您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关Python中小数据存储方式有哪些,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
小数据存储
我们在编写代码的时候,经常会涉及到数据存储的情况,如果是爬虫得到的大数据,我们会选择使用数据库,或者excel存储。但如果只是一些小数据,或者说关联性较强且存在存储后复用的数据,我们该如何存储呢?
使用open保存文本
最简单、粗暴+无脑的存储方式就是保存成一个文本文档了。
使用open函数,将结果一行行的保存成文本,这里涉及的知识点只有简单的几条:
·文件读写模式,r 、w、a、b、+,掌握这几种即可。
·使用单独的open打开文件时,需要注意结尾时的调用close()函数关闭文档。
·推荐使用上下文管理器的with open操作。
csv文件
之所以将csv与excel分开说,首先需要扫盲下,csv属于特定格式的文本文件(使用逗号分隔),而excel是二进制文件。
csv可以直接使用文本编辑器打开,excel不行。
其实csv文件,完全可以使用open函数进行保存,只要你将每行数据都使用,分隔开即可。
另外,python自带csv库,可以很方便的操作与保存该数据。
xml文件
xml文件的方式,已经逐渐被淘汰了,为什么这么说?因为它繁琐的树形结构,导致了在传输过程中,占用了更多的内存。所以,除非必要,真的不推荐以xml的形式存储你的数据。
configparser
python模块中configparser是一个专门用来保存配置文件的模块库,它非常适合保存一些具有关联性的数据内容,尤其是配置文件。通过定义section的方式,在section中添加key:value的方式,可以直观明了的数据内容。我之前专门写了一篇关于它的文章,会附在公众号的字文章中,喜欢的朋友可以去看看。
pyyaml
yaml类型的文件已经成为很多Linux下的主流配置文件类型,比如Docker、Ansible等等都在使用yaml,但它依然不是一个主流的数据存储方式,因为yaml本身的格式要求太过严苛,比结构化的Python格式更为严格,喜欢的朋友可以去研究下。
pickle
pickle模块的使用面很窄,但不得不说还是有些人会使用,所以简单说些它的优劣:
优势:接口简单(与json相似);存储格式通用型,及在Windows、Linux等平台下通用;二进制存储,效率高。
劣势:pickle是python特定的协议,其他语言无法使用;pickle存在安全性,这个要着重说下,看下图:
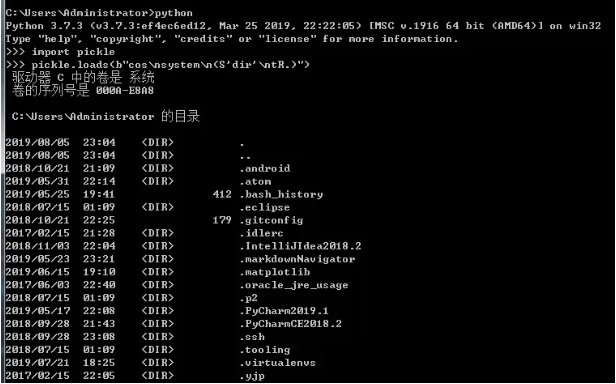
pickle安全性
Json文件
说了上面那么多,压轴的还是Json!
首先相对于xml,现在更多的网站在数据传输中使用json格式,因为同等的字节下,json传输数据的效率要更高于xml。

对于configparser,configparser有一个巨大的劣势,在于配置文件只能支持二维,section下定义option(key:value),如果想在option的value中再次定义列表、字典等数据类型,它只能识别为字符串,你需要将str手动再转化为对应的数据类型。
而针对ymal,json没有那么严格的格式要求,写做一行还是换行展示都随你,没有那么严苛的要求。
最后对比pickle,json格式是各种编程语言通用的数据格式,由于是key value的键值对,不存在loads之后的安全问题。而且你学会了json,也就学会了pickle,因为二者的使用方式一毛一样啊!
