жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚжҖҺд№ҲеңЁAndroidдёӯе®һзҺ°зЎ¬д»¶еҠ йҖҹпјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ
дәҶ解硬件еҠ йҖҹеҜ№AppејҖеҸ‘зҡ„ж„Ҹд№ү
еҜ№дәҺAppејҖеҸ‘иҖ…пјҢз®ҖеҚ•дәҶ解硬件еҠ йҖҹеҺҹзҗҶеҸҠдёҠеұӮAPIе®һзҺ°пјҢејҖеҸ‘ж—¶е°ұеҸҜд»Ҙе……еҲҶеҲ©з”ЁзЎ¬д»¶еҠ йҖҹжҸҗй«ҳйЎөйқўзҡ„жҖ§иғҪгҖӮд»ҘAndroidдёҫдҫӢпјҢе®һзҺ°дёҖдёӘеңҶи§’зҹ©еҪўжҢүй’®йҖҡеёёжңүдёӨз§Қж–№жЎҲпјҡдҪҝз”ЁPNGеӣҫзүҮпјӣдҪҝз”Ёд»Јз ҒпјҲXML/Javaпјүе®һзҺ°гҖӮз®ҖеҚ•еҜ№жҜ”дёӨз§Қж–№жЎҲеҰӮдёӢгҖӮ
| ж–№жЎҲ | еҺҹзҗҶ | зү№зӮ№ |
|---|---|---|
| дҪҝз”ЁPNGеӣҫзүҮпјҲBitmapDrawableпјү | и§Јз ҒPNGеӣҫзүҮз”ҹжҲҗBitmapпјҢдј еҲ°еә•еұӮпјҢз”ұGPUжёІжҹ“ | еӣҫзүҮи§Јз Ғж¶ҲиҖ—CPUиҝҗз®—иө„жәҗпјҢBitmapеҚ з”ЁеҶ…еӯҳеӨ§пјҢз»ҳеҲ¶ж…ў |
| дҪҝз”ЁXMLжҲ–Javaд»Јз Ғе®һзҺ°пјҲShapeDrawableпјү | зӣҙжҺҘе°ҶShapeдҝЎжҒҜдј еҲ°еә•еұӮпјҢз”ұGPUжёІжҹ“ | ж¶ҲиҖ—CPUиө„жәҗе°‘пјҢеҚ з”ЁеҶ…еӯҳе°ҸпјҢз»ҳеҲ¶еҝ« |
йЎөйқўжёІжҹ“иғҢжҷҜзҹҘиҜҶ
йЎөйқўжёІжҹ“ж—¶пјҢиў«з»ҳеҲ¶зҡ„е…ғзҙ жңҖз»ҲиҰҒиҪ¬жҚўжҲҗзҹ©йҳөеғҸзҙ зӮ№пјҲеҚіеӨҡз»ҙж•°з»„еҪўејҸпјҢзұ»дјје®үеҚ“дёӯзҡ„BitmapпјүпјҢжүҚиғҪиў«жҳҫзӨәеҷЁжҳҫзӨәгҖӮ
йЎөйқўз”ұеҗ„з§Қеҹәжң¬е…ғзҙ з»„жҲҗпјҢдҫӢеҰӮеңҶеҪўгҖҒеңҶи§’зҹ©еҪўгҖҒзәҝж®өгҖҒж–Үеӯ—гҖҒзҹўйҮҸеӣҫпјҲеёёз”ЁиҙқеЎһе°”жӣІзәҝз»„жҲҗпјүгҖҒBitmapзӯүгҖӮ
е…ғзҙ з»ҳеҲ¶ж—¶е°Өе…¶жҳҜеҠЁз”»з»ҳеҲ¶иҝҮзЁӢдёӯпјҢз»Ҹеёёж¶үеҸҠжҸ’еҖјгҖҒзј©ж”ҫгҖҒж—ӢиҪ¬гҖҒйҖҸжҳҺеәҰеҸҳеҢ–гҖҒеҠЁз”»иҝҮжёЎгҖҒжҜӣзҺ»з’ғжЁЎзіҠпјҢз”ҡиҮіеҢ…жӢ¬3DеҸҳжҚўгҖҒзү©зҗҶиҝҗеҠЁпјҲдҫӢеҰӮжёёжҲҸдёӯеёёи§Ғзҡ„жҠӣзү©зәҝиҝҗеҠЁпјүгҖҒеӨҡеӘ’дҪ“ж–Ү件解з ҒпјҲдё»иҰҒеңЁжЎҢйқўжңәдёӯжңүеә”з”ЁпјҢ移еҠЁи®ҫеӨҮдёҖиҲ¬дёҚз”ЁGPUеҒҡи§Јз Ғпјүзӯүиҝҗз®—гҖӮ
