您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章给大家分享的是有关有哪些大数据开发离线计算框架知识点,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
大数据开发离线计算框架知识点总结,大数据在带来发展机遇的同时,也带来了新的挑战,催生了新技术的发展和旧技术的革新。大数据离线计算技术应用于静态数据的离线计算和处理,框架设计的初衷是为了解决大规模、非实时数据计算,更加关注整个计算框架的吞吐量。
大数据离线计算框架介绍:
一、MapReduce计算框架
Hadoop是一个分布式系统架构,由Apache基金会所开发,其核心主要包括两个组件:HDFS和MapReduce,前者为海量存储提供了存储,而后者为海量的数据提供了计算。这里我们主要关注MapReduce。以下资料来源于Hadoop的官方说明文档和论文。
MapReduce是一个使用简易的软件框架,基于它写出来的应用程序能够运行在由上千个商用机器组成的大型集群上,并以一种可靠容错的方式并行处理上T级别的数据集。将计算过程分为两个阶段,Map和Reduce,Map阶段并行处理输入的数据,Reduce阶段对Map结果进行汇总。
一个MapReduce作业通常会把输入的数据集切分为若干独立的数据块,由Map任务以完全并行的方式处理它们。框架会对Map的输出先进行排序,然后把结果输入给Reduce任务。通常作业的输入和输出都会被存储在文件系统中。整个框架负责任务的调度和监控,以及重新执行已经失败的任务。
通常,MapReduce框架和分布式文件系统是运行在一组相同的节点上的,也就是说,计算节点和存储节点通常在一起。这种配置允许框架在那些已经存好数据的节点上高效地调度任务,这可以使整个集群的网络带宽被非常高效地利用。
MapReduce框架由一个单独的master JobTracker 和每个集群节点一个slave TaskTracker共同组成。master负责调度构成一个作业的所有任务,这些任务分布在不同的slave上,master监控它们的执行,重新执行已经失败的任务。而slave仅负责执行由master指派的任务。
应用程序至少应该指明输入/输出的路径,并通过实现合适的接口或抽象类提供map和reduce函数。再加上其他作业的参数,就构成了作业配置。然后,Hadoop的Job Client提交作业和配置信息给JobTracker,后者负责分发这些软件和配置信息给slave、调度任务并监控它们的执行,同时提供状态和诊断信息给Job Client。
应用程序通常会通过提供map和reduce来实现 Mapper和Reducer接口,它们组成作业的核心。map函数接受一个键值对,产生一组中间键值对。MapReduce框架会将map函数产生的中间键值对中键相同的值传递给一个reduce函数。reduce函数接受一个键,以及相关的一组值,将这组值进行合并产生一组规模更小的值。
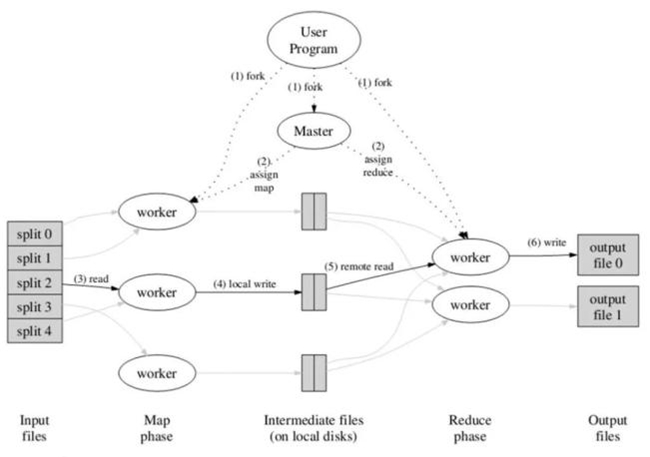
如图1所示,MapReduce的工作流程中,一切都是从最上方的user program开始的,user program链接了MapReduce库,实现了最基本的Map函数和Reduce函数。图中执行的顺序都用数字标记了。
二、Spark计算框架
Spark基于MapReduce算法实现的离线计算,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的Map Reduce的算法。
Spark中一个主要的结构是RDD(Resilient Distributed Datasets),这是一种只读的数据划分,并且可以在丢失之后重建。它利用了Lineage的概念实现容错,如果一个RDD丢失了,那么有足够的信息支持RDD重建。RDD可以被认为是提供了一种高度限制的共享内存,但是这些限制可以使得自动容错的开支变得很低。
RDD使用Lineage的容错机制,即每一个RDD都包含关于它是如何从其他RDD变换过来的以及如何重建某一块数据的信息。RDD仅支持粗颗粒度变换,即仅记录在单个块上执行的单个操作,然后创建某个RDD的变换序列存储下来,当数据丢失时,我们可以用变换序列来重新计算,恢复丢失的数据,以达到容错的目的。
Spark中的应用程序称为驱动程序,这些驱动程序可实现在单一节点上执行的操作或在一组节点上并行执行的操作。驱动程序可以在数据集上执行两种类型的操作:动作和转换。动作会在数据集上执行一个计算,并向驱动程序返回一个值;而转换会从现有数据集中创建一个新的数据集。动作的示例包括执行一个Reduce操作以及在数据集上进行迭代。转换示例包括Map操作和Cache操作。
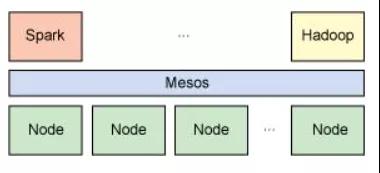
与Hadoop类似,Spark支持单节点集群或多节点集群。对于多节点操作,Spark依赖于Mesos集群管理器。Mesos为分布式应用程序的资源共享和隔离提供了一个有效平台,参考图2。
三、Dryad计算框架
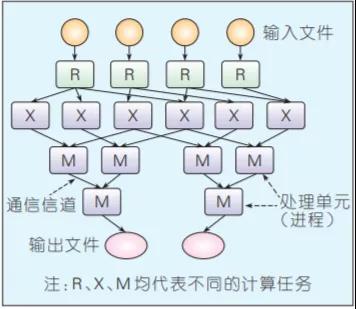
Dryad是构建微软云计算基础设施的核心技术。编程模型相比MapReduce更具一般性——用有向无环图(DAG)描述任务的执行,其中用户指定的程序是DAG图的节点,数据传输的通道是边,可通过文件、共享内存或者传输控制协议(TCP)通道来传递数据,任务相当于图的生成器,可以合成任何图,甚至在执行的过程中这些图也可以发生变化,以响应计算过程中发生的事件。图3给出了整个任务的处理流程。
Dryad在容错方面支持良好,底层的数据存储支持数据备份;在任务调度方面,Dryad的适用性更广,不仅适用于云计算,在多核和多处理器以及异构集群上同样有良好的性能;在扩展性方面,可伸缩于各种规模的集群计算平台,从单机多核计算机到由多台计算机组成的集群,甚至拥有数千台计算机的数据中心。Microsoft借助Dryad,在大数据处理方面也形成了完整的软件栈,部署了分布式存系统Cosmos,提供DryadLINQ编程语言,使普通程序员可以轻易进行大规模的分布式计算。
离线计算的数据量大且计算周期长,是在大量数据基础上进行复杂的批量运算。离线计算的数据是不再会发生变化,通常离线计算的任务都是定时的,使用场景一般式对时效性要求比较低的。
以上就是有哪些大数据开发离线计算框架知识点,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。