жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
ConcurrentSkipListMapд»Ӣз»Қ
ConcurrentSkipListMapжҳҜзәҝзЁӢе®үе…Ёзҡ„жңүеәҸзҡ„е“ҲеёҢиЎЁпјҢйҖӮз”ЁдәҺй«ҳ并еҸ‘зҡ„еңәжҷҜгҖӮ
ConcurrentSkipListMapе’ҢTreeMapпјҢе®ғ们иҷҪ然йғҪжҳҜжңүеәҸзҡ„е“ҲеёҢиЎЁгҖӮдҪҶжҳҜпјҢ第дёҖпјҢе®ғ们зҡ„зәҝзЁӢе®үе…ЁжңәеҲ¶дёҚеҗҢпјҢTreeMapжҳҜйқһзәҝзЁӢе®үе…Ёзҡ„пјҢиҖҢConcurrentSkipListMapжҳҜзәҝзЁӢе®үе…Ёзҡ„гҖӮ第дәҢпјҢConcurrentSkipListMapжҳҜйҖҡиҝҮи·іиЎЁе®һзҺ°зҡ„пјҢиҖҢTreeMapжҳҜйҖҡиҝҮзәўй»‘ж ‘е®һзҺ°зҡ„гҖӮ
е…ідәҺи·іиЎЁ(Skip List)пјҢе®ғжҳҜе№іиЎЎж ‘зҡ„дёҖз§Қжӣҝд»Јзҡ„ж•°жҚ®з»“жһ„пјҢдҪҶжҳҜе’Ңзәўй»‘ж ‘дёҚзӣёеҗҢзҡ„жҳҜпјҢи·іиЎЁеҜ№дәҺж ‘зҡ„е№іиЎЎзҡ„е®һзҺ°жҳҜеҹәдәҺдёҖз§ҚйҡҸжңәеҢ–зҡ„з®—жі•зҡ„пјҢиҝҷж ·д№ҹе°ұжҳҜиҜҙи·іиЎЁзҡ„жҸ’е…Ҙе’ҢеҲ йҷӨзҡ„е·ҘдҪңжҳҜжҜ”иҫғз®ҖеҚ•зҡ„гҖӮ
ConcurrentSkipListMapеҺҹзҗҶе’Ңж•°жҚ®з»“жһ„
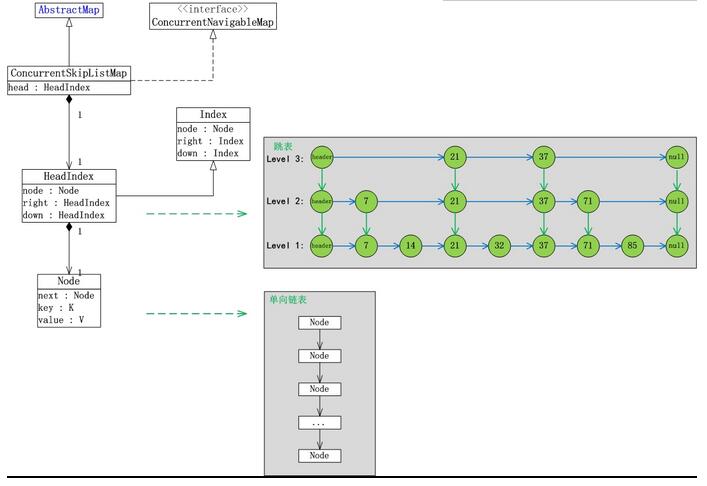
ConcurrentSkipListMapзҡ„ж•°жҚ®з»“жһ„пјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
иҜҙжҳҺпјҡ
е…Ҳд»Ҙж•°жҚ®вҖң7,14,21,32,37,71,85вҖқеәҸеҲ—дёәдҫӢпјҢжқҘеҜ№и·іиЎЁиҝӣиЎҢз®ҖеҚ•иҜҙжҳҺгҖӮ
и·іиЎЁеҲҶдёәи®ёеӨҡеұӮ(level)пјҢжҜҸдёҖеұӮйғҪеҸҜд»ҘзңӢдҪңжҳҜж•°жҚ®зҡ„зҙўеј•пјҢиҝҷдәӣзҙўеј•зҡ„ж„Ҹд№үе°ұжҳҜеҠ еҝ«и·іиЎЁжҹҘжүҫж•°жҚ®йҖҹеәҰгҖӮжҜҸдёҖеұӮзҡ„ж•°жҚ®йғҪжҳҜжңүеәҸзҡ„пјҢдёҠдёҖеұӮж•°жҚ®жҳҜдёӢдёҖеұӮж•°жҚ®зҡ„еӯҗйӣҶпјҢ并且第дёҖеұӮ(level 1)еҢ…еҗ«дәҶе…ЁйғЁзҡ„ж•°жҚ®пјӣеұӮж¬Ўи¶Ҡй«ҳпјҢи·іи·ғжҖ§и¶ҠеӨ§пјҢеҢ…еҗ«зҡ„ж•°жҚ®и¶Ҡе°‘гҖӮ
и·іиЎЁеҢ…еҗ«дёҖдёӘиЎЁеӨҙпјҢе®ғжҹҘжүҫж•°жҚ®ж—¶пјҢжҳҜд»ҺдёҠеҫҖдёӢпјҢд»Һе·ҰеҫҖеҸіиҝӣиЎҢжҹҘжүҫгҖӮзҺ°еңЁвҖңйңҖиҰҒжүҫеҮәеҖјдёә32зҡ„иҠӮзӮ№вҖқдёәдҫӢпјҢжқҘеҜ№жҜ”иҜҙжҳҺи·іиЎЁе’Ңжҷ®йҒҚзҡ„й“ҫиЎЁгҖӮ
жғ…еҶө1пјҡй“ҫиЎЁдёӯжҹҘжүҫвҖң32вҖқиҠӮзӮ№
и·Ҝеҫ„еҰӮдёӢеӣҫ1-02жүҖзӨәпјҡ

йңҖиҰҒ4жӯҘ(зәўиүІйғЁеҲҶиЎЁзӨәи·Ҝеҫ„)гҖӮ
жғ…еҶө2пјҡи·іиЎЁдёӯжҹҘжүҫвҖң32вҖқиҠӮзӮ№
и·Ҝеҫ„еҰӮдёӢеӣҫ1-03жүҖзӨәпјҡ
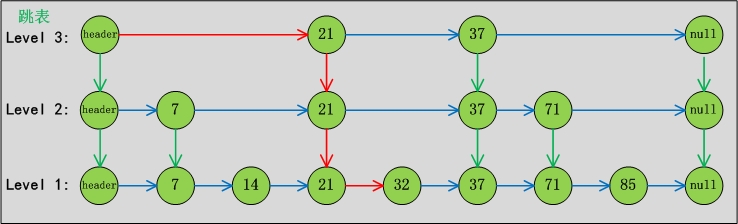
еҝҪз•Ҙзҙўеј•еһӮзӣҙзәҝи·ҜдёҠи·Ҝеҫ„зҡ„жғ…еҶөдёӢпјҢеҸӘйңҖиҰҒ2жӯҘ(зәўиүІйғЁеҲҶиЎЁзӨәи·Ҝеҫ„)гҖӮ
дёӢйқўиҜҙиҜҙJavaдёӯConcurrentSkipListMapзҡ„ж•°жҚ®з»“жһ„гҖӮ
(01) ConcurrentSkipListMap继жүҝдәҺAbstractMapзұ»пјҢд№ҹе°ұж„Ҹе‘ізқҖе®ғжҳҜдёҖдёӘе“ҲеёҢиЎЁгҖӮ
(02) IndexжҳҜConcurrentSkipListMapзҡ„еҶ…йғЁзұ»пјҢе®ғдёҺвҖңи·іиЎЁдёӯзҡ„зҙўеј•зӣёеҜ№еә”вҖқгҖӮHeadIndex继жүҝдәҺIndexпјҢConcurrentSkipListMapдёӯеҗ«жңүдёҖдёӘHeadIndexзҡ„еҜ№иұЎheadпјҢheadжҳҜвҖңи·іиЎЁзҡ„иЎЁеӨҙвҖқгҖӮ
(03) IndexжҳҜи·іиЎЁдёӯзҡ„зҙўеј•пјҢе®ғеҢ…еҗ«вҖңеҸізҙўеј•зҡ„жҢҮй’Ҳ(right)вҖқпјҢвҖңдёӢзҙўеј•зҡ„жҢҮй’Ҳ(down)вҖқе’ҢвҖңе“ҲеёҢиЎЁиҠӮзӮ№nodeвҖқгҖӮnodeжҳҜNodeзҡ„еҜ№иұЎпјҢNodeд№ҹжҳҜConcurrentSkipListMapдёӯзҡ„еҶ…йғЁзұ»гҖӮ
ConcurrentSkipListMapеҮҪж•°еҲ—иЎЁ