з»ҳеҲ¶иҝҮзЁӢз»ҸеёёйңҖиҰҒиҝӣиЎҢйҖ»иҫ‘иҫғз®ҖеҚ•гҖҒдҪҶж•°жҚ®йҮҸеәһеӨ§зҡ„жө®зӮ№иҝҗз®—гҖӮ
CPUдёҺGPUз»“жһ„еҜ№жҜ”
CPUпјҲCentral Processing UnitпјҢдёӯеӨ®еӨ„зҗҶеҷЁпјүжҳҜи®Ўз®—жңәи®ҫеӨҮж ёеҝғеҷЁд»¶пјҢз”ЁдәҺжү§иЎҢзЁӢеәҸд»Јз ҒпјҢиҪҜ件ејҖеҸ‘иҖ…еҜ№жӯӨйғҪеҫҲзҶҹжӮүпјӣGPUпјҲGraphics Processing UnitпјҢеӣҫеҪўеӨ„зҗҶеҷЁпјүдё»иҰҒз”ЁдәҺеӨ„зҗҶеӣҫеҪўиҝҗз®—пјҢйҖҡеёёжүҖиҜҙвҖңжҳҫеҚЎвҖқзҡ„ж ёеҝғйғЁд»¶е°ұжҳҜGPUгҖӮ
дёӢйқўжҳҜCPUе’ҢGPUзҡ„з»“жһ„еҜ№жҜ”еӣҫгҖӮе…¶дёӯпјҡ
й»„иүІзҡ„ControlдёәжҺ§еҲ¶еҷЁпјҢз”ЁдәҺеҚҸи°ғжҺ§еҲ¶ж•ҙдёӘCPUзҡ„иҝҗиЎҢпјҢеҢ…жӢ¬еҸ–еҮәжҢҮд»ӨгҖҒжҺ§еҲ¶е…¶д»–жЁЎеқ—зҡ„иҝҗиЎҢзӯүпјӣ
з»ҝиүІзҡ„ALUпјҲArithmetic Logic UnitпјүжҳҜз®—жңҜйҖ»иҫ‘еҚ•е…ғпјҢз”ЁдәҺиҝӣиЎҢж•°еӯҰгҖҒйҖ»иҫ‘иҝҗз®—пјӣ
ж©ҷиүІзҡ„Cacheе’ҢDRAMеҲҶеҲ«дёәзј“еӯҳе’ҢRAMпјҢз”ЁдәҺеӯҳеӮЁдҝЎжҒҜгҖӮ
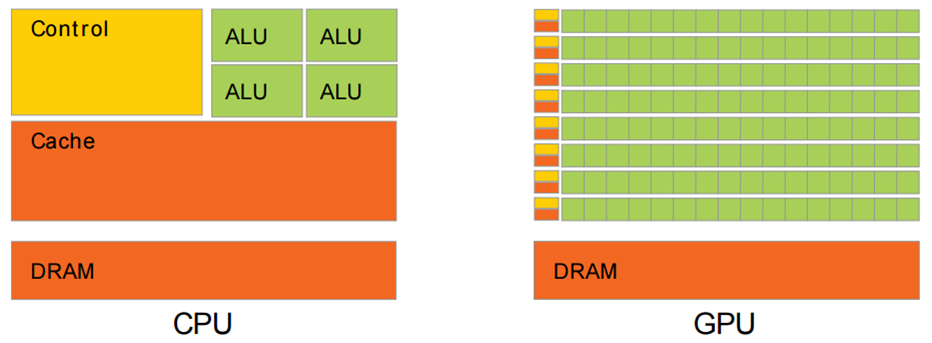
д»Һз»“жһ„еӣҫеҸҜд»ҘзңӢеҮәпјҢCPUзҡ„жҺ§еҲ¶еҷЁиҫғдёәеӨҚжқӮпјҢиҖҢALUж•°йҮҸиҫғе°‘гҖӮеӣ жӯӨCPUж“…й•ҝеҗ„з§ҚеӨҚжқӮзҡ„йҖ»иҫ‘иҝҗз®—пјҢдҪҶдёҚж“…й•ҝж•°еӯҰе°Өе…¶жҳҜжө®зӮ№иҝҗз®—гҖӮ
д»Ҙ8086дёәдҫӢпјҢдёҖзҷҫеӨҡжқЎжұҮзј–жҢҮд»ӨеӨ§йғЁеҲҶйғҪжҳҜйҖ»иҫ‘жҢҮд»ӨпјҢж•°еӯҰи®Ўз®—зӣёе…ізҡ„дё»иҰҒжҳҜ16дҪҚеҠ еҮҸд№ҳйҷӨе’Ң移дҪҚиҝҗз®—гҖӮдёҖж¬Ўж•ҙеһӢе’ҢйҖ»иҫ‘иҝҗз®—дёҖиҲ¬йңҖиҰҒ1~3дёӘжңәеҷЁе‘ЁжңҹпјҢиҖҢжө®зӮ№иҝҗз®—иҰҒиҪ¬жҚўжҲҗж•ҙж•°и®Ўз®—пјҢдёҖж¬Ўиҝҗз®—еҸҜиғҪж¶ҲиҖ—дёҠзҷҫдёӘжңәеҷЁе‘ЁжңҹгҖӮ
жӣҙз®ҖеҚ•зҡ„CPUз”ҡиҮіеҸӘжңүеҠ жі•жҢҮд»ӨпјҢеҮҸжі•з”ЁиЎҘз ҒеҠ жі•е®һзҺ°пјҢд№ҳжі•з”ЁзҙҜеҠ е®һзҺ°пјҢйҷӨжі•з”ЁеҮҸжі•еҫӘзҺҜе®һзҺ°гҖӮ
зҺ°д»ЈCPUдёҖиҲ¬йғҪеёҰжңү硬件жө®зӮ№иҝҗз®—еҷЁпјҲFPUпјүпјҢдҪҶдё»иҰҒйҖӮз”ЁдәҺж•°жҚ®йҮҸдёҚеӨ§зҡ„жғ…еҶөгҖӮ
