您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下python中处理异常值的方法,希望大家阅读完这篇文章后大所收获,下面让我们一起去探讨吧!
打开pycharm开发工具,在运行窗口输入命令:
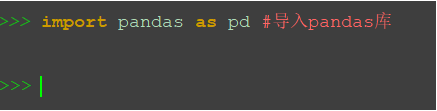
import pandas as pd #导入pandas库
输入数据集。
data=pd.DataFrame({'name':['A','B','C','D','E','F','G'],'cost':[2,127,4,6,3,13,14],'sales':[13,18,32,54,23,33,44]})
print(data)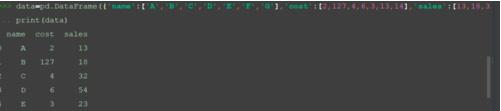
通过z-score方法判断异常值,即对原始值X进行正态标准化:(X-mean(X))/std(X),根据计算的结果判断样本值与中心的偏离程度。
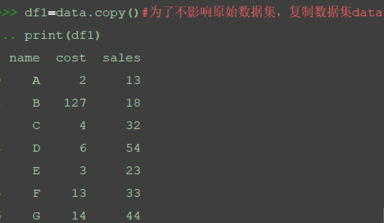
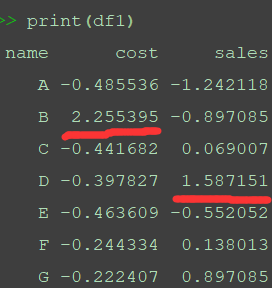
df1=data.copy()#为了不影响原始数据集,复制数据集data print(df1)
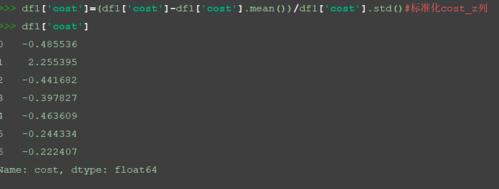
按列计算均值和标准差。
df1['cost']=(df1['cost']-df1['cost'].mean())/df1['cost'].std()#标准化cost_z列
对sales列进行标准化。
df1['sales']=(df1['sales']-df1['sales'].mean())/df1['sales'].std()#标准化cost_z列 df1['sales']
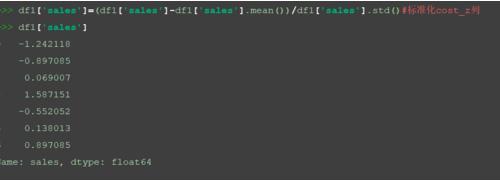
查看标准化后的数据集。
print(df1)
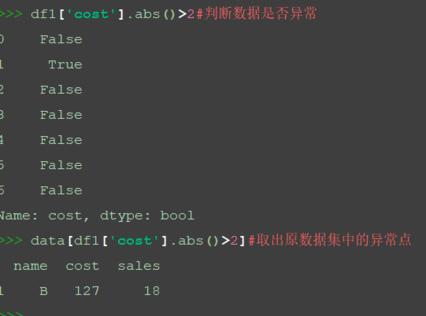
标准化后的绝对值越大,数据越有可能异常,是否异常根据设定的阈值判断。
假设cost列阈值为2,通过下面的方法找到异常值。
df1['cost'].abs()>2#判断数据是否异常 data[df1['cost'].abs()>2]#取出原数据集中的异常点
看完了这篇文章,相信你对python中处理异常值的方法有了一定的了解,想了解更多相关知识,欢迎关注亿速云行业资讯频道,感谢各位的阅读!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。