您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
1. 问题描述:
WARN util.NativeCodeLoader: Unable to load native-hadoop library foryour platform… using builtin-java classes where applicable
问题原因:默认lib为32位,不支持64位。
解决办法:重新编译64位库 - 请注意在jdk1.8上会编译出错
# yum install cmake lzo-devel zlib-devel gccgcc-c++ autoconf automake libtool ncurses-devel openssl-deve
安装maven
#wget http://mirror.cc.columbia.edu/pub/software/apache/maven/maven-3/3.2.3/binaries/apache-maven-3.2.3-bin.tar.gz
# tar zxfapache-maven-3.2.3-bin.tar.gz -C /usr/local
# cd /usr/local
# ln -sapache-maven-3.2.3 maven
# vim/etc/profile
exportMAVEN_HOME=/usr/local/maven
exportPATH=${MAVEN_HOME}/bin:${PATH}
# source/etc/profile
安装ant
# wget http://apache.dataguru.cn//ant/binaries/apache-ant-1.9.4-bin.tar.gz
# tar zxf apache-ant-1.9.4-bin.tar.gz -C/usr/local
# vim /etc/profile
exportANT_HOME=/usr/local/apache-ant-1.9.4
exportPATH=$PATH:$ANT_HOME/bin
# source /etc/profile
安装findbugs
#wget http://prdownloads.sourceforge.net/findbugs/findbugs-2.0.3.tar.gz?download
# tar zxf findbugs-2.0.3.tar.gz -C/usr/local
# vim /etc/profile
export FINDBUGS_HOME=/opt/findbugs-2.0.3
export PATH=$PATH:$FINDBUGS_HOME/bin
安装protobuf
# wget https://protobuf.googlecode.com/files/protobuf-2.5.0.tar.gz
# tar zxf protobuf-2.5.0.tar.gz
# cd protobuf-2.5.0
# ./configure && make && makeinstall
下载源码包
#wget http://mirrors.hust.edu.cn/apache/hadoop/common/hadoop-2.5.0/hadoop-2.5.0-src.tar.gz
# tar zxf hadoop-2.5.0-src.tar.gz
# cd hadoop-2.5.0-src
# mvn clean install -DskipTests
# mvn package -Pdist,native -DskipTests -Dtar
替换旧的lib库
# mv /data/hadoop-2.5.0/lib/native /data/hadoop-2.5.0/lib/native_old
# cp -r /data/hadoop-2.5.0-src/hadoop-dist/target/hadoop-2.5.0/lib/native\
/data/hadoop-2.5.0/lib/native
# bin/hdfs getconf -namenodes
参考:
http://www.tuicool.com/articles/zaY7Rz
http://hadoop.apache.org/docs/current/hadoop-project-dist/hadoop-common/NativeLibraries.html#Supported_Platforms)
2.问题描述:
出现WARN hdfs.DFSClient:DataStreamer Exception,然后执行
sbin/stop-dfs.sh => namenode1: no datanode tostop
或hadoop dfsadmin -report查询不到集群中文件系统的信息
问题原因:重新格式化文件系统时,namenode产生的新的namespaceID与datanode所持有的namespaceID不一致造成的。
解决方案:在我们格式化namenode前,应首先删除dfs.data.dir所配置文件中的data文件夹下的所有内容。
3. 问题描述:
ERRORorg.apache.hadoop.hdfs.server.datanode.DataNode: java.io.IOException:Incompatible namespaceIDs in
问题原因: 每次namenode format会重新创建一个namenodeId,而dfs.data.dir参数配置的目录中包含的是上次format创建的id,和dfs.name.dir参数配置的目录中的id不一致。namenode format清空了namenode下的数据,但是没有清空datanode下的数据,导致启动时失败,所要做的就是每次fotmat前,清空dfs.data.dir参数配置的目录.