// жһ„йҖ дёҖдёӘж–°зҡ„з©әжҳ е°„пјҢиҜҘжҳ е°„жҢүз…§й”®зҡ„иҮӘ然йЎәеәҸиҝӣиЎҢжҺ’еәҸгҖӮ ConcurrentSkipListMap() // жһ„йҖ дёҖдёӘж–°зҡ„з©әжҳ е°„пјҢиҜҘжҳ е°„жҢүз…§жҢҮе®ҡзҡ„жҜ”иҫғеҷЁиҝӣиЎҢжҺ’еәҸгҖӮ ConcurrentSkipListMap(Comparator<? super K> comparator) // жһ„йҖ дёҖдёӘж–°жҳ е°„пјҢиҜҘжҳ е°„жүҖеҢ…еҗ«зҡ„жҳ е°„е…ізі»дёҺз»ҷе®ҡжҳ е°„еҢ…еҗ«зҡ„жҳ е°„е…ізі»зӣёеҗҢпјҢ并жҢүз…§й”®зҡ„иҮӘ然йЎәеәҸиҝӣиЎҢжҺ’еәҸгҖӮ ConcurrentSkipListMap(Map<? extends K,? extends V> m) // жһ„йҖ дёҖдёӘж–°жҳ е°„пјҢиҜҘжҳ е°„жүҖеҢ…еҗ«зҡ„жҳ е°„е…ізі»дёҺжҢҮе®ҡзҡ„жңүеәҸжҳ е°„еҢ…еҗ«зҡ„жҳ е°„е…ізі»зӣёеҗҢпјҢдҪҝз”Ёзҡ„йЎәеәҸд№ҹзӣёеҗҢгҖӮ ConcurrentSkipListMap(SortedMap<K,? extends V> m) // иҝ”еӣһдёҺеӨ§дәҺзӯүдәҺз»ҷе®ҡй”®зҡ„жңҖе°Ҹй”®е…іиҒ”зҡ„й”®-еҖјжҳ е°„е…ізі»пјӣеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„жқЎзӣ®пјҢеҲҷиҝ”еӣһ nullгҖӮ Map.Entry<K,V> ceilingEntry(K key) // иҝ”еӣһеӨ§дәҺзӯүдәҺз»ҷе®ҡй”®зҡ„жңҖе°Ҹй”®пјӣеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„й”®пјҢеҲҷиҝ”еӣһ nullгҖӮ K ceilingKey(K key) // д»ҺжӯӨжҳ е°„дёӯ移йҷӨжүҖжңүжҳ е°„е…ізі»гҖӮ void clear() // иҝ”еӣһжӯӨ ConcurrentSkipListMap е®һдҫӢзҡ„жө…иЎЁеүҜжң¬гҖӮ ConcurrentSkipListMap<K,V> clone() // иҝ”еӣһеҜ№жӯӨжҳ е°„дёӯзҡ„й”®иҝӣиЎҢжҺ’еәҸзҡ„жҜ”иҫғеҷЁпјӣеҰӮжһңжӯӨжҳ е°„дҪҝз”Ёй”®зҡ„иҮӘ然йЎәеәҸпјҢеҲҷиҝ”еӣһ nullгҖӮ Comparator<? super K> comparator() // еҰӮжһңжӯӨжҳ е°„еҢ…еҗ«жҢҮе®ҡй”®зҡ„жҳ е°„е…ізі»пјҢеҲҷиҝ”еӣһ trueгҖӮ boolean containsKey(Object key) // еҰӮжһңжӯӨжҳ е°„дёәжҢҮе®ҡеҖјжҳ е°„дёҖдёӘжҲ–еӨҡдёӘй”®пјҢеҲҷиҝ”еӣһ trueгҖӮ boolean containsValue(Object value) // иҝ”еӣһжӯӨжҳ е°„дёӯжүҖеҢ…еҗ«й”®зҡ„йҖҶеәҸ NavigableSet и§ҶеӣҫгҖӮ NavigableSet<K> descendingKeySet() // иҝ”еӣһжӯӨжҳ е°„дёӯжүҖеҢ…еҗ«жҳ е°„е…ізі»зҡ„йҖҶеәҸи§ҶеӣҫгҖӮ ConcurrentNavigableMap<K,V> descendingMap() // иҝ”еӣһжӯӨжҳ е°„дёӯжүҖеҢ…еҗ«зҡ„жҳ е°„е…ізі»зҡ„ Set и§ҶеӣҫгҖӮ Set<Map.Entry<K,V>> entrySet() // жҜ”иҫғжҢҮе®ҡеҜ№иұЎдёҺжӯӨжҳ е°„зҡ„зӣёзӯүжҖ§гҖӮ boolean equals(Object o) // иҝ”еӣһдёҺжӯӨжҳ е°„дёӯзҡ„жңҖе°Ҹй”®е…іиҒ”зҡ„й”®-еҖјжҳ е°„е…ізі»пјӣеҰӮжһңиҜҘжҳ е°„дёәз©әпјҢеҲҷиҝ”еӣһ nullгҖӮ Map.Entry<K,V> firstEntry() // иҝ”еӣһжӯӨжҳ е°„дёӯеҪ“еүҚ第дёҖдёӘпјҲжңҖдҪҺпјүй”®гҖӮ K firstKey() // иҝ”еӣһдёҺе°ҸдәҺзӯүдәҺз»ҷе®ҡй”®зҡ„жңҖеӨ§й”®е…іиҒ”зҡ„й”®-еҖјжҳ е°„е…ізі»пјӣеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„й”®пјҢеҲҷиҝ”еӣһ nullгҖӮ Map.Entry<K,V> floorEntry(K key) // иҝ”еӣһе°ҸдәҺзӯүдәҺз»ҷе®ҡй”®зҡ„жңҖеӨ§й”®пјӣеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„й”®пјҢеҲҷиҝ”еӣһ nullгҖӮ K floorKey(K key) // иҝ”еӣһжҢҮе®ҡй”®жүҖжҳ е°„еҲ°зҡ„еҖјпјӣеҰӮжһңжӯӨжҳ е°„дёҚеҢ…еҗ«иҜҘй”®зҡ„жҳ е°„е…ізі»пјҢеҲҷиҝ”еӣһ nullгҖӮ V get(Object key) // иҝ”еӣһжӯӨжҳ е°„зҡ„йғЁеҲҶи§ҶеӣҫпјҢе…¶й”®еҖјдёҘж је°ҸдәҺ toKeyгҖӮ ConcurrentNavigableMap<K,V> headMap(K toKey) // иҝ”еӣһжӯӨжҳ е°„зҡ„йғЁеҲҶи§ҶеӣҫпјҢе…¶й”®е°ҸдәҺпјҲжҲ–зӯүдәҺпјҢеҰӮжһң inclusive