жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPythonеһғеңҫеӣһ收жңәеҲ¶жңүд»Җд№ҲдҪңз”ЁпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
еј•е…Ҙ
дёәд»Җд№ҲиҰҒжңүеһғеңҫеӣһ收жңәеҲ¶
гҖҖгҖҖPythonдёӯзҡ„еһғеңҫеӣһ收жңәеҲ¶з®Җз§°пјҲGCпјүпјҢжҲ‘们еңЁзЁӢеәҸзҡ„иҝҗиЎҢдёӯдјҡдә§з”ҹеӨ§йҮҸзҡ„еҸҳйҮҸз”ЁдәҺдҝқеӯҳж•°жҚ®пјҢиҖҢжңүж—¶еҖҷжңүдәӣеҸҳйҮҸе·Із»ҸжІЎжңүз”ЁдәҶе°ұйңҖиҰҒиў«жё…зҗҶйҮҠж”ҫжҺүиҜҘеҸҳйҮҸжүҖеҚ жҚ®зҡ„еҶ…еӯҳз©әй—ҙгҖӮеңЁдёҖдәӣиҫғдёәдҪҺзә§зҡ„иҜӯиЁҖдёӯпјҲжҜ”еҰӮпјҡCиҜӯиЁҖпјҢжұҮзј–иҜӯиЁҖпјүеҜ№дәҺеҶ…еӯҳз©әй—ҙзҡ„йҮҠж”ҫжҳҜйңҖиҰҒзј–зЁӢдәәе‘ҳжқҘжүӢеҠЁиҝӣиЎҢзҡ„пјҢиҝҷз§ҚдёҺеә•еұӮ硬件зӣҙжҺҘжү“дәӨйҒ“зҡ„ж“ҚдҪңжҳҜеҚҒеҲҶзҡ„еҚұйҷ©дёҺз№Ғзҗҗзҡ„пјҢиҖҢеҹәдәҺCиҜӯиЁҖејҖеҸ‘иҖҢжқҘзҡ„PythonдёәдәҶи§ЈеҶіжҺүиҝҷз§ҚйЎҫиҷ‘еҲҷиҮӘеёҰдәҶдёҖз§Қеһғеңҫеӣһ收жңәеҲ¶пјҢд»ҺиҖҢи®©ејҖеҸ‘дәәе‘ҳдёҚеҝ…иҝҮеҲҶжӢ…еҝғеҶ…еӯҳзҡ„дҪҝз”Ёжғ…еҶөиҖҢеҸҜд»Ҙе…Ёиә«еҝғзҡ„жҠ•е…ҘеҲ°ејҖеҸ‘дёӯеҺ»гҖӮ
>>> name = "yunya" #yunya еҮҶеӨҮж”№еҗҚ >>> name = "yunyaya" #еҺҹжң¬yunyaиҝҷдёӘеҗҚеӯ—дёҚдҪҝз”ЁдәҶпјҢзҺ°еңЁеҝ…йЎ»жё…зҗҶжҺүе®ғеҗҰеҲҷе°ҶдјҡеҚ жҚ®еҶ…еӯҳз©әй—ҙпјҢжүҖе№ёPythonзҡ„еһғеңҫеӣһ收жңәеҲ¶дјҡеё®жҲ‘жё…зҗҶжҺү "yunya" >>
е ҶеҢәе’Ңж ҲеҢәзҡ„жҰӮеҝө
