯү
жҲ‘们еңЁе®һйҷ…дҪҝз”Ёkotlinж—¶пјҢеҸҜиғҪеӨ§йғЁеҲҶAPIиҝҳжҳҜjava APIпјҢдҪҶжҳҜkotlinзҡ„lambdaеҸҜд»Ҙж— зјқең°е’ҢjavaAPIдә’ж“ҚдҪңпјҢжҜ”еҰӮз»ҷдёҖдёӘbuttonи®ҫзҪ®onclickдәӢ件:
button.setOnClickListener{ //... }
иҝҷдёӘж“ҚдҪңеңЁjava8д№ӢеүҚжҲ‘们дёҚеҫ—дёҚйҖҡиҝҮеҲӣе»әдёҖдёӘеҢҝеҗҚеҶ…йғЁзұ»жқҘе®һзҺ°гҖӮ
lambdaиЎЁиҫҫејҸзҡ„еҸҜйҮҚз”ЁжҖ§
жҜ”еҰӮжңүдёҖдёӘеҮҪж•°postponeComputation()пјҢжҺҘ收дёҖдёӘеҮҪж•°пјҢ并еҫӘзҺҜжү§иЎҢиҝҷдёӘеҮҪж•°жҢҮе®ҡж¬Ўж•°:
postponeComputation(1000, object:Runnable{
override fun run(){
print(42)
}
})
еҪ“дҪ жҳҫзӨәеЈ°жҳҺиҝҷдёӘеҸӮж•°еҜ№иұЎж—¶пјҢжҜҸж¬Ўи°ғз”ЁйғҪдјҡеҲӣе»әдёҖдёӘж–°зҡ„е®һдҫӢпјҢиҖҢдҪҝз”Ёlambdaжғ…еҶөдёҚеҗҢ:еҰӮжһңlambdaжІЎжңүи®ҝй—®д»»дҪ•жқҘиҮӘиҮӘе®ҡд№үе®ғзҡ„еҮҪж•°зҡ„еҸҳйҮҸпјҢзӣёеә”зҡ„еҢҝеҗҚзұ»е®һдҫӢеҸҜд»ҘеңЁеӨҡж¬Ўи°ғз”ЁдёӯйҮҚз”Ё:
postponeComputation(1000, { print(42) })
дҪҶжҳҜеҰӮжһңlambdaд»ҺеҢ…еӣҙе®ғзҡ„дҪңз”ЁеҹҹдёӯжҚ•жҚүдәҶеҸҳйҮҸпјҢжҜҸж¬Ўи°ғз”Ёе°ұдёҚеҶҚеҸҜиғҪйҮҚз”ЁеҗҢдёҖдёӘе®һдҫӢдәҶгҖӮ иҮідәҺдёәд»Җд№Ҳе°ҶдјҡеңЁ Lambdaзҡ„е®һзҺ°з»ҶиҠӮзҡ„и®ІеҲ°гҖӮ
Lambdaзҡ„е®һзҺ°з»ҶиҠӮ
еңЁkotlinдёӯпјҢжҜҸдёӘеҮҪж•°ејҸжҺҘеҸЈзҡ„lambdaйғҪдјҡиў«зј–иҜ‘жҲҗдёҖдёӘеҢҝеҗҚзұ»пјҲйҷӨеҶ…иҒ”lambda)гҖӮеҰӮжһңlambdaжҚ•жҚүдәҶеҸҳйҮҸпјҢжҜҸдёӘиў«жҚ•жҚүзҡ„еҸҳйҮҸдјҡеңЁеҢҝеҗҚеҶ…йғЁзұ»дёӯжңүеҜ№еә”зҡ„еӯ—ж®өпјҢиҖҢдё”жҜҸж¬Ўи°ғз”ЁиҝҷдёӘlambdaйғҪдјҡеҲӣе»әдёҖдёӘиҝҷдёӘеҢҝеҗҚеҶ…йғЁзұ»зҡ„е®һдҫӢгҖӮеҰӮжһңжІЎжңүжҚ•жҚүеҸҳйҮҸпјҢе°ұдјҡеҲӣе»әдёҖдёӘеҚ•дҫӢзҡ„зұ»гҖӮ
зј–иҜ‘еҗҺзҡ„еҢҝеҗҚеҶ…йғЁзұ»зҡ„еҗҚз§°з”ұlambdaеЈ°жҳҺжүҖеңЁзҡ„еҮҪж•°еҗҚз§°еҠ дёҠеҗҺзјҖиЎҚз”ҹеҮәжқҘзҡ„,жҜ”еҰӮдёӢйқўиҝҷдёӘlambda:
class Person{
fun test(){
