жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°ұи·ҹеӨ§е®¶иҒҠиҒҠжңүе…ідҪҝз”ЁJavaжҖҺд№ҲеҜ№еҫ®дҝЎе…¬дј—еҸ·жү№йҮҸиҺ·еҸ–пјҢеҸҜиғҪеҫҲеӨҡдәәйғҪдёҚеӨӘдәҶи§ЈпјҢдёәдәҶи®©еӨ§е®¶жӣҙеҠ дәҶи§ЈпјҢе°Ҹзј–з»ҷеӨ§е®¶жҖ»з»“дәҶд»ҘдёӢеҶ…е®№пјҢеёҢжңӣеӨ§е®¶ж №жҚ®иҝҷзҜҮж–Үз« еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
йҰ–е…Ҳдёәд»ЈзҗҶжңҚеҠЎеҷЁе®үиЈ…иҜҒд№ҰпјҢanyproxyй»ҳи®ӨдёҚи§Јжһҗhttpsй“ҫжҺҘпјҢе®үиЈ…иҜҒд№ҰеҗҺе°ұеҸҜд»Ҙи§ЈжһҗдәҶпјҢеңЁcmdжү§иЎҢanyproxy --root е°ұдјҡе®үиЈ…иҜҒд№ҰпјҢд№ӢеҗҺиҝҳеҫ—еңЁжЁЎжӢҹеҷЁд№ҹдёӢиҪҪиҝҷдёӘиҜҒд№ҰгҖӮ
然еҗҺиҫ“е…Ҙanyproxy -i е‘Ҫд»Ө жү“ејҖд»ЈзҗҶжңҚеҠЎгҖӮпјҲи®°еҫ—еҠ дёҠеҸӮж•°пјҒпјү

и®°дҪҸиҝҷдёӘipе’Ңз«ҜеҸЈпјҢд№ӢеҗҺе®үеҚ“жЁЎжӢҹеҷЁзҡ„д»ЈзҗҶе°ұз”ЁиҝҷдёӘгҖӮзҺ°еңЁз”ЁжөҸи§ҲеҷЁжү“ејҖзҪ‘йЎөпјҡhttp://localhost:8002/ иҝҷжҳҜanyproxyзҡ„зҪ‘йЎөз•ҢйқўпјҢз”ЁдәҺжҳҫзӨәhttpдј иҫ“ж•°жҚ®гҖӮ
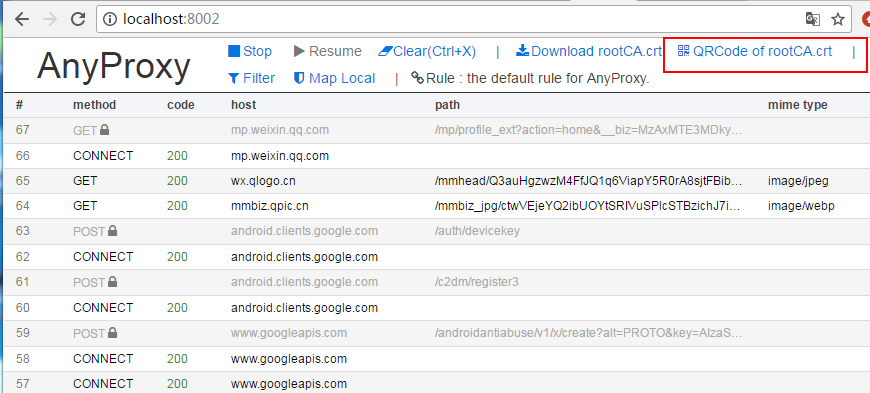
зӮ№еҮ»дёҠйқўзәўжЎҶжЎҶйҮҢйқўзҡ„иҸңеҚ•пјҢдјҡеҮәдёҖдёӘдәҢз»ҙз ҒпјҢз”Ёе®үеҚ“жЁЎжӢҹеҷЁжү«з ҒиҜҶеҲ«пјҢжЁЎжӢҹеҷЁпјҲжүӢжңәпјүе°ұдјҡдёӢиҪҪиҜҒд№ҰдәҶпјҢе®үиЈ…дёҠе°ұеҘҪдәҶгҖӮ
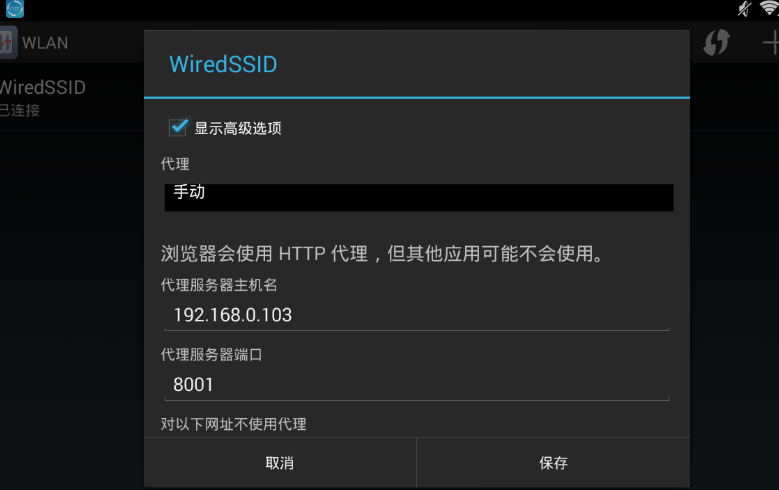
зҺ°еңЁеҮҶеӨҮдёәжЁЎжӢҹеҷЁи®ҫзҪ®д»ЈзҗҶпјҢд»ЈзҗҶж–№ејҸи®ҫзҪ®дёәжүӢеҠЁпјҢд»ЈзҗҶipдёәиҝҗиЎҢanyproxyжңәеҷЁзҡ„ipпјҢз«ҜеҸЈжҳҜ8001
еҲ°иҝҷйҮҢеҮҶеӨҮе·ҘдҪңеҹәжң¬е®ҢжҲҗпјҢеңЁжЁЎжӢҹеҷЁдёҠжү“ејҖеҫ®дҝЎйҡҸдҫҝжү“ејҖдёҖдёӘе…¬дј—еҸ·зҡ„ж–Үз« пјҢе°ұиғҪд»ҺдҪ еҲҡжү“ејҖзҡ„webз•ҢйқўдёӯзңӢеҲ°anyproxyжҠ“еҸ–еҲ°зҡ„ж•°жҚ®пјҡ
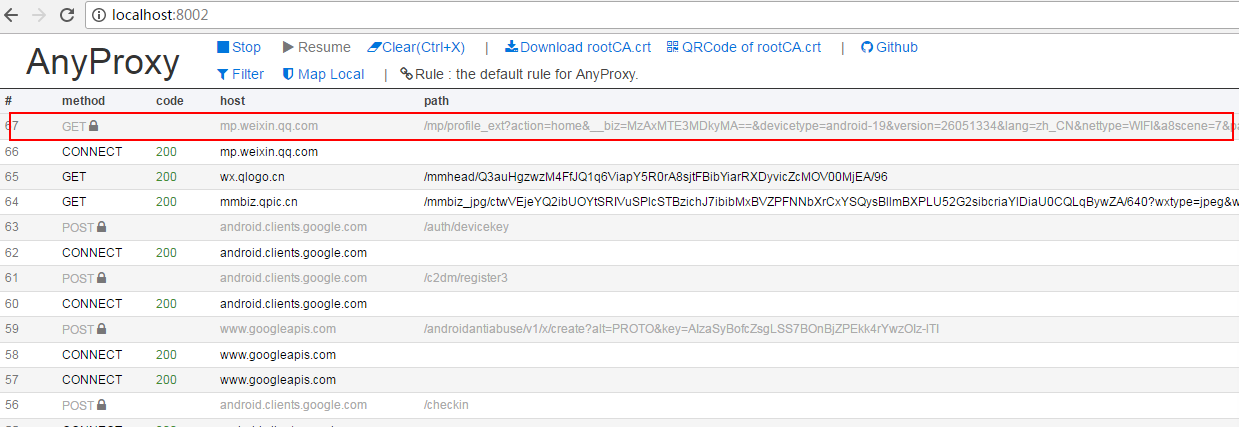
дёҠйқўзәўжЎҶеҶ…е°ұжҳҜеҫ®дҝЎж–Үз« зҡ„й“ҫжҺҘпјҢзӮ№еҮ»иҝӣеҺ»еҸҜд»ҘзңӢеҲ°е…·дҪ“зҡ„ж•°жҚ®гҖӮеҰӮжһңresponse bodyйҮҢйқўд»Җд№ҲйғҪжІЎжңүеҸҜиғҪиҜҒд№Ұе®үиЈ…жңүй—®йўҳгҖӮ
еҰӮжһңдёҠйқўйғҪиө°йҖҡдәҶпјҢе°ұеҸҜд»ҘжҺҘзқҖеҫҖдёӢиө°дәҶгҖӮ
иҝҷйҮҢжҲ‘们йқ д»ЈзҗҶжңҚеҠЎжҠ“еҫ®дҝЎж•°жҚ®пјҢдҪҶжҖ»дёҚиғҪжҠ“еҸ–дёҖжқЎж•°жҚ®е°ұиҮӘе·ұж“ҚдҪңдёҖдёӢеҫ®дҝЎпјҢйӮЈж ·иҝҳдёҚеҰӮзӣҙжҺҘдәәе·ҘеӨҚеҲ¶гҖӮжүҖд»ҘжҲ‘们йңҖиҰҒеҫ®дҝЎе®ўжҲ·з«ҜиҮӘе·ұи·іиҪ¬йЎөйқўгҖӮиҝҷж—¶е°ұеҸҜд»ҘдҪҝз”ЁanyproxyжӢҰжҲӘеҫ®дҝЎжңҚеҠЎеҷЁиҝ”еӣһзҡ„ж•°жҚ®пјҢеҫҖйҮҢйқўжіЁе…ҘйЎөйқўи·іиҪ¬д»Јз ҒпјҢеҶҚжҠҠеҠ е·Ҙзҡ„ж•°жҚ®иҝ”еӣһз»ҷжЁЎжӢҹеҷЁе®һзҺ°еҫ®дҝЎе®ўжҲ·з«ҜиҮӘеҠЁи·іиҪ¬гҖӮ
жү“ејҖanyproxyдёӯзҡ„дёҖдёӘеҸ«rule_default.jsзҡ„jsж–Ү件пјҢwindowsдёӢиҜҘж–Ү件еңЁпјҡC:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
еңЁж–Ү件йҮҢйқўжңүдёӘеҸ«replaceServerResDataAsync: function(req,res,serverResData,callback)зҡ„ж–№жі•пјҢиҝҷдёӘж–№жі•е°ұжҳҜиҙҹиҙЈеҜ№anyproxyжӢҝеҲ°зҡ„ж•°жҚ®иҝӣиЎҢеҗ„з§Қж“ҚдҪңгҖӮдёҖејҖе§Ӣеә”иҜҘеҸӘжңүcallback(serverResData)пјӣиҝҷжқЎиҜӯеҸҘзҡ„ж„ҸжҖқжҳҜзӣҙжҺҘиҝ”еӣһжңҚеҠЎеҷЁе“Қеә”ж•°жҚ®з»ҷе®ўжҲ·з«ҜгҖӮзӣҙжҺҘеҲ жҺүиҝҷжқЎиҜӯеҸҘпјҢжӣҝжҚўжҲҗеӨ§зүӣеҶҷзҡ„еҰӮдёӢд»Јз ҒгҖӮиҝҷйҮҢзҡ„д»Јз ҒжҲ‘并没жңүеҒҡд»Җд№Ҳж”№еҠЁпјҢйҮҢйқўзҡ„жіЁйҮҠд№ҹи§ЈйҮҠзҡ„з»ҷйқһеёёжё…жҘҡпјҢзӣҙжҺҘжҢүйҖ»иҫ‘зңӢжҮӮе°ұиЎҢпјҢй—®йўҳдёҚеӨ§гҖӮ
replaceServerResDataAsync: function(req,res,serverResData,callback){
if(/mp\/getmasssendmsg/i.test(req.url)){//еҪ“й“ҫжҺҘең°еқҖдёәе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜйЎөйқўж—¶(第дёҖз§ҚйЎөйқўеҪўејҸ)