гҖҖгҖҖеҰӮжһңдҪ зңӢжҲ‘д№ӢеүҚеҶҷзҡ„йӮЈзҜҮж–Үз« е…ідәҺPythonеҸҳйҮҸзҡ„еә•еұӮеҺҹзҗҶзҡ„иҜқйӮЈд№Ҳжғіеҝ…еҜ№е ҶеҢәе’Ңж ҲеҢәеҶ…еӯҳжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈгҖӮеҰӮжһңжІЎжңүзңӢиҝҮйӮЈд№Ҳд№ҹжІЎжңүе…ізі»пјҢй“ҫжҺҘеҰӮдёӢпјҡ
PythonеҸҳйҮҸдёҺеҹәжң¬ж•°жҚ®зұ»еһӢ
еә•еұӮе·ҘдҪңеҺҹзҗҶ
еј•з”Ёи®Ўж•°
гҖҖгҖҖеј•з”Ёи®Ўж•°иҜҙзҷҪдәҶе°ұжҳҜжқҘеҜ№е ҶеҢәзҡ„еҸҳйҮҸеҖјз»‘е®ҡзҡ„ж ҲеҢәеҸҳйҮҸеҗҚжқҘи®Ўж•°гҖӮеҰӮеӣҫпјҡ
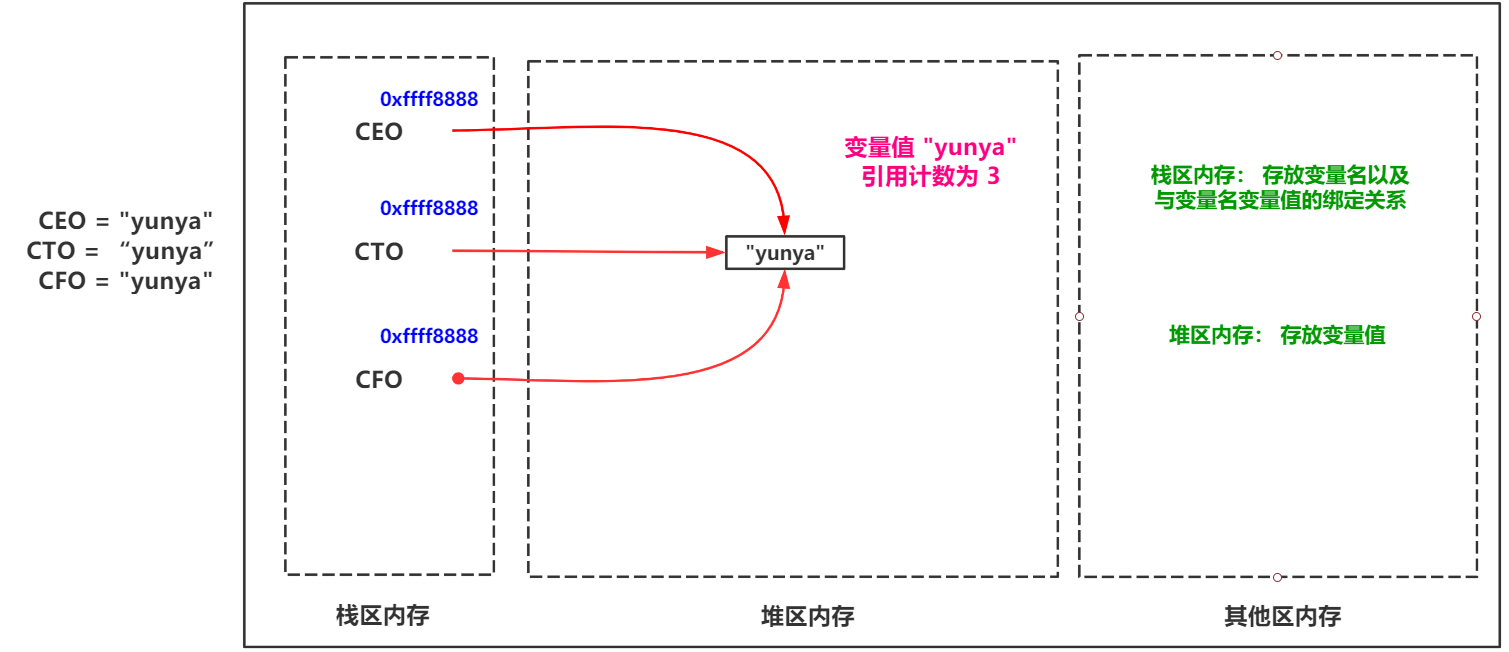
гҖҖгҖҖеҪ“дҪҝз”ЁdelжҲ–иҖ…еҜ№еҸҳйҮҸеҗҚйҮҚж–°иөӢеҖјеҗҺпјҢиҜҘеҸҳйҮҸеҖјзҡ„еј•з”Ёи®Ўж•°е°ұдјҡ -1 гҖӮеҪ“еј•з”Ёи®Ўж•°дёә 0 ж—¶еҖҷдёӢж¬Ў PythonеҶ…еӯҳеӣһ收жңәеҲ¶ иҝӣиЎҢеҶ…еӯҳжү«жҸҸж—¶дҫҝдјҡе°ҶиҜҘеҸҳйҮҸеҖјеҪ“еҒҡеһғеңҫиҝӣиЎҢеӣһ收гҖӮ
