жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іPython3зҲ¬иҷ«дёӯAjaxзҡ„з®Җд»ӢпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
1. жҹҘзңӢиҜ·жұӮ
иҝҷйҮҢиҝҳйңҖиҰҒеҖҹеҠ©жөҸи§ҲеҷЁзҡ„ејҖеҸ‘иҖ…е·Ҙе…·пјҢдёӢйқўд»ҘChromeжөҸи§ҲеҷЁдёәдҫӢжқҘд»Ӣз»ҚгҖӮ
йҰ–е…ҲпјҢз”ЁChromeжөҸи§ҲеҷЁжү“ејҖеҫ®еҚҡзҡ„й“ҫжҺҘhttps://m.weibo.cn/u/2830678474пјҢйҡҸеҗҺеңЁйЎөйқўдёӯзӮ№еҮ»йј ж ҮеҸій”®пјҢд»Һеј№еҮәзҡ„еҝ«жҚ·иҸңеҚ•дёӯйҖүжӢ©вҖңжЈҖжҹҘвҖқйҖүйЎ№пјҢжӯӨж—¶дҫҝдјҡеј№еҮәејҖеҸ‘иҖ…е·Ҙе…·пјҢеҰӮеӣҫ6-2жүҖзӨәпјҡ
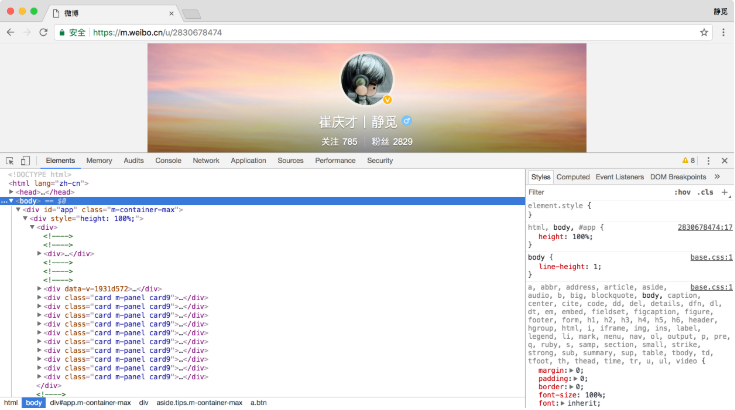
жӯӨж—¶еңЁElementsйҖүйЎ№еҚЎдёӯдҫҝдјҡи§ӮеҜҹеҲ°зҪ‘йЎөзҡ„жәҗд»Јз ҒпјҢеҸідҫ§дҫҝжҳҜиҠӮзӮ№зҡ„ж ·ејҸгҖӮ
дёҚиҝҮиҝҷдёҚжҳҜжҲ‘们жғіиҰҒеҜ»жүҫзҡ„еҶ…е®№гҖӮеҲҮжҚўеҲ°NetworkйҖүйЎ№еҚЎпјҢйҡҸеҗҺйҮҚж–°еҲ·ж–°йЎөйқўпјҢеҸҜд»ҘеҸ‘зҺ°иҝҷйҮҢеҮәзҺ°дәҶйқһеёёеӨҡзҡ„жқЎзӣ®пјҢеҰӮеӣҫ6-3жүҖзӨәгҖӮ
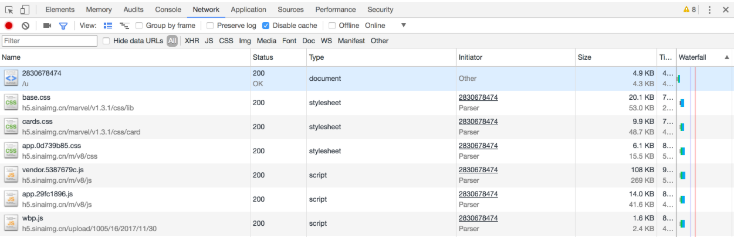
еүҚйқўд№ҹжҸҗеҲ°иҝҮпјҢиҝҷйҮҢе…¶е®һе°ұжҳҜеңЁйЎөйқўеҠ иҪҪиҝҮзЁӢдёӯжөҸи§ҲеҷЁдёҺжңҚеҠЎеҷЁд№Ӣй—ҙеҸ‘йҖҒиҜ·жұӮе’ҢжҺҘ收е“Қеә”зҡ„жүҖжңүи®°еҪ•гҖӮ