//console.log("ејҖе§Ӣ第дёҖз§ҚйЎөйқўзҲ¬еҸ–");
if(serverResData.toString() !== ""){
6 try {//йҳІжӯўжҠҘй”ҷйҖҖеҮәзЁӢеәҸ
var reg = /msgList = (.*?);/;//е®ҡд№үеҺҶеҸІж¶ҲжҒҜжӯЈеҲҷеҢ№й…Қ规еҲҷ
var ret = reg.exec(serverResData.toString());//иҪ¬жҚўеҸҳйҮҸдёәstring
HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//иҝҷдёӘеҮҪж•°жҳҜеҗҺж–Үе®ҡд№үзҡ„пјҢе°ҶеҢ№й…ҚеҲ°зҡ„еҺҶеҸІж¶ҲжҒҜjsonеҸ‘йҖҒеҲ°иҮӘе·ұзҡ„жңҚеҠЎеҷЁ
var http = require('http');
http.get('http://xxx/getWxHis', function(res) {//иҝҷдёӘең°еқҖжҳҜиҮӘе·ұжңҚеҠЎеҷЁдёҠзҡ„дёҖдёӘзЁӢеәҸпјҢзӣ®зҡ„жҳҜдёәдәҶиҺ·еҸ–еҲ°дёӢдёҖдёӘй“ҫжҺҘең°еқҖпјҢе°Ҷең°еқҖж”ҫеңЁдёҖдёӘjsи„ҡжң¬дёӯпјҢе°ҶйЎөйқўиҮӘеҠЁи·іиҪ¬еҲ°дёӢдёҖйЎөгҖӮеҗҺж–Үе°Ҷд»Ӣз»ҚgetWxHis.phpзҡ„еҺҹзҗҶгҖӮ
res.on('data', function(chunk){
callback(chunk+serverResData);//е°Ҷиҝ”еӣһзҡ„д»Јз ҒжҸ’е…ҘеҲ°еҺҶеҸІж¶ҲжҒҜйЎөйқўдёӯпјҢ并иҝ”еӣһжҳҫзӨәеҮәжқҘ
})
});
}catch(e){//еҰӮжһңдёҠйқўзҡ„жӯЈеҲҷжІЎжңүеҢ№й…ҚеҲ°пјҢйӮЈд№ҲиҝҷдёӘйЎөйқўеҶ…е®№еҸҜиғҪжҳҜе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜйЎөйқўеҗ‘дёӢзҝ»еҠЁзҡ„第дәҢйЎөпјҢеӣ дёәеҺҶеҸІж¶ҲжҒҜ第дёҖйЎөжҳҜhtmlж јејҸзҡ„пјҢ第дәҢйЎөе°ұжҳҜjsonж јејҸзҡ„гҖӮ
//console.log("ејҖе§Ӣ第дёҖз§ҚйЎөйқўзҲ¬еҸ–еҗ‘дёӢзҝ»еҪўејҸ");
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//иҝҷдёӘеҮҪж•°е’ҢдёҠйқўзҡ„дёҖж ·жҳҜеҗҺж–Үе®ҡд№үзҡ„пјҢе°Ҷ第дәҢйЎөеҺҶеҸІж¶ҲжҒҜзҡ„jsonеҸ‘йҖҒеҲ°иҮӘе·ұзҡ„жңҚеҠЎеҷЁ
}
}catch(e){
console.log(e);//й”ҷиҜҜжҚ•жҚү
}
callback(serverResData);//зӣҙжҺҘиҝ”еӣһ第дәҢйЎөjsonеҶ…е®№
}
}
//console.log("ејҖе§Ӣ第дёҖз§ҚйЎөйқўзҲ¬еҸ– з»“жқҹ");
}else if(/mp\/profile_ext\?action=home/i.test(req.url)){//еҪ“й“ҫжҺҘең°еқҖдёәе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜйЎөйқўж—¶(第дәҢз§ҚйЎөйқўеҪўејҸ)
try {
var reg = /var msgList = \'(.*?)\';/;//е®ҡд№үеҺҶеҸІж¶ҲжҒҜжӯЈеҲҷеҢ№й…Қ规еҲҷпјҲе’Ң第дёҖз§ҚйЎөйқўеҪўејҸзҡ„жӯЈеҲҷдёҚеҗҢпјү
var ret = reg.exec(serverResData.toString());//иҪ¬жҚўеҸҳйҮҸдёәstring
HttpPost(ret[1],req.url,"/xxx/showBiz");//иҝҷдёӘеҮҪж•°жҳҜеҗҺж–Үе®ҡд№үзҡ„пјҢе°ҶеҢ№й…ҚеҲ°зҡ„еҺҶеҸІж¶ҲжҒҜjsonеҸ‘йҖҒеҲ°иҮӘе·ұзҡ„жңҚеҠЎеҷЁ
var http = require('http');
http.get('xxx/getWxHis', function(res) {//иҝҷдёӘең°еқҖжҳҜиҮӘе·ұжңҚеҠЎеҷЁдёҠзҡ„дёҖдёӘзЁӢеәҸпјҢзӣ®зҡ„жҳҜдёәдәҶиҺ·еҸ–еҲ°дёӢдёҖдёӘй“ҫжҺҘең°еқҖпјҢе°Ҷең°еқҖж”ҫеңЁдёҖдёӘjsи„ҡжң¬дёӯпјҢе°ҶйЎөйқўиҮӘеҠЁи·іиҪ¬еҲ°дёӢдёҖйЎөгҖӮеҗҺж–Үе°Ҷд»Ӣз»ҚgetWxHis.phpзҡ„еҺҹзҗҶгҖӮ
res.on('data', function(chunk){
callback(chunk+serverResData);//е°Ҷиҝ”еӣһзҡ„д»Јз ҒжҸ’е…ҘеҲ°еҺҶеҸІж¶ҲжҒҜйЎөйқўдёӯпјҢ并иҝ”еӣһжҳҫзӨәеҮәжқҘ
})
});
}catch(e){
//console.log(e);
callback(serverResData);
}
}else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第дәҢз§ҚйЎөйқўиЎЁзҺ°еҪўејҸзҡ„еҗ‘дёӢзҝ»йЎөеҗҺзҡ„json
try {
var json = JSON.parse(serverResData.toString());
if (json.general_msg_list != []) {
HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//иҝҷдёӘеҮҪж•°е’ҢдёҠйқўзҡ„дёҖж ·жҳҜеҗҺж–Үе®ҡд№үзҡ„пјҢе°Ҷ第дәҢйЎөеҺҶеҸІж¶ҲжҒҜзҡ„jsonеҸ‘йҖҒеҲ°иҮӘе·ұзҡ„жңҚеҠЎеҷЁ