дёә trueпјүtoKeyгҖӮ ConcurrentNavigableMap<K,V> headMap(K toKey, boolean inclusive) // иҝ”еӣһдёҺдёҘж јеӨ§дәҺз»ҷе®ҡй”®зҡ„жңҖе°Ҹй”®е…іиҒ”зҡ„й”®-еҖјжҳ е°„е…ізі»пјӣеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„й”®пјҢеҲҷиҝ”еӣһ nullгҖӮ Map.Entry<K,V> higherEntry(K key) // иҝ”еӣһдёҘж јеӨ§дәҺз»ҷе®ҡй”®зҡ„жңҖе°Ҹй”®пјӣеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„й”®пјҢеҲҷиҝ”еӣһ nullгҖӮ K higherKey(K key) // еҰӮжһңжӯӨжҳ е°„жңӘеҢ…еҗ«й”®-еҖјжҳ е°„е…ізі»пјҢеҲҷиҝ”еӣһ trueгҖӮ boolean isEmpty() // иҝ”еӣһжӯӨжҳ е°„дёӯжүҖеҢ…еҗ«й”®зҡ„ NavigableSet и§ҶеӣҫгҖӮ NavigableSet<K> keySet() // иҝ”еӣһдёҺжӯӨжҳ е°„дёӯзҡ„жңҖеӨ§й”®е…іиҒ”зҡ„й”®-еҖјжҳ е°„е…ізі»пјӣеҰӮжһңиҜҘжҳ е°„дёәз©әпјҢеҲҷиҝ”еӣһ nullгҖӮ Map.Entry<K,V> lastEntry() // иҝ”еӣһжҳ е°„дёӯеҪ“еүҚжңҖеҗҺдёҖдёӘпјҲжңҖй«ҳпјүй”®гҖӮ K lastKey() // иҝ”еӣһдёҺдёҘж је°ҸдәҺз»ҷе®ҡй”®зҡ„жңҖеӨ§й”®е…іиҒ”зҡ„й”®-еҖјжҳ е°„е…ізі»пјӣеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„й”®пјҢеҲҷиҝ”еӣһ nullгҖӮ Map.Entry<K,V> lowerEntry(K key) // иҝ”еӣһдёҘж је°ҸдәҺз»ҷе®ҡй”®зҡ„жңҖеӨ§й”®пјӣеҰӮжһңдёҚеӯҳеңЁиҝҷж ·зҡ„й”®пјҢеҲҷиҝ”еӣһ nullгҖӮ K lowerKey(K key) // иҝ”еӣһжӯӨжҳ е°„дёӯжүҖеҢ…еҗ«й”®зҡ„ NavigableSet и§ҶеӣҫгҖӮ NavigableSet<K> navigableKeySet() // 移йҷӨ并иҝ”еӣһдёҺжӯӨжҳ е°„дёӯзҡ„жңҖе°Ҹй”®е…іиҒ”зҡ„й”®-еҖјжҳ е°„е…ізі»пјӣеҰӮжһңиҜҘжҳ е°„дёәз©әпјҢеҲҷиҝ”еӣһ nullгҖӮ Map.Entry<K,V> pollFirstEntry() // 移йҷӨ并иҝ”еӣһдёҺжӯӨжҳ е°„дёӯзҡ„жңҖеӨ§й”®е…іиҒ”зҡ„й”®-еҖјжҳ е°„е…ізі»пјӣеҰӮжһңиҜҘжҳ е°„дёәз©әпјҢеҲҷиҝ”еӣһ nullгҖӮ Map.Entry<K,V> pollLastEntry() // е°ҶжҢҮе®ҡеҖјдёҺжӯӨжҳ е°„дёӯзҡ„жҢҮе®ҡй”®е…іиҒ”гҖӮ V put(K key, V value) // еҰӮжһңжҢҮе®ҡй”®е·Із»ҸдёҚеҶҚдёҺжҹҗдёӘеҖјзӣёе…іиҒ”пјҢеҲҷе°Ҷе®ғдёҺз»ҷе®ҡеҖје…іиҒ”гҖӮ V putIfAbsent(K key, V value) // д»ҺжӯӨжҳ е°„дёӯ移йҷӨжҢҮе®ҡй”®зҡ„жҳ е°„е…ізі»пјҲеҰӮжһңеӯҳеңЁпјүгҖӮ V remove(Object key) // еҸӘжңүзӣ®еүҚе°Ҷй”®зҡ„жқЎзӣ®жҳ е°„еҲ°з»ҷе®ҡеҖјж—¶пјҢжүҚ移йҷӨиҜҘй”®зҡ„жқЎзӣ®гҖӮ boolean remove(Object key, Object value) // еҸӘжңүзӣ®еүҚе°Ҷй”®зҡ„жқЎзӣ®жҳ е°„еҲ°жҹҗдёҖеҖјж—¶пјҢжүҚжӣҝжҚўиҜҘй”®зҡ„жқЎзӣ®гҖӮ V replace(K key, V value) // еҸӘжңүзӣ®еүҚе°Ҷй”®зҡ„жқЎзӣ®жҳ е°„еҲ°з»ҷе®ҡеҖјж—¶пјҢжүҚжӣҝжҚўиҜҘй”®зҡ„жқЎзӣ®гҖӮ boolean replace(K key, V oldValue, V newValue) // иҝ”еӣһжӯӨжҳ е°„дёӯзҡ„й”®-еҖјжҳ е°„е…ізі»ж•°гҖӮ int size() // иҝ”еӣһжӯӨжҳ е°„зҡ„йғЁеҲҶи§ҶеӣҫпјҢе…¶й”®зҡ„иҢғеӣҙд»Һ fromKey еҲ° toKeyгҖӮ ConcurrentNavigableMap<K,V> subMap(K fromKey, boolean fromInclusive, K toKey, boolean toInclusive) // иҝ”еӣһжӯӨжҳ е°„зҡ„йғЁеҲҶи§ҶеӣҫпјҢе…¶й”®еҖјзҡ„иҢғеӣҙд»Һ fromKeyпјҲеҢ…жӢ¬пјүеҲ° toKeyпјҲдёҚеҢ…жӢ¬пјүгҖӮ ConcurrentNavigableMap<K,V> subMap(K fromKey, K toKey) // иҝ”еӣһжӯӨжҳ е°„зҡ„йғЁеҲҶи§ҶеӣҫпјҢе…¶й”®еӨ§дәҺзӯүдәҺ fromKeyгҖӮ ConcurrentNavigableMap<K,V> tailMap(K fromKey) // иҝ”еӣһжӯӨжҳ е°„зҡ„йғЁеҲҶи§ҶеӣҫпјҢе…¶й”®еӨ§дәҺпјҲжҲ–зӯүдәҺпјҢеҰӮжһң inclusive дёә trueпјүfromKeyгҖӮ ConcurrentNavigableMap<K,V> tailMap(K fromKey, boolean inclusive) // иҝ”еӣһжӯӨжҳ е°„дёӯжүҖеҢ…еҗ«еҖјзҡ„ Collection и§ҶеӣҫгҖӮ Collection<V> values()