CPUжҳҜдёІиЎҢз»“жһ„гҖӮд»Ҙи®Ўз®—100дёӘж•°еӯ—дёәдҫӢпјҢеҜ№дәҺCPUзҡ„дёҖдёӘж ёпјҢжҜҸж¬ЎеҸӘиғҪи®Ўз®—дёӨдёӘж•°зҡ„е’ҢпјҢз»“жһңйҖҗжӯҘзҙҜеҠ гҖӮ
е’ҢCPUдёҚеҗҢзҡ„жҳҜпјҢGPUе°ұжҳҜдёәе®һзҺ°еӨ§йҮҸж•°еӯҰиҝҗз®—и®ҫи®Ўзҡ„гҖӮд»Һз»“жһ„еӣҫдёӯеҸҜд»ҘзңӢеҲ°пјҢGPUзҡ„жҺ§еҲ¶еҷЁжҜ”иҫғз®ҖеҚ•пјҢдҪҶеҢ…еҗ«дәҶеӨ§йҮҸALUгҖӮGPUдёӯзҡ„ALUдҪҝз”ЁдәҶ并иЎҢи®ҫи®ЎпјҢдё”е…·жңүиҫғеӨҡжө®зӮ№иҝҗз®—еҚ•е…ғгҖӮ
硬件еҠ йҖҹзҡ„дё»иҰҒеҺҹзҗҶпјҢе°ұжҳҜйҖҡиҝҮеә•еұӮиҪҜ件代з ҒпјҢе°ҶCPUдёҚж“…й•ҝзҡ„еӣҫеҪўи®Ўз®—иҪ¬жҚўжҲҗGPUдё“з”ЁжҢҮд»ӨпјҢз”ұGPUе®ҢжҲҗгҖӮ
жү©еұ•пјҡеҫҲеӨҡи®Ўз®—жңәдёӯзҡ„GPUжңүиҮӘе·ұзӢ¬з«Ӣзҡ„жҳҫеӯҳпјӣжІЎжңүзӢ¬з«ӢжҳҫеӯҳеҲҷдҪҝз”Ёе…ұдә«еҶ…еӯҳзҡ„еҪўејҸпјҢд»ҺеҶ…еӯҳдёӯеҲ’еҲҶдёҖеқ—еҢәеҹҹдҪңдёәжҳҫеӯҳгҖӮжҳҫеӯҳеҸҜд»ҘдҝқеӯҳGPUжҢҮд»ӨзӯүдҝЎжҒҜгҖӮ
并иЎҢз»“жһ„дёҫдҫӢпјҡзә§иҒ”еҠ жі•еҷЁ
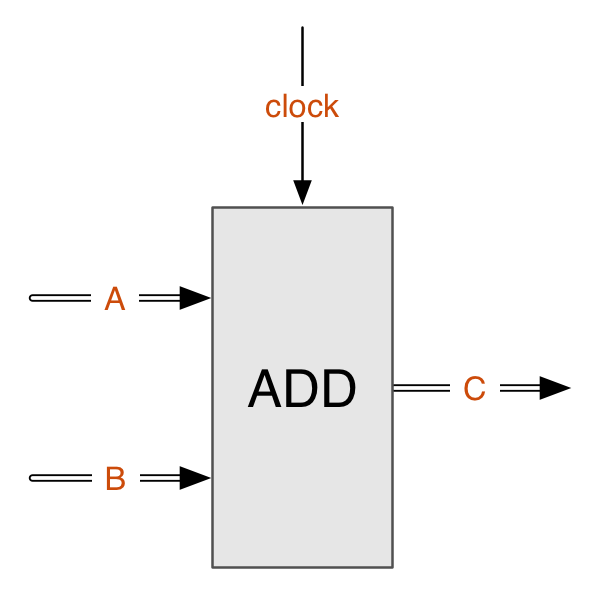
дёәдәҶж–№дҫҝзҗҶи§ЈпјҢиҝҷйҮҢе…Ҳд»Һеә•еұӮз”өи·Ҝз»“жһ„зҡ„и§’еәҰдёҫдёҖдёӘдҫӢеӯҗгҖӮеҰӮдёӢеӣҫдёәдёҖдёӘеҠ жі•еҷЁпјҢеҜ№еә”е®һйҷ…зҡ„ж•°еӯ—з”өи·Ҝз»“жһ„гҖӮ
AгҖҒBдёәиҫ“е…ҘпјҢCдёәиҫ“еҮәпјҢдё”AгҖҒBгҖҒCеқҮдёәжҖ»зәҝпјҢд»Ҙ32дҪҚCPUдёәдҫӢпјҢеҲҷжҜҸж №жҖ»зәҝе®һйҷ…з”ұ32ж №еҜјзәҝз»„жҲҗпјҢжҜҸж №еҜјзәҝз”ЁдёҚеҗҢзҡ„з”өеҺӢиЎЁзӨәдёҖдёӘдәҢиҝӣеҲ¶зҡ„0жҲ–1гҖӮ
Clockдёәж—¶й’ҹдҝЎеҸ·зәҝпјҢжҜҸдёӘеӣәе®ҡзҡ„ж—¶й’ҹе‘ЁжңҹеҸҜеҗ‘е…¶иҫ“е…ҘдёҖдёӘзү№е®ҡзҡ„з”өеҺӢдҝЎеҸ·пјҢжҜҸеҪ“дёҖдёӘж—¶й’ҹдҝЎеҸ·еҲ°жқҘж—¶пјҢAе’ҢBзҡ„е’Ңе°ұдјҡиҫ“еҮәеҲ°CгҖӮ
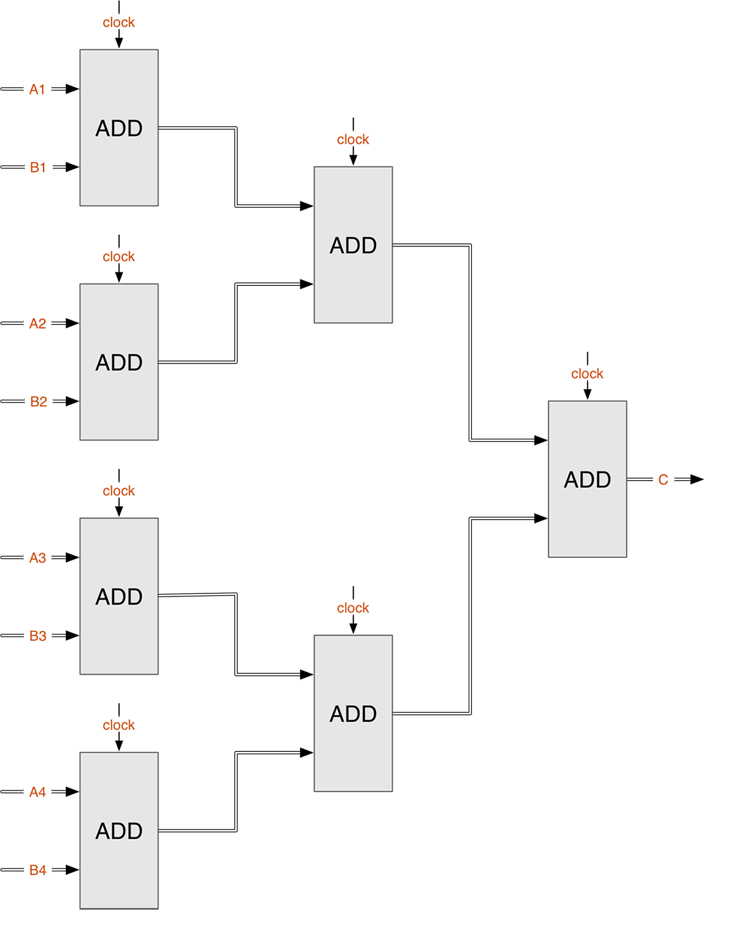
зҺ°еңЁжҲ‘们иҰҒи®Ўз®—8дёӘж•ҙж•°зҡ„е’ҢгҖӮ
еҜ№дәҺCPUиҝҷз§ҚдёІиЎҢз»“жһ„пјҢд»Јз Ғзј–еҶҷеҫҲз®ҖеҚ•пјҢз”ЁforеҫӘзҺҜжҠҠжүҖжңүж•°еӯ—йҖҗдёӘзӣёеҠ еҚіеҸҜгҖӮдёІиЎҢз»“жһ„еҸӘжңүдёҖдёӘеҠ жі•еҷЁпјҢйңҖиҰҒ7ж¬ЎжұӮе’Ңиҝҗз®—пјӣжҜҸж¬Ўи®Ўз®—е®ҢйғЁеҲҶе’ҢпјҢиҝҳиҰҒе°Ҷе…¶еҶҚиҪ¬з§»еҲ°еҠ жі•еҷЁзҡ„иҫ“е…Ҙз«ҜпјҢеҒҡдёӢдёҖж¬Ўи®Ўз®—гҖӮж•ҙдёӘиҝҮзЁӢиҮіе°‘иҰҒж¶ҲиҖ—еҚҒеҮ дёӘжңәеҷЁе‘ЁжңҹгҖӮ