Ajaxе…¶е®һжңүе…¶зү№ж®Ҡзҡ„иҜ·жұӮзұ»еһӢпјҢе®ғеҸ«дҪңxhrгҖӮеңЁеӣҫ6-3дёӯпјҢжҲ‘们еҸҜд»ҘеҸ‘зҺ°дёҖдёӘеҗҚз§°д»ҘgetIndexејҖеӨҙзҡ„иҜ·жұӮпјҢе…¶TypeдёәxhrпјҢиҝҷе°ұжҳҜдёҖдёӘAjaxиҜ·жұӮгҖӮз”Ёйј ж ҮзӮ№еҮ»иҝҷдёӘиҜ·жұӮпјҢеҸҜд»ҘжҹҘзңӢиҝҷдёӘиҜ·жұӮзҡ„иҜҰз»ҶдҝЎжҒҜпјҢеҰӮеӣҫ6-4жүҖзӨәгҖӮ
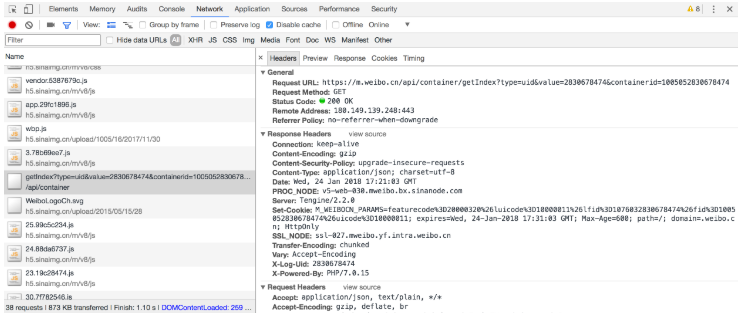
еңЁеҸідҫ§еҸҜд»Ҙи§ӮеҜҹеҲ°е…¶Request HeadersгҖҒURLе’ҢResponse HeadersзӯүдҝЎжҒҜгҖӮе…¶дёӯRequest HeadersдёӯжңүдёҖдёӘдҝЎжҒҜдёәX-Requested-With:XMLHttpRequestпјҢиҝҷе°ұж Үи®°дәҶжӯӨиҜ·жұӮжҳҜAjaxиҜ·жұӮпјҢеҰӮеӣҫ6-5жүҖзӨәгҖӮ
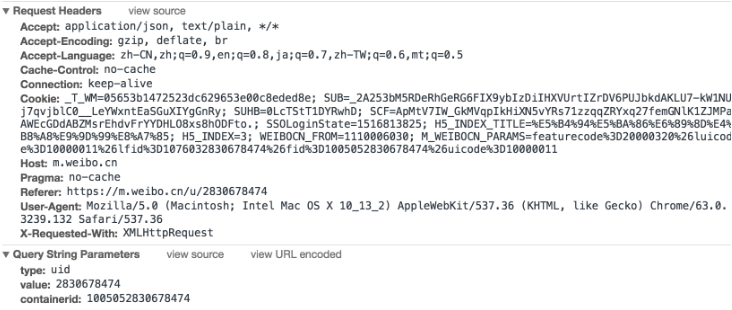
йҡҸеҗҺзӮ№еҮ»дёҖдёӢPreviewпјҢеҚіеҸҜзңӢеҲ°е“Қеә”зҡ„еҶ…е®№пјҢе®ғжҳҜJSONж јејҸзҡ„гҖӮиҝҷйҮҢChromeдёәжҲ‘们иҮӘеҠЁеҒҡдәҶи§ЈжһҗпјҢзӮ№еҮ»з®ӯеӨҙеҚіеҸҜеұ•ејҖе’Ң收иө·зӣёеә”еҶ…е®№пјҢеҰӮеӣҫ6-6жүҖзӨәгҖӮ
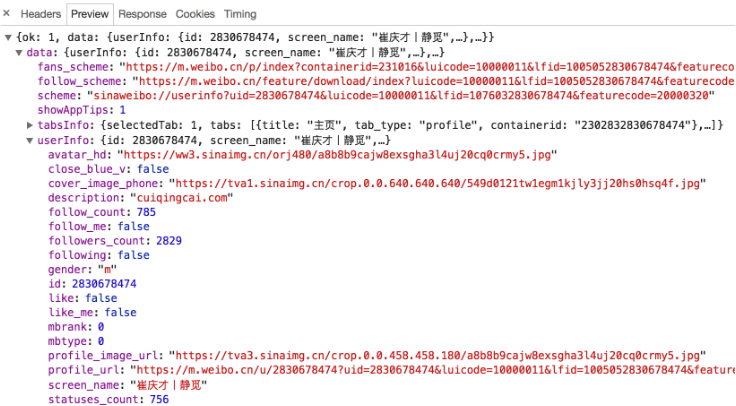