三分钟学会Json
1.简介
JSON(JavaScript Object Notation, JS 对象简谱) 是一种轻量级的数据交换格式。它基于 ECMAScript (欧洲计算机协会制定的js规范)的一个子集,采用完全独立于编程语言的文本格式来存储和表示数据。简洁和清晰的层次结构使得 JSON 成为理想的数据交换语言。易于人阅读和编写,同时也易于机器解析和生成,并有效地提升网络传输效率。
至于推荐使用Json的理由:
·Json格式是一种通用的数据类型
·Python内置json模块,便于操作
·json格式类似于python的dict
·json的保存与读取极为方便
·学习成本低,3分钟包教包会
2.类型、语法说明
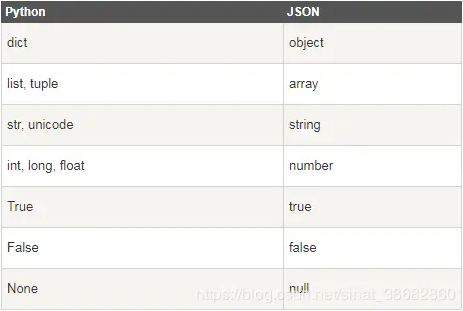
看到上图的Python与json对比关系,其实差异并不大,我们只需要注意几点即可:
·json的数据为key:value,且以逗号分隔,但注意json使用双引号包裹键值对
·花括号中保存为对象,而方括号保存的是数组,不论python是list还是tuple,最终都会转化为数组
·json由于是js引申的数据类型,所以在布尔表达式与空值上,使用与python不同,需要注意
3.json的方法
·dump():将python对象序列化到一个文件,是文本文件,相当于将序列化后的json字符写到一个文件
·load():从文件反序列表出python对象
·json和pickle相同,都只有四个方法:
·dumps():将python对象编码为json的字符串
·loads():将字符串编码为一个python对象
即:带s的方法是数据类型间的转化str <--> dict,不带s的都是数据与文件的转化。
4.实例说明
在演示前,我们需要先定义一个初始化数据:
data = {
"in_use": True,
"info": {
"name_cn": 'Python',
"name_en": "BreezePython",
},
"contents": ["Python", "Java", "Linux"]
}5.dumps() .loads()
import json
json.dumps(data)
>>> '{"in_use": true, "info": {"name_cn": "\\u6e05\\u98cePython", "name_en": "BreezePython"}, "contents":
["Python",
"Java", "Linux"]}'
#这里大家看到一个问题,中文异常,此时我们需要添加参数ensure_ascii=False
json.dumps(data,ensure_ascii=False)
>>> '{"in_use": true, "info": {"name_cn": "Python", "name_en": "BreezePython"}, "contents": ["Python",
"Java", "Linux"]}'
# 当然我们可以美观的打印它
json_data = json.dumps(data, sort_keys=True, indent=4, separators=(',', ': '),ensure_ascii=False)
print(json_data)
>>> {
"contents": [
"Python",
"Java",
"Linux"
],
"in_use": true,
"info": {
"name_cn": "Python",
"name_en": "BreezePython"
}
}
# 了解了dumps,loads就比较简单了...
json.loads(json_data)
{'contents': ['Python', 'Java', 'Linux'], 'in_use': True, 'info': {'name_cn': 'Python', 'name_en':
'BreezePython'}}6.dump() .load()
import json
# 先来看看dump将数据保存至文本
with open('data.json', 'w', encoding='utf-8') as f:
json.dump(data, f, indent=4)
# 同理我们还可以使用dumps完成写入操作
# f.write(json.dumps(data, indent=4))
# 保存了文本,我们在通过load读取出来
with open('data.json', 'r', encoding='utf-8') as f:
data = json.load(f)
# 同理我们还可以使用loads完成读取操作
# data = json.loads(f.read())
print(data)
>>>{'in_use': True, 'info': {'name_cn': 'Python', 'name_en': 'BreezePython'}, 'contents': ['Python', 'Java',
'Linux']}关于Python中小数据存储方式有哪些就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。