жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
java TreeMapжәҗз Ғи§ЈжһҗиҜҰи§Ј
еңЁд»Ӣз»ҚTreeMapд№ӢеүҚпјҢжҲ‘们жқҘдәҶи§ЈдёҖз§Қж•°жҚ®з»“жһ„пјҡжҺ’еәҸдәҢеҸүж ‘гҖӮзӣёдҝЎеӯҰиҝҮж•°жҚ®з»“жһ„зҡ„еҗҢеӯҰзҹҘйҒ“пјҢиҝҷз§Қз»“жһ„зҡ„ж•°жҚ®еӯҳеӮЁеҪўејҸеңЁжҹҘжүҫзҡ„ж—¶еҖҷж•ҲзҺҮйқһеёёй«ҳгҖӮ

еҰӮеӣҫжүҖзӨәпјҢиҝҷз§Қж•°жҚ®з»“жһ„жҳҜд»ҘдәҢеҸүж ‘дёәеҹәзЎҖзҡ„пјҢжүҖжңүзҡ„е·Ұеӯ©еӯҗзҡ„valueеҖјйғҪжҳҜе°ҸдәҺж №з»“зӮ№зҡ„valueеҖјзҡ„пјҢжүҖжңүеҸіеӯ©еӯҗзҡ„valueеҖјйғҪжҳҜеӨ§дәҺж №з»“зӮ№зҡ„гҖӮиҝҷж ·еҒҡзҡ„еҘҪеӨ„еңЁдәҺпјҡеҰӮжһңйңҖиҰҒжҢүз…§й”®еҖјжҹҘжүҫж•°жҚ®е…ғзҙ пјҢеҸӘиҰҒжҜ”иҫғеҪ“еүҚз»“зӮ№зҡ„valueеҖјеҚіеҸҜпјҲе°ҸдәҺеҪ“еүҚз»“зӮ№valueеҖјзҡ„пјҢеҫҖе·Ұиө°пјҢеҗҰеҲҷеҫҖеҸіиө°пјүпјҢиҝҷз§Қж–№ејҸпјҢжҜҸж¬ЎеҸҜд»ҘеҮҸе°‘дёҖеҚҠзҡ„ж“ҚдҪңпјҢжүҖд»Ҙж•ҲзҺҮжҜ”иҫғй«ҳгҖӮеңЁе®һзҺ°жҲ‘们зҡ„TreeMapдёӯпјҢдҪҝз”Ёзҡ„жҳҜзәўй»‘ж ‘пјҲдёҖз§ҚдјҳеҢ–дәҶзҡ„дәҢеҸүжҺ’еәҸж ‘пјүгҖӮ
дёҖгҖҒTreeMapзҡ„и¶…жҺҘеҸЈ
TreeMapдё»иҰҒ继жүҝдәҶзұ»AbstractMapпјҲдёҖдёӘеҜ№MapжҺҘеҸЈзҡ„е®һзҺ°зұ»пјүе’Ң NavigableMapпјҲдё»иҰҒжҸҗдҫӣдәҶеҜ№TreeMapзҡ„дёҖдәӣй«ҳзә§ж“ҚдҪңдҫӢеҰӮпјҡиҝ”еӣһ第дёҖдёӘй”®жҲ–иҖ…иҝ”еӣһе°ҸдәҺжҹҗдёӘй”®зҡ„и§ҶеӣҫзӯүпјүгҖӮдё»иҰҒзҡ„дёҖдәӣж“ҚдҪңжңүпјҡputж·»еҠ е…ғзҙ еҲ°йӣҶеҗҲдёӯпјҢremoveж №жҚ®й”®еҖјжҲ–иҖ…valueеҲ йҷӨжҢҮе®ҡе…ғзҙ пјҢgetж №жҚ®жҢҮе®ҡй”®еҖјиҺ·еҸ–жҹҗдёӘе…ғзҙ пјҢcontainsValueжҹҘзңӢжҳҜеҗҰеҢ…еҗ«жҹҗдёӘжҢҮе®ҡзҡ„еҖјпјҢcontainsKey жҹҘзңӢжҳҜеҗҰеҢ…еҗ«жҹҗдёӘжҢҮе®ҡзҡ„keyж•°еҖјзӯүгҖӮ
дәҢгҖҒжһ„йҖ еҮҪж•°
TreeMap зҡ„жһ„йҖ еҮҪж•°дё»иҰҒжңүд»ҘдёӢеҮ з§Қпјҡ
private final Comparator<? super K> comparator;