}
}catch(e){
console.log(e);
}
callback(serverResData);
}else if(/mp\/getappmsgext/i.test(req.url)){//еҪ“й“ҫжҺҘең°еқҖдёәе…¬дј—еҸ·ж–Үз« йҳ…иҜ»йҮҸе’ҢзӮ№иөһйҮҸж—¶
try {
HttpPost(serverResData,req.url,"/xxx/getMsgExt");//еҮҪж•°жҳҜеҗҺж–Үе®ҡд№үзҡ„пјҢеҠҹиғҪжҳҜе°Ҷж–Үз« йҳ…иҜ»йҮҸзӮ№иөһйҮҸзҡ„jsonеҸ‘йҖҒеҲ°жңҚеҠЎеҷЁ
}catch(e){
}
callback(serverResData);
}else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//еҪ“й“ҫжҺҘең°еқҖдёәе…¬дј—еҸ·ж–Үз« ж—¶пјҲrumorиҝҷдёӘең°еқҖжҳҜе…¬дј—еҸ·ж–Үз« иў«иҫҹи°ЈдәҶпјү
try {
var http = require('http');
http.get('http://xxx/getWxPost', function(res) {//иҝҷдёӘең°еқҖжҳҜиҮӘе·ұжңҚеҠЎеҷЁдёҠзҡ„еҸҰдёҖдёӘзЁӢеәҸпјҢзӣ®зҡ„жҳҜдёәдәҶиҺ·еҸ–еҲ°дёӢдёҖдёӘй“ҫжҺҘең°еқҖпјҢе°Ҷең°еқҖж”ҫеңЁдёҖдёӘjsи„ҡжң¬дёӯпјҢе°ҶйЎөйқўиҮӘеҠЁи·іиҪ¬еҲ°дёӢдёҖйЎөгҖӮеҗҺж–Үе°Ҷд»Ӣз»ҚgetWxPost.phpзҡ„еҺҹзҗҶгҖӮ
res.on('data', function(chunk){
callback(chunk+serverResData);
})
});
}catch(e){
callback(serverResData);
}
}else{
callback(serverResData);
}
//callback(serverResData);
},иҝҷйҮҢз®ҖеҚ•и§ЈйҮҠдёҖдёӢпјҢеҫ®дҝЎе…¬дј—еҸ·зҡ„еҺҶеҸІж¶ҲжҒҜйЎөй“ҫжҺҘжңүдёӨз§ҚеҪўејҸпјҡдёҖз§Қд»Ҙ mp.weixin.qq.com/mp/getmasssendmsg ејҖеӨҙпјҢеҸҰдёҖз§ҚжҳҜ mp.weixin.qq.com/mp/profile_ext ејҖеӨҙгҖӮеҺҶеҸІйЎөжҳҜеҸҜд»Ҙеҗ‘дёӢзҝ»зҡ„пјҢеҰӮжһңеҗ‘дёӢзҝ»е°Ҷи§ҰеҸ‘jsдәӢ件еҸ‘йҖҒиҜ·жұӮеҫ—еҲ°jsonж•°жҚ®пјҲдёӢдёҖйЎөеҶ…е®№пјүгҖӮиҝҳжңүе…¬дј—еҸ·ж–Үз« й“ҫжҺҘпјҢд»ҘеҸҠж–Үз« зҡ„йҳ…иҜ»йҮҸе’ҢзӮ№иөһйҮҸзҡ„й“ҫжҺҘпјҲиҝ”еӣһзҡ„жҳҜjsonж•°жҚ®пјүпјҢиҝҷеҮ з§Қй“ҫжҺҘзҡ„еҪўејҸжҳҜеӣәе®ҡзҡ„еҸҜд»ҘйҖҡиҝҮйҖ»иҫ‘еҲӨж–ӯжқҘеҢәеҲҶгҖӮиҝҷйҮҢжңүдёӘй—®йўҳе°ұжҳҜеҺҶеҸІйЎөеҰӮжһңйңҖиҰҒе…ЁйғЁзҲ¬еҸ–еҲ°иҜҘжҖҺд№ҲеҒҡеҲ°гҖӮжҲ‘зҡ„жҖқи·ҜжҳҜйҖҡиҝҮjsеҺ»жЁЎжӢҹйј ж Үеҗ‘дёӢж»‘еҠЁпјҢд»ҺиҖҢи§ҰеҸ‘жҸҗдәӨеҠ иҪҪдёӢдёҖйғЁеҲҶеҲ—иЎЁзҡ„иҜ·жұӮгҖӮжҲ–иҖ…зӣҙжҺҘеҲ©з”ЁanyproxyеҲҶжһҗдёӢж»‘еҠ иҪҪзҡ„иҜ·жұӮпјҢзӣҙжҺҘеҗ‘еҫ®дҝЎжңҚеҠЎеҷЁеҸ‘з”ҹиҝҷдёӘиҜ·жұӮгҖӮдҪҶйғҪжңүдёҖдёӘй—®йўҳе°ұжҳҜеҰӮдҪ•еҲӨж–ӯе·Із»ҸжІЎжңүдҪҷдёӢж•°жҚ®дәҶгҖӮжҲ‘жҳҜзҲ¬еҸ–жңҖж–°ж•°жҚ®пјҢжҡӮж—¶жІЎиҝҷдёӘйңҖжұӮпјҢеҸҜиғҪд»ҘеҗҺиҰҒгҖӮеҰӮжһңжңүйңҖжұӮзҡ„еҸҜд»Ҙе°қиҜ•дёҖдёӢгҖӮ
дёӢеӣҫжҳҜдёҠж–Үдёӯзҡ„HttpPostж–№жі•еҶ…е®№гҖӮ
function HttpPost(str,url,path) {//е°ҶjsonеҸ‘йҖҒеҲ°жңҚеҠЎеҷЁпјҢstrдёәjsonеҶ…е®№пјҢurlдёәеҺҶеҸІж¶ҲжҒҜйЎөйқўең°еқҖпјҢpathжҳҜжҺҘ收зЁӢеәҸзҡ„и·Ҝеҫ„е’Ңж–Ү件еҗҚ
console.log("ејҖе§Ӣжү§иЎҢиҪ¬еҸ‘ж“ҚдҪң");
try{
var http = require('http');
var data = {
str: encodeURIComponent(str),
url: encodeURIComponent(url)
};
data = require('querystring').stringify(data);
var options = {
method: "POST",
host: "xxx",//жіЁж„ҸжІЎжңүhttp://пјҢиҝҷжҳҜжңҚеҠЎеҷЁзҡ„еҹҹеҗҚгҖӮ
port: xxx,
path: path,//жҺҘ收зЁӢеәҸзҡ„и·Ҝеҫ„е’Ңж–Ү件еҗҚ
headers: {
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
"Content-Length": data.length
}
};
var req = http.request(options, function (res) {
res.setEncoding('utf8');
res.on('data', function (chunk) {
console.log('BODY: ' + chunk);
