您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
SQLServer的检查点、redo和undo
检查点与恢复效率的关系
检查点将脏数据页从当前数据库的缓冲区高速缓存刷新到磁盘上。 这最大限度地减少了恢复时必须重做(Redo)的修改量。
为什么在日志文件中设置了检查点之后,基于日志的恢复机制就可以提高效率了呢?如图所示为检查点发生时可能的事务的状态。
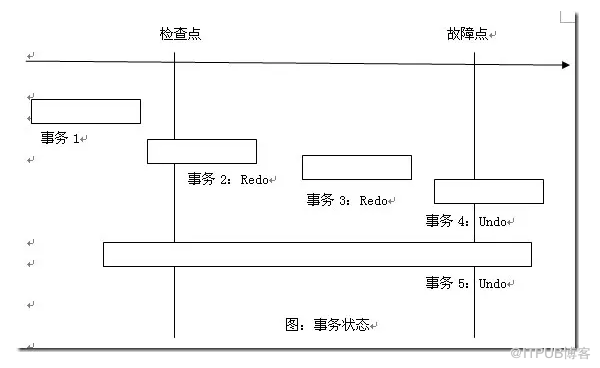
① 事务1
其start和commit日志记录都发生在检查点之前,这样的事务其结果已经反映到物理介质上去了(因为检查点会保证WAL协议,确保数据被写入),所以在恢复时无须对该事务做Redo操作。
② 事务2
其start日志记录在检查点之前发生,其commit记录在故障点之前发生,说明日志中事务已经完美提交,但数据不一定已经写入,所以属于圆满事务,需要Redo操作。
③ 事务3
其start日志记录在检查点之后发生,其commit记录在故障点之前发生,说明日志中事务已经完美提交,但数据不一定已经写入,所以属于圆满事务,需要Redo操作。
④ 事务4
其start日志记录在检查点之后发生,其commit记录在故障点之前尚未发生,说明日志中事务为中止事务,需要Undo操作。
⑤ 事务5
其start日志记录在检查点之前发生,其commit记录在故障点之前尚未发生,说明日志中事务为中止事务,需要Undo操作。
由CheckPoint的机制可以看出,由于内存中的数据往往比持久化存储中的数据更新,而CheckPoint保证了这部分数据能够被持久化到磁盘,因此CheckPoint之前的数据一定不会再需要被Redo。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。