您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这期内容当中小编将会给大家带来有关Python解释为什么百度已死,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
Python3爬虫百度一下,坑死你?
一、写在前面
这个标题是借用的路人甲大佬的一篇文章的标题(百度一下,坑死你),而且这次的爬虫也是看了这篇文章后才写出来的,感兴趣的可以先看下这篇文章。
前段时间有篇文章《搜索引擎百度已死》引起了很多讨论,而百度对此的回复是:百家号的内容在百度搜索结果中不超过10%。但是这个10%是第一页的10%还是所有数据的10%,我们不得而知,但是由于很多人都只会看第一页的内容,而如果这第一页里有十分之一的内容都来自于百家号,那搜索体验恐怕不怎么好吧?然后我这次写的爬虫就是把百度上面的热搜事件都搜索一下,然后把搜索结果的第一页上的标题链接提取出来,最后对这些链接进行一些简单的分析,看看百家号的内容占比能有多少。
二、具体步骤
1.页面分析
首先打开网页查看百度的热点事件,页面如下:
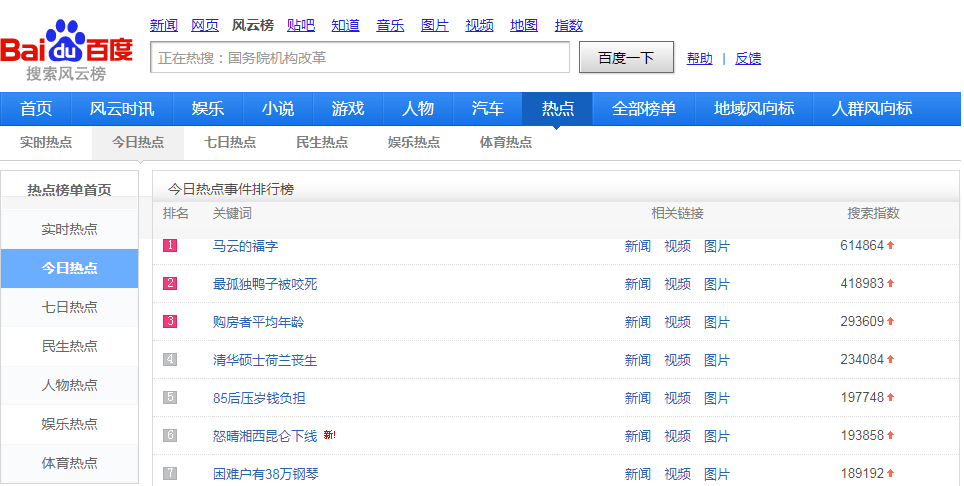
这次我主要对今日热点、娱乐热点、体育热点进行了爬取,每个热点下面有50条热点事件,然后对每个事件进行搜索,比如第一条--马云的福字:
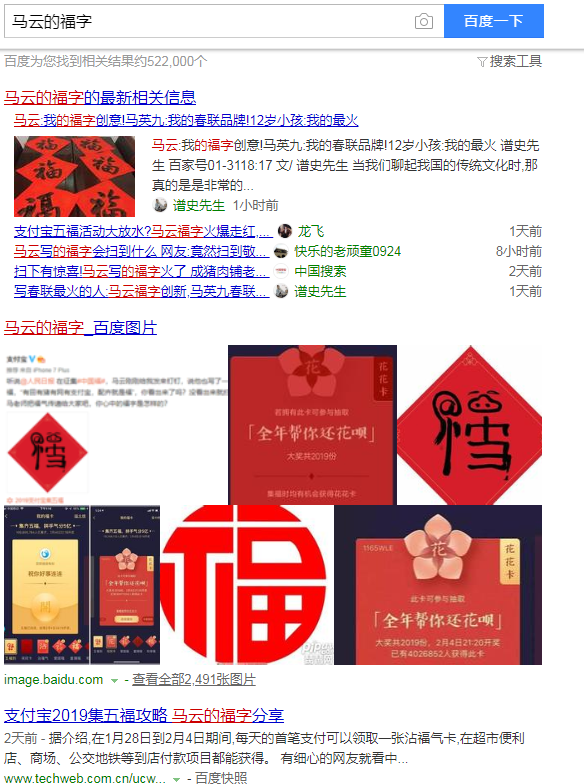
可以看到搜索结果的第一页上有很多标题,然后对这些标题的链接进行爬取,再保存到一个txt文件里,最后对这些数据进行分析。
2.主要代码
(1)获取真实链接
这些搜索结果页面上的链接都是经过加密的,如下图:
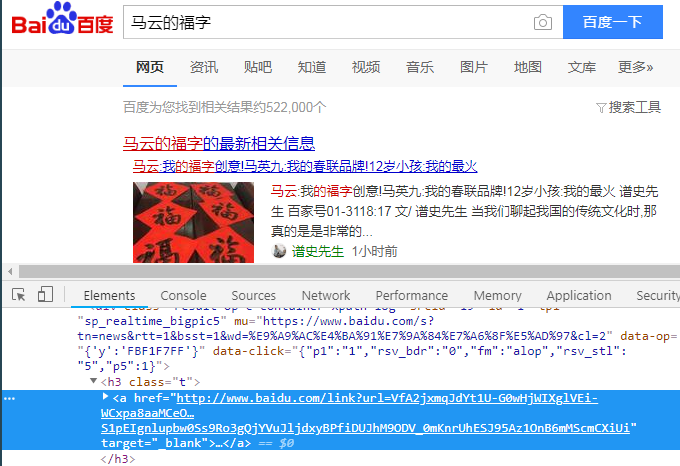
所以我们爬取得到的链接都是http://www.baidu.com/link?url=VfA2jxmqJdYt1U-G0wHjWIXglVEi-WCxpa8aaMCeOzkqK-c5CgYngPiJT6_-kmWE3ePTHCpgYlX5oq9SQDJgEukKCY19o26JlS1pEIgnlupbw0Ss9Ro3gQjYVuJljdxyBPfiDUJhM9ODV_0mKnrUhESJ95Az1OnB6mMScmCXiUi这种,但是我们点进去之后就能得到真实的链接https://www.baidu.com/s?tn=news&rtt=1&bsst=1&wd=%E9%A9%AC%E4%BA%91%E7%9A%84%E7%A6%8F%E5%AD%97&cl=2&origin=ps,那我们要怎么得到真实的链接呢?相关代码如下:
def get_real_url(self, fake_url): # 获取真实的链接 try: res = requests.get(fake_url, headers=self.headers) real_url = res.url except Exception as e: print(e)
(2)数据处理
这里我总共爬取了1051条链接,如下图:
但是这样的数据是明显没有办法进行分析的,所以需要进行一下处理,比如将https://baijiahao.baidu.com/s?id=1624053575252859170&wfr=spider&for=pc变成baijiahao.baidu,相关代码如下:
href = "https://baijiahao.baidu.com/s?id=1624053575252859170&wfr=spider&for=pc"