});
});
req.on('error', function (e) {
console.log('problem with request: ' + e.message);
});
req.write(data);
req.end();
}catch(e){
console.log("й”ҷиҜҜдҝЎжҒҜпјҡ"+e);
}
console.log("иҪ¬еҸ‘ж“ҚдҪңз»“жқҹ");
}еҒҡе®Ңд»ҘдёҠе·ҘдҪңпјҢжҺҘдёӢжқҘе°ұжҳҜжҢүиҮӘе·ұдёҡеҠЎжқҘе®ҢжҲҗжңҚеҠЎз«Ҝд»Јз ҒдәҶпјҢжҲ‘们зҡ„жңҚеҠЎз”ЁдәҺжҺҘ收代зҗҶжңҚеҠЎеҷЁеҸ‘иҝҮжқҘзҡ„ж•°жҚ®иҝӣиЎҢеӨ„зҗҶпјҢиҝӣиЎҢжҢҒд№…еҢ–ж“ҚдҪңпјҢеҗҢж—¶еҗ‘д»ЈзҗҶжңҚеҠЎеҷЁеҸ‘йҖҒйңҖиҰҒжіЁе…ҘеҲ°еҫ®дҝЎзҡ„jsд»Јз ҒгҖӮй’ҲеҜ№д»ЈзҗҶжңҚеҠЎеҷЁжӢҰжҲӘеҲ°зҡ„еҮ з§ҚдёҚеҗҢй“ҫжҺҘеҸ‘жқҘзҡ„ж•°жҚ®пјҢжҲ‘们е°ұйңҖиҰҒи®ҫи®Ўзӣёеә”зҡ„ж–№жі•жқҘеӨ„зҗҶиҝҷдәӣж•°жҚ®гҖӮд»ҺanyproxyеӨ„зҗҶеҫ®дҝЎж•°жҚ®зҡ„jsж–№жі•replaceServerResDataAsync: function(req,res,serverResData,callback)дёӯпјҢжҲ‘们еҸҜд»ҘзҹҘйҒ“иҮіе°‘йңҖиҰҒеҜ№е…¬дј—еҸ·еҺҶеҸІйЎөж•°жҚ®гҖҒе…¬дј—еҸ·ж–Үз« йЎөж•°жҚ®гҖҒе…¬дј—еҸ·ж–Үз« зӮ№иөһйҮҸе’Ңйҳ…иҜ»йҮҸж•°жҚ®и®ҫи®Ўдёүз§Қж–№жі•жқҘеӨ„зҗҶгҖӮеҗҢж—¶жҲ‘们иҝҳйңҖиҰҒи®ҫи®ЎдёҖдёӘж–№жі•жқҘз”ҹжҲҗзҲ¬еҸ–д»»еҠЎпјҢе®ҢжҲҗе…¬дј—еҸ·зҡ„иҪ®еҜ»зҲ¬еҸ–гҖӮеҰӮжһңйңҖиҰҒзҲ¬еҸ–жӣҙеӨҡж•°жҚ®пјҢеҸҜд»Ҙд»ҺanyproxyжҠ“еҸ–еҲ°зҡ„й“ҫжҺҘдёӯеҲҶжһҗеҮәжӣҙеӨҡйңҖиҰҒзҡ„ж•°жҚ®пјҢ然еҗҺеҫҖreplaceServerResDataAsync: function(req,res,serverResData,callback)дёӯж·»еҠ еҲӨе®ҡпјҢжӢҰжҲӘеҲ°йңҖиҰҒзҡ„ж•°жҚ®еҸ‘йҖҒеҲ°иҮӘе·ұзҡ„жңҚеҠЎеҷЁпјҢзӣёеә”зҡ„еңЁжңҚеҠЎз«Ҝж·»еҠ ж–№жі•еӨ„зҗҶиҜҘзұ»ж•°жҚ®е°ұиЎҢдәҶгҖӮ
жҲ‘жҳҜз”ЁjavaеҶҷзҡ„жңҚеҠЎз«Ҝд»Јз ҒгҖӮ
еӨ„зҗҶе…¬дј—еҸ·еҺҶеҸІйЎөж•°жҚ®ж–№жі•пјҡ
public void getMsgJson(String str ,String url) throws UnsupportedEncodingException {
// TODO Auto-generated method stub
String biz = "";
Map<String,String> queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
}
/**
* д»Һж•°жҚ®еә“дёӯжҹҘиҜўbizжҳҜеҗҰе·Із»ҸеӯҳеңЁпјҢеҰӮжһңдёҚеӯҳеңЁеҲҷжҸ’е…ҘпјҢ
* иҝҷд»ЈиЎЁзқҖжҲ‘们新添еҠ дәҶдёҖдёӘйҮҮйӣҶзӣ®ж Үе…¬дј—еҸ·гҖӮ
*/
List<WeiXin> results = weiXinMapper.selectByBiz(biz);
if(results == null || results.size() == 0){
WeiXin weiXin = new WeiXin();
weiXin.setBiz(biz);
weiXin.setCollect(System.currentTimeMillis());
weiXinMapper.insert(weiXin);
}
//System.out.println(str);
//и§ЈжһҗstrеҸҳйҮҸ
List<Object> lists = JsonPath.read(str, "['list']");
for(Object list : lists){
Object json = list;
int type = JsonPath.read(json, "['comm_msg_info']['type']");
if(type == 49){//type=49иЎЁзӨәжҳҜеӣҫж–Үж¶ҲжҒҜ
String content_url = JsonPath.read(json, "$.app_msg_ext_info.content_url");
content_url = content_url.replace("\\", "").replaceAll("amp;", "");//иҺ·еҫ—еӣҫж–Үж¶ҲжҒҜзҡ„й“ҫжҺҘең°еқҖ
int is_multi = JsonPath.read(json, "$.app_msg_ext_info.is_multi");//жҳҜеҗҰжҳҜеӨҡеӣҫж–Үж¶ҲжҒҜ
Integer datetime = JsonPath.read(json, "$.comm_msg_info.datetime");//еӣҫж–Үж¶ҲжҒҜеҸ‘йҖҒж—¶й—ҙ
/**
* еңЁиҝҷйҮҢе°Ҷеӣҫж–Үж¶ҲжҒҜй“ҫжҺҘең°еқҖжҸ’е…ҘеҲ°йҮҮйӣҶйҳҹеҲ—еә“tmplistдёӯ
* пјҲйҳҹеҲ—еә“е°ҶеңЁеҗҺж–Үд»Ӣз»ҚпјҢдё»иҰҒзӣ®зҡ„жҳҜе»әз«ӢдёҖдёӘжү№йҮҸйҮҮйӣҶйҳҹеҲ—пјҢ
* еҸҰдёҖдёӘзЁӢеәҸе°Ҷж №жҚ®йҳҹеҲ—е®үжҺ’дёӢдёҖдёӘйҮҮйӣҶзҡ„е…¬дј—еҸ·жҲ–иҖ…ж–Үз« еҶ…е®№пјү