дёӢйқўд»ҺConcurrentSkipListMapзҡ„ж·»еҠ пјҢеҲ йҷӨпјҢиҺ·еҸ–иҝҷ3дёӘж–№йқўеҜ№е®ғиҝӣиЎҢеҲҶжһҗгҖӮ
1. ж·»еҠ
дёӢйқўд»Ҙput(K key, V value)дёәдҫӢпјҢеҜ№ConcurrentSkipListMapзҡ„ж·»еҠ ж–№жі•иҝӣиЎҢиҜҙжҳҺгҖӮ
public V put(K key, V value) {
if (value == null)
throw new NullPointerException();
return doPut(key, value, false);
}
е®һйҷ…дёҠпјҢput()жҳҜйҖҡиҝҮdoPut()е°Ҷkey-valueй”®еҖјеҜ№ж·»еҠ еҲ°ConcurrentSkipListMapдёӯзҡ„гҖӮ
doPut()зҡ„жәҗз ҒеҰӮдёӢпјҡ
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
// жүҫеҲ°keyзҡ„еүҚ继иҠӮзӮ№
Node<K,V> b = findPredecessor(key);
// и®ҫзҪ®nдёәвҖңkeyзҡ„еүҚ继иҠӮзӮ№зҡ„еҗҺ继иҠӮзӮ№вҖқпјҢеҚіnеә”иҜҘжҳҜвҖңжҸ’е…ҘиҠӮзӮ№вҖқзҡ„вҖңеҗҺ继иҠӮзӮ№вҖқ
Node<K,V> n = b.next;
for (;;) {
if (n != null) {
Node<K,V> f = n.next;
// еҰӮжһңдёӨж¬ЎиҺ·еҫ—зҡ„b.nextдёҚжҳҜзӣёеҗҢзҡ„NodeпјҢе°ұи·іиҪ¬еҲ°вҖқеӨ–еұӮforеҫӘзҺҜвҖңпјҢйҮҚж–°иҺ·еҫ—bе’ҢnеҗҺеҶҚйҒҚеҺҶгҖӮ
if (n != b.next)
break;
// vжҳҜвҖңnзҡ„еҖјвҖқ
Object v = n.value;
// еҪ“nзҡ„еҖјдёәnull(ж„Ҹе‘ізқҖе…¶е®ғзәҝзЁӢеҲ йҷӨдәҶn)пјӣжӯӨж—¶еҲ йҷӨbзҡ„дёӢдёҖдёӘиҠӮзӮ№пјҢ然еҗҺи·іиҪ¬еҲ°вҖқеӨ–еұӮforеҫӘзҺҜвҖңпјҢйҮҚж–°иҺ·еҫ—bе’ҢnеҗҺеҶҚйҒҚеҺҶгҖӮ
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
// еҰӮжһңе…¶е®ғзәҝзЁӢеҲ йҷӨдәҶbпјӣеҲҷи·іиҪ¬еҲ°вҖқеӨ–еұӮforеҫӘзҺҜвҖңпјҢйҮҚж–°иҺ·еҫ—bе’ҢnеҗҺеҶҚйҒҚеҺҶгҖӮ
if (v == n || b.value == null) // b is deleted
break;
// жҜ”иҫғkeyе’Ңn.key
int c = key.compareTo(n.key);
if (c > 0) {
b = n;
n = f;
continue;
}
if (c == 0) {
if (onlyIfAbsent || n.casValue(v, value))
return (V)v;
else
break; // restart if lost race to replace value
}
// else c < 0; fall through
}
// ж–°е»әиҠӮзӮ№(еҜ№еә”жҳҜвҖңиҰҒжҸ’е…Ҙзҡ„й”®еҖјеҜ№вҖқ)
Node<K,V> z = new Node<K,V>(kkey, value, n);
// и®ҫзҪ®вҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқдёәz
if (!b.casNext(n, z))
break; // еӨҡзәҝзЁӢжғ…еҶөдёӢпјҢbreakжүҚеҸҜиғҪеҸ‘з”ҹ(е…¶е®ғзәҝзЁӢеҜ№bиҝӣиЎҢдәҶж“ҚдҪң)
// йҡҸжңәиҺ·еҸ–дёҖдёӘlevel
// 然еҗҺеңЁвҖң第1еұӮвҖқеҲ°вҖң第levelеұӮвҖқзҡ„й“ҫиЎЁдёӯйғҪжҸ’е…Ҙж–°е»әиҠӮзӮ№
int level = randomLevel();
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
иҜҙжҳҺпјҡdoPut() зҡ„дҪңз”Ёе°ұжҳҜе°Ҷй”®еҖјеҜ№ж·»еҠ еҲ°вҖңи·іиЎЁвҖқдёӯгҖӮ
иҰҒжғіжҗһжё…doPut()пјҢйҰ–е…ҲиҰҒеј„жё…жҘҡе®ғзҡ„дё»е№ІйғЁеҲҶ вҖ”вҖ” жҲ‘们е…ҲеҚ•зәҜзҡ„еҸӘиҖғиҷ‘вҖңеҚ•зәҝзЁӢзҡ„жғ…еҶөдёӢпјҢе°Ҷkey-valueж·»еҠ еҲ°и·іиЎЁдёӯвҖқпјҢеҚіеҝҪз•ҘвҖңеӨҡзәҝзЁӢзӣёе…ізҡ„еҶ…е®№вҖқгҖӮе®ғзҡ„жөҒзЁӢеҰӮдёӢпјҡ
