您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Operator是指一类基于Kubernetes自定义资源对象(CRD)和控制器(Controller)的云原生拓展服务,其中CRD定义了每个operator所创建和管理的自定义资源对象,Controller则包含了管理这些对象所相关的运维逻辑代码。
对于普通用户来说,如果要在k8s集群中部署一个高可用的etcd集群,那么不仅要了解其相关的配置,同时又需要特定的etcd专业知识才能完成维护仲裁,重新配置集群成员,创建备份,处理灾难恢复等等繁琐的事件。
而在operator这一类拓展服务的协助下,我们就可以使用简单易懂的YAML文件(同理参考Deployment)来声明式的配置,创建和管理我们的etcd集群,下面我们就来一同了解下etcd-operator这个服务的架构以及它所包含的一些功能。

了解etcd-operator的架构与CRD资源对象
部署etcd-operator
使用etcd-operator创建etcd cluster
etcd-operator的设计是基于k8s的API Extension机制来进行拓展的,它为用户设计了一个类似于Deployment的Controller,只不过这个Controller是用来专门管理etcd这一服务的。
用户默认还是通过kubectl或UI来与k8s的API进行交互,只不过在这个k8s集群中多了一个用户自定义的控制器(custom controller),operator controller的服务是以Pod的方式运行在k8s集群中的,同时这个服务也需要配置所需的RBAC权限(比如对Pod,Deployment,Volume等使用到的资源进行增删改查的操作),下面我们用一个简单的架构图来进行阐述:
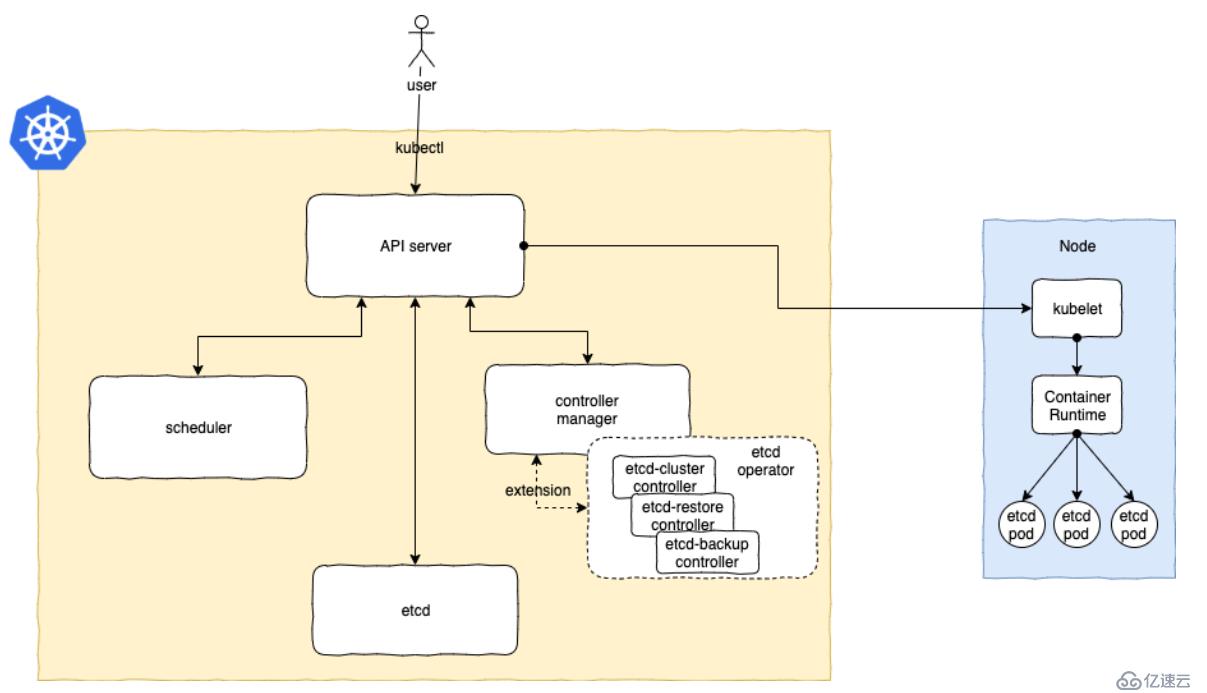
在k8s中,所有自定义的Controller和其自定义的资源对象(CRD)都必须满足k8s API的规范(参考下图):
apiVersion描述了当前自定义资源对象的版本号
Kind表示自定义资源对象的名称,用户可通过执行kubectl get $KIND_NAME来获取所创建的CRD对象
Metadata继承了原生k8s的metadata,用于添加标签,Annotations等元数据
Spec是用户可自定义设计的服务配置参数,如镜像版本号,节点数量,资源配置等等..