иҖҢеҜ№дәҺ并иЎҢз»“жһ„пјҢдёҖз§Қеёёи§Ғзҡ„и®ҫи®ЎжҳҜзә§иҒ”еҠ жі•еҷЁпјҢеҰӮдёӢеӣҫпјҢе…¶дёӯжүҖжңүзҡ„clockиҝһеңЁдёҖиө·гҖӮеҪ“йңҖиҰҒзӣёеҠ зҡ„8дёӘж•°жҚ®еңЁиҫ“е…Ҙз«ҜA1~B4еҮҶеӨҮеҘҪеҗҺпјҢз»ҸиҝҮдёүдёӘж—¶й’ҹе‘ЁжңҹпјҢжұӮе’Ңж“ҚдҪңе°ұе®ҢжҲҗдәҶгҖӮеҰӮжһңж•°жҚ®йҮҸжӣҙеӨ§гҖҒзә§иҒ”зҡ„еұӮзә§жӣҙеӨ§пјҢеҲҷ并иЎҢз»“жһ„зҡ„дјҳеҠҝжӣҙжҳҺжҳҫгҖӮ
з”ұдәҺз”өи·Ҝзҡ„йҷҗеҲ¶пјҢдёҚе®№жҳ“йҖҡиҝҮжҸҗй«ҳж—¶й’ҹйў‘зҺҮгҖҒеҮҸе°Ҹж—¶й’ҹе‘Ёжңҹзҡ„ж–№ејҸжҸҗй«ҳиҝҗз®—йҖҹеәҰгҖӮ并иЎҢз»“жһ„йҖҡиҝҮеўһеҠ з”өи·Ҝ规模гҖҒ并иЎҢеӨ„зҗҶпјҢжқҘе®һзҺ°жӣҙеҝ«зҡ„иҝҗз®—гҖӮдҪҶ并иЎҢз»“жһ„дёҚе®№жҳ“е®һзҺ°еӨҚжқӮйҖ»иҫ‘пјҢеӣ дёәеҗҢж—¶иҖғиҷ‘еӨҡдёӘж”Ҝи·Ҝзҡ„иҫ“еҮәз»“жһңпјҢ并еҚҸи°ғеҗҢжӯҘеӨ„зҗҶзҡ„иҝҮзЁӢеҫҲеӨҚжқӮпјҲжңүзӮ№еғҸеӨҡзәҝзЁӢзј–зЁӢпјүгҖӮ
GPU并иЎҢи®Ўз®—дёҫдҫӢ
еҒҮи®ҫжҲ‘们жңүеҰӮдёӢеӣҫеғҸеӨ„зҗҶд»»еҠЎпјҢз»ҷжҜҸдёӘеғҸзҙ еҖјеҠ 1гҖӮGPU并иЎҢи®Ўз®—зҡ„ж–№ејҸз®ҖеҚ•зІ—жҡҙпјҢеңЁиө„жәҗе…Ғи®ёзҡ„жғ…еҶөдёӢпјҢеҸҜд»ҘдёәжҜҸдёӘеғҸзҙ ејҖдёҖдёӘGPUзәҝзЁӢпјҢз”ұе…¶иҝӣиЎҢеҠ 1ж“ҚдҪңгҖӮж•°еӯҰиҝҗз®—йҮҸи¶ҠеӨ§пјҢиҝҷз§Қ并иЎҢж–№ејҸжҖ§иғҪдјҳеҠҝи¶ҠжҳҺжҳҫгҖӮ

Androidдёӯзҡ„硬件еҠ йҖҹ
еңЁAndroidдёӯпјҢеӨ§еӨҡж•°еә”з”Ёзҡ„з•ҢйқўйғҪжҳҜеҲ©з”Ёеёёи§„зҡ„ViewжқҘжһ„е»әзҡ„пјҲйҷӨдәҶжёёжҲҸгҖҒи§Ҷйў‘гҖҒеӣҫеғҸзӯүеә”з”ЁеҸҜиғҪзӣҙжҺҘдҪҝз”ЁOpenGL ESпјүгҖӮдёӢйқўж №жҚ®Android 6.0еҺҹз”ҹзі»з»ҹзҡ„JavaеұӮд»Јз ҒпјҢеҜ№Viewзҡ„иҪҜ件е’Ң硬件еҠ йҖҹжёІжҹ“еҒҡдёҖдәӣеҲҶжһҗе’ҢеҜ№жҜ”гҖӮ
DisplayList
DisplayListжҳҜдёҖдёӘеҹәжң¬з»ҳеҲ¶е…ғзҙ пјҢеҢ…еҗ«е…ғзҙ еҺҹе§ӢеұһжҖ§пјҲдҪҚзҪ®гҖҒе°әеҜёгҖҒи§’еәҰгҖҒйҖҸжҳҺеәҰзӯүпјүпјҢеҜ№еә”Canvasзҡ„drawXxx()ж–№жі•пјҲеҰӮдёӢеӣҫпјүгҖӮ