第1жӯҘпјҡжүҫеҲ°вҖңжҸ’е…ҘдҪҚзҪ®вҖқгҖӮ
еҚіпјҢжүҫеҲ°вҖңkeyзҡ„еүҚ继иҠӮзӮ№(b)вҖқе’ҢвҖңkeyзҡ„еҗҺ继иҠӮзӮ№(n)вҖқпјӣkeyжҳҜиҰҒжҸ’е…ҘиҠӮзӮ№зҡ„й”®гҖӮ
第2жӯҘпјҡж–°е»ә并жҸ’е…ҘиҠӮзӮ№гҖӮ
еҚіпјҢж–°е»әиҠӮзӮ№z(keyеҜ№еә”зҡ„иҠӮзӮ№)пјҢ并е°Ҷж–°иҠӮзӮ№zжҸ’е…ҘеҲ°вҖңи·іиЎЁвҖқдёӯ(и®ҫзҪ®вҖңbзҡ„еҗҺ继иҠӮзӮ№дёәzвҖқпјҢвҖңzзҡ„еҗҺ继иҠӮзӮ№дёәnвҖқ)гҖӮ
第3жӯҘпјҡжӣҙж–°и·іиЎЁгҖӮ
еҚіпјҢйҡҸжңәиҺ·еҸ–дёҖдёӘlevelпјҢ然еҗҺеңЁвҖңи·іиЎЁвҖқзҡ„第1еұӮпҪһ第levelеұӮд№Ӣй—ҙпјҢжҜҸдёҖеұӮйғҪжҸ’е…ҘиҠӮзӮ№zпјӣеңЁз¬¬levelеұӮд№ӢдёҠе°ұдёҚеҶҚжҸ’е…ҘиҠӮзӮ№дәҶгҖӮиӢҘlevelж•°еҖјеӨ§дәҺвҖңи·іиЎЁзҡ„еұӮж¬ЎвҖқпјҢеҲҷж–°е»әдёҖеұӮгҖӮ
дё»е№ІйғЁеҲҶвҖңеҜ№еә”зҡ„зІҫз®ҖеҗҺзҡ„doPut()зҡ„д»Јз ҒвҖқеҰӮдёӢ(д»…дҫӣеҸӮиҖғ)пјҡ
private V doPut(K kkey, V value, boolean onlyIfAbsent) {
Comparable<? super K> key = comparable(kkey);
for (;;) {
// жүҫеҲ°keyзҡ„еүҚ继иҠӮзӮ№
Node<K,V> b = findPredecessor(key);
// и®ҫзҪ®nдёәkeyзҡ„еҗҺ继иҠӮзӮ№
Node<K,V> n = b.next;
for (;;) {
// ж–°е»әиҠӮзӮ№(еҜ№еә”жҳҜвҖңиҰҒиў«жҸ’е…Ҙзҡ„й”®еҖјеҜ№вҖқ)
Node<K,V> z = new Node<K,V>(kkey, value, n);
// и®ҫзҪ®вҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқдёәz
b.casNext(n, z);
// йҡҸжңәиҺ·еҸ–дёҖдёӘlevel
// 然еҗҺеңЁвҖң第1еұӮвҖқеҲ°вҖң第levelеұӮвҖқзҡ„й“ҫиЎЁдёӯйғҪжҸ’е…Ҙж–°е»әиҠӮзӮ№
int level = randomLevel();
if (level > 0)
insertIndex(z, level);
return null;
}
}
}
зҗҶжё…дё»е№Ід№ӢеҗҺпјҢеү©дҪҷзҡ„е·ҘдҪңе°ұзӣёеҜ№з®ҖеҚ•дәҶгҖӮдё»иҰҒжҳҜдёҠйқўеҮ жӯҘзҡ„еҜ№еә”з®—жі•зҡ„е…·дҪ“е®һзҺ°пјҢд»ҘеҸҠеӨҡзәҝзЁӢзӣёе…іжғ…еҶөзҡ„еӨ„зҗҶпјҒ
2. еҲ йҷӨ
дёӢйқўд»Ҙremove(Object key)дёәдҫӢпјҢеҜ№ConcurrentSkipListMapзҡ„еҲ йҷӨж–№жі•иҝӣиЎҢиҜҙжҳҺгҖӮ
public V remove(Object key) {
return doRemove(key, null);
}
е®һйҷ…дёҠпјҢremove()жҳҜйҖҡиҝҮdoRemove()е°ҶConcurrentSkipListMapдёӯзҡ„keyеҜ№еә”зҡ„й”®еҖјеҜ№еҲ йҷӨзҡ„гҖӮ
doRemove()зҡ„жәҗз ҒеҰӮдёӢпјҡ
final V doRemove(Object okey, Object value) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// жүҫеҲ°вҖңkeyзҡ„еүҚ继иҠӮзӮ№вҖқ
Node<K,V> b = findPredecessor(key);
// и®ҫзҪ®nдёәвҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқ(еҚіиӢҘkeyеӯҳеңЁдәҺвҖңи·іиЎЁдёӯвҖқпјҢnе°ұжҳҜkeyеҜ№еә”зҡ„иҠӮзӮ№)
Node<K,V> n = b.next;
for (;;) {
if (n == null)
return null;
// fжҳҜвҖңеҪ“еүҚиҠӮзӮ№nзҡ„еҗҺ继иҠӮзӮ№вҖқ
Node<K,V> f = n.next;
// еҰӮжһңдёӨж¬ЎиҜ»еҸ–еҲ°зҡ„вҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқдёҚеҗҢ(е…¶е®ғзәҝзЁӢж“ҚдҪңдәҶиҜҘи·іиЎЁ)пјҢеҲҷиҝ”еӣһеҲ°вҖңеӨ–еұӮforеҫӘзҺҜвҖқйҮҚж–°йҒҚеҺҶгҖӮ
if (n != b.next) // inconsistent read
break;
// еҰӮжһңвҖңеҪ“еүҚиҠӮзӮ№nзҡ„еҖјвҖқеҸҳдёәnull(е…¶е®ғзәҝзЁӢж“ҚдҪңдәҶиҜҘи·іиЎЁ)пјҢеҲҷиҝ”еӣһеҲ°вҖңеӨ–еұӮforеҫӘзҺҜвҖқйҮҚж–°йҒҚеҺҶгҖӮ
Object v = n.value;
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