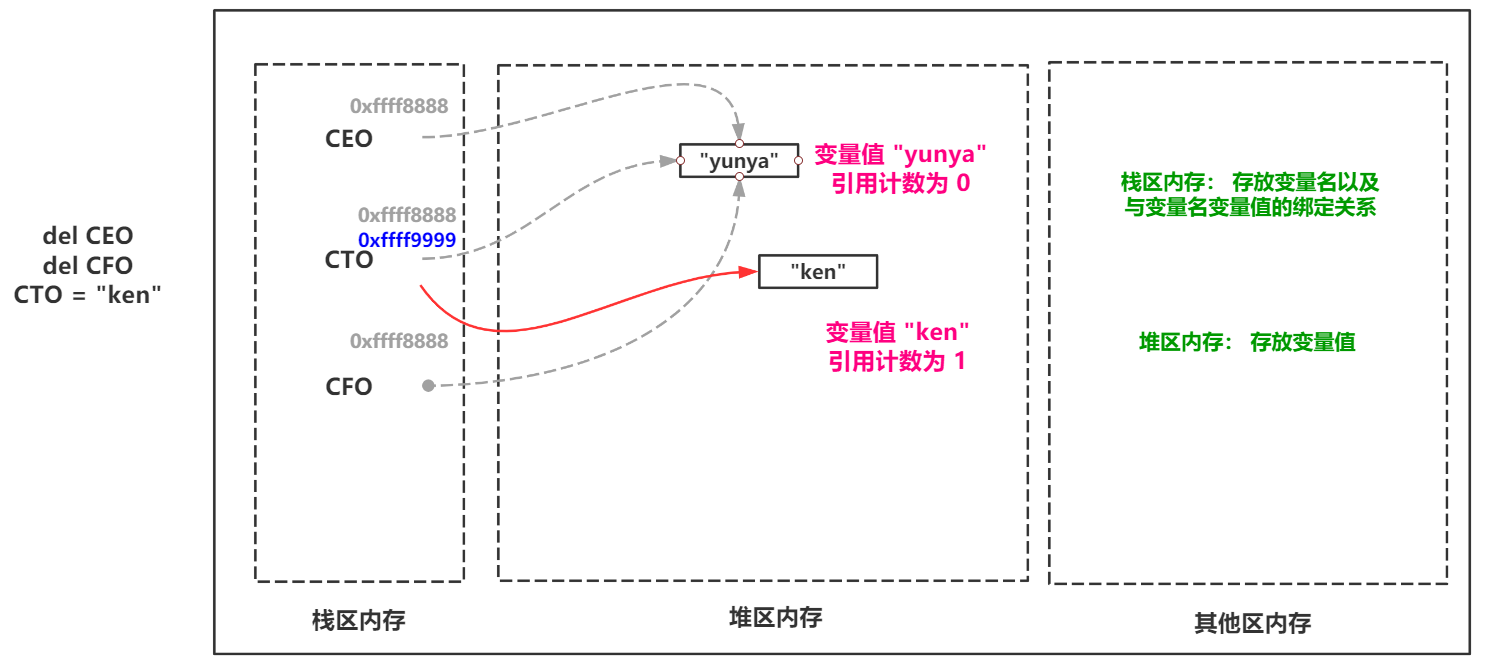
гҖҖйӮЈд№ҲиҝҷйҮҢе°ұжҳҜPythonеҶ…еӯҳеӣһ收жңәеҲ¶дёӯжңҖеҹәжң¬зҡ„д№ҹжңҖеёёз”Ёзҡ„еј•з”Ёи®Ўж•°д»Ӣз»ҚгҖӮ
еҫӘзҺҜеј•з”Ё-еҶ…еӯҳжі„жјҸ
гҖҖгҖҖеј•з”Ёи®Ўж•°иҷҪ然дҪңдёәPythonеҶ…еӯҳеӣһ收жңәеҲ¶дёӯжңҖз»ҸеёёдҪҝз”Ёзҡ„дёҖз§ҚжңәеҲ¶пјҢдҪҶжҳҜе®ғжң¬иә«д№ҹжҳҜе…·жңүдёҖе®ҡзҡ„зјәзӮ№гҖӮжҲ‘们жқҘзңӢдёӢйқўиҝҷж®өд»Јз Ғпјҡ
>>> l1 = [1,2,3] >>> l2 = [1,2,3,l1] >>> l1.append(l2) #append()ж–№жі•з”ЁдәҺеҗ‘еҲ—иЎЁдёӯж·»еҠ дёҖдёӘе…ғзҙ еҖј >>> l1 [1, 2, 3, [1, 2, 3, [...]]] >>> l2 [1, 2, 3, [1, 2, 3, [...]]] >>>