match = re.match("(http[s]?://.+?[com,cn,net]/)", href)
href = match.group()
href = href.replace('cn', 'com').replace('net', 'com')
href = href[href.index(':') + 3:].rstrip('.com/')
print(href)
# baijiahao.baidu(3)数据分析
这里主要使用了matplotlib绘图帮助我们分析数据。首先需要统计出各个网站出现的次数,然后进行一个排序,得到排名前十的网站,结果如下(前面是网站,后面是出现次数):
https://baijiahao.baidu.com/ 188 https://www.baidu.com/ 114 http://www.sohu.com/ 60 https://news.china.com/ 29 http://www.guangyuanol.cn/ 27 http://image.baidu.com/ 24 http://3g.163.com/ 20 https://sports.qq.com/ 19 https://www.iqiyi.com/ 17 https://baike.baidu.com/ 17
可以看到百家号出现的次数是最多的。然后进行绘图分析,这里主要是绘图的代码,因为使用的是百分数,所以在绘图的时候会稍微麻烦一点:
def plot(self, index_list, value_list):
b = self.ax.barh(range(len(index_list)), value_list, color='blue', height=0.8)
# 添加数据标签
for rect in b:
w = rect.get_width()
self.ax.text(w, rect.get_y() + rect.get_height() / 2, '{}%'.format(w),
ha='left', va='center')
# 设置Y轴刻度线标签
self.ax.set_yticks(range(len(index_list)))
self.ax.set_yticklabels(index_list)
# 设置X轴刻度线
lst = ["{}%".format(i) for i in range(0, 20, 2)]
self.ax.set_xticklabels(lst)
plt.subplots_adjust(left=0.25)
plt.xlabel("占比")
plt.ylabel("网站")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.savefig("bjh.jpg")
print("已保存为bjh.jpg!")三、运行结果
由于每个事件的搜索结果都是不同的,所以在解析网页的时候可能会出错,然后就是请求频率太高了会被ban掉,而且有时候UA会被识别出来然后就被ban掉了,运行情况如下图:
最后看一下绘制出来的图片:
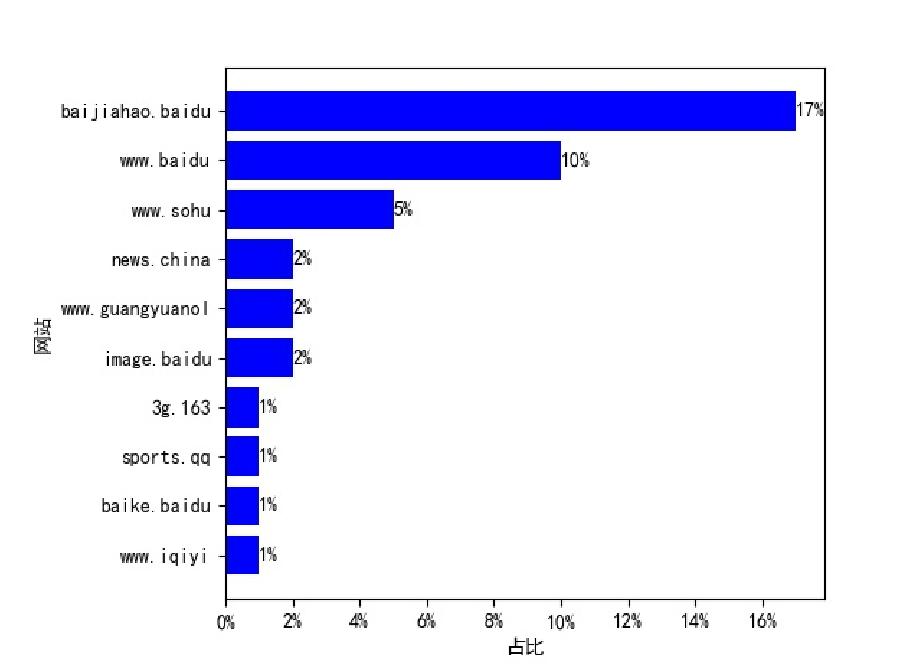
可以看到百家号的内容占比达到了17%,而排在第二的也是百度自家的产品,内容占比也达到了10%。当然了,由于搜索的都是百度上的热搜事件,所以得到的结果百度自家的内容会多一点,但是光百家号的内容就占了17%,是不是也太多了点呢?
上述就是小编为大家分享的Python解释为什么百度已死了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。