格式化hdfs的命令
解决方案:bin/hadoop namenode -format
MapReduce学习blog:http://www.cnblogs.com/xia520pi/archive/2012/05/16/2504205.html
4. 问题描述:
[root@namenode1hadoop]# hadoop fs -put README.txt /
15/01/04 21:50:49 WARN hdfs.DFSClient:DataStreamer Exception
org.apache.hadoop.ipc.RemoteException(java.io.IOException):File /README.txt._COPYING_ could only be replicated to 0 nodes instead ofminReplication (=1). There are 6datanode(s) running and no node(s) are excluded in this operation.
问题原因:是由于hdfs-site.xml的下列配置有误(下面的参数需要根据实际情况修改)
<property>
<name>dfs.block.size</name>
<value>268435456</value>
<description>The default block size for newfiles</description>
</property>
<property>
<name>dfs.datanode.max.xcievers</name>
<value>10240</value>
<description>
An Hadoop HDFS datanode has an upper bound on the number of files thatit will serve at any one time.
</description>
</property>
<property>
<name>dfs.datanode.du.reserved</name>
<value>32212254720</value>
<description>Reserved space in bytes per volume. Always leave thismuch space free for non dfs use.</description>
</property>
解决办法:修改上面的配置,然后重新启动。
5. 问题描述:
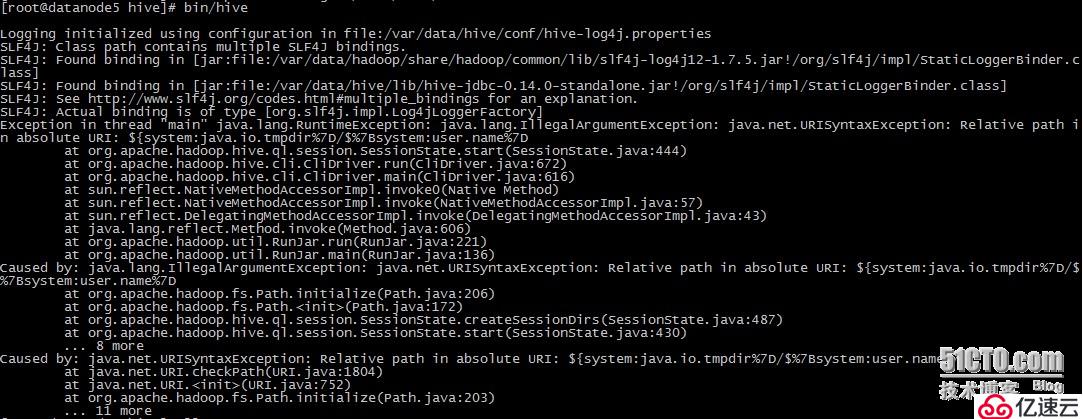
问题原因:slf4j bindings 冲突
解决办法:
# mv /var/data/hive-1.40/lib/hive-jdbc-0.14.0-standalone.jar/opt/
当hive依然不能启动时,检查一下
1.查看hive-site.xml配置,会看到配置值含有"system:java.io.tmpdir"的配置项
2.新建文件夹/var/data/hive/iotmp
3.将含有"system:java.io.tmpdir"的配置项的值修改为如上地址
启动hive,成功!
6.问题描述
HADOOP:Error Launching job : org.apache.hadoop.yarn.exceptions.InvalidResourceRequestException:Invalid resource request, requested memory < 0, or requested memory > maxconfigured, requestedMemory=1536, maxMemory=1024
问题原因:mapreduce默认需要的内存为1536M,分配的过小
<property>
<name>mapreduce.map.memory.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx410m</value>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>512</value>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx410m</value>
</property>
the 512 is value the yarn.scheduler.maximum-allocation-mb inyarn-site.xml, and the 1536 is default value ofyarn.app.mapreduce.am.resource.mb parameter in mapred-site.xml, make sure theallocation-mb>app.mapreduce.resouce will be ok.