public TreeMap() {comparator = null;}
public TreeMap(Comparator<? super K> comparator) {
this.comparator = comparator;
}
еӣ дёәеңЁжҲ‘们зҡ„еҶ…йғЁеӯҳеӮЁз»“жһ„дёӯпјҢжҳҜйңҖиҰҒеҜ№дёӨдёӘиҠӮзӮ№зҡ„е…ғзҙ зҡ„й”®еҖјиҝӣиЎҢжҜ”иҫғзҡ„пјҢжүҖд»Ҙе°ұеҝ…йЎ»иҰҒе®һзҺ°ComparableжҺҘеҸЈжқҘе…·жңүжҜ”иҫғеҠҹиғҪгҖӮ第дёҖдёӘжһ„йҖ еҮҪж•°й»ҳи®Өж— еҸӮпјҢеҶ…йғЁе°ҶжҲ‘们зҡ„жҜ”иҫғеҷЁиөӢеҖјдёәnullпјҢиЎЁжҳҺпјҡеңЁеҶ…йғЁйӣҶеҗҲдёӯдёҚйңҖиҰҒжҺҘеҸ—жқҘиҮӘеӨ–йғЁдј е…Ҙзҡ„жҜ”иҫғеҷЁпјҢй»ҳи®ӨдҪҝз”ЁKeyзҡ„жҜ”иҫғеҷЁпјҲдҫӢеҰӮпјҡKeyжҳҜIntegerзұ»еһӢе°ұдјҡй»ҳи®ӨдҪҝз”Ёе®ғзҡ„жҜ”иҫғеҷЁпјүгҖӮ第дәҢз§Қжһ„йҖ еҮҪж•°е°ұжҳҜд»ҺеӨ–йғЁдј е…ҘжҢҮе®ҡзҡ„жҜ”иҫғеҷЁпјҢжҢҮе®ҡTreeMapеҶ…йғЁеңЁеҜ№й”®иҝӣиЎҢжҜ”иҫғзҡ„ж—¶еҖҷдҪҝз”ЁжҲ‘们д»ҺеӨ–йғЁдј е…Ҙзҡ„жҜ”иҫғеҷЁгҖӮ
дёүгҖҒеҶ…йғЁеӯҳеӮЁзҡ„еҹәжң¬еҺҹзҗҶ
д»Һжәҗз Ғдёӯж‘ҳеҸ–йғЁеҲҶд»Јз ҒпјҢиғҪиҜҙжҳҺеҶ…йғЁз»“жһ„еҚіеҸҜгҖӮ
private final Comparator<? super K> comparator;
private transient Entry<K,V> root;
private transient int modCount = 0;
//йқҷжҖҒжҲҗе‘ҳеҶ…йғЁзұ»
static final class Entry<K,V> implements Map.Entry<K,V> {
K key;
V value;
Entry<K,V> left;
Entry<K,V> right;
Entry<K,V> parent;
boolean color = BLACK;
.........
}
д»Һд»Јз ҒдёӯпјҢжҲ‘们еҸҜд»ҘеҫҲе®№жҳ“зҡ„зңӢеҮәжқҘпјҢеҶ…йғЁеҢ…еҗ«дёҖдёӘ comparator жҜ”иҫғеҷЁпјҲжҲ–еҖјиў«зҪ®дёәKeyзҡ„жҜ”иҫғеҷЁпјҢжҲ–жҳҜиў«зҪ®дёәеӨ–йғЁдј е…Ҙзҡ„жҜ”иҫғеҷЁпјүпјҢж №з»“зӮ№ root пјҲжҢҮеҗ‘зәўй»‘ж ‘зҡ„и·ҹз»“зӮ№пјүпјҢи®°еҪ•дҝ®ж”№ж¬Ўж•° modCount пјҲз”ЁдәҺеҜ№йӣҶеҗҲз»“жһ„жҖ§зҡ„жЈҖжҹҘе’ҢеүҚйқўж–Үз« иҜҙзҡ„дёҖж ·пјүпјҢиҝҳжңүдёҖдёӘйқҷжҖҒеҶ…йғЁзұ»пјҲе…¶е®һеҸҜд»ҘзҗҶи§ЈдёәдёҖдёӘж ‘з»“зӮ№пјүпјҢе…¶дёӯжңүеӯҳеӮЁй”®е’ҢеҖјзҡ„keyе’ҢvalueпјҢиҝҳжңүжҢҮеҗ‘е·Ұеӯ©еӯҗе’ҢеҸіеӯ©еӯҗзҡ„вҖңжҢҮй’ҲвҖқпјҢиҝҳжңүжҢҮеҗ‘зҲ¶з»“зӮ№зҡ„вҖңжҢҮй’ҲвҖқпјҢжңҖеҗҺиҝҳеҢ…жӢ¬дёҖдёӘж Үеҝ— colorпјҲиҝҷдёӘжҡӮж—¶дёҚз”ЁзҹҘйҒ“пјүгҖӮд№ҹе°ұжҳҜиҜҙпјҢдёҖдёӘrootжҢҮеҗ‘ж ‘зҡ„и·ҹз»“зӮ№пјҢиҖҢиҝҷдёӘи·ҹж №з»“зӮ№еҸҲй“ҫжҺҘдёәдёҖжЈөж ‘пјҢжңҖеҗҺйҖҡиҝҮиҝҷдёӘrootеҸҜд»ҘйҒҚеҺҶж•ҙдёӘж ‘гҖӮ
еӣӣгҖҒputж·»еҠ е…ғзҙ еҲ°йӣҶеҗҲдёӯ
еңЁдәҶи§ЈдәҶTreeMapзҡ„еҶ…йғЁз»“жһ„д№ӢеҗҺпјҢжҲ‘们еҸҜд»ҘзңӢзңӢд»–жҳҜжҖҺд№Ҳе°ҶдёҖдёӘе…ғзҙ з»“зӮ№жҢӮеҲ°ж•ҙжЈөж ‘дёҠзҡ„гҖӮз”ұдәҺputж–№жі•зҡ„жәҗз ҒжҜ”иҫғеӨҡпјҢиҜ·еӨ§е®¶ж…ўж…ўзңӢгҖӮ
public V put(K key, V value) {
Entry<K,V> t = root;
if (t == null) {
compare(key, key); // type (and possibly null) check
root = new Entry<>(key, value, null);
size = 1;
modCount++;
return null;
}
int cmp;
Entry<K,V> parent;
// split comparator and comparable paths
Comparator<? super K> cpr = comparator;
if (cpr != null) {
do {
parent = t;
cmp = cpr.compare(key, t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
else {
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
do {
parent = t;
cmp = k.compareTo(t.key);
if (cmp < 0)
t = t.left;
else if (cmp > 0)
t = t.right;
else
return t.setValue(value);
} while (t != null);
}
Entry<K,V> e = new Entry<>(key, value, parent);
if (cmp < 0)
parent.left = e;
else
parent.right = e;
fixAfterInsertion(e);
size++;
modCount++;
return null;
}
йҰ–е…ҲеҲӨж–ӯж №з»“зӮ№жҳҜеҗҰжҳҜз©әзҡ„пјҢеҰӮжһңжҳҜз©әзҡ„зӣҙжҺҘеҲӣе»әдёҖдёӘз»“зӮ№е№¶е°ҶparentиөӢnullпјҢе°Ҷе…¶дҪңдёәиҜҘж ‘зҡ„и·ҹз»“зӮ№пјҢиҝ”еӣһnullи·іиҝҮдҪҷдёӢд»Јз ҒгҖӮеҰӮжһңи·ҹз»“зӮ№дёҚжҳҜз©әзҡ„пјҢе°ұеҺ»еҲӨж–ӯ comparator жҳҜеҗҰдёәnullпјҲд№ҹе°ұжҳҜеҲӨж–ӯcomparatorзҡ„еҖјжҳҜй»ҳи®Өkeyзҡ„жҜ”иҫғеҷЁиҝҳжҳҜеӨ–йғЁдј е…Ҙзҡ„жҜ”иҫғеҷЁпјүпјҢеҰӮжһңcomparatorзҡ„еҖјжҳҜеӨ–йғЁдј е…Ҙзҡ„пјҢйҖҡиҝҮеҫӘзҺҜжҜ”иҫғkeyзҡ„еҖји®Ўз®—е°ҶиҰҒж·»еҠ зҡ„з»“зӮ№зҡ„дҪҚзҪ®пјҲиҝҮзЁӢдёӯеҰӮжһңеҸ‘зҺ°жңүжҹҗдёӘз»“зӮ№зҡ„keyеҖје’Ңе°ҶиҰҒж·»еҠ зҡ„keyзҡ„еҖјзӣёзӯүпјҢиҜҙжҳҺиҝҷжҳҜдҝ®ж”№ж“ҚдҪңпјҢдҝ®ж”№е…¶valueеҖјиҝ”еӣһж—§valueеҖјпјүгҖӮ
еҰӮжһңеңЁеҲӣе»әеҜ№иұЎзҡ„ж—¶еҖҷ并没жңүд»ҺеӨ–йғЁдј е…ҘжҜ”иҫғеҷЁпјҢйҰ–е…ҲеҲӨж–ӯkeyзҡ„еҖјжҳҜеҗҰдёәnullпјҲеҰӮжһңжҳҜе°ұжҠӣеҮәз©әжҢҮй’ҲејӮеёёпјүпјҢйӮЈжңүдәәиҜҙпјҡдёәд»Җд№ҲиҰҒеҜ№keyжҳҜеҗҰдёәз©әеҒҡеҲӨж–ӯе‘ўпјҹдёҠйқўдёҚжҳҜд№ҹжІЎжңүеҒҡеҲӨж–ӯд№Ҳпјҹ зӯ”жЎҲжҳҜпјҡеҰӮжһң comparator жҳҜеӨ–йғЁдј е…Ҙзҡ„пјҢйӮЈд№ҲжІЎй—®йўҳпјҢдҪҶжҳҜеҰӮжһңжҳҜkeyзҡ„й»ҳи®ӨжҜ”иҫғеҷЁпјҢйӮЈеҰӮжһңkeyдёәnull иҝҳиҰҒи°ғз”ЁжҜ”д»·еҷЁ еҝ…然жҠӣз©әжҢҮй’ҲејӮеёёгҖӮжҺҘдёӢжқҘеҒҡзҡ„дәӢжғ…е’ҢдёҠйқўдёҖж ·зҡ„гҖӮ
зЁӢеәҸжү§иЎҢеҲ°жңҖеҗҺдәҶпјҢжҲ‘们иҰҒзҹҘйҒ“дёҖзӮ№зҡ„жҳҜпјҡparentжҢҮеҗ‘зҡ„жҳҜжңҖеҗҺдёҖдёӘз»“зӮ№д№ҹе°ұжҳҜжҲ‘们е°ҶиҰҒж·»еҠ зҡ„з»“зӮ№зҡ„зҲ¶з»“зӮ№гҖӮжңҖеҗҺж №жҚ®keyе’Ңvalueе’ҢparentеҲӣе»әдёҖдёӘеҮ зӮ№пјҲзҲ¶з»“зӮ№жҳҜparentпјүпјҢ然еҗҺж №жҚ®дёҠйқўзҡ„еҲӨж–ӯзЎ®е®ҡжӯӨз»“зӮ№жҳҜparentзҡ„е·Ұеӯ©еӯҗиҝҳжҳҜеҸіеӯ©еӯҗгҖӮ
