您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家介绍如何理解vxlan在openstack中的使用场景,内容非常详细,感兴趣的小伙伴们可以参考借鉴,希望对大家能有所帮助。
介绍前,首先讲一下网络中underlay和overlay的概念。underlay指的是物理网络层,overlay是指在物理网络层之上的逻辑网络或者又称为虚拟网络。overlay是建立在underlay的基础上,需要物理网络中的设备两两互联,overlay的出现突破了underlay的物理局限性,使得网络的架构更为灵活。以vlan为例,在underlay环境下不同网络的设备需要连接至不同的交换机下,如果要改变设备所属的网络,则要调整设备的连线。引入vlan后,调整设备所属网络只需要将设备加入目标vlan下,避免了设备的连线调整。
vlan id数量不足
vlan header由12bit组成,理论上限为4096个,可用vlan数量为1~4094个,无法满足云环境下的需求。
vm热迁移
云计算场景下,传统服务器变成一个个运行在宿主机上的vm。vm是运行在宿主机的内存中,所以可以在不中断的情况下从宿主机A迁移到宿主机B,前提是迁移前后vm的ip和mac地址不能发生变化,这就要求vm处在一个二层网络。毕竟在三层环境下,不同vlan使用不同的ip段,否则路由器就犯难了。
mac表项有限
普通的交换机mac表项有4k或8k等,在小规模场景下不会成为瓶颈,云计算环境下每台物理服务器上运行多台vm,每个vm有可能有多张vnic,mac地址会成倍增长,交换机的表项限制则成为必须面对的问题。
以多取胜
vxlan header由24bit组成,所以理论上VNI的数量为16777216个,解决了vid数量不足的问题。
此处需要说明的是:在openstack中,尽管br-tun上的vni数量增多,但br-int上的网络类型只能是vlan,所有vm都有一个内外vid(vni)转换的过程,将用户层的vni转换为本地层的vid。
细心的你可能会有这样的疑问:尽管br-tun上vni的数量为16777216个,但br-int上vid只有4096个,那引入vxlan是否有意义?答案是肯定的,以目前的物理机计算能力来说,假设每个vm属于不同的tenant,1台物理机上也不可能运行4094个vm,所以这么映射是有意义的。 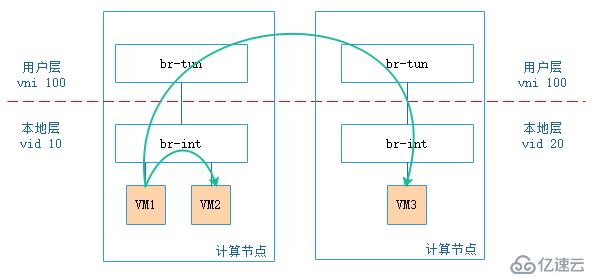