Status包含了当前资源的的相关状态,每个operator controller可自定义status所包含的信息,一般会选择添加如conditions,updateTime和message等一类的信息。
1、EtcdCluster: etcdcluster用来描述用户自定义的etcd集群,可一键式部署和配置一个相关的etcd集群。
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdCluster
metadata:
name: etcd-cluster
spec:
size: 3
version: 3.2.25
2、EtcdBackup: etcdbackup用来描述和管理一个etcd集群的备份,当前支持定期备份到云端存储,如AWS s3, Aliyun oss(oss当前需使用quay.io/coreos/etcd-operator:dev镜像)。
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdBackup
metadata:
name: etcd-backup
spec:
etcdEndpoints: [<etcd-cluster-endpoints>]
storageType: OSS #options are S3/ABS/GCS/OSS
backupPolicy:
backupIntervalInSecond: 125
maxBackups: 4
oss:
#"<oss-bucket-name>/<path-to-backup-file>"
path: <full-oss-path>
ossSecret: <oss-secret>
# Details about regions and endpoints, see https://www.alibabacloud.com/help/doc-detail/31837.htm
endpoint: <endpoint>
3、EtcdRestore:etcdrestore用来帮助将etcdbackup服务所创建的备份恢复到一个指定的etcd的集群。
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdRestore
metadata:
# name must be same to the spec.etcdCluster.name
name: example-etcd-cluster
spec:
etcdCluster:
name: example-etcd-cluster
backupStorageType: OSS
oss:
path: <full-oss-path>
ossSecret: <oss-secret>
endpoint: <endpoint>
1、部署etcd-operator
在Rancher最新的stable v2.3.2 的版本中,用户可通过应用商店(Catalog)来一键式部署 etcd-operator v0.9.0版本,同时原生k8s也可下载rancher/charts到本地后通过helm install的方式进行部署。

1)(可选)部署etcd-operator时可选择同时创建一个etcd集群(此集群在etcd-operator被删除时会被一同移除),当然用户也可待etcd-operator部署完成通过kubectl apply -f myetcd.yaml来创建一个新的etcd集群。
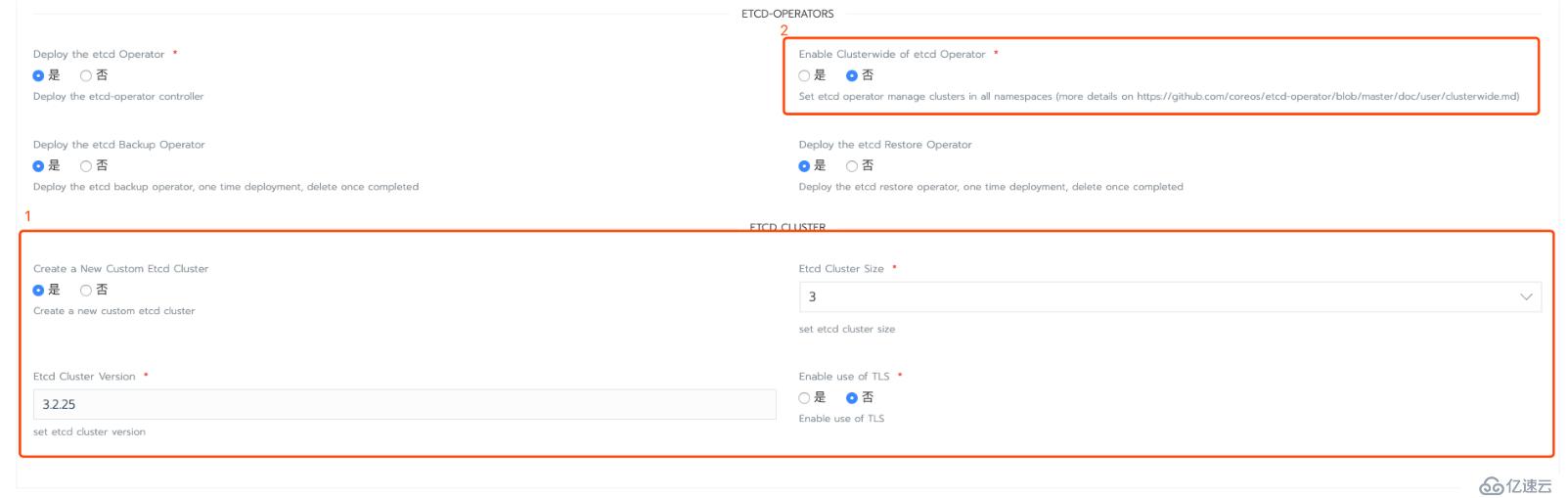
2)部署时,如果用户选择启动Enable Clusterwide of etcd Operator这个选项,那么这个etcd-operator将作为集群层级对象来使用(否则为namespaced隔离),如果enable这个选项,那么在创建etcd集群时需添加以下注释才能创建创建:
kind: EtcdCluster
metadata:
name: etcd-cluster
# add this annotation when the clusterWide is enabled
annotations:
etcd.database.coreos.com/scope: clusterwide
2、创建etcd集群
接下来我们就可以使用上述的CRD自定义资源对象对来创建和管理我们的etcd集群了。
2.1 手动创建etcd集群
cat <<EOF | kubectl apply -f -
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdCluster
metadata:
name: "etcd-cluster"
spec:
size: 3 # 默认etcd节点数
version: "3.2.25" # etcd版本号
EOF
2.2 部署后可通过CRD对象来查看我们创建的etcd集群和pod状态
$ kubectl get etcdcluster
NAME AGE
etcd-cluster 2m
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
etcd-cluster-g28f552vvx 1/1 Running 0 2m
etcd-cluster-lpftgqngl8 1/1 Running 0 2m
etcd-cluster-sdpcfrtv99 1/1 Running 0 2m
2.3 可以往etcd集群任意的写入几条数据验证etcd集群是正常工作的(后续也可用来验证集群的备份和恢复功能)
$ kubectl get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
etcd-cluster ClusterIP None <none> 2379/TCP,2380/TCP 17h
etcd-cluster-client ClusterIP 10.43.130.71 <none> 2379/TCP 17h
## write data
$ kubectl exec -it any-etcd-pod -- env "ETCDCTL_API=3" etcdctl --endpoints http://etcd-cluster-client:2379 put foo "Hello World"
## get data
$ kubectl exec -it any-etcd-pod -- env "ETCDCTL_API=3" etcdctl --endpoints http://etcd-cluster-client:2379 get foo
