жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
дҪҝз”ЁSpring BatchеҰӮдҪ•е®һзҺ°е°Ҷtxtж–Ү件еҶҷе…Ҙж•°жҚ®еә“пјҹй’ҲеҜ№иҝҷдёӘй—®йўҳпјҢиҝҷзҜҮж–Үз« иҜҰз»Ҷд»Ӣз»ҚдәҶзӣёеҜ№еә”зҡ„еҲҶжһҗе’Ңи§Јзӯ”пјҢеёҢжңӣеҸҜд»Ҙеё®еҠ©жӣҙеӨҡжғіи§ЈеҶіиҝҷдёӘй—®йўҳзҡ„е°ҸдјҷдјҙжүҫеҲ°жӣҙз®ҖеҚ•жҳ“иЎҢзҡ„ж–№жі•гҖӮ
1гҖҒеҲӣе»ә Maven йЎ№зӣ®пјҢ并еңЁ pom.xml дёӯж·»еҠ дҫқиө–
<parent> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>1.5.2.RELEASE</version> </parent> <properties> <java.version>1.8</java.version> </properties> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-batch</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-jpa</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-test</artifactId> <scope>test</scope> </dependency> <dependency> <groupId>org.mybatis.spring.boot</groupId> <artifactId>mybatis-spring-boot-starter</artifactId> <version>1.2.0</version> </dependency> <!-- е·Ҙе…·зұ»дҫқиө–--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId> <version>1.12.6</version> </dependency> <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-lang3</artifactId> <version>3.4</version> </dependency> <!-- ж•°жҚ®еә“зӣёе…ідҫқиө– --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <scope>runtime</scope> </dependency> <dependency> <groupId>com.alibaba</groupId> <artifactId>druid</artifactId> <version>1.0.26</version> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> </dependencies>
иҝҷйҮҢжҳҜиҝҷдёӘе°ҸйЎ№зӣ®дёӯз”ЁеҲ°зҡ„жүҖжңүдҫқиө–пјҢеҢ…жӢ¬иҝһжҺҘж•°жҚ®еә“зҡ„дҫқиө–д»ҘеҸҠе·Ҙе…·зұ»зӯүгҖӮ
2гҖҒзј–еҶҷ Model зұ»
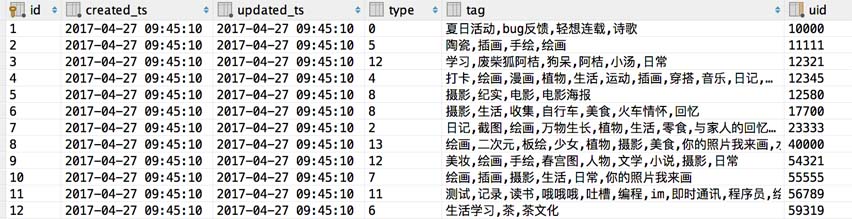
жҲ‘们иҰҒд»Һж–ҮжЎЈдёӯиҜ»еҸ–зҡ„жңүж•ҲеҲ—е°ұжҳҜ uidпјҢtagпјҢtypeпјҢе°ұжҳҜз”ЁжҲ· IDпјҢз”ЁжҲ·еҸҜиғҪеҢ…еҗ«зҡ„ж ҮзӯҫпјҲз”ЁдәҺжҺЁйҖҒпјүпјҢз”ЁжҲ·зұ»еҲ«пјҲз”ЁжҲ·з”ЁжҲ·д№Ӣй—ҙдә’зӣёжҺЁиҚҗпјүгҖӮ
UserMap.java дёӯзҡ„ @EntityпјҢ@Column жіЁи§ЈпјҢжҳҜдёәдәҶеҲ©з”Ё JPA з”ҹжҲҗж•°жҚ®иЎЁиҖҢеҶҷзҡ„пјҢеҸҜиҰҒеҸҜдёҚиҰҒгҖӮ
UserMap.java
@Data
@EqualsAndHashCode
@NoArgsConstructor
@AllArgsConstructor
//@Entity(name = "user_map")
public class UserMap extends BaseModel {
@Column(name = "uid", unique = true, nullable = false)
private Long uid;
@Column(name = "tag")
private String tag;
@Column(name = "type")
private Integer type;
}3гҖҒе®һзҺ°жү№еӨ„зҗҶй…ҚзҪ®зұ»
BatchConfiguration.java
@Configuration
@EnableBatchProcessing