дҝЎжҒҜдј йҖ’жөҒзЁӢпјҡCanvas(Java API) вҖ”> OpenGL(C/C++ Lib) вҖ”> й©ұеҠЁзЁӢеәҸ вҖ”> GPUгҖӮ
еңЁAndroid 4.1еҸҠд»ҘдёҠзүҲжң¬пјҢDisplayListж”ҜжҢҒеұһжҖ§пјҢеҰӮжһңViewзҡ„дёҖдәӣеұһжҖ§еҸ‘з”ҹеҸҳеҢ–пјҲжҜ”еҰӮScaleгҖҒAlphaгҖҒTranslateпјүпјҢеҸӘйңҖжҠҠеұһжҖ§жӣҙж–°з»ҷGPUпјҢдёҚйңҖиҰҒз”ҹжҲҗж–°зҡ„DisplayListгҖӮ
RenderNode
дёҖдёӘRenderNodeеҢ…еҗ«иӢҘе№ІдёӘDisplayListпјҢйҖҡеёёдёҖдёӘRenderNodeеҜ№еә”дёҖдёӘViewпјҢеҢ…еҗ«ViewиҮӘиә«еҸҠе…¶еӯҗViewзҡ„жүҖжңүDisplayListгҖӮ

Androidз»ҳеҲ¶жөҒзЁӢпјҲAndroid 6.0пјү
дёӢйқўжҳҜе®үеҚ“Viewе®Ңж•ҙзҡ„з»ҳеҲ¶жөҒзЁӢеӣҫпјҢдё»иҰҒйҖҡиҝҮйҳ…иҜ»жәҗз Ғе’Ңи°ғиҜ•еҫ—еҮәпјҢиҷҡзәҝз®ӯеӨҙиЎЁзӨәйҖ’еҪ’и°ғз”ЁгҖӮ
д»ҺViewRootImpl.performTraversalsеҲ°PhoneWindow.DecroView.drawChildжҳҜжҜҸж¬ЎйҒҚеҺҶViewж ‘зҡ„еӣәе®ҡжөҒзЁӢпјҢйҰ–е…Ҳж №жҚ®ж Үеҝ—дҪҚеҲӨж–ӯжҳҜеҗҰйңҖиҰҒйҮҚж–°еёғеұҖ并жү§иЎҢеёғеұҖпјӣ然еҗҺиҝӣиЎҢCanvasзҡ„еҲӣе»әзӯүж“ҚдҪңејҖе§Ӣз»ҳеҲ¶гҖӮ
еҰӮжһң硬件еҠ йҖҹдёҚж”ҜжҢҒжҲ–иҖ…иў«е…ій—ӯпјҢеҲҷдҪҝз”ЁиҪҜ件з»ҳеҲ¶пјҢз”ҹжҲҗзҡ„CanvasеҚіCanvas.classзҡ„еҜ№иұЎпјӣ
еҰӮжһңж”ҜжҢҒ硬件еҠ йҖҹпјҢеҲҷз”ҹжҲҗзҡ„жҳҜDisplayListCanvas.classзҡ„еҜ№иұЎпјӣ
дёӨиҖ…зҡ„isHardwareAccelerated()ж–№жі•иҝ”еӣһзҡ„еҖјеҲҶеҲ«дёәfalseгҖҒtrueпјҢViewж №жҚ®иҝҷдёӘеҖјеҲӨж–ӯжҳҜеҗҰдҪҝ用硬件еҠ йҖҹгҖӮ
Viewдёӯзҡ„draw(canvas,parent,drawingTime) - draw(canvas) - onDraw - dispachDraw - drawChildиҝҷжқЎйҖ’еҪ’и·Ҝеҫ„пјҲдёӢж–Үз®Җз§°Drawи·Ҝеҫ„пјүпјҢи°ғз”ЁдәҶCanvas.drawXxx()ж–№жі•пјҢеңЁиҪҜ件渲жҹ“ж—¶з”ЁдәҺе®һйҷ…з»ҳеҲ¶пјӣеңЁзЎ¬д»¶еҠ йҖҹж—¶пјҢз”ЁдәҺжһ„е»әDisplayListгҖӮ