*/
try{
if(content_url != null && !"".equals(content_url)){
TmpList tmpList = new TmpList();
tmpList.setContentUrl(content_url);
tmpListMapper.insertSelective(tmpList);
}
}catch(Exception e){
System.out.println("йҳҹеҲ—е·ІеӯҳеңЁ,дёҚжҸ’е…ҘпјҒ");
}
/**
* еңЁиҝҷйҮҢж №жҚ®$content_urlд»Һж•°жҚ®еә“postдёӯеҲӨж–ӯдёҖдёӢжҳҜеҗҰйҮҚеӨҚ
*/
List<Post> postList = postMapper.selectByContentUrl(content_url);
boolean contentUrlExist = false;
if(postList != null && postList.size() != 0){
contentUrlExist = true;
}
if(!contentUrlExist){//'ж•°жҚ®еә“postдёӯдёҚеӯҳеңЁзӣёеҗҢзҡ„$content_url'
Integer fileid = JsonPath.read(json, "$.app_msg_ext_info.fileid");//дёҖдёӘеҫ®дҝЎз»ҷзҡ„id
String title = JsonPath.read(json, "$.app_msg_ext_info.title");//ж–Үз« ж Үйўҳ
String title_encode = URLEncoder.encode(title, "utf-8");
String digest = JsonPath.read(json, "$.app_msg_ext_info.digest");//ж–Үз« ж‘ҳиҰҒ
String source_url = JsonPath.read(json, "$.app_msg_ext_info.source_url");//йҳ…иҜ»еҺҹж–Үзҡ„й“ҫжҺҘ
source_url = source_url.replace("\\", "");
String cover = JsonPath.read(json, "$.app_msg_ext_info.cover");//е°ҒйқўеӣҫзүҮ
cover = cover.replace("\\", "");
/**
* еӯҳе…Ҙж•°жҚ®еә“
*/
// System.out.println("еӨҙжқЎж Үйўҳпјҡ"+title);
// System.out.println("еҫ®дҝЎIDпјҡ"+fileid);
// System.out.println("ж–Үз« ж‘ҳиҰҒ:"+digest);
// System.out.println("йҳ…иҜ»еҺҹж–Үй“ҫжҺҘ:"+source_url);
// System.out.println("е°ҒйқўеӣҫзүҮең°еқҖ:"+cover);
Post post = new Post();
post.setBiz(biz);
post.setTitle(title);
post.setTitleEncode(title_encode);
post.setFieldId(fileid);
post.setDigest(digest);
post.setSourceUrl(source_url);
post.setCover(cover);
post.setIsTop(1);//ж Үи®°дёҖдёӢжҳҜеӨҙжқЎеҶ…е®№
post.setIsMulti(is_multi);
post.setDatetime(datetime);
post.setContentUrl(content_url);
postMapper.insert(post);
}
if(is_multi == 1){//еҰӮжһңжҳҜеӨҡеӣҫж–Үж¶ҲжҒҜ
List<Object> multiLists = JsonPath.read(json, "['app_msg_ext_info']['multi_app_msg_item_list']");
for(Object multiList : multiLists){
Object multiJson = multiList;
content_url = JsonPath.read(multiJson, "['content_url']").toString().replace("\\", "").replaceAll("amp;", "");//еӣҫж–Үж¶ҲжҒҜй“ҫжҺҘең°еқҖ
/**
* иҝҷйҮҢеҶҚж¬Ўж №жҚ®$content_urlеҲӨж–ӯдёҖдёӢж•°жҚ®еә“дёӯжҳҜеҗҰйҮҚеӨҚд»Ҙе…ҚеҮәй”ҷ
*/
contentUrlExist = false;
List<Post> posts = postMapper.selectByContentUrl(content_url);
if(posts != null && posts.size() != 0){
contentUrlExist = true;
}
if(!contentUrlExist){//'ж•°жҚ®еә“дёӯдёҚеӯҳеңЁзӣёеҗҢзҡ„$content_url'
/**
* еңЁиҝҷйҮҢе°Ҷеӣҫж–Үж¶ҲжҒҜй“ҫжҺҘең°еқҖжҸ’е…ҘеҲ°йҮҮйӣҶйҳҹеҲ—еә“дёӯ
* пјҲйҳҹеҲ—еә“е°ҶеңЁеҗҺж–Үд»Ӣз»ҚпјҢдё»иҰҒзӣ®зҡ„жҳҜе»әз«ӢдёҖдёӘжү№йҮҸйҮҮйӣҶйҳҹеҲ—пјҢ
* еҸҰдёҖдёӘзЁӢеәҸе°Ҷж №жҚ®йҳҹеҲ—е®үжҺ’дёӢдёҖдёӘйҮҮйӣҶзҡ„е…¬дј—еҸ·жҲ–иҖ…ж–Үз« еҶ…е®№пјү
*/
if(content_url != null && !"".equals(content_url)){