и§ӮеҜҹеҸҜд»ҘеҸ‘зҺ°пјҢиҝҷйҮҢзҡ„иҝ”еӣһз»“жһңжҳҜжҲ‘зҡ„дёӘдәәдҝЎжҒҜпјҢеҰӮжҳөз§°гҖҒз®Җд»ӢгҖҒеӨҙеғҸзӯүпјҢиҝҷд№ҹжҳҜз”ЁжқҘжёІжҹ“дёӘдәәдё»йЎөжүҖдҪҝз”Ёзҡ„ж•°жҚ®гҖӮJavaScriptжҺҘ收еҲ°иҝҷдәӣж•°жҚ®д№ӢеҗҺпјҢеҶҚжү§иЎҢзӣёеә”зҡ„жёІжҹ“ж–№жі•пјҢж•ҙдёӘйЎөйқўе°ұжёІжҹ“еҮәжқҘдәҶгҖӮ
еҸҰеӨ–пјҢд№ҹеҸҜд»ҘеҲҮжҚўеҲ°ResponseйҖүйЎ№еҚЎпјҢд»Һдёӯи§ӮеҜҹеҲ°зңҹе®һзҡ„иҝ”еӣһж•°жҚ®пјҢеҰӮеӣҫ6-7жүҖзӨәгҖӮ

жҺҘдёӢжқҘпјҢеҲҮеӣһеҲ°з¬¬дёҖдёӘиҜ·жұӮпјҢи§ӮеҜҹдёҖдёӢе®ғзҡ„ResponseжҳҜд»Җд№ҲпјҢеҰӮеӣҫ6-8жүҖзӨәгҖӮ

иҝҷжҳҜжңҖеҺҹе§Ӣзҡ„й“ҫжҺҘhttps://m.weibo.cn/u/2830678474иҝ”еӣһзҡ„з»“жһңпјҢе…¶д»Јз ҒеҸӘжңүдёҚеҲ°50иЎҢпјҢз»“жһ„д№ҹйқһеёёз®ҖеҚ•пјҢеҸӘжҳҜжү§иЎҢдәҶдёҖдәӣJavaScriptгҖӮ
жүҖд»ҘиҜҙпјҢжҲ‘们зңӢеҲ°зҡ„еҫ®еҚҡйЎөйқўзҡ„зңҹе®һж•°жҚ®е№¶дёҚжҳҜжңҖеҺҹе§Ӣзҡ„йЎөйқўиҝ”еӣһзҡ„пјҢиҖҢжҳҜеҗҺжқҘжү§иЎҢJavaScriptеҗҺеҶҚж¬Ўеҗ‘еҗҺеҸ°еҸ‘йҖҒдәҶAjaxиҜ·жұӮпјҢжөҸи§ҲеҷЁжӢҝеҲ°ж•°жҚ®еҗҺеҶҚиҝӣдёҖжӯҘжёІжҹ“еҮәжқҘзҡ„гҖӮ
2. иҝҮж»ӨиҜ·жұӮ
жҺҘдёӢжқҘпјҢеҶҚеҲ©з”ЁChromeејҖеҸ‘иҖ…е·Ҙе…·зҡ„зӯӣйҖүеҠҹиғҪзӯӣйҖүеҮәжүҖжңүзҡ„AjaxиҜ·жұӮгҖӮеңЁиҜ·жұӮзҡ„дёҠж–№жңүдёҖеұӮзӯӣйҖүж ҸпјҢзӣҙжҺҘзӮ№еҮ»XHRпјҢжӯӨж—¶еңЁдёӢж–№жҳҫзӨәзҡ„жүҖжңүиҜ·жұӮдҫҝйғҪжҳҜAjaxиҜ·жұӮдәҶпјҢеҰӮеӣҫ6-9жүҖзӨәгҖӮ