a.setRunnable({
print("a")
})
}
}
иҝҷдёӘlambdaдјҡиў«зј–иҜ‘жҲҗ:
class Person$1:Runnable{
override fun run(){
print("a")
}
}
lambdaдёҺеҮҪж•°ејҸжҺҘеҸЈзҡ„иҪ¬жҚў
жңүдәӣж—¶еҖҷжҲ‘们йңҖиҰҒеҮҪж•°ејҸжҺҘеҸЈзҡ„е®һдҫӢпјҢжҜ”еҰӮдёҖдёӘж–№жі•иҝ”еӣһзҡ„жҳҜдёҖдёӘеҮҪж•°ејҸжҺҘеҸЈпјҢиҝҷж—¶еҖҷе°ұдёҚиғҪзӣҙжҺҘиҝ”еӣһдёҖдёӘlambdaдәҶ:
fun getRunnable():Runnable{}
иҝҷж—¶еҖҷеҰӮжһңзӣҙжҺҘиҝҷж ·еҶҷе°ұдјҡжҠҘй”ҷ : fun getRunnable() = { } ,иҝҷжҳҜеӣ дёәзј–иҜ‘еҷЁдёҚдјҡжҷәиғҪиҪ¬жҚўпјҢдёҚиҝҮkotlinжҸҗдҫӣдәҶ еҮҪж•°ејҸжҺҘеҸЈжһ„йҖ ж–№жі•жқҘдҪҝж“ҚдҪңжӣҙж–№дҫҝ:
fun getRunnable() = Runnable{ }
Runnable{}жҳҜзј–иҜ‘еҷЁз”ҹжҲҗзҡ„ж–№жі•пјҢзӯүеҗҢдәҺдҪҝз”ЁеҢҝеҗҚеҜ№иұЎзҡ„ж–№ејҸгҖӮ
еёҰжҺҘ收иҖ…зҡ„lambda: with дёҺ apply
иҝҷдёӨдёӘеҮҪж•°ејҸkotlinж ҮеҮҶеә“дёӯзҡ„еҮҪж•°гҖӮеёҰжҺҘеҸ—иҖ…жҳҜжҢҮпјҡеңЁlambdaеҮҪж•°дҪ“еҸҜд»Ҙи°ғз”ЁдёҖдёӘдёҚеҗҢеҜ№иұЎзҡ„ж–№жі•пјҢиҖҢдё”ж— йЎ»еҖҹеҠ©д»»дҪ•йўқеӨ–йҷҗе®ҡз¬ҰгҖӮ
with
withжҳҜдёҖдёӘжҺҘ收дёӨдёӘеҸӮж•°зҡ„еҮҪж•°пјҢдёҖдёӘеҸӮж•°жҳҜ иў«жҺҘ收иҖ…пјҢ е®ғдјҡиў«дј з»ҷ第дәҢдёӘеҸӮж•° lambdaиЎЁиҫҫејҸ пјҢ еңЁlambdaиЎЁиҫҫејҸзқҖе‘ўдёӘжҲ‘们еҸҜд»ҘдёҚз”Ёд»»дҪ•йҷҗе®ҡз¬ҰзӣҙжҺҘи®ҝй—®иҝҷдёӘеҖјзҡ„ж–№жі•е’ҢеұһжҖ§
fun alphabet():String{
val stringBuilder = StringBuilder()
return with(stringBuilder){
for(letter in 'A'..'Z'){
append(letter) //д№ҹеҸҜд»ҘдҪҝз”Ёthis.append()
}
toString()
}
}
withзҡ„иҝ”еӣһеҖјжҳҜжү§иЎҢдәҶlambdaд»Јз Ғзҡ„з»“жһң
apply
applyдёҺwithзҡ„е”ҜдёҖеҢәеҲ«жҳҜе®ғе§Ӣз»Ҳиҝ”еӣһжҺҘ收иҖ…еҜ№иұЎгҖӮдёҠйқўзҡ„еҮҪж•°жҲ‘们еҸҜд»Ҙиҝҷж ·ж”№еҶҷпјҡ
fun alphabet() = StringBuilder().apply{
for(letter in 'A'..'Z'){