解决办法:
调整上面的参数为2048,并扩充内存
7.问题描述:
Hadoop:java.lang.IncompatibleClassChangeError:
Found interface org.apache.hadoop.mapreduce.JobContext,but class was expected
问题原因: sqoop的版本和hadoop的版本不匹配
解决办法:重新编译sqoop,方法如下:
如何编译sqoop
第一步:
Additionally,building the documentation requires these tools:
* asciidoc
* make
* python 2.5+
* xmlto
* tar
* gzip
yum -y install git
yum -y install asciidoc
yum -y install make
yum -y install xmlto
yum -y install tar
yum -y install gzip
第二步:
下载相关软件包:
wget http://dist.codehaus.org/jetty/jetty-6.1.26/jetty-6.1.26.zip
wget http://mirrors.cnnic.cn/apache/sqoop/1.4.5/sqoop-1.4.5.tar.gz
mv jetty-6.1.26.zip/root/.m2/repository/org/mortbay/jetty/jetty/6.1.26/
第三步:
解压并修改相关文件:
tar -zxvf sqoop-1.4.5.tar.gz; cd sqoop-1.4.5
修改:build.xml后内容如下
<elseif>
<equalsarg1="${hadoopversion}" arg2="200" />
<then>
<propertyname="hadoop.version" value="2.5.0" />
<propertyname="hbase94.version" value="0.94.2" />
<propertyname="zookeeper.version" value="3.4.6" />
<propertyname="hadoop.version.full" value="2.5.0" />
<propertyname="hcatalog.version" value="0.13.0" />
<propertyname="hbasecompatprofile" value="2" />
<propertyname="avrohadoopprofile" value="2" />
</then>
</elseif>
修改550行和568行debug="${javac.debug}">
为:debug="${javac.debug}"includeantruntime="on">
修改:src/test/org/apache/sqoop/TestExportUsingProcedure.java
修改
修改第244行sql.append(StringUtils.repeat("?",", ",
为:sql.append(StringUtils.repeat("?,",
以上配置完成修改后,执行:ant package
如果编译成功会提示:BUILD SUCCESSFUL
第四步:打包我们需要的sqoop安装包
编译成功后,默认会在sqoop-1.4.5/build目录下生成sqoop-1.4.5.bin__hadoop-2.5.0
tar -zcfsqoop-1.4.5.bin__hadoop-2.5.0.tar.gz sqoop-1.4.5.bin__hadoop-2.5.0
完毕! 参考:http://www.aboutyun.com/thread-8462-1-1.html
8.问题描述:
执行命令:
# sqoopexport --connect jdbc:mysql://10.40.214.9:3306/emails \
--usernamehive --password hive --table izhenxin \
--export-dir/user/hive/warehouse/maillog.db/izhenxin_total
…
Caused by:java.lang.RuntimeException: Can't parse input data: '@QQ.com'
atizhenxin.__loadFromFields(izhenxin.java:378)
at izhenxin.parse(izhenxin.java:306)
atorg.apache.sqoop.mapreduce.TextExportMapper.map(TextExportMapper.java:83)
... 10 more
Caused by:java.lang.NumberFormatException: For input string: "@QQ.com"
…
15/01/19 23:15:21 INFO mapreduce.ExportJobBase: Transferred 0bytes in 46.0078 seconds (0 bytes/sec)
15/01/19 23:15:21 INFO mapreduce.ExportJobBase: Exported 0records.
15/01/19 23:15:21 ERROR tool.ExportTool: Error during export: Exportjob failed!