иҝҷдёӘж–№жі•дёӯжңүдёҖдёӘ fixAfterInsertion(e); жҳҜз”ЁдәҺзәўй»‘ж ‘зҡ„жһ„йҖ зҡ„пјҢи°ғз”ЁиҝҷдёӘеҮҪж•°еҸҜд»Ҙе°ҶжҲ‘们еҲҡеҲҡеҲӣе»әе®ҢжҲҗд№ӢеҗҺзҡ„ж ‘йҖҡиҝҮжҢӘеҠЁйҮҚж–°жһ„е»әжҲҗзәўй»‘ж ‘гҖӮ
жңҖеҗҺжҖ»з»“дёҖдёӢж•ҙдёӘputж–№жі•зҡ„жү§иЎҢиҝҮзЁӢпјҡ
е…¶дёӯпјҢжҲ‘们иҰҒеҢәеҲҶдёҖзӮ№зҡ„жҳҜпјҢдёәд»Җд№Ҳжңүж—¶еҖҷиҝ”еӣһзҡ„nullпјҢжңүж—¶еҖҷиҝ”еӣһзҡ„жҳҜж—§з»“зӮ№зҡ„valueпјҢдё»иҰҒеҢәеҲ«иҝҳжҳҜеңЁдәҺпјҢputж–№жі•дҪңдёәж·»еҠ е…ғзҙ е’Ңдҝ®ж”№е…ғзҙ зҡ„дёӨз§ҚеҠҹиғҪпјҢж·»еҠ е…ғзҙ зҡ„ж—¶еҖҷз»ҹдёҖиҝ”еӣһзҡ„жҳҜnullпјҢдҝ®ж”№е…ғзҙ зҡ„ж—¶еҖҷз»ҹдёҖиҝ”еӣһзҡ„жҳҜеҲ«дҝ®ж”№д№ӢеүҚзҡ„е…ғзҙ зҡ„valueгҖӮ
дә”гҖҒж №жҚ®й”®зҡ„еҖјеҲ йҷӨз»“зӮ№е…ғзҙ
ж·»еҠ е…ғзҙ зӣҙеҲ°жҳҜжҖҺд№ҲеӣһдәӢдәҶд№ӢеҗҺпјҢжҲ‘们жқҘзңӢзңӢеҲ йҷӨе…ғзҙ жҳҜжҖҺд№Ҳиў«е®һзҺ°зҡ„пјҢйҰ–е…ҲзңӢremoveж–№жі•пјҡ
public V remove(Object key) {
Entry<K,V> p = getEntry(key);
if (p == null)
return null;
V oldValue = p.value;
deleteEntry(p);
return oldValue;
}
д»Һд»Јз ҒдёӯеҸҜд»ҘзңӢеҮәжқҘпјҢеҲ йҷӨзҡ„ж“ҚдҪңдё»иҰҒиҝҳжҳҜдёӨдёӘж“ҚдҪңзҡ„з»“еҗҲпјҢдёҖдёӘжҳҜиҺ·еҸ–жҢҮе®ҡе…ғзҙ пјҢдёҖдёӘжҳҜеҲ йҷӨжҢҮе®ҡе…ғзҙ гҖӮжҲ‘们е…ҲзңӢеҰӮдҪ•иҺ·еҸ–жҢҮе®ҡе…ғзҙ гҖӮ
final Entry<K,V> getEntry(Object key) {
// Offload comparator-based version for sake of performance
if (comparator != null)
return getEntryUsingComparator(key);
if (key == null)
throw new NullPointerException();
@SuppressWarnings("unchecked")
Comparable<? super K> k = (Comparable<? super K>) key;
Entry<K,V> p = root;
while (p != null) {
int cmp = k.compareTo(p.key);
if (cmp < 0)
p = p.left;
else if (cmp > 0)
p = p.right;
