您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关python做数据清洗的方法,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
1.数据清洗的代码:
import pandas as pd
import numpy as np
# 创建空的df,保存测试数据
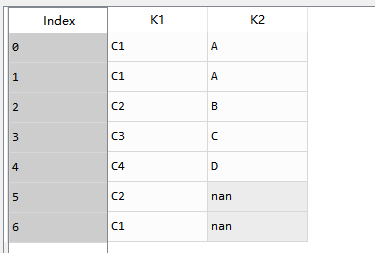
test_df = pd.DataFrame({'K1':['C1','C1','C2','C3','C4','C2','C1'],'K2':['A','A','B','C','D',np.NaN,np.NaN]})
# 按K1列进行分组,组内进行unique操作(去除重复元素,返回元组或列表)
test_df_unique = pd.DataFrame(test_df.groupby(['K1'])['K2'].agg('unique'))
# 自定义函数判断元组中是否含有nan
def has_nan(list):
flag = False
for x in list:
if x is np.NaN:
flag = True
break
return flag
# 自定义函数判断元组中是否不含有nan
def no_nan(list):
flag = True
for x in list:
if x is np.NaN:
flag = False
break
return flag
# 获取k2列含有nan的数据
test_df_unique_has_nan = test_df_unique[test_df_unique['K2'].apply(has_nan)]
# 获取k2列不含有nan的数据
test_df_unique_no_nan = test_df_unique[test_df_unique['K2'].apply(no_nan)]
# 管理测试数据,获取源数据
test_df_get = test_df[test_df['K1'].isin(test_df_unique_has_nan.index.tolist())]
test_df_alone = test_df[test_df['K1'].isin(test_df_unique_no_nan.index.tolist())]
# 去除含nan的重复数据
test_df_get_nonan = test_df_get[~test_df_get['K2'].isna()]
# 组合数据
result = test_df_get_nonan.append(test_df_alone)
# 去重,得到最终结果
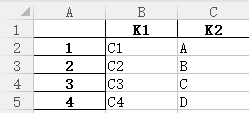
result_save = result.drop_duplicates(subset=['K1','K2'],keep='last')
# 结果落地
result_save.to_excel('C:/Users/zhen/Desktop/数据清洗之去重.xlsx')2、测试数据:
3、结果:
关于python做数据清洗的方法就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。