上图是2计算节点间vm通信的示意图,图中所有的vm属于同一个tenant,尽管在用户层同一tenant的vni一致,但在本地层,同一tenant由nova-compute分配的vid可以不一致,同一宿主机上同一tenant的相同subnet之间的vm相互访问不需要经过内外vid(vni)转换,不同宿主机上相同tenant的vm之间相互访问则需要经过vid(vni)转换。如果所有宿主机上vid和vni对应关系一致,整个云环境最多只能有4094个tenant,引入vxlan才真的没有意义。
暗渡陈仓
前面说过,vm的热迁移需要迁移前后ip和mac地址不能发生管改变,所以需要vm处于一个二层网络中。vxlan是一种overlay的技术,将原有的报文进行再次封装,利用udp进行传输,所以也称为mac in udp,表面上传输的是封装后的ip和mac,实际传播的是封装前的ip和mac。 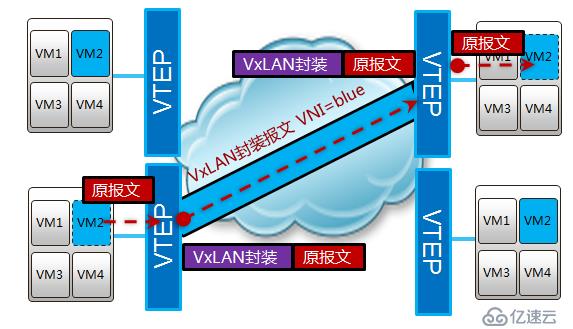
销声匿迹
在云环境下,接入交换机的表项大小会成为瓶颈,解决这个问题的方法无外乎两种:
1.扩大表项 : 更高级的交换机有着更大的表项,使用高级交换机取代原有接入交换机,此举会增加成本。
2.隐藏mac地址: 在不增加成本的前提下,使用vxlan也能达到同样的效果。前文得知,vxlan是对原有的报文再次封装,实现vxlan功能的vetp角色可以位于交换机或者vm所在的宿主机,如果vtep角色位于宿主机上,接入交换机只会学习经过再次封装后vtep的mac地址,不会学习其上vm的mac地址。 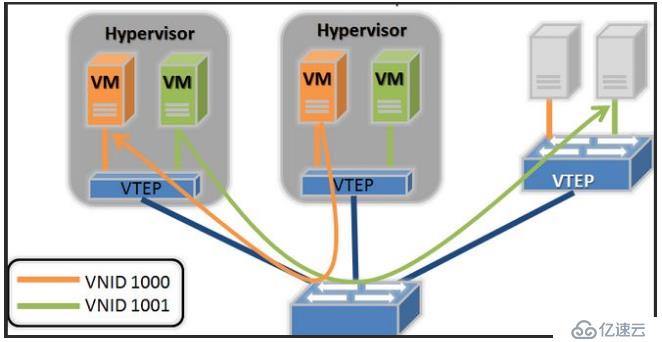
如果vtep角色位于接入交换机上,处理报文的效率更高,但是接入交换机会学习到vm的mac地址,表项的限制依然没有得到解决,后续对这两种情况会做详细说明。
以上就是openstack场景中使用vxlan的原因,下面将会对vxlan的实现原理进行详细说明。
vxlan报文长什么样
vxlan报文是在原有报文的基础上再次进行封装,已实现三层传输二层的目的。 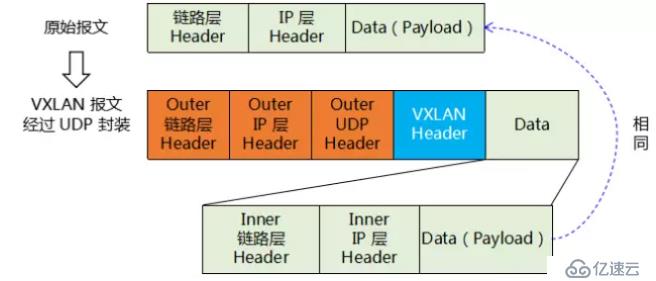
如上图所示,原有封装后的报文成为vxlan的data部分,vxlan header为vni,ip层header为源和目的vtep地址,链路层header为源vtep的mac地址和到目的vtep的下一个设备mac地址。
在笔者所从事的公有云架构中,vtep角色通过宿主机上的ovs实现,宿主机上联至接入交换机的接口类型为trunk,在物理网络中为vtep专门规划出一个网络平面 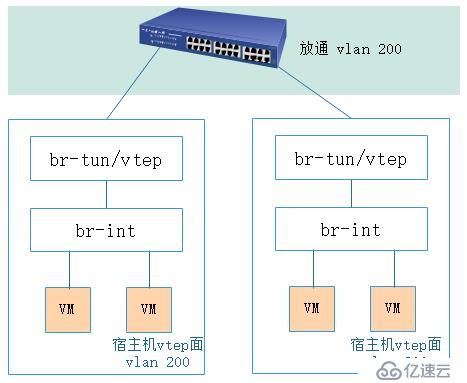
vm在经过vtep时,通过流表规则,去除vid,添加上vni 
vtep平面规划的vid在vxlan的封装过程中被打上,原因如下图所示,vxlan的mac header中可以设置vlan tag 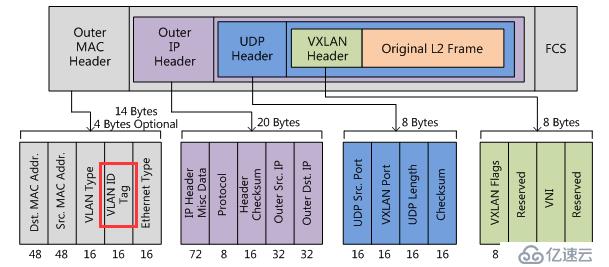