гҖҖгҖҖзҺ°еңЁl1е’Ңl2е…ЁйғЁдҪңдёәдә’зӣёеј•з”ЁдәҶгҖӮйӮЈд№ҲеҜ№дәҺиҝҷз§Қеј•з”Ёж–№ејҸеҸ«еҒҡеҫӘзҺҜеј•з”ЁпјҲд№ҹиў«з§°дёәдәӨеҸүеј•з”ЁпјүпјҢеҫӘзҺҜеј•з”ЁдјҡеёҰжқҘдёҖдёӘй—®йўҳпјҡ
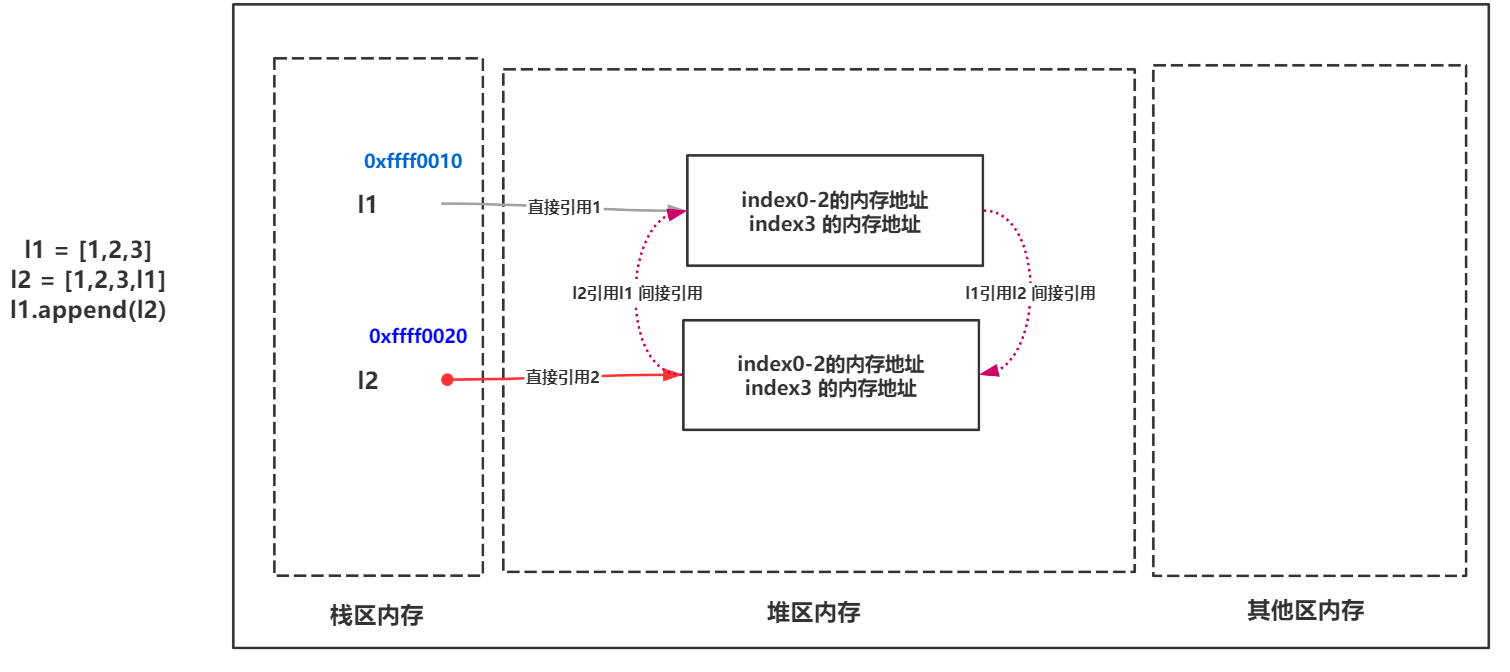
>>> del l1 >>> del l2 >>> #зҺ°еңЁжҖҺд№Ҳи®ҝй—® li1 жҲ–иҖ… li2 е‘ўпјҹи®ҝй—®дёҚеҲ°пјҢдҪҶжҳҜ他们зҡ„еҸҳйҮҸеҖјдҫқ然еӯҳеңЁдәҺеҶ…еӯҳпјҢеј•з”Ёи®Ўж•°д»Һ2еҸҳдёә1
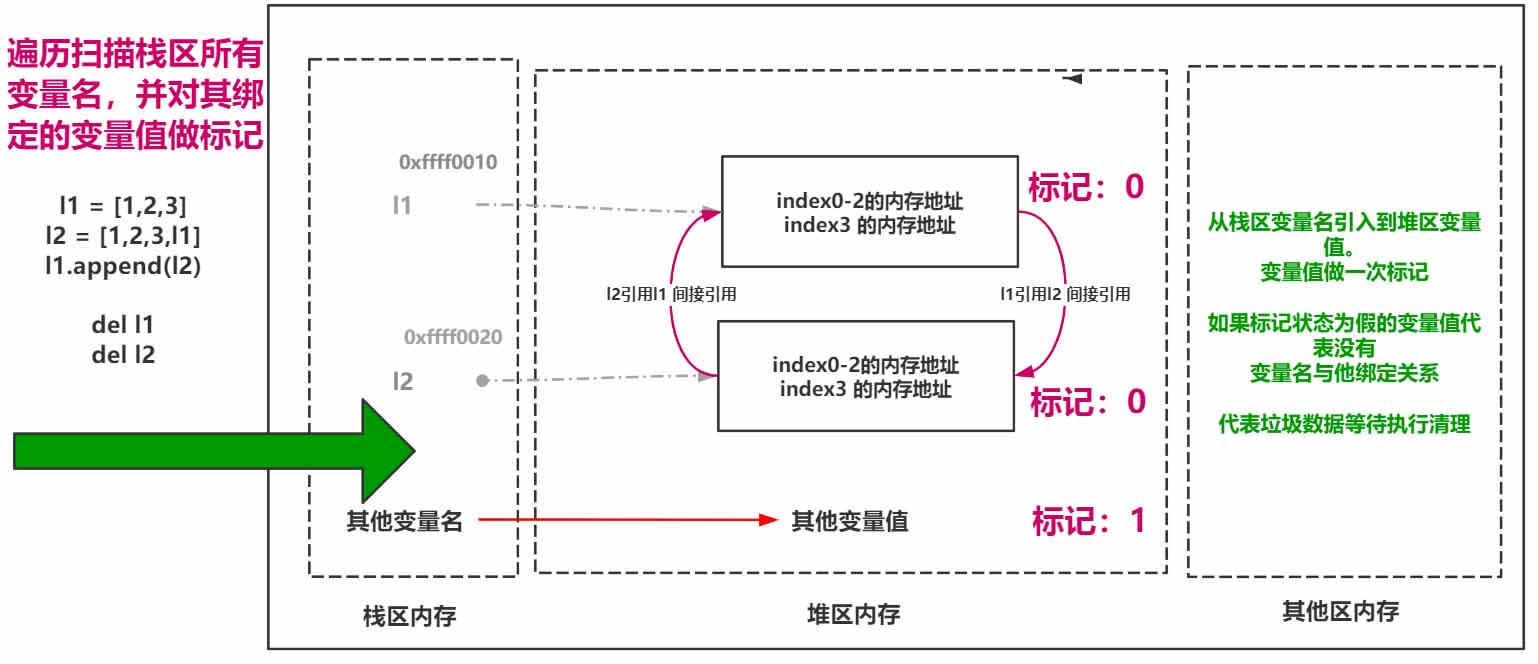
ж Үи®°-жё…йҷӨ
гҖҖгҖҖж Үи®°жё…йҷӨзҡ„ж„ҸжҖқеңЁдәҺеҪ“еә”з”ЁзЁӢеәҸеҸҜз”ЁеҶ…еӯҳз©әй—ҙеҚіе°Ҷиў«иҖ—е°Ҫж—¶дҫҝејҖе§Ӣжү«жҸҸж ҲеҢәпјҢ并且дјҡйЎәзқҖж ҲеҢәеҸҳйҮҸеҗҚеҜ№е ҶеҢәдёӯзҡ„еҸҳйҮҸеҖјеҒҡдёҖдёӘж Үи®°пјҢеҰӮжһңе