else
return p;
}
return null;
}
иҝҷж®өд»Јз ҒдёҚйҡҫзҗҶи§ЈпјҢдҫқ然жҳҜеҲҶдёӨз§Қжғ…еҶөжҜ”иҫғеҷЁзҡ„жқҘжәҗпјҲз”ұдәҺдёӨз§Қжғ…еҶөдёӢзҡ„еӨ„зҗҶж–№ејҸзұ»дјјпјҢжӯӨеӨ„жҢҮе…·дҪ“иҜҙе…¶дёӯдёҖз§ҚпјүпјҢpжҢҮеҗ‘ж №з»“зӮ№rootпјҢеҫӘзҺҜйҒҚеҺҶпјҢжҜ”иҫғkeyе’ҢеҪ“еүҚеҫӘзҺҜеҲ°зҡ„keyжҳҜеҗҰзӣёзӯүпјҢдёҚзӣёзӯүе°ұж №жҚ®еӨ§е°Ҹеҗ‘е·ҰжҲ–иҖ…еҗ‘еҸіпјҢеҰӮжһңзӣёзӯүжү§иЎҢreturn p; иҝ”еӣһжӯӨз»“зӮ№гҖӮеҰӮжһңж•ҙжЈөж ‘йҒҚеҺҶе®ҢжҲҗд№ӢеҗҺпјҢжІЎжңүжүҫеҲ°жҢҮе®ҡй”®еҖјзҡ„з»“зӮ№е°ұдјҡиҝ”еӣһnullиЎЁзӨәжңӘжүҫеҲ°иҜҘз»“зӮ№гҖӮиҝҷе°ұжҳҜжҹҘжүҫж–№жі•пјҢдёӢйқўжҲ‘们зңӢзңӢеҲ йҷӨжҢҮе®ҡз»“зӮ№зҡ„ж–№жі•гҖӮ
еңЁзңӢд»Јз Ғд№ӢеүҚжҲ‘们е…ҲдәҶи§ЈдёҖдёӢж•ҙдҪ“зҡ„жҖқи·ҜпјҢе°ҶиҰҒеҲ йҷӨзҡ„з»“зӮ№еҸҜиғҪжңүд»ҘдёӢдёүз§Қжғ…еҶөпјҡ
第дёҖз§Қжғ…еҶөпјҢзӣҙжҺҘе°ҶиҜҘз»“зӮ№еҲ йҷӨпјҢ并е°ҶзҲ¶з»“зӮ№зҡ„еҜ№еә”еј•з”ЁиөӢеҖјдёәnull
第дәҢз§Қжғ…еҶөпјҢи·іиҝҮиҜҘз»“зӮ№е°Ҷе…¶зҲ¶з»“зӮ№жҢҮеҗ‘иҝҷдёӘеӯ©еӯҗз»“зӮ№
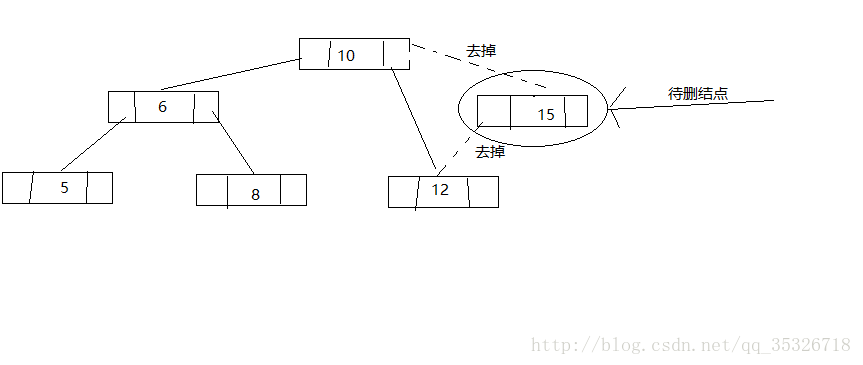
第дёүз§Қжғ…еҶөпјҢжүҫеҲ°еҫ…еҲ з»“зӮ№зҡ„еҗҺ继结зӮ№е°ҶеҗҺ继结зӮ№жӣҝжҚўеҲ°еҫ…еҲ з»“зӮ№е№¶еҲ йҷӨеҗҺ继结зӮ№пјҲе°Ҷй—®йўҳиҪ¬жҚўдёәеҲ йҷӨеҗҺ继结зӮ№пјҢйҖҡиҝҮеүҚйқўдёӨз§ҚеҸҜд»Ҙи§ЈеҶіпјү
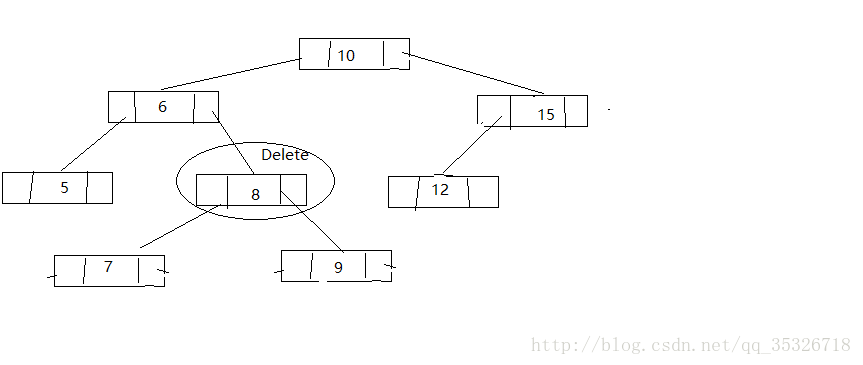
жүҫеҲ°еҗҺ继结зӮ№
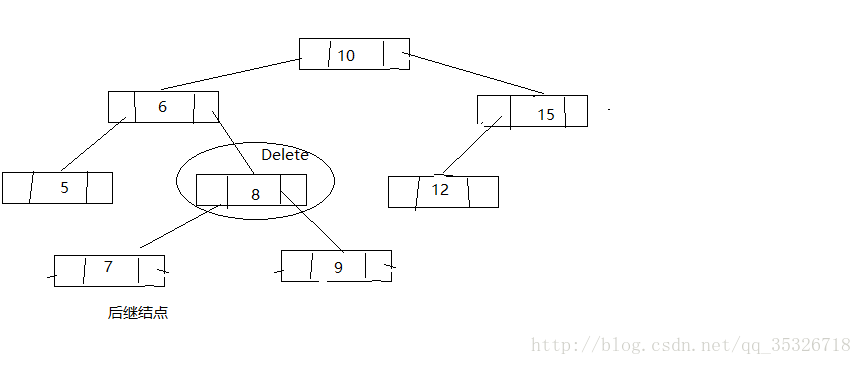
жӣҝжҚўеҫ…еҲ з»“зӮ№
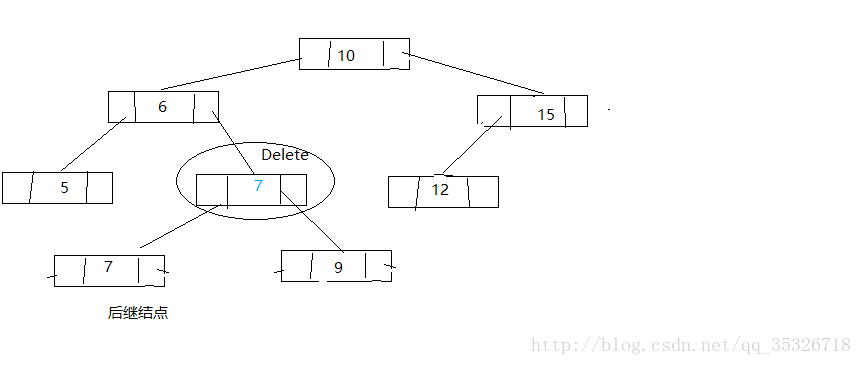
еҲ йҷӨеҗҺ继结зӮ№

дёӢйқўжҲ‘们зңӢд»Јз Ғпјҡ
/*д»Јз ҒиҷҪеӨҡпјҢжҲ‘们дёҖзӮ№дёҖзӮ№зңӢ*/
private void deleteEntry(Entry<K,V> p) {
modCount++;
size--;
// If strictly internal, copy successor's element to p and then make p
// point to successor.