TmpList tmpListT = new TmpList();
tmpListT.setContentUrl(content_url);
tmpListMapper.insertSelective(tmpListT);
}
String title = JsonPath.read(multiJson, "$.title");
String title_encode = URLEncoder.encode(title, "utf-8");
Integer fileid = JsonPath.read(multiJson, "$.fileid");
String digest = JsonPath.read(multiJson, "$.digest");
String source_url = JsonPath.read(multiJson, "$.source_url");
source_url = source_url.replace("\\", "");
String cover = JsonPath.read(multiJson, "$.cover");
cover = cover.replace("\\", "");
// System.out.println("ж Үйўҳ:"+title);
// System.out.println("еҫ®дҝЎID:"+fileid);
// System.out.println("ж–Үз« ж‘ҳиҰҒ:"+digest);
// System.out.println("йҳ…иҜ»еҺҹж–Үй“ҫжҺҘ:"+source_url);
// System.out.println("е°ҒйқўеӣҫзүҮең°еқҖ:"+cover);
Post post = new Post();
post.setBiz(biz);
post.setTitle(title);
post.setTitleEncode(title_encode);
post.setFieldId(fileid);
post.setDigest(digest);
post.setSourceUrl(source_url);
post.setCover(cover);
post.setIsTop(0);//ж Үи®°дёҖдёӢдёҚжҳҜеӨҙжқЎеҶ…е®№
post.setIsMulti(is_multi);
post.setDatetime(datetime);
post.setContentUrl(content_url);
postMapper.insert(post);
}
}
}
}
}
}еӨ„зҗҶе…¬дј—еҸ·ж–Үз« йЎөзҡ„ж–№жі•пјҡ
public String getWxPost() {
// TODO Auto-generated method stub
/**
* еҪ“еүҚйЎөйқўдёәе…¬дј—еҸ·ж–Үз« йЎөйқўж—¶пјҢиҜ»еҸ–иҝҷдёӘзЁӢеәҸ
* йҰ–е…ҲеҲ йҷӨйҮҮйӣҶйҳҹеҲ—иЎЁдёӯload=1зҡ„иЎҢ
* 然еҗҺд»ҺйҳҹеҲ—иЎЁдёӯжҢүз…§вҖңorder by id ascвҖқйҖүжӢ©еӨҡиЎҢ(жіЁж„ҸиҝҷдёҖиЎҢе’ҢдёҠйқўзҡ„зЁӢеәҸдёҚдёҖж ·)
*/
tmpListMapper.deleteByLoad(1);
List<TmpList> queues = tmpListMapper.selectMany(5);
String url = "";
if(queues != null && queues.size() != 0 && queues.size() > 1){
TmpList queue = queues.get(0);
url = queue.getContentUrl();
queue.setIsload(1);
int result = tmpListMapper.updateByPrimaryKey(queue);
System.out.println("update result:"+result);
}else{
System.out.println("getpost queues is null?"+queues==null?null:queues.size());
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
if((Math.random()>0.5?1:0) == 1){
url = "http://mp.weixin.qq.com/mp/getmasssendmsg?__biz=" + biz +
"#wechat_webview_type=1&wechat_redirect";//жӢјжҺҘе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜurlең°еқҖпјҲ第дёҖз§ҚйЎөйқўеҪўејҸпјү
}else{
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//жӢјжҺҘе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜurlең°еқҖпјҲ第дәҢз§ҚйЎөйқўеҪўејҸпјү
}
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//жӢјжҺҘе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜurlең°еқҖпјҲ第дәҢз§ҚйЎөйқўеҪўејҸпјү
//жӣҙж–°еҲҡжүҚжҸҗеҲ°зҡ„е…¬дј—еҸ·иЎЁдёӯзҡ„йҮҮйӣҶж—¶й—ҙtimeеӯ—ж®өдёәеҪ“еүҚж—¶й—ҙжҲігҖӮ
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getPost weiXin updateResult:"+result);
}
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "<script>setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");</script>";
