您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍用Python爬取彩票信息的步骤,文中示例代码介绍的非常详细,具有一定的参考价值,感兴趣的小伙伴们一定要看完!
一、爬取网页数据所使用到的库
1、获取网络请求
requests、BeautifulSoup
2、写入excel文件
openpyxl、pprint、column_index_from_string
注意column_index_from_string是openpyxl.utils的子库
二、详细处理
1、第一步我们要考虑的自然是将要爬取的url获取,并使用get方法发起请求,返回接收的内容使用BeautifulSoup进行处理。为了方便重复利用,将其封装到函数体当中
def get_soup(url): response = requests.get(url) soup = BeautifulSoup(response.text, 'lxml') return soup
2、返回soup对象,利用soup对象找出网页源码中的详细信息
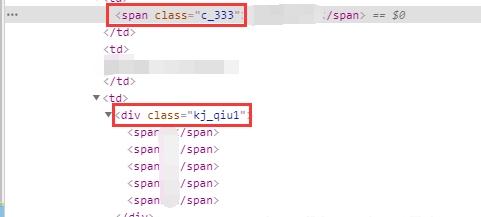
# 准备空列表用于存放期号和中奖号码
info = []
num = []
def run_url(url):
global info, num, qihao, zhongjiang
res = get_soup(url) # 返回soup对象
# 获取期号和中奖号码数据
qihao = res.find_all('span', class_='c_333')
zhongjiang = res.find_all('div', class_='kj_qiu1')
# 期号列表
for i in qihao:
info.append(str(i.text))
# 中奖号码
for i in zhongjiang:
a = i.text.split('\n')
num.append(a)调用函数找到具体代码块中的数据之后,将其进行适当处理分别添加到期号列表和中奖号码列表中,进行存储
3、简单循环批量访问url,并自动去替换页数
for i in range(1, 101):
url = '相应的URL,p=%s'%i
run_url(url)
# 将最后的数据进行压缩处理成字典格式存储,写入单独文件当中
data = dict(zip(info,num))
response = open(r'D:\res_data.py', 'w', encoding='utf-8')
response.write('allData=' + pprint.pformat(data))
print('写入结束')三、使用生成的文件中的数据,写入excel文件当中
1、先创建工作簿对象,将excel的sheet的格式提前设置
import openpyxl import res_data # 写入excel表格 # 创建新的工作簿 wb = openpyxl.Workbook() sheet = wb.active sheet.title = 'Data' ws = wb['Data'] # 选中表单 ws.cell(row = 1, column = 1).value = '期号' ws.cell(row = 1, column = 2).value = '中奖号码' # 设置列宽 ws.column_dimensions['A'].width = 20 ws.column_dimensions['D'].width = 20
2、将期号写入文件
# 写入期号 num = [] for key in res_data.allData.keys(): num.append(key) num_sort = num[::-1] for rowNum in range(2, len(res_data.allData)+2): ws.cell(row = rowNum, column = 1).value = num_sort[rowNum-2]
3、写入中奖号码
# 写入中奖号码
num_zhong = []
for value in res_data.allData.values():
num_zhong.append(''.join(value))
num_zhong_sort = num_zhong[::-1]
for rowNum in range(2, len(res_data.allData)+2):
ws.cell(row = rowNum, column = 2).value = num_zhong_sort[rowNum-2]4、计算某一位的中间概率,并分析前一期的概率
# 万位
count0_0, count0_1, count0_2, count0_3, count0_4, count0_5, count0_6, count0_7,count0_8,count0_9= 0,0,0,0,0,0,0,0,0,0
for i in num_zhong:
# 万位
if i[0] == '0':
count0_0 += 1
elif i[0] == '1':
count0_1 += 1
elif i[0] == '2':
count0_2 += 1
elif i[0] == '3':
count0_3 += 1
elif i[0] == '4':
count0_4 += 1
elif i[0] == '5':
count0_5 += 1
elif i[0] == '6':
count0_6 += 1
elif i[0] == '7':
count0_7 += 1
elif i[0] == '8':
count0_8 += 1
elif i[0] == '9':
count0_9 += 1
# 万位
res0_0, res0_1 = round(count0_0/len(num_zhong)*100,2) ,round(count0_1/len(num_zhong)*100,2)
res0_2, res0_3 = round(count0_2/len(num_zhong)*100,2) ,round(count0_3/len(num_zhong)*100,2)
res0_4, res0_5 = round(count0_4/len(num_zhong)*100,2) ,round(count0_5/len(num_zhong)*100,2)
