您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下Android中怎么实现混音,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
初识音频
从初中物理上我们就学到,声音是一种波。计算机只能处理离散的信号,通过收集足够多的离散的信号,来不断逼近波形,这个过程我们叫做采样。怎么样才能更好的还原声音信息呢?这里很自然引出两个概念了。
采样频率(Sample Rate):每秒采集声音的数量,它用赫兹(Hz)来表示。
采样率越高越靠近原声音的波形,常见的采样率有以下几种:
8khz:电话等使用,对于记录人声已经足够使用。
22.05khz:广播使用频率。
44.1kb:音频CD。
48khz:DVD、数字电视中使用。
96khz-192khz:DVD-Audio、蓝光高清等使用。
采样精度(Bit Depth): 它表示每次采样的精度,位数越多,能记录的范围就越大。
采样精度常用范围为8bit-32bit,而CD中一般都使用16bit。
把声音记录下来之后,通过喇叭的震动把波再还给空气传到你的耳朵就完成了这个完美的循环了。但是富有创造力的人类不会限制于此就结束了,很快人们发现,当把不同的声音传递到不同的喇叭的时候,竟然会惊奇地让声音变得有空间感了,即时是同一个声音,也比单个通道能获得更好的体验,于是就出现了什么立体声,5.1 环绕等看起来很高大上的东西。所以,音频又多了一个东西:
声音通道(Channel): 你知道每个通道存储的声音会从其中的一个喇叭出来就好了,不过可以通过算法的模拟来让没有那么多喇叭也能出来类似的效果。
有了声音通道,乐队在录音的时候就可以每个人插一条音轨了,然后每一个声音可以写到不同的通道里面,当然,实际录音当然都是后期混音而成的。下面介绍的其中一个混音算法会用到声音通道这个特性。
最后再介绍一个大家经常看到的概念:
比特率(bps [bits per second]): 其实看单位就很容易知道它要表达的意思了,就是每秒钟要播放多少 bit 的数据。公式一目了然:
比特率 = 采样率 × 采样深度 × 通道。
比如 采样率 = 44100,采样深度 = 16,通道 = 2 的音频的的比特率就是 44100 16 2 = 1411200 bps。
一般来说,比特率越高,音频质量越好。要注意一些比特率的换算不是 1024 作为一个级别换算的哈。
1,000 bps = 【1 kbps】 = 1,000 bit/s
1,000,000 bps = 【1 Mbps】 = 1,000,000 bit/s
1,000,000,000 bps = 【1 Gbps】 = 1,000,000,000 bit/s
音频在计算机中的表示
我们来看一下真实音频在计算机中究竟是怎样的表示状态,这里指的是原始的数据表示,而非编码(Mp3,Acc等)后的表示,平时我们看到的.wav后缀的音频,把前面 44 个字节用于记录采样率、通道等的头部信息去掉后就是就是原始的音频数据了。
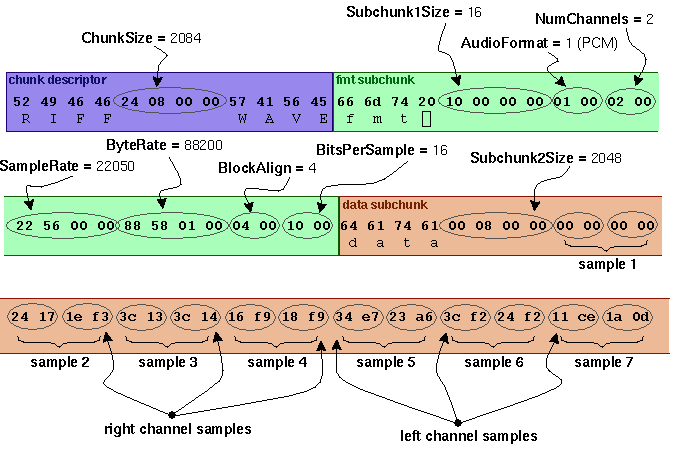
在理解了上面的概念之后,我们再来看这张图。对于文件头部信息我们就不详细介绍了,不影响我们理解介绍的混音处理方式,需要了解的可以点击这里。
我们抽取其中的一个采样来看,这里我加多了一个通道,便于大家理解通道的存储位置。
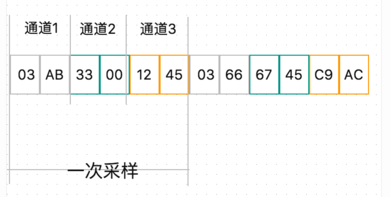
不难理解,这个采样中有三个通道,每通道采样精度是 16 比特。每个采样值的排序是 Little-Endian 低位在前的方式,比如通道 1 的采样值就是 AB03, 每个采样值的大小表示的是幅度信息。
混音的原理
音频混音的原理: 空气中声波的叠加等价于量化的语音信号的叠加。
这句话可能有点拗口,我们从程序员的角度去观察就不难理解了。下图是两条音轨的数据,将每个通道的值做线性叠加后的值就是混音的结果了。比如音轨A和音轨B的叠加,A.1 表示 A 音轨的 1 通道的值 AB03 , B.1 表示 B 音轨的 1 通道的值 1122 , 结果是 bc25,然后按照低位在前的方式排列,在合成音轨中就是 25bc,这里的表示都是 16 进制的。
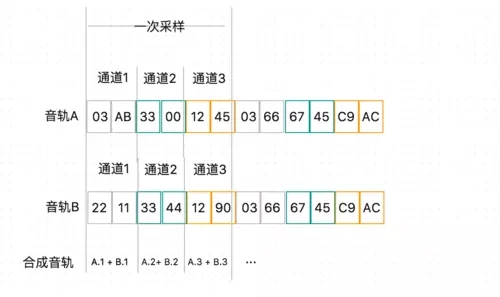
直接加起来就可以了?事情如果这么简单就好了。音频设备支持的采样精度肯定都是有限的,一般为 8 位或者 16 位,大一些的为 32 位。在音轨数据叠加的过程中,肯定会导致溢出的问题。为了解决这个问题,人们找了不少的办法。这里我主要介绍几种我用过的,并给出相关代码实现和最终的混音效果对比结果。
线性叠加平均
这种办法的原理非常简单粗暴,也不会引入噪音。原理就是把不同音轨的通道值叠加之后取平均值,这样就不会有溢出的问题了。但是会带来的后果就是某一路或几路音量特别小那么整个混音结果的音量会被拉低。
以下的的单路音轨的音频参数我们假定为采样频率一致,通道数一致,通道采样精度统一为 16 位。
其中参数 bMulRoadAudios 的一维表示的是音轨数,二维表示该音轨的音频数据。
Java 代码实现:
@Override
public byte[] mixRawAudioBytes(byte[][] bMulRoadAudios) {