return jsCode;
}еӨ„зҗҶе…¬дј—еҸ·зӮ№иөһйҮҸе’Ңйҳ…иҜ»йҮҸзҡ„ж–№жі•пјҡ
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map<String,String> queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `ж–Үз« иЎЁ` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* ж №жҚ®bizе’ҢsnжүҫеҲ°еҜ№еә”зҡ„ж–Үз«
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("jsonж•°жҚ®:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//йҳ…иҜ»йҮҸ
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//зӮ№иөһйҮҸ
}catch(Exception e){
read_num = 123;//йҳ…иҜ»йҮҸ
like_num = 321;//зӮ№иөһйҮҸ
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* еңЁиҝҷйҮҢеҗҢж ·ж №жҚ®snеңЁйҮҮйӣҶйҳҹеҲ—иЎЁдёӯеҲ йҷӨеҜ№еә”зҡ„ж–Үз« пјҢд»ЈиЎЁиҝҷзҜҮж–Үз« еҸҜд»Ҙ移еҮәйҮҮйӣҶйҳҹеҲ—дәҶ
* $sql = "delete from `йҳҹеҲ—иЎЁ` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然еҗҺе°Ҷйҳ…иҜ»йҮҸе’ҢзӮ№иөһйҮҸжӣҙж–°еҲ°ж–Үз« иЎЁдёӯгҖӮ
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}еӨ„зҗҶи·іиҪ¬еҗ‘еҫ®дҝЎжіЁе…Ҙjsзҡ„ж–№жі•пјҡ
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* еҪ“еүҚйЎөйқўдёәе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜж—¶пјҢиҜ»еҸ–иҝҷдёӘзЁӢеәҸ
* еңЁйҮҮйӣҶйҳҹеҲ—иЎЁдёӯжңүдёҖдёӘloadеӯ—ж®өпјҢеҪ“еҖјзӯүдәҺ1ж—¶д»ЈиЎЁжӯЈеңЁиў«иҜ»еҸ–
* йҰ–е…ҲеҲ йҷӨйҮҮйӣҶйҳҹеҲ—иЎЁдёӯload=1зҡ„иЎҢ
* 然еҗҺд»ҺйҳҹеҲ—иЎЁдёӯд»»ж„ҸselectдёҖиЎҢ
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//йҳҹеҲ—иЎЁдёәз©ә
/**
* йҳҹеҲ—иЎЁеҰӮжһңз©әдәҶпјҢе°ұд»ҺеӯҳеӮЁе…¬дј—еҸ·bizзҡ„иЎЁдёӯеҸ–еҫ—дёҖдёӘbizпјҢ
* иҝҷйҮҢжҲ‘еңЁе…¬дј—еҸ·иЎЁдёӯи®ҫзҪ®дәҶдёҖдёӘйҮҮйӣҶж—¶й—ҙзҡ„timeеӯ—ж®өпјҢжҢүз…§жӯЈеәҸжҺ’еҲ—д№ӢеҗҺпјҢ
* е°ұеҫ—еҲ°ж—¶й—ҙжҲіжңҖе°Ҹзҡ„дёҖдёӘе…¬дј—еҸ·и®°еҪ•пјҢ并еҸ–еҫ—е®ғзҡ„biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/profile_ext?action=home&__biz=" + biz +
"#wechat_redirect";//жӢјжҺҘе…¬дј—еҸ·еҺҶеҸІж¶ҲжҒҜurlең°еқҖпјҲ第дәҢз§ҚйЎөйқўеҪўејҸпјү
//жӣҙж–°еҲҡжүҚжҸҗеҲ°зҡ„е…¬дј—еҸ·иЎЁдёӯзҡ„йҮҮйӣҶж—¶й—ҙtimeеӯ—ж®өдёәеҪ“еүҚж—¶й—ҙжҲігҖӮ
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//еҸ–еҫ—еҪ“еүҚиҝҷдёҖиЎҢзҡ„content_urlеӯ—ж®ө
url = queue.getContentUrl();
//е°Ҷloadеӯ—ж®өupdateдёә1
tmpListMapper.updateByContentUrl(url);
}
//е°ҶдёӢдёҖдёӘе°ҶиҰҒи·іиҪ¬зҡ„$urlеҸҳжҲҗjsи„ҡжң¬пјҢз”ұanyproxyжіЁе…ҘеҲ°еҫ®дҝЎйЎөйқўдёӯгҖӮ
//echo "<script>setTimeout(function(){window.location.href='".$url."';},2000);</script>";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "<script>setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");</script>";
return jsCode;
}д»ҘдёҠе°ұжҳҜеҜ№еӨ„зҗҶд»ЈзҗҶжңҚеҠЎеҷЁжӢҰжҲӘеҲ°зҡ„ж•°жҚ®иҝӣиЎҢеӨ„зҗҶзҡ„зЁӢеәҸгҖӮиҝҷйҮҢжңүдёҖдёӘйңҖиҰҒжіЁж„Ҹзҡ„й—®йўҳпјҢзЁӢеәҸдјҡеҜ№ж•°жҚ®еә“дёӯзҡ„жҜҸдёӘ收еҪ•зҡ„е…¬дј—еҸ·иҝӣиЎҢиҪ®еҫӘи®ҝй—®пјҢз”ҡиҮіжҳҜе·Із»ҸеӯҳеӮЁзҡ„ж–Үз« д№ҹдјҡеҶҚж¬Ўи®ҝй—®пјҢзӣ®зҡ„жҳҜдёәдәҶдёҖзӣҙжӣҙж–°ж–Үз« зҡ„йҳ…иҜ»ж•°е’ҢзӮ№иөһж•°гҖӮеҰӮжһңйңҖиҰҒжҠ“еҸ–еӨ§йҮҸзҡ„е…¬дј—еҸ·е»әи®®еҜ№ж·»еҠ д»»еҠЎйҳҹеҲ—зҡ„д»Јз ҒиҝӣиЎҢдҝ®ж”№пјҢж·»еҠ жқЎд»¶йҷҗеҲ¶пјҢеҗҰеҲҷе…¬дј—еҸ·дёҖеӨҡ иҪ®еҫӘжҠ“еҸ–йҮҚеӨҚж•°жҚ®е°ҶеҚҒеҲҶеҪұе“Қж•ҲзҺҮгҖӮ