public class BatchConfiguration {
@Autowired
public JobBuilderFactory jobBuilderFactory;
@Autowired
public StepBuilderFactory stepBuilderFactory;
@Autowired
@Qualifier("prodDataSource")
DataSource prodDataSource;
@Bean
public FlatFileItemReader<UserMap> reader() {
FlatFileItemReader<UserMap> reader = new FlatFileItemReader<>();
reader.setResource(new ClassPathResource("c152.txt"));
reader.setLineMapper(new DefaultLineMapper<UserMap>() {{
setLineTokenizer(new DelimitedLineTokenizer("|") {{
setNames(new String[]{"uid", "tag", "type"});
}});
setFieldSetMapper(new BeanWrapperFieldSetMapper<UserMap>() {{
setTargetType(UserMap.class);
}});
}});
return reader;
}
@Bean
public JdbcBatchItemWriter<UserMap> importWriter() {
JdbcBatchItemWriter<UserMap> writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
writer.setSql("INSERT INTO user_map (uid,tag,type) VALUES (:uid, :tag,:type)");
writer.setDataSource(prodDataSource);
return writer;
}
@Bean
public JdbcBatchItemWriter<UserMap> updateWriter() {
JdbcBatchItemWriter<UserMap> writer = new JdbcBatchItemWriter<>();
writer.setItemSqlParameterSourceProvider(new BeanPropertyItemSqlParameterSourceProvider<>());
writer.setSql("UPDATE user_map SET type = (:type),tag = (:tag) WHERE uid = (:uid)");
writer.setDataSource(prodDataSource);
return writer;
}
@Bean
public UserMapItemProcessor processor(UserMapItemProcessor.ProcessStatus processStatus) {
return new UserMapItemProcessor(processStatus);
}
@Bean
public Job importUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory.get("importUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(importStep())
.end()
.build();
}
@Bean
public Step importStep() {
return stepBuilderFactory.get("importStep")
.<UserMap, UserMap>chunk(100)
.reader(reader())
.processor(processor(IMPORT))
.writer(importWriter())
.build();
}
@Bean
public Job updateUserJob(JobCompletionNotificationListener listener) {
return jobBuilderFactory.get("updateUserJob")
.incrementer(new RunIdIncrementer())
.listener(listener)
.flow(updateStep())
.end()
.build();
}
@Bean
public Step updateStep() {
return stepBuilderFactory.get("updateStep")
.<UserMap, UserMap>chunk(100)
.reader(reader())
.processor(processor(UPDATE))
.writer(updateWriter())
.build();
}