vtep是什么
vtep全称vxlan tunnel endpoint,vxlan可以抽象的理解为在三层网络中打通了一条条隧道,起点和终点的两端就是vetp。vtep是实现vxlan功能的重要模型,可以部署在接入交换机或者服务器上,部署在不同的位置除了前文中提到是否学习vm的mac地址外,实现的机制也所有不同,以下内容如无特别说明,默认vtep部署在接入交换机上,vtep部署在服务器上后面会单独说明。
vxlan隧道的建立
对于物理交换机而言,vtep是物理交换机上的一个角色,换句话说,vtep只是交换机上的一部分功能,并非所有的报文都需要走vxlan隧道,报文也可能走普通的二三层转发。那么哪些报文需要走vxlan隧道? 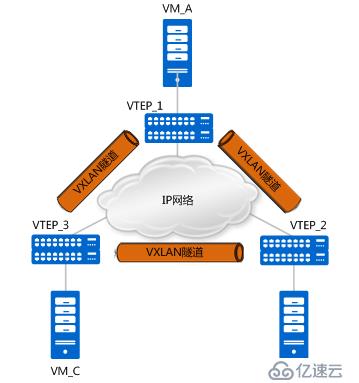
如上图所示,vxlan打造了一个大二层的概念,当连接两个不同vtep的vm需要进行通信时,就需要建立vxlan隧道。每一个大二层域称为一个bridge-domain,简称bd,类似于vlan的vid,不同的bd用vni表示,bd与vni是1:1的关系。
创建bd和设置bd与vni对应关系的配置如下:
# bridge-domain 10 //创建一个编号为10的bd vxlan vni 5000 //设置bd10对应的vni为5000 #
vtep会根据以上配置生成bd与vni的映射关系表,该映射表可以通过命令行查看,如下所示: 
有了映射表后,进入vtep的报文就可以根据自己所属的bd来确定报文封装时该添加哪个vni。问题就剩下报文根据什么来确定自己属于哪个bd。
它可以通过二层子接口接入vxlan隧道和vlan接入vxlan隧道来实现。二层子接口主要做两件事:一是根据配置来检查哪些报文需要进入vxlan隧道;二是判断对检查通过的报文做怎样的处理。 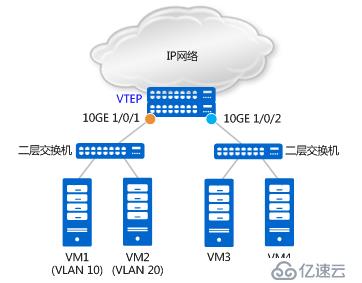
如上图所示,基于二层物理接口10GE 1/0/1,分别创建二层子接口10GE 1/0/1.1和10GE 1/0/1.2,且分别配置其流封装类型为dot1q和untag。配置如下:
# interface 10GE1/0/1.1 mode l2 //创建二层子接口10GE1/0/1.1 encapsulation dot1q vid 10 //只允许携带VLAN Tag 10的报文进入VXLAN隧道 bridge-domain 10 //报文进入的是BD 10 # interface 10GE1/0/1.2 mode l2 //创建二层子接口10GE1/0/1.2 encapsulation untag //只允许不携带VLAN Tag的报文进入VXLAN隧道 bridge-domain 20 //报文进入的是BD 20 #
基于二层物理接口10GE 1/0/2,创建二层子接口10GE 1/0/2.1,且流封装类型为default。配置如下:
# interface 10GE1/0/2.1 mode l2 //创建二层子接口 10GE1/0/2.1 encapsulation default //允许所有报文进入VXLAN隧道 bridge-domain 30 //报文进入的是BD 30 #
至此,所有条件都已具备,就可以通过协议自动建立vxlan隧道隧道,或者手动指定vxlan隧道的源和目的ip地址在本端vtep和对端vtep之间建立静态vxlan隧道。对于华为CE系列交换机,以上配置是在nve(network virtualization Edge)接口下完成的。配置过程如下:
# interface Nve1 //创建逻辑接口 NVE 1 source 1.1.1.1 //配置源VTEP的IP地址(推荐使用Loopback接口的IP地址) vni 5000 head-end peer-list 2.2.2.2 vni 5000 head-end peer-list 2.2.2.3 #
其中,vni 5000的对端vtep有两个,ip地址分别为2.2.2.2和2.2.2.3,至此,vxlan隧道建立完成。
VXLAN隧道两端二层子接口的配置并不一定是完全对等的。正因为这样,才可能实现属于同一网段但是不同VLAN的两个VM通过VXLAN隧道进行通信。
总结一下,vxlan目前支持三种封装类型,如下表所示: 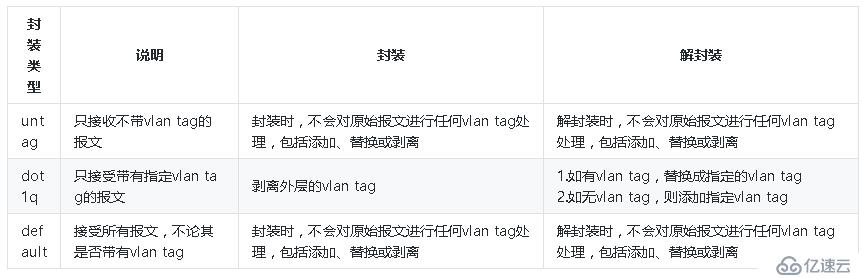
这种方法当有众多个vni的时候,需要为每一个vni创建一个子接口,会变得非常麻烦。 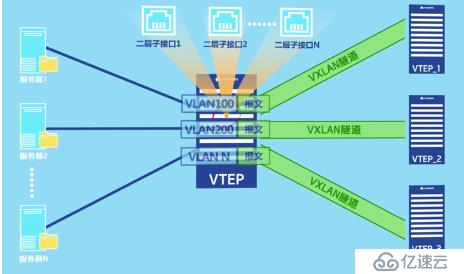
此时就应该采用vlan接入vxlan隧道的方法。vlan接入vxlan隧道只需要在物理接口下允许携带这些vlan的报文通过,然后再将vlan与bd绑定,建立bd与vni对应的bd信息,最后创建vxlan隧道即可。 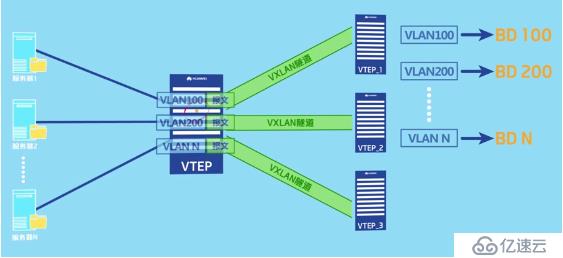
vlan与bd绑定的配置如下:
# bridge-domain 10 //创建一个编号为10的bd l2 binding vlan 10 //将bd10与vlan10绑定 vxlan vni 5000 //设置bd10对应的vni为5000 #
同子网vxlan通信流程 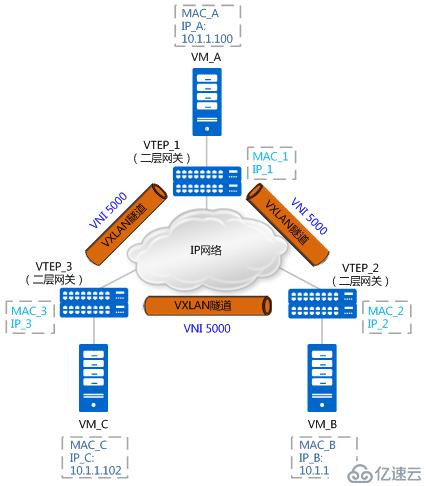
