жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іpythonеҰӮдҪ•е®һзҺ°зҲ¬еҸ–дёӯеӣҪеүҚ20еӨ§еӯҰжҺ’еҗҚжЎҲдҫӢпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒдёӯеӣҪеӨ§еӯҰжҺ’еҗҚзҲ¬иҷ«жЎҲдҫӢзҡ„жӯҘйӘӨеҰӮдёӢпјҡ
жӯҘйӘӨ1пјҡд»ҺзҪ‘з»ңдёҠиҺ·еҸ–еӨ§еӯҰжҺ’еҗҚзҪ‘йЎөеҶ…е®№ getHTMLText()
жӯҘйӘӨ2пјҡжҸҗеҸ–зҪ‘йЎөеҶ…е®№дёӯдҝЎжҒҜеҲ°еҗҲйҖӮзҡ„ж•°жҚ®з»“жһ„ fillUnivList()
жӯҘйӘӨ3пјҡеҲ©з”Ёж•°жҚ®з»“жһ„еұ•зӨә并иҫ“еҮәз»“жһң printUnivList()

е®һдҫӢд»Јз Ғ
import requests
import bs4
from bs4 import BeautifulSoup
def getHTMLText(url):
'''д»ҺзҪ‘з»ңдёҠиҺ·еҸ–еӨ§еӯҰжҺ’еҗҚзҪ‘йЎөеҶ…е®№'''
try:
r = requests.get(url, timeout=30)
# #еҰӮжһңзҠ¶жҖҒдёҚжҳҜ200пјҢе°ұдјҡеј•еҸ‘HTTPErrorејӮеёё
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return ""
def fillUnivList(ulist, html):
'''жҸҗеҸ–зҪ‘йЎөеҶ…е®№дёӯдҝЎжҒҜеҲ°еҗҲйҖӮзҡ„ж•°жҚ®з»“жһ„'''
soup = BeautifulSoup(html, "html.parser")
# жҹҘжүҫhtmlдёӯtbodyж Үзӯҫзҡ„жүҖжңү<tr>еӯҗж Үзӯҫ
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
# tds[0].string жҳҜжҺ’еҗҚпјҢtds[1].string жҳҜеӯҰж ЎеҗҚз§°пјҢtds[3].string жҳҜеӯҰж Ўзҡ„жҖ»еҲҶ
ulist.append([tds[0].string, tds[1].string, tds[3].string])
def printUnivList(ulist, num):
''' жү“еҚ°еүҚ num еҗҚзҡ„еӨ§еӯҰ'''
# {1:{3}^10} дёӯзҡ„ {3} д»ЈиЎЁеҸ–第дёүдёӘеҸӮж•°
tplt = "{0:^10}\t{1:{3}^10}\t{2:^10}"
print(tplt.format("жҺ’еҗҚ","еӯҰж ЎеҗҚз§°","жҖ»еҲҶ",chr(12288))) # chr(12288) д»ЈиЎЁдёӯж–Үз©әж ј
for i in range(num):
u=ulist[i]
print(tplt.format(u[0],u[1],u[2],chr(12288))) # chr(12288) д»ЈиЎЁдёӯж–Үз©әж ј
def main():
uinfo = []
url = 'http://www.zuihaodaxue.cn/zuihaodaxuepaiming2019.html'
html = getHTMLText(url)# иҺ·еҸ–еӨ§еӯҰжҺ’еҗҚзҪ‘йЎөеҶ…е®№
fillUnivList(uinfo, html)#жҸҗеҸ–зҪ‘йЎөеҶ…е®№дёӯдҝЎжҒҜ
printUnivList(uinfo, 20) #иҫ“еҮәз»“жһң
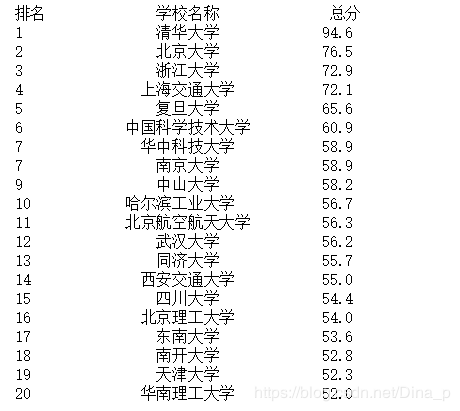
main()з»“жһңеҰӮдёӢ
е…ідәҺpythonеҰӮдҪ•е®һзҺ°зҲ¬еҸ–дёӯеӣҪеүҚ20еӨ§еӯҰжҺ’еҗҚжЎҲдҫӢе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