}prodDataSource жҳҜеҒҮи®ҫз”ЁжҲ·е·Із»Ҹи®ҫзҪ®еҘҪзҡ„пјҢеҰӮжһңдёҚзҹҘйҒ“жҖҺд№Ҳй…ҚзҪ®пјҢд№ҹеҸҜд»ҘеҸӮиҖғд№ӢеүҚзҡ„ж–Үз« иҝӣиЎҢй…ҚзҪ®пјҡSpringboot йӣҶжҲҗ MybatisгҖӮ
reader()пјҢиҝҷж–№жі•д»Һж–Ү件дёӯиҜ»еҸ–ж•°жҚ®пјҢ并且и®ҫзҪ®дәҶдёҖдәӣеҝ…иҰҒзҡ„еҸӮж•°гҖӮзҙ§жҺҘзқҖжҳҜеҶҷж“ҚдҪң importWriter() е’Ң updateWriter() пјҢиҜ»иҖ…зңӢе…¶дёӯдёҖдёӘе°ұеҘҪпјҢеӣ дёәжҲ‘иҝҷйҮҢжҳҜйңҖиҰҒжӣҙж–°жҲ–иҖ…дҝ®ж”№зҡ„пјҢжүҖд»ҘеҲҶдёәдёӨдёӘгҖӮ
processor(ProcessStatus status) пјҢиҜҘж–№жі•жҳҜеҜ№жҲ‘们еӨ„зҗҶж•°жҚ®зҡ„зұ»иҝӣиЎҢе®һдҫӢеҢ–пјҢиҝҷйҮҢжҲ‘ж №жҚ® status жҳҜ IMPORT иҝҳжҳҜ UPDATE жқҘиҺ·еҸ–дёҚеҗҢзҡ„еӨ„зҗҶз»“жһңгҖӮ
е…¶д»–зҡ„зңӢд»Јз Ғе°ұеҸҜд»ҘзңӢжҮӮдәҶпјҢе“Ҳе“ҲпјҢдёҚиҜҰз»ҶиҜҙдәҶгҖӮ
4гҖҒе°ҶиҺ·еҫ—зҡ„ж•°жҚ®иҝӣиЎҢжё…жҙ—
UserMapItemProcessor.java
public class UserMapItemProcessor implements ItemProcessor<UserMap, UserMap> {
private static final int MAX_TAG_LENGTH = 200;
private ProcessStatus processStatus;
public UserMapItemProcessor(ProcessStatus processStatus) {
this.processStatus = processStatus;
}
@Autowired
IUserMapService userMapService;
private static final String TAG_PATTERN_STR = "^[a-zA-Z0-9\\u4E00-\\u9FA5_-]+$";
public static final Pattern TAG_PATTERN = Pattern.compile(TAG_PATTERN_STR);
private static final Logger LOG = LoggerFactory.getLogger(UserMapItemProcessor.class);
@Override
public UserMap process(UserMap userMap) throws Exception {
Long uid = userMap.getUid();
String tag = cleanTag(userMap.getTag());
Integer label = userMap.getType() == null ? Integer.valueOf(0) : userMap.getType();
if (StringUtils.isNotBlank(tag)) {
Map<String, Object> params = new HashMap<>();
params.put("uid", uid);
UserMap userMapFromDB = userMapService.selectOne(params);
if (userMapFromDB == null) {
if (this.processStatus == ProcessStatus.IMPORT) {
return new UserMap(uid, tag, label);
}
} else {
if (this.processStatus == ProcessStatus.UPDATE) {
if (!tag.equals(userMapFromDB.getTag()) && !label.equals(userMapFromDB.getType())) {
userMapFromDB.setType(label);
userMapFromDB.setTag(tag);
return userMapFromDB;
}
}
}
}
return null;
}
/**
* жё…жҙ—ж Үзӯҫ
*
* @param tag
* @return
*/
private static String cleanTag(String tag) {
if (StringUtils.isNotBlank(tag)) {
try {
tag = tag.substring(tag.indexOf("{") + 1, tag.lastIndexOf("}"));
String[] tagArray = tag.split(",");