// еҰӮжһңвҖңеүҚ继иҠӮзӮ№bвҖқиў«еҲ йҷӨ(е…¶е®ғзәҝзЁӢж“ҚдҪңдәҶиҜҘи·іиЎЁ)пјҢеҲҷиҝ”еӣһеҲ°вҖңеӨ–еұӮforеҫӘзҺҜвҖқйҮҚж–°йҒҚеҺҶгҖӮ
if (v == n || b.value == null) // b is deleted
break;
int c = key.compareTo(n.key);
if (c < 0)
return null;
if (c > 0) {
b = n;
n = f;
continue;
}
// д»ҘдёӢжҳҜc=0зҡ„жғ…еҶө
if (value != null && !value.equals(v))
return null;
// и®ҫзҪ®вҖңеҪ“еүҚиҠӮзӮ№nвҖқзҡ„еҖјдёәnull
if (!n.casValue(v, null))
break;
// и®ҫзҪ®вҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқдёәf
if (!n.appendMarker(f) || !b.casNext(n, f))
findNode(key); // Retry via findNode
else {
// жё…йҷӨвҖңи·іиЎЁвҖқдёӯжҜҸдёҖеұӮзҡ„keyиҠӮзӮ№
findPredecessor(key); // Clean index
// еҰӮжһңвҖңиЎЁеӨҙзҡ„еҸізҙўеј•дёәз©әвҖқпјҢеҲҷе°ҶвҖңи·іиЎЁзҡ„еұӮж¬ЎвҖқ-1гҖӮ
if (head.right == null)
tryReduceLevel();
}
return (V)v;
}
}
}
иҜҙжҳҺпјҡdoRemove()зҡ„дҪңз”ЁжҳҜеҲ йҷӨи·іиЎЁдёӯзҡ„иҠӮзӮ№гҖӮ
е’ҢdoPut()дёҖж ·пјҢжҲ‘们йҮҚзӮ№зңӢdoRemove()зҡ„дё»е№ІйғЁеҲҶпјҢдәҶи§Јдё»е№ІйғЁеҲҶд№ӢеҗҺпјҢе…¶дҪҷйғЁеҲҶе°ұйқһеёёе®№жҳ“зҗҶи§ЈдәҶгҖӮдёӢйқўжҳҜвҖңеҚ•зәҝзЁӢзҡ„жғ…еҶөдёӢпјҢеҲ йҷӨи·іиЎЁдёӯй”®еҖјеҜ№зҡ„жӯҘйӘӨвҖқпјҡ
第1жӯҘпјҡжүҫеҲ°вҖңиў«еҲ йҷӨиҠӮзӮ№зҡ„дҪҚзҪ®вҖқгҖӮ
еҚіпјҢжүҫеҲ°вҖңkeyзҡ„еүҚ继иҠӮзӮ№(b)вҖқпјҢвҖңkeyжүҖеҜ№еә”зҡ„иҠӮзӮ№(n)вҖқпјҢвҖңnзҡ„еҗҺ继иҠӮзӮ№fвҖқпјӣkeyжҳҜиҰҒеҲ йҷӨиҠӮзӮ№зҡ„й”®гҖӮ
第2жӯҘпјҡеҲ йҷӨиҠӮзӮ№гҖӮ
еҚіпјҢе°ҶвҖңkeyжүҖеҜ№еә”зҡ„иҠӮзӮ№nвҖқд»Һи·іиЎЁдёӯ移йҷӨ -- е°ҶвҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқи®ҫдёәвҖңfвҖқпјҒ
第3жӯҘпјҡжӣҙж–°и·іиЎЁгҖӮ
еҚіпјҢйҒҚеҺҶи·іиЎЁпјҢеҲ йҷӨжҜҸдёҖеұӮзҡ„вҖңkeyиҠӮзӮ№вҖқ(еҰӮжһңеӯҳеңЁзҡ„иҜқ)гҖӮеҰӮжһңеҲ йҷӨвҖңkeyиҠӮзӮ№вҖқд№ӢеҗҺпјҢи·іиЎЁзҡ„еұӮж¬ЎйңҖиҰҒ-1пјӣеҲҷжү§иЎҢзӣёеә”зҡ„ж“ҚдҪңпјҒ
дё»е№ІйғЁеҲҶвҖңеҜ№еә”зҡ„зІҫз®ҖеҗҺзҡ„doRemove()зҡ„д»Јз ҒвҖқеҰӮдёӢ(д»…дҫӣеҸӮиҖғ)пјҡ
final V doRemove(Object okey, Object value) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// жүҫеҲ°вҖңkeyзҡ„еүҚ继иҠӮзӮ№вҖқ
Node<K,V> b = findPredecessor(key);
// и®ҫзҪ®nдёәвҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқ(еҚіиӢҘkeyеӯҳеңЁдәҺвҖңи·іиЎЁдёӯвҖқпјҢnе°ұжҳҜkeyеҜ№еә”зҡ„иҠӮзӮ№)
Node<K,V> n = b.next;
for (;;) {
// fжҳҜвҖңеҪ“еүҚиҠӮзӮ№nзҡ„еҗҺ继иҠӮзӮ№вҖқ
Node<K,V> f = n.next;
// и®ҫзҪ®вҖңеҪ“еүҚиҠӮзӮ№nвҖқзҡ„еҖјдёәnull
n.casValue(v, null);
// и®ҫзҪ®вҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқдёәf
b.casNext(n, f);
// жё…йҷӨвҖңи·іиЎЁвҖқдёӯжҜҸдёҖеұӮзҡ„keyиҠӮзӮ№
findPredecessor(key);
// еҰӮжһңвҖңиЎЁеӨҙзҡ„еҸізҙўеј•дёәз©әвҖқпјҢеҲҷе°ҶвҖңи·іиЎЁзҡ„еұӮж¬ЎвҖқ-1гҖӮ
if (head.right == null)
tryReduceLevel();
return (V)v;
}
}
}
3. иҺ·еҸ–
дёӢйқўд»Ҙget(Object key)дёәдҫӢпјҢеҜ№ConcurrentSkipListMapзҡ„иҺ·еҸ–ж–№жі•иҝӣиЎҢиҜҙжҳҺгҖӮ
public V get(Object key) {
return doGet(key);
}