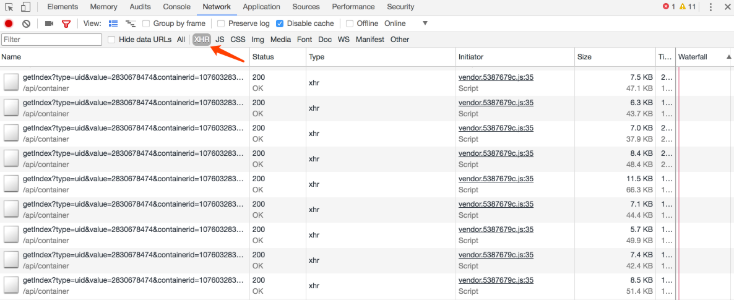
жҺҘдёӢжқҘпјҢдёҚж–ӯж»‘еҠЁйЎөйқўпјҢеҸҜд»ҘзңӢеҲ°йЎөйқўеә•йғЁжңүдёҖжқЎжқЎж–°зҡ„еҫ®еҚҡиў«еҲ·еҮәпјҢиҖҢејҖеҸ‘иҖ…е·Ҙе…·дёӢж–№д№ҹдёҖдёӘдёӘең°еҮәзҺ°AjaxиҜ·жұӮпјҢиҝҷж ·жҲ‘们е°ұеҸҜд»ҘжҚ•иҺ·еҲ°жүҖжңүзҡ„AjaxиҜ·жұӮдәҶгҖӮ
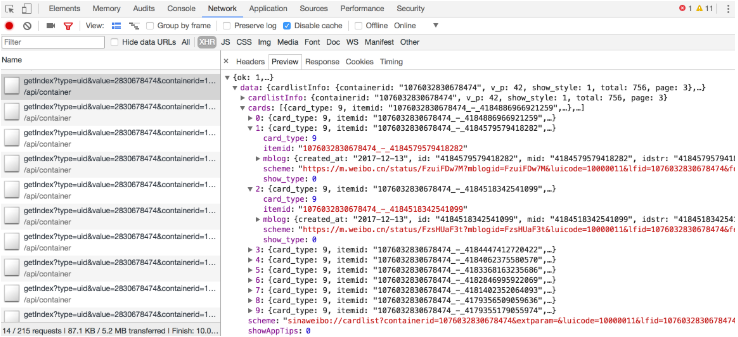
йҡҸж„ҸзӮ№ејҖдёҖдёӘжқЎзӣ®пјҢйғҪеҸҜд»Ҙжё…жҘҡең°зңӢеҲ°е…¶Request URLгҖҒRequest HeadersгҖҒResponse HeadersгҖҒResponse BodyзӯүеҶ…е®№пјҢжӯӨж—¶жғіиҰҒжЁЎжӢҹиҜ·жұӮе’ҢжҸҗеҸ–е°ұйқһеёёз®ҖеҚ•дәҶгҖӮ
еӣҫ6-10жүҖзӨәзҡ„еҶ…е®№дҫҝжҳҜжҲ‘зҡ„жҹҗдёҖйЎөеҫ®еҚҡзҡ„еҲ—иЎЁдҝЎжҒҜгҖӮ
еҲ°зҺ°еңЁдёәжӯўпјҢжҲ‘们已з»ҸеҸҜд»ҘеҲҶжһҗеҮәжқҘAjaxиҜ·жұӮзҡ„дёҖдәӣиҜҰз»ҶдҝЎжҒҜдәҶпјҢжҺҘдёӢжқҘеҸӘйңҖиҰҒз”ЁзЁӢеәҸжЁЎжӢҹиҝҷдәӣAjaxиҜ·жұӮпјҢе°ұеҸҜд»ҘиҪ»жқҫжҸҗеҸ–жҲ‘们жүҖйңҖиҰҒзҡ„дҝЎжҒҜдәҶгҖӮ
е…ідәҺPython3зҲ¬иҷ«дёӯAjaxзҡ„з®Җд»Ӣе°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