res0_6, res0_7 = round(count0_6/len(num_zhong)*100,2) ,round(count0_7/len(num_zhong)*100,2)
res0_8, res0_9 = round(count0_8/len(num_zhong)*100,2) ,round(count0_9/len(num_zhong)*100,2)
res_wan = {
'0':res0_0,
'1':res0_1,
'2':res0_2,
'3':res0_3,
'4':res0_4,
'5':res0_5,
'6':res0_6,
'7':res0_7,
'8':res0_8,
'9':res0_9
}
max_wan = res_wan['0']
max_key = 0
for key in res_wan.keys():
if res_wan[key] > max_wan:
max_wan = res_wan[key]
max_key = key
zhongjiang = dict(zip(num[::-1], num_zhong[::-1]))
zj_qihao = []
zj_qianyiqi = []
zj_num = []
zj_qnum = []
for key, value in zhongjiang.items():
#print(key, value)
if int(value[0]) == max_key:
qihao = int(key)
#print(qihao, value)
qianyiqi = str(qihao - 1)
if qihao and qianyiqi in zhongjiang:
zj_qihao.append(qihao)
zj_num.append(zhongjiang[str(qihao)])
zj_qianyiqi.append(qianyiqi)
zj_qnum.append(zhongjiang[qianyiqi])
# 计算前一期概率
count0_zjq ,count1_zjq,count2_zjq,count3_zjq,count4_zjq,count5_zjq,count6_zjq,count7_zjq,count8_zjq,count9_zjq= 0,0,0,0,0,0,0,0,0,0
for i in zj_qnum:
if i[0] == '0':
count0_zjq += 1
elif i[0]=='1':
count1_zjq += 1
elif i[0]=='2':
count2_zjq += 1
elif i[0]=='3':
count3_zjq += 1
elif i[0]=='4':
count4_zjq += 1
elif i[0]=='5':
count5_zjq += 1
elif i[0]=='6':
count6_zjq += 1
elif i[0]=='7':
count7_zjq += 1
elif i[0]=='8':
count8_zjq += 1
elif i[0]=='9':
count9_zjq += 1
res0_zjq,res1_zjq = round(count0_zjq/len(zj_qnum),2),round(count1_zjq/len(zj_qnum),2)
res2_zjq,res3_zjq = round(count2_zjq/len(zj_qnum),2),round(count3_zjq/len(zj_qnum),2)
res4_zjq,res5_zjq = round(count4_zjq/len(zj_qnum),2),round(count5_zjq/len(zj_qnum),2)
res6_zjq,res7_zjq = round(count6_zjq/len(zj_qnum),2),round(count7_zjq/len(zj_qnum),2)
res8_zjq,res9_zjq = round(count8_zjq/len(zj_qnum),2),round(count9_zjq/len(zj_qnum),2)\
# 计算最大概率
probability = [res0_zjq,res1_zjq,res2_zjq,res3_zjq,res4_zjq,res5_zjq,res6_zjq,res7_zjq,res8_zjq,res9_zjq]
max_probability = probability[0] # 最大概率
max_probability_num = 0 # 最大概率数字
for i in range(len(probability)):
if probability[i] > max_probability:
max_probability = probability[i]
max_probability_num = i
ws.cell(row = 1, column = 4).value = '万位最大概率数字'
ws.cell(row = 1, column = 5).value = '概率'
ws.cell(row = 2, column = 4).value = max_key
ws.cell(row = 2, column = 5).value = max_wan
ws.cell(row = 3, column = 4).value = '前一期万位最大概率'
ws.cell(row = 4, column = 4).value = max_probability_num
ws.cell(row = 4, column = 5).value = max_probability*100
for i in probability:
print(i)
for row in range(len(probability)):
ws.cell(row=row + 5, column=4).value = row
ws.cell(row=row + 5, column=5).value = probability[row]*100
wb.save(filename='D:/caipiao.xlsx')
print('Write Over!')
4、保存文件即可
wb.save(filename='指定路径文件')
print('Write Over!')以上是用Python爬取彩票信息的步骤的所有内容,感谢各位的阅读!希望分享的内容对大家有帮助,更多相关知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。