if (p.left != null && p.right != null) {
Entry<K,V> s = successor(p);
p.key = s.key;
p.value = s.value;
p = s;
} // p has 2 children
// Start fixup at replacement node, if it exists.
Entry<K,V> replacement = (p.left != null ? p.left : p.right);
if (replacement != null) {
// Link replacement to parent
replacement.parent = p.parent;
if (p.parent == null)
root = replacement;
else if (p == p.parent.left)
p.parent.left = replacement;
else
p.parent.right = replacement;
// Null out links so they are OK to use by fixAfterDeletion.
p.left = p.right = p.parent = null;
// Fix replacement
if (p.color == BLACK)
fixAfterDeletion(replacement);
} else if (p.parent == null) { // return if we are the only node.
root = null;
} else { // No children. Use self as phantom replacement and unlink.
if (p.color == BLACK)
fixAfterDeletion(p);
if (p.parent != null) {
if (p == p.parent.left)
p.parent.left = null;
else if (p == p.parent.right)
p.parent.right = null;
p.parent = null;
}
}
}
йҰ–е…ҲпјҢеҲӨж–ӯеҫ…еҲ з»“зӮ№жҳҜеҗҰе…·жңүдёӨдёӘеӯ©еӯҗпјҢеҰӮжһңжңүи°ғз”ЁеҮҪж•° successorиҝ”еӣһеҗҺ继结зӮ№пјҢ并且жӣҝжҚўеҫ…еҲ з»“зӮ№гҖӮеҜ№дәҺиҝҷжқЎиҜӯеҸҘпјҡEntry>K,V< replacement = (p.left != null ? p.left : p.right); пјҢжҲ‘们дёҠиҝ°зҡ„дёүз§Қжғ…еҶөдёӢreplacementзҡ„еҸ–еҖјеҖјеҫ—з ”з©¶пјҢеҰӮжһңжҳҜ第дёҖз§Қжғ…еҶөпјҲеҸ¶еӯҗз»“зӮ№пјүпјҢйӮЈд№ҲreplacementеҸ–еҖјдёәnullпјҢиҝӣе…ҘдёӢйқўзҡ„еҲӨж–ӯпјҢ第дёҖдёӘifиҝҮпјҢ第дәҢдёӘеҲӨж–ӯеҫ…еҲ з»“зӮ№жҳҜеҗҰжҳҜж №з»“зӮ№пјҲеҸӘжңүж №з»“зӮ№зҡ„зҲ¶з»“зӮ№дёәnullпјүпјҢеҰӮжһңжҳҜиҜҙжҳҺж•ҙдёӘж ‘еҸӘжңүдёҖдёӘз»“зӮ№пјҢйӮЈд№ҲзӣҙжҺҘеҲ йҷӨеҚіеҸҜпјҢеҰӮжһңдёҚжҳҜж №з»“зӮ№е°ұиҜҙжҳҺжҳҜеҸ¶еӯҗз»“зӮ№пјҢжӯӨж—¶е°ҶзҲ¶з»“зӮ№иөӢеҖјдёәnull然еҗҺеҲ йҷӨеҚіеҸҜгҖӮ
еҜ№дәҺ第дәҢз§Қжғ…еҶөдёӢпјҲеҸӘжңүдёҖдёӘеӯ©еӯҗз»“зӮ№ж—¶еҖҷпјүпјҢжңҖдёҠйқўзҡ„ifиҜӯеҸҘжҳҜдёҚеҒҡзҡ„пјҢеҰӮжһңйӮЈдёҖдёӘз»“зӮ№жҳҜе·Ұеӯ©еӯҗ replacementдёәиҜҘз»“зӮ№пјҢ然еҗҺе°ҶжӯӨз»“зӮ№и·іиҝҮзҲ¶з»“зӮ№жҢӮеңЁеҫ…еҲ з»“зӮ№зҡ„дёӢйқўпјҢеҰӮжһңйӮЈдёҖдёӘеӯ©еӯҗжҳҜеҸіеӯ©еӯҗпјҢreplacementдёәиҜҘз»“зӮ№пјҢеҗҢж ·ж“ҚдҪңгҖӮ
第дёүз§Қжғ…еҶөпјҲеҫ…еҲ з»“зӮ№е…·жңүдёӨдёӘеӯ©еӯҗз»“зӮ№пјүпјҢйӮЈиӮҜе®ҡжү§иЎҢжңҖжңҖдёҠйқўзҡ„ifиҜӯеҸҘдёӯд»Јз ҒпјҢжүҫеҲ°еҗҺ继结зӮ№жӣҝжҚўеҫ…еҲ з»“зӮ№пјҲеҗҺ继结зӮ№дёҖе®ҡжІЎжңүе·Ұеӯ©еӯҗпјүпјҢжҲҗеҠҹзҡ„е°Ҷй—®йўҳиҪ¬жҚўдёәеҲ йҷӨеҗҺ继结зӮ№пјҢеҸҲеӣ дёәеҗҺ继结зӮ№дёҖе®ҡжІЎжңүе·Ұеӯ©еӯҗпјҢж•ҙдёӘй—®йўҳе·Із»Ҹиў«иҪ¬жҚўжҲҗдёҠиҝ°дёӨз§Қжғ…еҶөдәҶпјҢпјҲеҒҮеҰӮеҗҺ继结зӮ№жІЎжңүеҸіеӯ©еӯҗе°ұжҳҜ第дёҖз§ҚпјҢеҒҮеҰӮжңүе°ұжҳҜ第дәҢз§ҚпјүжүҖд»Ҙreplacement = p.rightпјҢдёӢйқўеҲҶжғ…еҶөеӨ„зҗҶгҖӮеҲ йҷӨж–№жі•з»“жқҹгҖӮ
е°Ҹз»“дёҖдёӢпјҢеҲ йҷӨз»“зӮ№йҡҫзӮ№еңЁдәҺеҲ йҷӨжҢҮе®ҡй”®еҖјзҡ„з»“зӮ№пјҢдё»иҰҒеҲҶдёәдёүз§Қжғ…еҶөпјҢеҸ¶еӯҗз»“зӮ№пјҢдёҖдёӘеӯ©еӯҗз»“зӮ№пјҢдёӨдёӘеӯ©еӯҗз»“зӮ№гҖӮиҖҢеҜ№дәҺдёҚеҗҢзҡ„жғ…еҶөпјҢjdkзј–еҶҷиҖ…е°ҶжңҖйҡҫзҡ„дёӨдёӘеӯ©еӯҗз»“зӮ№иҪ¬жҚўдёәеүҚдёӨз§Қиҫғдёәз®ҖеҚ•зҡ„ж–№ејҸпјҢеҸҜи§ҒеӨ§зҘһд№ӢдҪңгҖӮй’ҰдҪ©гҖӮ
ж„ҹи°ўйҳ…иҜ»пјҢеёҢжңӣиғҪеё®еҠ©еҲ°еӨ§е®¶пјҢи°ўи°ўеӨ§е®¶еҜ№жң¬з«ҷзҡ„ж”ҜжҢҒпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