if (bMulRoadAudios == null || bMulRoadAudios.length == 0)
return null;
byte[] realMixAudio = bMulRoadAudios[0];
if(realMixAudio == null){
return null;
}
final int row = bMulRoadAudios.length;
//单路音轨
if (bMulRoadAudios.length == 1)
return realMixAudio;
//不同轨道长度要一致,不够要补齐
for (int rw = 0; rw < bMulRoadAudios.length; ++rw) {
if (bMulRoadAudios[rw] == null || bMulRoadAudios[rw].length != realMixAudio.length) {
return null;
}
}
/**
* 精度为 16位
*/
int col = realMixAudio.length / 2;
short[][] sMulRoadAudios = new short[row][col];
for (int r = 0; r < row; ++r) {
for (int c = 0; c < col; ++c) {
sMulRoadAudios[r][c] = (short) ((bMulRoadAudios[r][c * 2] & 0xff) | (bMulRoadAudios[r][c * 2 + 1] & 0xff) << 8);
}
}
short[] sMixAudio = new short[col];
int mixVal;
int sr = 0;
for (int sc = 0; sc < col; ++sc) {
mixVal = 0;
sr = 0;
for (; sr < row; ++sr) {
mixVal += sMulRoadAudios[sr][sc];
}
sMixAudio[sc] = (short) (mixVal / row);
}
for (sr = 0; sr < col; ++sr) {
realMixAudio[sr * 2] = (byte) (sMixAudio[sr] & 0x00FF);
realMixAudio[sr * 2 + 1] = (byte) ((sMixAudio[sr] & 0xFF00) >> 8);
}
return realMixAudio;
}自适应混音
参与混音的多路音频信号自身的特点,以它们自身的比例作为权重,从而决定它们在合成后的输出中所占的比重。具体的原理可以参考这篇论文:快速实时自适应混音方案研究。这种方法对于音轨路数比较多的情况应该会比上面的平均法要好,但是可能会引入噪音。
Java 代码实现:
@Override
public byte[] mixRawAudioBytes(byte[][] bMulRoadAudios) {
//简化检查代码
/**
* 精度为 16位
*/
int col = realMixAudio.length / 2;
short[][] sMulRoadAudios = new short[row][col];
for (int r = 0; r < row; ++r) {
for (int c = 0; c < col; ++c) {
sMulRoadAudios[r][c] = (short) ((bMulRoadAudios[r][c * 2] & 0xff) | (bMulRoadAudios[r][c * 2 + 1] & 0xff) << 8);
}
}
short[] sMixAudio = new short[col];
int sr = 0;
double wValue;
double absSumVal;
for (int sc = 0; sc < col; ++sc) {
sr = 0;
wValue = 0;
absSumVal = 0;
for (; sr < row; ++sr) {
wValue += Math.pow(sMulRoadAudios[sr][sc], 2) * Math.signum(sMulRoadAudios[sr][sc]);
absSumVal += Math.abs(sMulRoadAudios[sr][sc]);
}
sMixAudio[sc] = absSumVal == 0 ? 0 : (short) (wValue / absSumVal);
}
for (sr = 0; sr < col; ++sr) {
realMixAudio[sr * 2] = (byte) (sMixAudio[sr] & 0x00FF);
realMixAudio[sr * 2 + 1] = (byte) ((sMixAudio[sr] & 0xFF00) >> 8);
}
return realMixAudio;
}多通道混音
在实际开发中,我发现上面的两种方法都不能达到满意的效果。一方面是和音乐相关,对音频质量要求比较高;另外一方面是通过手机录音,效果肯定不会太好。不知道从哪里冒出来的灵感,为什么不试着把不同的音轨数据塞到不同的通道上,让声音从不同的喇叭上同时发出,这样也可以达到混音的效果啊!而且不会有音频数据损失的问题,能很完美地呈现原来的声音。