ҶеҢәдёӯеӯҳеңЁжІЎжңүдёҺж ҲеҢәеҸҳйҮҸеҗҚеҒҡеҜ№еә”е…ізі»зҡ„ж•°жҚ®еҲҷдјҡиў«и®ӨдёәжҳҜеһғеңҫж•°жҚ®д»ҺиҖҢиў«Pythonеһғеңҫеӣһ收жңәеҲ¶жё…зҗҶгҖӮ
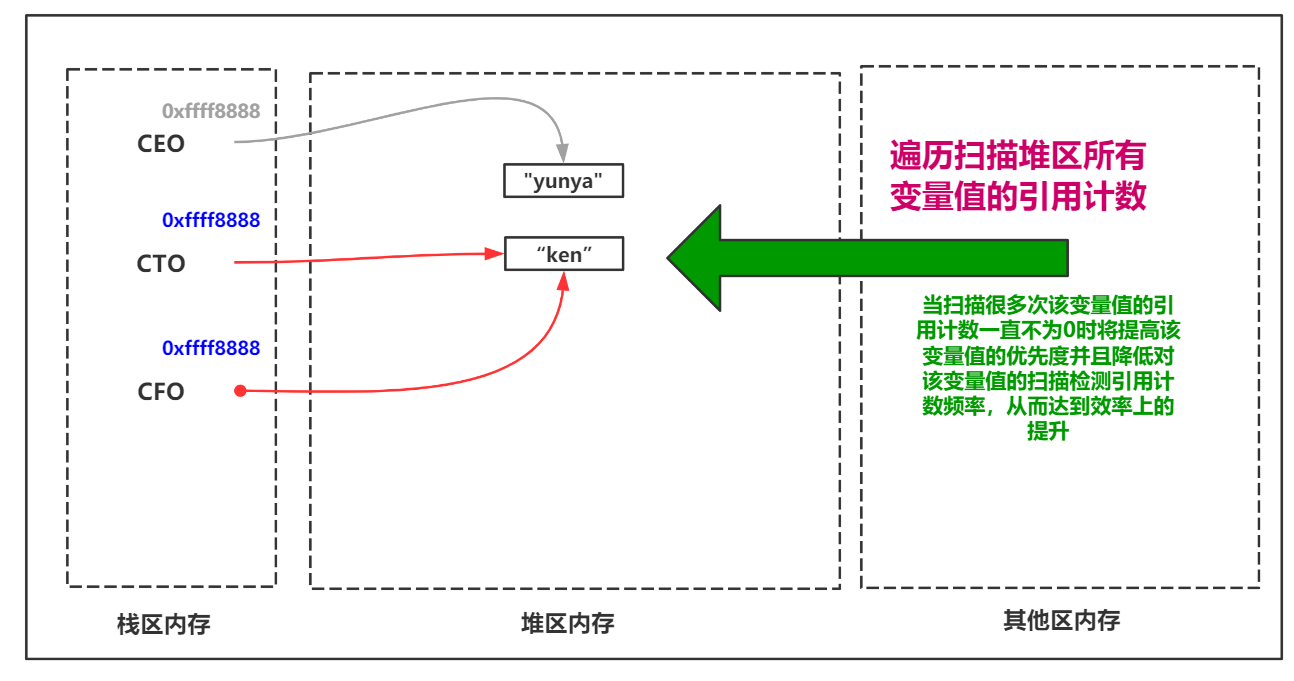
ж•ҲзҺҮй—®йўҳи§ЈеҶіж–№жЎҲ-еҲҶд»Јеӣһ收
гҖҖгҖҖеҹәдәҺеј•з”Ёи®Ўж•°зҡ„еһғеңҫеӣһ收жңәеҲ¶жҜҸдёҖж¬Ўжү§иЎҢжё…зҗҶж“ҚдҪңеүҚйғҪдјҡе°Ҷж•ҙдёӘе ҶеҢәзҡ„еҸҳйҮҸеҖјзҡ„еј•з”Ёи®Ўж•°еҒҡдёҖж¬ЎйҒҚеҺҶз»ҹи®ЎгҖӮиҝҷж ·еҒҡжҳҜйқһеёёж¶ҲиҖ—ж—¶й—ҙзҡ„пјҢжүҖд»ҘPythonеһғеңҫеӣһ收жңәеҲ¶дёәдәҶж•ҲзҺҮзҡ„жҸҗеҚҮеҠ е…ҘдәҶеҲҶд»Јеӣһ收зҡ„зӯ–з•ҘгҖӮ
е…ідәҺPythonеһғеңҫеӣһ收жңәеҲ¶жңүд»Җд№ҲдҪңз”Ёе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