doGetзҡ„жәҗз ҒеҰӮдёӢпјҡ
private V doGet(Object okey) {
Comparable<? super K> key = comparable(okey);
for (;;) {
// жүҫеҲ°вҖңkeyеҜ№еә”зҡ„иҠӮзӮ№вҖқ
Node<K,V> n = findNode(key);
if (n == null)
return null;
Object v = n.value;
if (v != null)
return (V)v;
}
}
иҜҙжҳҺпјҡdoGet()жҳҜйҖҡиҝҮfindNode()жүҫеҲ°е№¶иҝ”еӣһиҠӮзӮ№зҡ„гҖӮ
private Node<K,V> findNode(Comparable<? super K> key) {
for (;;) {
// жүҫеҲ°keyзҡ„еүҚ继иҠӮзӮ№
Node<K,V> b = findPredecessor(key);
// и®ҫзҪ®nдёәвҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқ(еҚіиӢҘkeyеӯҳеңЁдәҺвҖңи·іиЎЁдёӯвҖқпјҢnе°ұжҳҜkeyеҜ№еә”зҡ„иҠӮзӮ№)
Node<K,V> n = b.next;
for (;;) {
// еҰӮжһңвҖңnдёәnullвҖқпјҢеҲҷи·іиҪ¬дёӯдёҚеӯҳеңЁkeyеҜ№еә”зҡ„иҠӮзӮ№пјҢзӣҙжҺҘиҝ”еӣһnullгҖӮ
if (n == null)
return null;
Node<K,V> f = n.next;
// еҰӮжһңдёӨж¬ЎиҜ»еҸ–еҲ°зҡ„вҖңbзҡ„еҗҺ继иҠӮзӮ№вҖқдёҚеҗҢ(е…¶е®ғзәҝзЁӢж“ҚдҪңдәҶиҜҘи·іиЎЁ)пјҢеҲҷиҝ”еӣһеҲ°вҖңеӨ–еұӮforеҫӘзҺҜвҖқйҮҚж–°йҒҚеҺҶгҖӮ
if (n != b.next) // inconsistent read
break;
Object v = n.value;
// еҰӮжһңвҖңеҪ“еүҚиҠӮзӮ№nзҡ„еҖјвҖқеҸҳдёәnull(е…¶е®ғзәҝзЁӢж“ҚдҪңдәҶиҜҘи·іиЎЁ)пјҢеҲҷиҝ”еӣһеҲ°вҖңеӨ–еұӮforеҫӘзҺҜвҖқйҮҚж–°йҒҚеҺҶгҖӮ
if (v == null) { // n is deleted
n.helpDelete(b, f);
break;
}
if (v == n || b.value == null) // b is deleted
break;
// иӢҘnжҳҜеҪ“еүҚиҠӮзӮ№пјҢеҲҷиҝ”еӣһnгҖӮ
int c = key.compareTo(n.key);
if (c == 0)
return n;
// иӢҘвҖңиҠӮзӮ№nзҡ„keyвҖқе°ҸдәҺвҖңkeyвҖқпјҢеҲҷиҜҙжҳҺи·іиЎЁдёӯдёҚеӯҳеңЁkeyеҜ№еә”зҡ„иҠӮзӮ№пјҢиҝ”еӣһnull
if (c < 0)
return null;
// иӢҘвҖңиҠӮзӮ№nзҡ„keyвҖқеӨ§дәҺвҖңkeyвҖқпјҢеҲҷжӣҙж–°bе’ҢnпјҢ继з»ӯжҹҘжүҫгҖӮ
b = n;
n = f;
}
}
}
иҜҙжҳҺпјҡfindNode(key)зҡ„дҪңз”ЁжҳҜеңЁиҝ”еӣһи·іиЎЁдёӯkeyеҜ№еә”зҡ„иҠӮзӮ№пјӣеӯҳеңЁеҲҷиҝ”еӣһиҠӮзӮ№пјҢдёҚеӯҳеңЁеҲҷиҝ”еӣһnullгҖӮ
е…Ҳеј„жё…еҮҪж•°зҡ„дё»е№ІйғЁеҲҶпјҢеҚіжҠӣејҖвҖңеӨҡзәҝзЁӢзӣёе…іеҶ…е®№вҖқпјҢеҚ•зәҜзҡ„иҖғиҷ‘еҚ•зәҝзЁӢжғ…еҶөдёӢпјҢд»Һи·іиЎЁиҺ·еҸ–иҠӮзӮ№зҡ„з®—жі•гҖӮ
第1жӯҘпјҡжүҫеҲ°вҖңиў«еҲ йҷӨиҠӮзӮ№зҡ„дҪҚзҪ®вҖқгҖӮ
ж №жҚ®findPredecessor()е®ҡдҪҚkeyжүҖеңЁзҡ„еұӮж¬Ўд»ҘеҸҠжүҫеҲ°keyзҡ„еүҚ继иҠӮзӮ№(b)пјҢ然еҗҺжүҫеҲ°bзҡ„еҗҺ继иҠӮзӮ№nгҖӮ
第2жӯҘпјҡж №жҚ®вҖңkeyзҡ„еүҚ继иҠӮзӮ№(b)вҖқе’ҢвҖңkeyзҡ„еүҚ继иҠӮзӮ№зҡ„еҗҺ继иҠӮзӮ№(n)вҖқжқҘе®ҡдҪҚвҖңkeyеҜ№еә”зҡ„иҠӮзӮ№вҖқгҖӮ
е…·дҪ“жҳҜйҖҡиҝҮжҜ”иҫғвҖңnзҡ„й”®еҖјвҖқе’ҢвҖңkeyвҖқзҡ„еӨ§е°ҸгҖӮеҰӮжһңзӣёзӯүпјҢеҲҷnе°ұжҳҜжүҖиҰҒжҹҘжүҫзҡ„й”®гҖӮ
ConcurrentSkipListMapзӨәдҫӢ
import java.util.*;
import java.util.concurrent.*;
/*
* ConcurrentSkipListMapжҳҜвҖңзәҝзЁӢе®үе…ЁвҖқзҡ„е“ҲеёҢиЎЁпјҢиҖҢTreeMapжҳҜйқһзәҝзЁӢе®үе…Ёзҡ„гҖӮ
*
* дёӢйқўжҳҜвҖңеӨҡдёӘзәҝзЁӢеҗҢж—¶ж“ҚдҪң并且йҒҚеҺҶmapвҖқзҡ„зӨәдҫӢ
* (01) еҪ“mapжҳҜConcurrentSkipListMapеҜ№иұЎж—¶пјҢзЁӢеәҸиғҪжӯЈеёёиҝҗиЎҢгҖӮ
* (02) еҪ“mapжҳҜTreeMapеҜ№иұЎж—¶пјҢзЁӢеәҸдјҡдә§з”ҹConcurrentModificationExceptionејӮеёёгҖӮ