Viewдёӯзҡ„updateDisplayListIfDirty - dispatchGetDisplayList - recreateChildDisplayListиҝҷжқЎйҖ’еҪ’и·Ҝеҫ„пјҲдёӢж–Үз®Җз§°DisplayListи·Ҝеҫ„пјүпјҢд»…еңЁзЎ¬д»¶еҠ йҖҹж—¶дјҡз»ҸиҝҮпјҢз”ЁдәҺеңЁйҒҚеҺҶViewж ‘з»ҳеҲ¶зҡ„иҝҮзЁӢдёӯжӣҙж–°DisplayListеұһжҖ§пјҢ并еҝ«йҖҹи·іиҝҮдёҚйңҖиҰҒйҮҚе»әDisplayListзҡ„ViewгҖӮ
Android 6.0дёӯпјҢе’ҢDisplayListзӣёе…ізҡ„APIзӣ®еүҚд»Қиў«ж Үи®°дёәвҖң@hideвҖқдёҚеҸҜи®ҝй—®пјҢиЎЁзӨәиҝҳдёҚжҲҗзҶҹпјҢеҗҺз»ӯзүҲжң¬еҸҜиғҪејҖж”ҫгҖӮ
硬件еҠ йҖҹжғ…еҶөдёӢпјҢdrawжөҒзЁӢжү§иЎҢз»“жқҹеҗҺDisplayListжһ„е»әе®ҢжҲҗпјҢ然еҗҺйҖҡиҝҮThreadedRenderer.nSyncAndDrawFrame()еҲ©з”ЁGPUз»ҳеҲ¶DisplayListеҲ°еұҸ幕дёҠгҖӮ

зәҜиҪҜ件з»ҳеҲ¶ VS 硬件еҠ йҖҹпјҲAndroid 6.0пјү
дёӢйқўж №жҚ®е…·дҪ“зҡ„еҮ з§ҚеңәжҷҜпјҢе…·дҪ“еҲҶжһҗдёҖдёӢ硬件еҠ йҖҹеүҚеҗҺзҡ„жөҒзЁӢдёҺеҠ йҖҹж•ҲжһңгҖӮ
| жёІжҹ“еңәжҷҜ | зәҜиҪҜ件з»ҳеҲ¶ | 硬件еҠ йҖҹ | еҠ йҖҹж•ҲжһңеҲҶжһҗ |
|---|---|---|---|
| йЎөйқўеҲқе§ӢеҢ– | з»ҳеҲ¶жүҖжңүView | еҲӣе»әжүҖжңүDisplayList | GPUеҲҶжӢ…дәҶеӨҚжқӮи®Ўз®—д»»еҠЎ |
| еңЁдёҖдёӘеӨҚжқӮйЎөйқўи°ғз”ЁиғҢжҷҜйҖҸжҳҺTextViewзҡ„setText()пјҢдё”и°ғз”ЁеҗҺе…¶е°әеҜёдҪҚзҪ®дёҚеҸҳ | йҮҚз»ҳи„ҸеҢәжүҖжңүView | TextViewеҸҠжҜҸдёҖзә§зҲ¶ViewйҮҚе»әDisplayList | йҮҚеҸ зҡ„е…„ејҹиҠӮзӮ№дёҚйңҖCPUйҮҚз»ҳпјҢGPUдјҡиҮӘиЎҢеӨ„зҗҶ |
| TextViewйҖҗеё§ж’ӯж”ҫAlpha / Translation / ScaleеҠЁз”» | жҜҸеё§йғҪиҰҒйҮҚз»ҳи„ҸеҢәжүҖжңүView | йҷӨ第дёҖеё§еҗҢеңәжҷҜ2пјҢд№ӢеҗҺжҜҸеё§еҸӘжӣҙж–°TextViewеҜ№еә”RenderNodeзҡ„еұһжҖ§ | еҲ·ж–°дёҖеё§жҖ§иғҪжһҒеӨ§жҸҗй«ҳпјҢеҠЁз”»жөҒз•…еәҰжҸҗй«ҳ |
| дҝ®ж”№TextViewйҖҸжҳҺеәҰ | йҮҚз»ҳи„ҸеҢәжүҖжңүView | зӣҙжҺҘи°ғз”ЁRenderNode.setAlpha()жӣҙж–° | еҠ йҖҹеүҚйңҖе…ЁйЎөйқўйҒҚеҺҶпјҢ并йҮҚз»ҳеҫҲеӨҡViewпјӣеҠ йҖҹеҗҺеҸӘи§ҰеҸ‘DecorView.updateDisplayListIfDirtyпјҢдёҚеҶҚеҫҖдёӢйҒҚеҺҶпјҢCPUжү§иЎҢж—¶й—ҙеҸҜеҝҪз•ҘдёҚи®Ў |