append(letter) //д№ҹеҸҜд»ҘдҪҝз”Ёthis.append()
}
}.toString()
еҶ…иҒ”еҮҪж•°:ж¶ҲйҷӨLambdaеёҰжқҘзҡ„иҝҗиЎҢж—¶ејҖй”Җ
дёҠйқўжҲ‘们已з»ҸзҹҘйҒ“пјҢlambdaиЎЁиҫҫејҸдјҡиў«жӯЈеёёең°зј–иҜ‘жҲҗеҢҝеҗҚзұ»пјҢиҝҷиЎЁзӨәжҜҸи°ғз”ЁдёҖж¬ЎlambdaиЎЁиҫҫејҸпјҢдёҖдёӘйўқеӨ–зҡ„зұ»е°ұдјҡиў«еҲӣе»әпјҢдёәдәҶи§ЈеҶіиҝҷдёӘиҝҗиЎҢж—¶жҖ§иғҪзҡ„ејҖй”ҖпјҢkotlinжҸҗдҫӣдәҶinlineдҝ®йҘ°з¬ҰпјҢеҰӮжһңдҪҝз”Ёinline
дҝ®йҘ°з¬Ұж Үи®°дёҖдёӘеҮҪж•°пјҢеңЁеҮҪж•°иў«дҪҝз”Ёзҡ„ж—¶еҖҷзј–иҜ‘еҷЁе№¶дёҚдјҡз”ҹжҲҗеҮҪж•°и°ғз”Ёзҡ„д»Јз ҒпјҢиҖҢжҳҜдҪҝз”ЁеҮҪж•°е®һзҺ°зҡ„зңҹе®һд»Јз ҒжӣҝжҚўжҜҸдёҖж¬Ўзҡ„еҮҪж•°и°ғз”ЁгҖӮ
е…ҲжқҘдёҫдёҖдёӘдҫӢеӯҗ:
inline fun test(action:()->T){
action()
}
fun foo(){
test{
print("a")
}
}
foo()е®һйҷ…дјҡиў«зј–иҜ‘дёәдёӢйқўзҡ„д»Јз Ғ:
fun foo_(){
print("a")
}
д»ҺдёҠйқўиҝҷдёӘдҫӢеӯҗеҸҜд»ҘзңӢеҮәпјҢдҪңдёәеҸӮж•°зҡ„lambdaиЎЁиҫҫејҸдјҡиў«зӣҙжҺҘжӣҝжҚўеҲ°жңҖз»Ҳз”ҹжҲҗзҡ„д»Јз ҒдёӯпјҢиҖҢдёҚжҳҜиў«еҢ…еҗ«еңЁдёҖдёӘе®һзҺ°дәҶеҮҪж•°жҺҘеҸЈзҡ„еҢҝеҗҚзұ»дёӯгҖӮ
жіЁж„ҸеҰӮжһңlambdaеҸӮж•°еңЁжҹҗдёӘең°ж–№иў«дҝқеӯҳиө·жқҘпјҢд»ҘдҫҝеҗҺйқўеҸҜд»Ҙ继з»ӯдҪҝз”ЁпјҢиҝҷз§ҚlambdaиЎЁиҫҫејҸе°ҶдёҚдјҡиў«еҶ…иҒ”пјҢеӣ дёәеҝ…йЎ»иҰҒжңүдёҖдёӘеҢ…еҗ«иҝҷдәӣд»Јз Ғзҡ„еҜ№иұЎеӯҳеңЁ
еҶ…иҒ”зҡ„йӣҶеҗҲж“ҚдҪң
kotlinж ҮеҮҶеә“дёӯзҡ„mapгҖҒfilterзӯүеӨ§йғЁеҲҶеҮҪж•°йғҪжҳҜеҶ…иҒ”еҮҪж•°пјҢеӣ жӯӨдҪҝз”Ёж ҮеҮҶеә“еҮҪж•°дёҚйңҖиҰҒжӢ…еҝғжҖ§иғҪејҖй”ҖгҖӮ
жҖ»з»“
д»ҘдёҠе°ұжҳҜиҝҷзҜҮж–Үз« зҡ„е…ЁйғЁеҶ…е®№дәҶпјҢеёҢжңӣжң¬ж–Үзҡ„еҶ…е®№еҜ№еӨ§е®¶зҡ„еӯҰд№ жҲ–иҖ…е·ҘдҪңе…·жңүдёҖе®ҡзҡ„еҸӮиҖғеӯҰд№ д»·еҖјпјҢеҰӮжһңжңүз–‘й—®еӨ§е®¶еҸҜд»Ҙз•ҷиЁҖдәӨжөҒпјҢи°ўи°ўеӨ§е®¶еҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