问题原因:
由于没有指定的文件的全路径导致的
事实上全路径应该是:
# hadoop fs -ls/user/hive/warehouse/maillog.db/izhenxin_total/
Found 1 items
-rw-r--r-- 2 rootsupergroup 2450 2015-01-19 23:50/user/hive/warehouse/maillog.db/izhenxin_total/000000_0
解决办法:
# sqoop export --connectjdbc:mysql://10.40.214.9:3306/emails --username hive --password hive --tableizhenxin --export-dir /user/hive/warehouse/maillog.db/izhenxin_total/000000_0--input-fields-terminated-by '\t'
依然报错:
mysql> create table izhenxin(id int(10)unsigned NOT NULL AUTO_INCREMENT,mail_domain varchar(32) DEFAULTNULL,sent_number int,bounced_number int, deffered_number int, PRIMARY KEY(`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='sent mail'; ##原来的表
##解决办法:先删除上面的表,然后创建下面的表以适应hive的表结构
mysql> create table izhenxin(mail_domainvarchar(32) DEFAULT NULL,sent_number int,bounced_number int, deffered_numberint) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT='sent mail';
##最终输出:
15/01/20 00:05:51 INFO mapreduce.ExportJobBase: Transferred6.9736 KB in 26.4035 seconds (270.4564 bytes/sec)
15/01/20 00:05:51 INFO mapreduce.ExportJobBase: Exported 132records.
mysql> select count(1) from izhenxin;
+----------+
| count(1) |
+----------+
| 132 |
+----------+
1 row in set (0.00 sec)
搞定!
9.问题描述:
15/01/27 10:48:56 INFO mapreduce.Job: Task Id :attempt_1420738964879_0244_m_000003_0, Status : FAILED
AttemptID:attempt_1420738964879_0244_m_000003_0 Timed out after600 secs
15/01/27 10:48:57 INFO mapreduce.Job: map 75% reduce 0%
15/01/27 10:49:08 INFO mapreduce.Job: map 100% reduce 0%
15/01/27 10:59:26 INFO mapreduce.Job: Task Id :attempt_1420738964879_0244_m_000003_1, Status : FAILED
AttemptID:attempt_1420738964879_0244_m_000003_1 Timed out after600 secs
15/01/27 10:59:27 INFO mapreduce.Job: map 75% reduce 0%
15/01/27 10:59:38 INFO mapreduce.Job: map 100% reduce 0%
15/01/27 11:09:55 INFO mapreduce.Job: Task Id :attempt_1420738964879_0244_m_000003_2, Status : FAILED
AttemptID:attempt_1420738964879_0244_m_000003_2 Timed out after600 secs
问题原因:
执行超时
解决办法:
vim mapred-site.xml
<property>
<name>mapred.task.timeout</name>
<value>1800000</value> <!-- 30 minutes -->
</property>
方法2:
Configuration conf=new Configuration();
long milliSeconds = 1000*60*60;<default is 600000, likewise can give any value)
conf.setLong("mapred.task.timeout",milliSeconds);
方法3:
setmapred.tasktracker.expiry.interval=1800000;
setmapred.task.timeout= 1800000;
15/02/01 03:03:37 ERROR manager.SqlManager: Error reading fromdatabase: java.sql.SQLException: Streaming result set com
.mysql.jdbc.RowDataDynamic@4c0f73a3 is still active. Nostatements may be issued when any streaming result sets are open
and in use on a givenconnection. Ensure that you have called .close() on any active streaming resultsets before attem
pting more queries.
java.sql.SQLException: Streaming result setcom.mysql.jdbc.RowDataDynamic@4c0f73a3 is still active. No statements may be
issued when any streamingresult sets are open and in use on a given connection. Ensure that you havecalled .close() o
n any active streaming result sets before attempting morequeries.
mysql-connector-java-5.1.18-bin.jar 更换为: mysql-connector-java-5.1.32-bin.jar
问题:
由于2015年4月24日,openstack虚拟机整体宕机,造成hadoop运行异常,datanode无法启动
解决办法:
重新格式化namenode
然后删除hdfs/data 并赋予可写权限
/var/data/hadoop/bin/hadoop namenode -format
rm -rf /var/hadoop/tmp/dfs/data #下面两条命令在所有节点都执行
chown -R 777 /var/hadoop/tmp/dfs/data
/var/data/hadoop/sbin/hadoop-daemons.sh start datanode
hdfs haadmin -transitionToActive namenode1 如果两个namenode都是standby状态,用该命令提升为active
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。