foo
Hello World
3、基于operator备份etcd cluster
3.1 确认了etcd集群正常运行后,作为devops后面要考虑的就是如何创建etcd集群的自动化备份,下面以阿里云的OSS举例:
cat <<EOF | kubectl apply -f -
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdBackup
metadata:
name: example-etcd-cluster-periodic-backup
spec:
etcdEndpoints: [http://etcd-cluster-client:2379] #内网可使用svc地址,外网可用NodePort或LB代理地址
storageType: OSS
backupPolicy:
backupIntervalInSecond: 120 #备份时间间隔
maxBackups: 4 #最大备份数
oss:
path: my-bucket/etcd.backup
ossSecret: oss-secret #需预先创建oss secret
endpoint: oss-cn-hangzhou.aliyuncs.com
EOF
3.2 若OSS Secret不存在,用户可先手动创建,具体配置可参考如下:
cat << EOF | kubectl apply -f -
apiVersion: v1
kind: Secret
metadata:
name: oss-secret
type: Opaque
stringData:
accessKeyID: myAccessKey
accessKeySecret: mySecret
EOF
3.3 待etcdbackup创建成功后,用户可以通过kubectl describe etcdbackup或查看etcd-backup controller日志来查看备份状态,如状态显示为Succeeded: true,可以前往oss查看具体的备份内容。

4、基于operator恢复etcd cluster
最后,假设我们要将etcd集群A的备份数据恢复到另一个新的etcd集群B,那么我们先手动创建一个名为etcd-cluster2的新集群(oss备份/恢复当前需使用quay.io/coreos/etcd-operator:dev镜像)。
cat <<EOF | kubectl apply -f -
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdCluster
metadata:
name: "etcd-cluster2"
spec:
size: 3
version: "3.2.25"
EOF
然后通过创建etcdresotre将备份数据恢复到etcd-cluster2集群
cat <<EOF | kubectl apply -f -
apiVersion: etcd.database.coreos.com/v1beta2
kind: EtcdRestore
metadata:
# name必须与下面的spec.etcdCluster.name保持一致
name: etcd-cluster2
spec:
etcdCluster:
name: etcd-cluster2
backupStorageType: OSS
oss:
path: my-bucket/etcd.backup_v1_2019-08-07-06:44:17
ossSecret: oss-secret
endpoint: oss-cn-hangzhou.aliyuncs.com
EOF
待etcdresotre对象创建成功后,可以查看etcd-operator-restore的日志,大致内容如下:
$ kubectl logs -f etcd-operator-restore
...
time="2019-08-07T06:50:26Z" level=info msg="listening on 0.0.0.0:19999"
time="2019-08-07T06:50:26Z" level=info msg="starting restore controller" pkg=controller
time="2019-08-07T06:56:25Z" level=info msg="serving backup for restore CR etcd-cluster2"
通过kubectl查看pod我们可以看到etcd-cluster2集群的etcd节点被删除重建:
NAME READY STATUS RESTARTS AGE
etcd-cluster2-5tq2d5bvpf 0/1 Terminating 0 93s
etcd-cluster2-kfgvc692pp 1/1 Terminating 0 101s
etcd-cluster2-xqkgz8chb8 0/1 Init:1/3 0 6s
etcd-cluster2-pf2qxgtg9d 1/1 Running 0 48s
etcd-cluster2-x92l9vpx97 1/1 Running 0 40s
最后可通过etcdctl来验证之前的数据是否存在(需设置ETCDCTL_API=3):
$ kubectl exec -it etcd-pod -- env "ETCDCTL_API=3" etcdctl --endpoints http://etcd-cluster2-client:2379 get foo
foo
Hello World
Etcd作为当前非常流行的key-value分布式文件存储,它本身的强一致性和较优的性能可以为许多分布式计算解决分布式存储的需求,如果你的微服务和应用需要用到此类的数据库,不妨来试试Rancher Catalog应用中的etcd-operator吧,Just do it!
相关资料:
https://github.com/coreos/etcd-operator
https://coreos.com/blog/introducing-the-etcd-operator.html
https://github.com/rancher/charts/tree/master/charts/etcd-operator/v0.9.0
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。