*
* @author skywang
*/
public class ConcurrentSkipListMapDemo1 {
// TODO: mapжҳҜTreeMapеҜ№иұЎж—¶пјҢзЁӢеәҸдјҡеҮәй”ҷгҖӮ
//private static Map<String, String> map = new TreeMap<String, String>();
private static Map<String, String> map = new ConcurrentSkipListMap<String, String>();
public static void main(String[] args) {
// еҗҢж—¶еҗҜеҠЁдёӨдёӘзәҝзЁӢеҜ№mapиҝӣиЎҢж“ҚдҪңпјҒ
new MyThread("a").start();
new MyThread("b").start();
}
private static void printAll() {
String key, value;
Iterator iter = map.entrySet().iterator();
while(iter.hasNext()) {
Map.Entry entry = (Map.Entry)iter.next();
key = (String)entry.getKey();
value = (String)entry.getValue();
System.out.print("("+key+", "+value+"), ");
}
System.out.println();
}
private static class MyThread extends Thread {
MyThread(String name) {
super(name);
}
@Override
public void run() {
int i = 0;
while (i++ < 6) {
// вҖңзәҝзЁӢеҗҚвҖқ + "еәҸеҸ·"
String val = Thread.currentThread().getName()+i;
map.put(val, "0");
// йҖҡиҝҮвҖңIteratorвҖқйҒҚеҺҶmapгҖӮ
printAll();
}
}
}
}
(жҹҗдёҖж¬Ў)иҝҗиЎҢз»“жһңпјҡ
(a1, 0), (a1, 0), (b1, 0), (b1, 0), (a1, 0), (b1, 0), (b2, 0), (a1, 0), (a1, 0), (a2, 0), (a2, 0), (b1, 0), (b1, 0), (b2, 0), (b2, 0), (b3, 0), (b3, 0), (a1, 0), (a2, 0), (a3, 0), (a1, 0), (b1, 0), (a2, 0), (b2, 0), (a3, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (a1, 0), (b3, 0), (a2, 0), (b4, 0), (a3, 0), (a1, 0), (a4, 0), (a2, 0), (b1, 0), (a3, 0), (b2, 0), (a4, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0), (b3, 0), (a1, 0), (b4, 0), (a2, 0), (b5, 0), (a3, 0), (a1, 0), (a4, 0), (a2, 0), (a5, 0), (a3, 0), (b1, 0), (a4, 0), (b2, 0), (a5, 0), (b3, 0), (b1, 0), (b4, 0), (b2, 0), (b5, 0), (b3, 0), (b6, 0), (b4, 0), (a1, 0), (b5, 0), (a2, 0), (b6, 0), (a3, 0), (a4, 0), (a5, 0), (a6, 0), (b1, 0), (b2, 0), (b3, 0), (b4, 0), (b5, 0), (b6, 0),
з»“жһңиҜҙжҳҺпјҡ
зӨәдҫӢзЁӢеәҸдёӯпјҢеҗҜеҠЁдёӨдёӘзәҝзЁӢ(зәҝзЁӢaе’ҢзәҝзЁӢb)еҲҶеҲ«еҜ№ConcurrentSkipListMapиҝӣиЎҢж“ҚдҪңгҖӮд»ҘзәҝзЁӢaиҖҢиЁҖпјҢе®ғдјҡе…ҲиҺ·еҸ–вҖңзәҝзЁӢеҗҚвҖқ+вҖңеәҸеҸ·вҖқпјҢ然еҗҺе°ҶиҜҘеӯ—з¬ҰдёІдҪңдёәkeyпјҢе°ҶвҖң0вҖқдҪңдёәvalueпјҢжҸ’е…ҘеҲ°ConcurrentSkipListMapдёӯпјӣжҺҘзқҖпјҢйҒҚеҺҶ并иҫ“еҮәConcurrentSkipListMapдёӯзҡ„е…ЁйғЁе…ғзҙ гҖӮ зәҝзЁӢbзҡ„ж“ҚдҪңе’ҢзәҝзЁӢaдёҖж ·пјҢеҸӘдёҚиҝҮзәҝзЁӢbзҡ„еҗҚеӯ—е’ҢзәҝзЁӢaзҡ„еҗҚеӯ—дёҚеҗҢгҖӮ
еҪ“mapжҳҜConcurrentSkipListMapеҜ№иұЎж—¶пјҢзЁӢеәҸиғҪжӯЈеёёиҝҗиЎҢгҖӮеҰӮжһңе°Ҷmapж”№дёәTreeMapж—¶пјҢзЁӢеәҸдјҡдә§з”ҹConcurrentModificationExceptionејӮеёёгҖӮ
д»ҘдёҠе°ұжҳҜжң¬ж–Үзҡ„е…ЁйғЁеҶ…е®№пјҢеёҢжңӣеҜ№еӨ§е®¶зҡ„еӯҰд№ жңүжүҖеё®еҠ©пјҢд№ҹеёҢжңӣеӨ§е®¶еӨҡеӨҡж”ҜжҢҒдәҝйҖҹдә‘гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