еңәжҷҜ1дёӯпјҢж— и®әжҳҜеҗҰеҠ йҖҹпјҢйҒҚеҺҶViewж ‘е№¶йғҪдјҡиө°Drawи·Ҝеҫ„гҖӮ硬件еҠ йҖҹеҗҺDrawи·Ҝеҫ„дёҚеҒҡе®һйҷ…з»ҳеҲ¶е·ҘдҪңпјҢеҸӘжҳҜжһ„е»әDisplayListпјҢеӨҚжқӮзҡ„з»ҳеҲ¶и®Ўз®—д»»еҠЎиў«GPUеҲҶжӢ…пјҢе·Із»ҸжңүдәҶиҫғеӨ§зҡ„еҠ йҖҹж•ҲжһңгҖӮ
еңәжҷҜ2дёӯпјҢTextViewи®ҫзҪ®еүҚеҗҺе°әеҜёдҪҚзҪ®дёҚеҸҳпјҢдёҚдјҡи§ҰеҸ‘йҮҚж–°LayoutгҖӮ
иҪҜ件з»ҳеҲ¶ж—¶пјҢTextViewжүҖеңЁеҢәеҹҹеҚідёәи„ҸеҢәгҖӮз”ұдәҺTextViewжңүйҖҸжҳҺеҢәеҹҹпјҢйҒҚеҺҶViewж ‘зҡ„иҝҮзЁӢдёӯпјҢе’Ңи„ҸеҢәйҮҚеҸ зҡ„еӨҡж•°ViewйғҪиҰҒйҮҚз»ҳпјҢеҢ…жӢ¬дёҺд№ӢйҮҚеҸ зҡ„е…„ејҹиҠӮзӮ№е’Ң他们зҡ„зҲ¶иҠӮзӮ№пјҲиҜҰи§ҒеҗҺйқўзҡ„д»Ӣз»ҚпјүпјҢдёҚйңҖиҰҒз»ҳеҲ¶зҡ„ViewеңЁdraw(canvas,parent,drawingTime)ж–№жі•дёӯеҲӨж–ӯзӣҙжҺҘиҝ”еӣһгҖӮ
硬件еҠ йҖҹеҗҺпјҢд№ҹйңҖиҰҒйҒҚеҺҶViewж ‘пјҢдҪҶеҸӘжңүTextViewеҸҠе…¶жҜҸдёҖеұӮзҲ¶иҠӮзӮ№йңҖиҰҒйҮҚе»әDisplayListпјҢиө°зҡ„жҳҜDrawи·Ҝеҫ„пјҢе…¶д»–ViewзӣҙжҺҘиө°дәҶDisplayListи·Ҝеҫ„пјҢеү©дёӢзҡ„е·ҘдҪңйғҪдәӨз»ҷGPUеӨ„зҗҶгҖӮйЎөйқўи¶ҠеӨҚжқӮпјҢдёӨиҖ…жҖ§иғҪе·®и·қи¶ҠжҳҺжҳҫгҖӮ
еңәжҷҜ3дёӯпјҢиҪҜ件з»ҳеҲ¶жҜҸдёҖеё§йғҪиҰҒеҒҡеӨ§йҮҸз»ҳеҲ¶е·ҘдҪңпјҢеҫҲе®№жҳ“еҜјиҮҙеҠЁз”»еҚЎйЎҝгҖӮ硬件еҠ йҖҹеҗҺпјҢеҠЁз”»иҝҮзЁӢзӣҙжҺҘиө°DisplayListи·Ҝеҫ„жӣҙж–°DisplayListзҡ„еұһжҖ§пјҢеҠЁз”»жөҒз•…еәҰиғҪеҫ—еҲ°жһҒеӨ§жҸҗй«ҳгҖӮ
еңәжҷҜ4дёӯпјҢдёӨиҖ…зҡ„жҖ§иғҪе·®и·қжӣҙжҳҺжҳҫгҖӮз®ҖеҚ•дҝ®ж”№йҖҸжҳҺеәҰпјҢиҪҜ件з»ҳеҲ¶д»Қ然иҰҒеҒҡеҫҲеӨҡе·ҘдҪңпјӣ硬件еҠ йҖҹеҗҺдёҖиҲ¬зӣҙжҺҘжӣҙж–°RenderNodeзҡ„еұһжҖ§пјҢдёҚйңҖиҰҒи§ҰеҸ‘invalidateпјҢд№ҹдёҚдјҡйҒҚеҺҶViewж ‘пјҲйҷӨдәҶе°‘ж•°ViewеҸҜиғҪиҰҒеҜ№AlphaеҒҡзү№ж®Ҡе“Қеә”并еңЁonSetAlpha()иҝ”еӣһtrueпјҢд»Јз ҒеҰӮдёӢпјүгҖӮ
public class View {
// ...