于是我开始查了一下 Android 对多通道的支持情况,对应代码可以在android.media.AudioFormat中查看,结果如下:
public static final int CHANNEL_OUT_FRONT_LEFT = 0x4; public static final int CHANNEL_OUT_FRONT_RIGHT = 0x8; public static final int CHANNEL_OUT_FRONT_CENTER = 0x10; public static final int CHANNEL_OUT_LOW_FREQUENCY = 0x20; public static final int CHANNEL_OUT_BACK_LEFT = 0x40; public static final int CHANNEL_OUT_BACK_RIGHT = 0x80; public static final int CHANNEL_OUT_FRONT_LEFT_OF_CENTER = 0x100; public static final int CHANNEL_OUT_FRONT_RIGHT_OF_CENTER = 0x200; public static final int CHANNEL_OUT_BACK_CENTER = 0x400; public static final int CHANNEL_OUT_SIDE_LEFT = 0x800; public static final int CHANNEL_OUT_SIDE_RIGHT = 0x1000;
一共支持 10 个通道,对于我的情况来说是完全够用了。我们的耳机一般只有左右声道,那些更多通道的支持是 Android 系统内部通过软件算法模拟实现的,至于具体如何实现的,我也没有深入了解,在这里我们知道这回事就行了。我们平时所熟知的立体声,5.1 环绕等就是上面那些通道的组合。
int CHANNEL_OUT_MONO = CHANNEL_OUT_FRONT_LEFT; int CHANNEL_OUT_STEREO = (CHANNEL_OUT_FRONT_LEFT | CHANNEL_OUT_FRONT_RIGHT); int CHANNEL_OUT_5POINT1 = (CHANNEL_OUT_FRONT_LEFT | CHANNEL_OUT_FRONT_RIGHT | CHANNEL_OUT_FRONT_CENTER | CHANNEL_OUT_LOW_FREQUENCY | CHANNEL_OUT_BACK_LEFT | CHANNEL_OUT_BACK_RIGHT);
知道原理之后,实现起来非常简单,下面是具体的代码:
@Override
public byte[] mixRawAudioBytes(byte[][] bMulRoadAudios) {
int roadLen = bMulRoadAudios.length;
//单路音轨
if (roadLen == 1)
return bMulRoadAudios[0];
int maxRoadByteLen = 0;
for(byte[] audioData : bMulRoadAudios){
if(maxRoadByteLen < audioData.length){
maxRoadByteLen = audioData.length;
}
}
byte[] resultMixData = new byte[maxRoadByteLen * roadLen];
for(int i = 0; i != maxRoadByteLen; i = i + 2){
for(int r = 0; r != roadLen; r++){
resultMixData[i * roadLen + 2 * r] = bMulRoadAudios[r][i];
resultMixData[i * roadLen + 2 * r + 1] = bMulRoadAudios[r][i+1];
}
}
return resultMixData;
}结果比较
线性叠加平均法虽然看起来很简单,但是在音轨数量比较少的时候取得的效果可能会比复杂的自适应混音法要出色。
自适应混音法比较合适音轨数量比较多的情况,但是可能会引入一些噪音。
多通道混音虽然看起来很完美,但是产生的文件大小是数倍于其他的处理方法。
没有银弹,还是要根据自己的应用场景来选择,多试一下。
下面是我录的两路音轨:
音轨一:
音轨二:
线性叠加平均法:
自适应混音法:
多通道混音:
采样频率、采样精度和通道数不同的情况如何处理?
不同采样频率需要算法进行重新采样处理,让所有音轨在同一采样率下进行混音,这个比较复杂,等有机会再写篇文章介绍。
采样精度不同比较好处理,向上取精度较高的作为基准即可,高位补0;如果是需要取向下精度作为基准的,那么就要把最大通道值和基准最大值取个倍数,把数值都降到最大基准数以下,然后把低位移除。
通道数不同的情况也和精度不同的情况相似处理。
以上是“Android中怎么实现混音”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。