Optional<String> reduce = Arrays.stream(tagArray).parallel()
.map(str -> str.split(":")[0])
.map(str -> str.replaceAll("\'", ""))
.map(str -> str.replaceAll(" ", ""))
.filter(str -> TAG_PATTERN.matcher(str).matches())
.reduce((x, y) -> x + "," + y);
Function<String, String> str = (s -> s.length() > MAX_TAG_LENGTH ? s.substring(0, MAX_TAG_LENGTH) : s);
return str.apply(reduce.get());
} catch (Exception e) {
LOG.error(e.getMessage(), e);
}
}
return null;
}
protected enum ProcessStatus {
IMPORT,
UPDATE;
}
public static void main(String[] args) {
String distinctTag = cleanTag("Counter({'гҖҠйҮҚж–°е®ҡд№үгҖӢ': 3, 'иҪ»жғідёҠзҡ„иҪ»е°ҸиҜҙ': 3, 'е°ҸиҜҙ': 2, 'Fate': 2, 'еҗҢдәәе°ҸиҜҙ': 2, 'йӣӘзӢје…«з»„': 1, " +
"'зӨҫдјҡ': 1, 'дәәж–Ү': 1, 'зҹӯзҜҮ': 1, 'йҮҚж–°е®ҡд№ү': 1, 'AMV': 1, 'гҖҠFBDгҖӢ': 1, 'гҖҠйӣӘзӢје…ӯз»„гҖӢ': 1, 'жҲҳдәү': 1, 'гҖҠзҒ°зҫҪиҒ”зӣҹгҖӢ': 1, " +
"'и°ҒиҜҙиҪ»жғіжІЎдәәеҶҷе°ҸиҜҙ': 1})");
System.out.println(distinctTag);
}
}иҜ»еҸ–еҲ°зҡ„ж•°жҚ®ж јејҸеҰӮ main() ж–№жі•жүҖзӨәпјҢжё…зҗҶд№ӢеҗҺзҡ„з»“жһңеҰӮпјҡ
иҪ»жғідёҠзҡ„иҪ»е°ҸиҜҙ,е°ҸиҜҙ,Fate,еҗҢдәәе°ҸиҜҙ,йӣӘзӢје…«з»„,зӨҫдјҡ,дәәж–Ү,зҹӯзҜҮ,йҮҚж–°е®ҡд№ү,AMV,жҲҳдәү,и°ҒиҜҙиҪ»жғіжІЎдәәеҶҷе°ҸиҜҙ гҖӮ
еҺ»жҺүдәҶзү№ж®Ҡз¬ҰеҸ·д»ҘеҸҠж•°еӯ—зӯүгҖӮдҪҝз”ЁдәҶ Java8 зҡ„ Lambda иЎЁиҫҫејҸгҖӮ
并且иҝҷйҮҢеңЁеӨ„зҗҶзҡ„ж—¶еҖҷпјҢеҲӨж–ӯеҰӮжһңиҜҘж•°жҚ®з”ЁжҲ·е·Із»ҸеӯҳеңЁпјҢеҲҷиҝӣиЎҢжӣҙж–°пјҢеҰӮжһңдёҚеӯҳеңЁпјҢеҲҷж–°еўһгҖӮ
5гҖҒJob жү§иЎҢз»“жқҹеӣһи°ғзұ»
JobCompletionNotificationListener.java
@Component
public class JobCompletionNotificationListener extends JobExecutionListenerSupport {
private static final Logger log = LoggerFactory.getLogger(JobCompletionNotificationListener.class);
private final JdbcTemplate jdbcTemplate;
@Autowired
public JobCompletionNotificationListener(JdbcTemplate jdbcTemplate) {
this.jdbcTemplate = jdbcTemplate;
}
@Override
public void afterJob(JobExecution jobExecution) {
System.out.println("end .....");
}
}е…·дҪ“зҡ„йҖ»иҫ‘еҸҜиҮӘиЎҢе®һзҺ°гҖӮ
е®ҢжҲҗд»ҘдёҠеҮ дёӘжӯҘйӘӨпјҢиҝҗиЎҢйЎ№зӣ®пјҢе°ұеҸҜд»ҘиҜ»еҸ–并еҶҷе…Ҙж•°жҚ®еҲ°ж•°жҚ®еә“дәҶгҖӮ
е…ідәҺдҪҝз”ЁSpring BatchеҰӮдҪ•е®һзҺ°е°Ҷtxtж–Ү件еҶҷе…Ҙж•°жҚ®еә“й—®йўҳзҡ„и§Јзӯ”е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҰӮжһңдҪ иҝҳжңүеҫҲеӨҡз–‘жғ‘жІЎжңүи§ЈејҖпјҢеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“дәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