public void setAlpha(@FloatRange(from=0.0, to=1.0) float alpha) {
ensureTransformationInfo();
if (mTransformationInfo.mAlpha != alpha) {
mTransformationInfo.mAlpha = alpha;
if (onSetAlpha((int) (alpha * 255))) {
// ...
invalidate(true);
} else {
// ...
mRenderNode.setAlpha(getFinalAlpha());
// ...
}
}
}
protected boolean onSetAlpha(int alpha) {
return false;
}
// ...
}иҪҜ件з»ҳеҲ¶еҲ·ж–°йҖ»иҫ‘з®Җд»Ӣ
е®һйҷ…йҳ…иҜ»жәҗз Ғ并е®һйӘҢпјҢеҫ—еҮәйҖҡеёёжғ…еҶөдёӢзҡ„иҪҜ件з»ҳеҲ¶еҲ·ж–°йҖ»иҫ‘пјҡ
й»ҳи®Өжғ…еҶөдёӢпјҢViewзҡ„clipChildrenеұһжҖ§дёәtrueпјҢеҚіжҜҸдёӘViewз»ҳеҲ¶еҢәеҹҹдёҚиғҪи¶…еҮәе…¶зҲ¶Viewзҡ„иҢғеӣҙгҖӮеҰӮжһңи®ҫзҪ®дёҖдёӘйЎөйқўж №еёғеұҖзҡ„clipChildrenеұһжҖ§дёәfalseпјҢеҲҷеӯҗViewеҸҜд»Ҙи¶…еҮәзҲ¶Viewзҡ„з»ҳеҲ¶еҢәеҹҹгҖӮ
еҪ“дёҖдёӘViewи§ҰеҸ‘invalidateпјҢдё”жІЎжңүж’ӯж”ҫеҠЁз”»гҖҒжІЎжңүи§ҰеҸ‘layoutзҡ„жғ…еҶөдёӢпјҡ
clipChildrenдёәtrueж—¶пјҢи„ҸеҢәдјҡиў«иҪ¬жҚўжҲҗViewRootдёӯзҡ„RectпјҢеҲ·ж–°ж—¶еұӮеұӮеҗ‘дёӢеҲӨж–ӯпјҢеҪ“ViewдёҺи„ҸеҢәжңүйҮҚеҸ еҲҷйҮҚз»ҳгҖӮеҰӮжһңдёҖдёӘViewи¶…еҮәзҲ¶ViewиҢғеӣҙдё”дёҺи„ҸеҢәйҮҚеҸ пјҢдҪҶе…¶зҲ¶ViewдёҚдёҺи„ҸеҢәйҮҚеҸ пјҢиҝҷдёӘеӯҗViewдёҚдјҡйҮҚз»ҳгҖӮ
clipChildrenдёәfalseж—¶пјҢViewGroup.invalidateChildInParent()дёӯдјҡжҠҠи„ҸеҢәжү©еӨ§еҲ°иҮӘиә«ж•ҙдёӘеҢәеҹҹпјҢдәҺжҳҜдёҺиҝҷдёӘеҢәеҹҹйҮҚеҸ зҡ„жүҖжңүViewйғҪдјҡйҮҚз»ҳгҖӮ
еҜ№дәҺе…ЁдёҚйҖҸжҳҺзҡ„ViewпјҢе…¶иҮӘиә«дјҡи®ҫзҪ®ж Үеҝ—дҪҚPFLAG_DIRTYпјҢе…¶зҲ¶Viewдјҡи®ҫзҪ®ж Үеҝ—дҪҚPFLAG_DIRTY_OPAQUEгҖӮеңЁdraw(canvas)ж–№жі•дёӯпјҢеҸӘжңүиҝҷдёӘViewиҮӘиә«йҮҚз»ҳгҖӮ
еҜ№дәҺеҸҜиғҪжңүйҖҸжҳҺеҢәеҹҹзҡ„ViewпјҢе…¶иҮӘиә«е’ҢзҲ¶ViewйғҪдјҡи®ҫзҪ®ж Үеҝ—дҪҚPFLAG_DIRTYгҖӮ
е…ідәҺжҖҺд№ҲеңЁAndroidдёӯе®һзҺ°зЎ¬д»¶еҠ йҖҹе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