иҮіжӯӨе°ұе°Ҷеҫ®дҝЎе…¬дј—еҸ·зҡ„ж–Үз« й“ҫжҺҘе…ЁйғЁзҲ¬еҸ–еҲ°пјҢиҖҢдё”иҝҷдёӘй“ҫжҺҘжҳҜж°ёд№…жңүж•ҲиҖҢдё”еҸҜд»ҘеңЁжөҸи§ҲеҷЁжү“ејҖзҡ„й“ҫжҺҘпјҢжҺҘдёӢжқҘе°ұжҳҜеҶҷзҲ¬иҷ«зЁӢеәҸд»Һж•°жҚ®еә“дёӯжӢҝй“ҫжҺҘзҲ¬еҸ–ж–Үз« еҶ…е®№зӯүдҝЎжҒҜдәҶгҖӮ
жҲ‘жҳҜз”ЁwebmagicеҶҷзҡ„зҲ¬иҷ«пјҢиҪ»йҮҸеҘҪз”ЁгҖӮ
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List<Post> posts;
// жҠ“еҸ–зҪ‘з«ҷзҡ„зӣёе…ій…ҚзҪ®пјҢеҢ…жӢ¬зј–з ҒгҖҒжҠ“еҸ–й—ҙйҡ”гҖҒйҮҚиҜ•ж¬Ўж•°зӯү
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//еӯҳеңЁе’Ңи°җж–Үз« жӯӨеӨ„еҒҡеҲӨе®ҡеҰӮжһңжңүзӣҙжҺҘеҲ йҷӨи®°еҪ•жҲ–и®ҫзҪ®иЎЁзӨәдҪҚиЎЁзӨәж–Үз« иў«е’Ңи°җ
if(content == null){
System.out.println("ж–Үз« е·Іе’Ңи°җпјҒ");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//еҝ«з…§
String contentTxt = HtmlToWord.stripHtml(content);//зәҜж–Үжң¬еҶ…е®№
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//ж–Үз« еҸ‘еёғж—¶й—ҙ
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//е…¬дј—еҸ·еҗҚз§°
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//ж–Үз« дҪңиҖ…
}
}
// System.out.println("еҸ‘еёғж—¶й—ҙ:"+pubTime);
// System.out.println("е…¬дј—еҸ·еҗҚз§°:"+wxname);
// System.out.println("ж–Үз« дҪңиҖ…:"+author);
String title = post.getTitle().replaceAll(" ", "");//ж–Үз« ж Үйўҳ
String digest = post.getDigest();//ж–Үз« ж‘ҳиҰҒ
int likeNum = post.getLikenum();//ж–Үз« зӮ№иөһж•°
int readNum = post.getReadnum();//ж–Үз« йҳ…иҜ»ж•°
String contentUrl = post.getContentUrl();//ж–Үз« й“ҫжҺҘ
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//зәҜж–Үжң¬еҶ…е®№
wechatBean.setSourceCode(contentSnap);//еҝ«з…§
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//ж‘ҳиҰҒ
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//з«ҷзӮ№еҗҚз§° е…¬дј—еҸ·еҗҚз§°
wechatBean.setAuthor(author);
wechatBean.setMediaType("еҫ®дҝЎе…¬дј—еҸ·");//жқҘжәҗеӘ’дҪ“зұ»еһӢ
WechatStorage.saveWechatInfo(wechatBean);
//ж ҮзӨәж–Үз« е·Із»Ҹиў«зҲ¬еҸ–
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List<Post> inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("зҲ¬еҸ–ж—¶й—ҙ" + ((endTime - startTime) / 1000) + "з§’--");
}
}е…¶е®ғзҡ„дёҖдәӣж— е…ійҖ»иҫ‘зҡ„еӯҳеӮЁж•°жҚ®д»Јз Ғе°ұдёҚиҙҙдәҶпјҢиҝҷйҮҢжҲ‘жҠҠд»ЈзҗҶжңҚеҠЎеҷЁжҠ“еҸ–еҲ°зҡ„ж•°жҚ®еӯҳеңЁдәҶmysqlпјҢжҠҠиҮӘе·ұзҡ„зҲ¬иҷ«зЁӢеәҸзҲ¬еҲ°зҡ„ж•°жҚ®еӯҳеӮЁеңЁдәҶmongodbгҖӮ
дёӢйқўжҳҜиҮӘе·ұзҲ¬еҸ–еҲ°зҡ„е…¬дј—еҸ·еҸ·зҡ„дҝЎжҒҜпјҡ
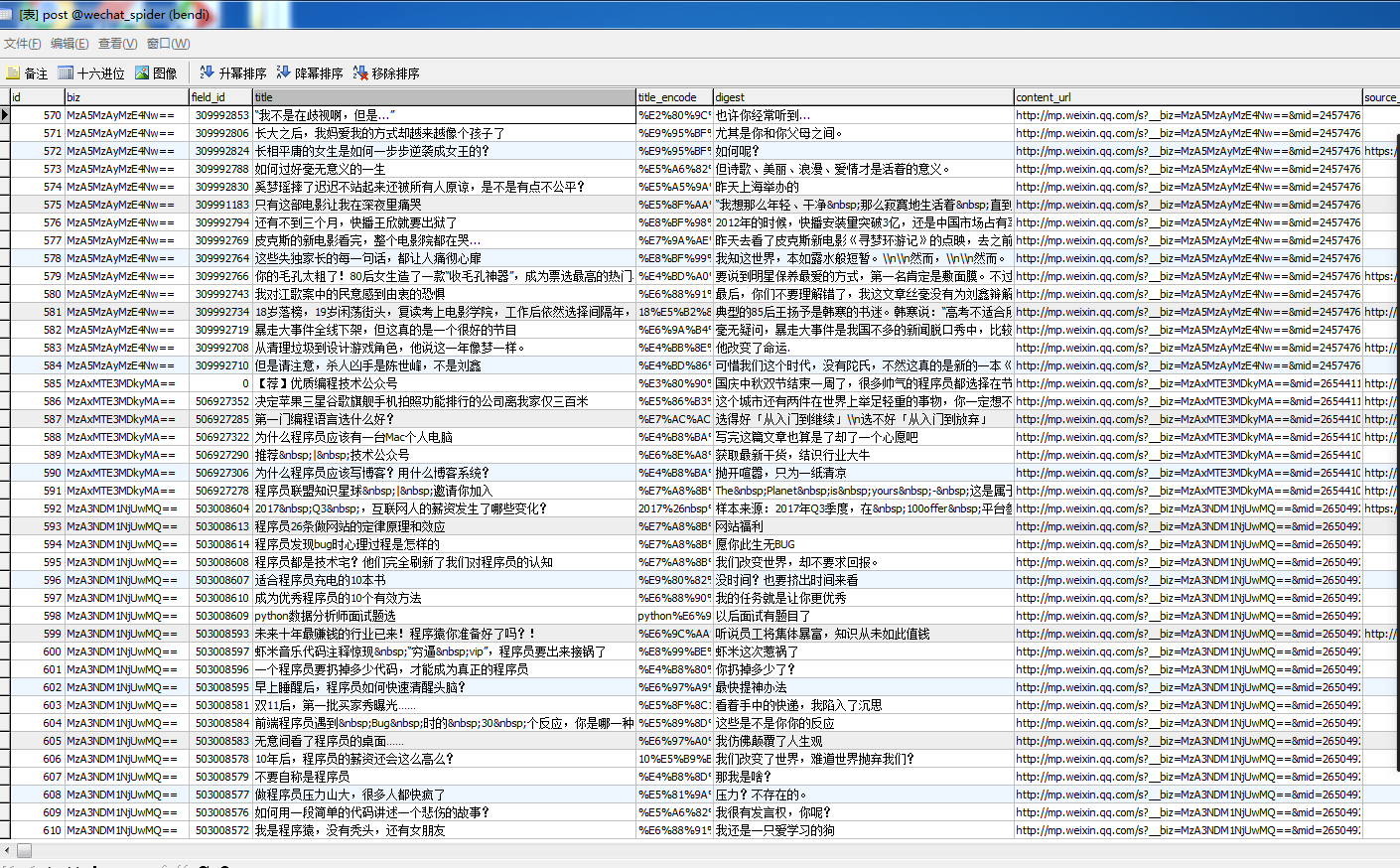
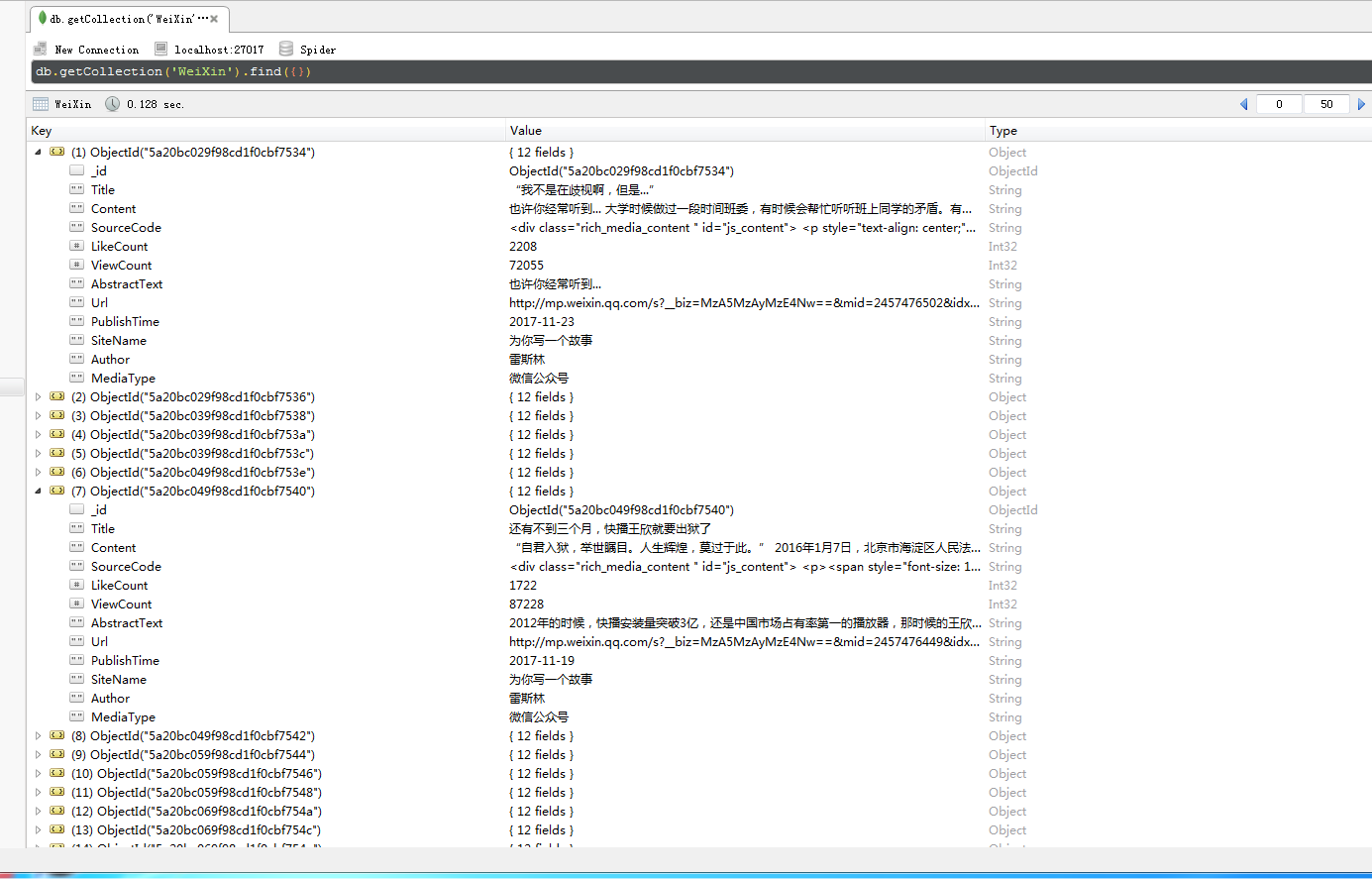
зңӢе®ҢдёҠиҝ°еҶ…е®№пјҢдҪ 们еҜ№дҪҝз”ЁJavaжҖҺд№ҲеҜ№еҫ®дҝЎе…¬дј—еҸ·жү№йҮҸиҺ·еҸ–жңүиҝӣдёҖжӯҘзҡ„дәҶи§Јеҗ—пјҹеҰӮжһңиҝҳжғідәҶи§ЈжӣҙеӨҡзҹҘиҜҶжҲ–иҖ…зӣёе…іеҶ…е®№пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеӨ§е®¶зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