您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
—举例(学生排课)—
正常思路的处理方法和优化过后的处理方法:
比如说给学生排课。学生和课程是一个多对多的关系。

按照正常的逻辑 应该有一个关联表来维护 两者之间的关系。

现在,添加一个约束条件用于校验。如:张三上学期学过的课程,在排课的时候不应该再排这种课程。
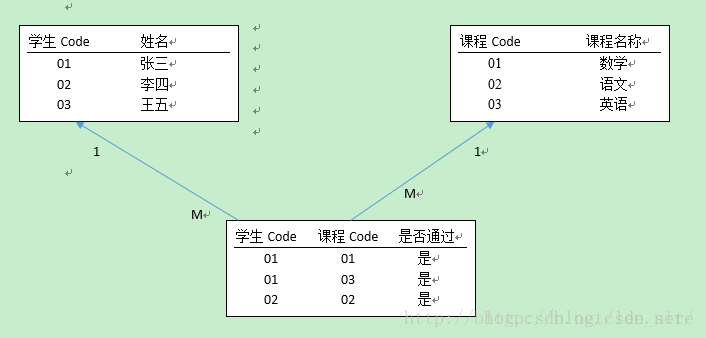
所以需要出现一个约束表(即:历史成绩表)。
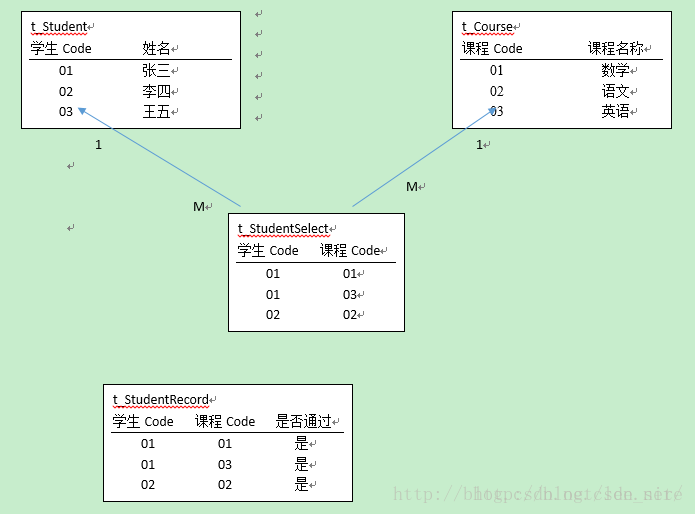
即:学生选课表,需要学生成绩表作为约束。
—方案一:正常处理方式—
当一个学生进行再次选课的时候。需要查询学生选课表看是否已经存在。
即有如下校验:
//查询 学生code和课程code分别为 A 和 B的数据是否存在
//list集合中存放 学生选课记录全部的数据
List<StudentRecordEntity> ListStudentRecord=service.findAll();
//查询数据,看是否已经存在
StudentRecordEntity enSr=ListStudentRecord.find(s=>s.学生Code==A && s.课程Code==B);
If(enSr==null){
//学生没有选该课程
//....
}else{
//学生已经选过该课程
//....
}
对于上面这种代码的写法,非常的简练。而且也非常易懂。
首先,假设有5000个学生,100门课程。那么对于学生选课的数据集中,数据量将是5000*100.数据量会是十万级别的数量级。
在十万条数据中,查询学生=A课程=B的一条记录。执行的效率会很低。因为find方法的查询也就是where查询,即通过遍历数据集合来查找。
所以,使用上面的代码。在数据量逐渐增长的过程中,程序的执行效率会大幅度下降。
ps:数据量增长,在该例子中并不太适合。例子可能不太恰当。总之,大概就是这个意思。)
—方案二:使用内存进行优化效率—
这种做法,需要消耗内存。或者说把校验的工作向前做(数据的初始化,在部署系统的过程中进行)。即:在页面加载的时候数据只调用提供的public方法进行校验。
//学生Code 到 数组索引
Private Dictionary<string,int> _DicStudentCodeToArrayIndex;
//课程Code 到 数据索引
Private Dictionary<string,int> _DicCourseCodeToArrayIndex;
//所有学生
List<StudentEntity> ListStudent=service.findAllStudent();
//所有课程
List<CourseEntity> ListCourse=service.findAllCourse();
//所有 学生选课记录
List<StudentCourseEntity> ListStudentRecord=service.finAll();
Private int[,] _ConnStudentRecord=new int[ListStudent.count,ListCourse.count];
//构造 学生、课程的 数组 用于快速查找字典索引
Private void GenerateDic(){
For(int i=0;
i<ListStudent.Count;
i++)
_DicStudentCodeToArrayIndex.Add(ListStudent[i].code,i)
}
For(int i=0;
i<ListCourse.Count;
i++){
_DicCourseCodeToArrayIndex.Add(ListCourse[i].code,i)
}
}
//构造学生选课 匹配的 二维数组。 1表示 学生已选该课程
Private void GenerateArray(){
Foreach(StudentRecordEntity sre in ListStudentRecord){
int x=_DicStudentCodeToArrayIndex[sre.学生Code];
int y=DicCourseCodeToArrayIndex[sre.课程Code];
ConnStudentRecord[x,y]=1;
}
}
//对外公开的方法:根据学生Code 和课程Code 查询 选课记录是否存在
/// <returns>返回1 表示存在。返回0表示不存在</returns>
Public void VerifyRecordByStudentCodeAndCourseCode(String pStudentCode,String pCourseCode){
int x=_DicStudentCodeToArrayIndex[pStudentCode];
int y=_DicCourseCodeToArrayIndex[pCourseCode];
Return ConnStudentRecord[x,y];
}
—性能分析—
分析一下第二种方案的表象。
1、方法很多。
2、使用的变量很多。
首先要说一下。该优化的目的,是提高学生在选课的时候,所出现的卡顿现象(校验数据量大)。
分别对以上两种方案进行分析:
假设学生为N,课程为M
第一种方案:
时间复杂度很容易计算第一种方案最小为O(NM)
第二种方案:
1、代码多。但是给用户提供的只有一个VerifyRecordByStudentCodeAndCourseCode方法。
2、变量多,因为该方案就是要使用内存提高效率的。
这个方法执行流程:1、在Dictionary中使用Code找Index2、使用Index查询数组。
第一步中,Dictionary中查询是使用的Hash查找算法。时间复杂度为O(lgN)时间比较快。第二步,时间复杂度为O(1),因为数组是连续的使用索引会直接查找对应的地址。
所以,使用第二种方案进行校验,第二种方案时间复杂度为O(lgN+lgM)
—总结—
通过上面的分析,可以看出,内存的付出是可以提高程序的执行效率的。以上只是一个例子,优化的好坏取决于使用的数据结构。
以上就是本文关于Java性能优化之数据结构实例代码的全部内容,希望对大家有所帮助。感兴趣的朋友可以继续参阅本站其他相关专题,如有不足之处,欢迎留言指出。感谢朋友们对本站的支持!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。