如上图所示,假设vtep是通过接入交换机上的子接口实现,VM_A与VM_C进行首次进行通信。由于是,VM_A上没有VM_C的MAC地址,所以会发送ARP广播报文请求VM_C的MAC地址。就以ARP请求报文及ARP应答报文的转发流程,来说明MAC地址是如何进行学习的。 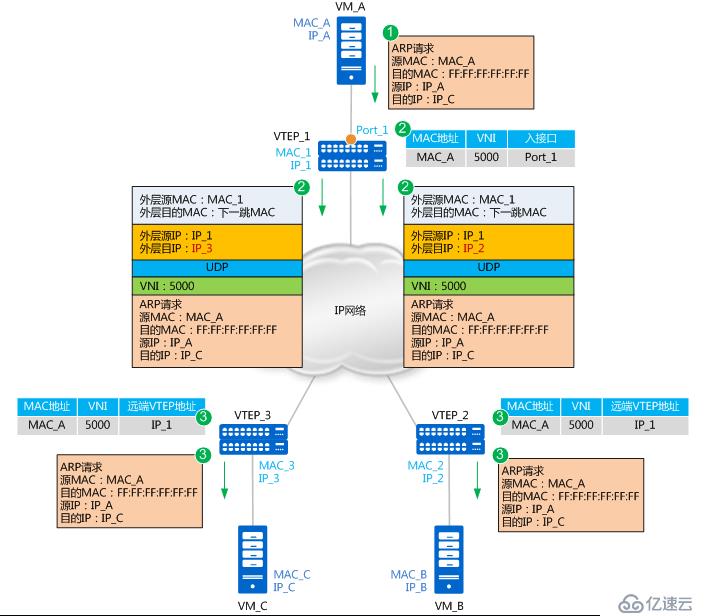
ARP请求报文的转发流程如下:
1. VM_A发送源MAC为MAC_A、目的MAC为全F、源IP为IP_A、目的IP为IP_C的ARP广播报文,请求VM_C的MAC地址。
2. VTEP_1收到这种BUM(Broadcast&Unknown-unicast&Multicast)请求后,会根据头端复制列表对报文进行复制,并分别进行封装。根据二层子接口上的配置判断报文需要进入VXLAN隧道。确定了报文所属BD后,也就确定了报文所属的VNI。同时,VTEP_1学习MAC_A、VNI和报文入接口(Port_1,即二层子接口对应的物理接口)的对应关系,并记录在本地MAC表中。
3. 报文到达VTEP_2和VTEP_3后,VTEP对报文进行解封装,得到VM_A发送的原始报文。同时,VTEP_2和VTEP_3学习VM_A的MAC地址、VNI和远端VTEP的IP地址(IP_1)的对应关系,并记录在本地MAC表中。之后,VTEP_2和VTEP_3根据二层子接口上的配置对报文进行相应的处理并在对应的二层域内广播。
VM_B和VM_C接收到ARP请求后,比较报文中的目的IP地址是否为本机的IP地址。VM_B发现目的IP不是本机IP,故将报文丢弃;VM_C发现目的IP是本机IP,则对ARP请求做出应答。
ARP应答报文转发流程如下图所示: 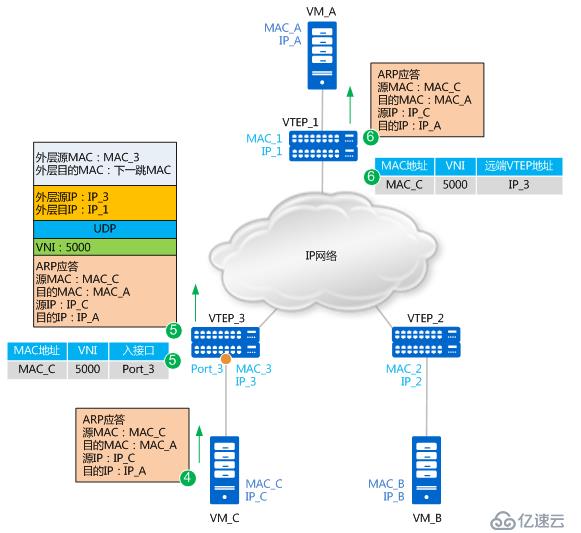
4. 由于此时VM_C上已经学习到了VM_A的MAC地址,所以ARP应答报文为单播报文,单播报文就不再进行头端复制。报文源MAC为MAC_C,目的MAC为MAC_A,源IP为IP_C、目的IP为IP_A。
5. VTEP_3接收到VM_C发送的ARP应答报文后,识别报文所属的VNI(识别过程与步骤2类似)。同时,VTEP_3学习MAC_C、VNI和报文入接口(Port_3)的对应关系,并记录在本地MAC表中。之后,VTEP_3对报文进行封装。这里封装的外层源IP地址为本地VTEP(VTEP_3)的IP地址,外层目的IP地址为对端VTEP(VTEP_1)的IP地址;外层源MAC地址为本地VTEP的MAC地址,而外层目的MAC地址为去往目的IP的网络中下一跳设备的MAC地址。封装后的报文,根据外层MAC和IP信息,在IP网络中进行传输,直至到达对端VTEP。
6. 报文到达VTEP_1后,VTEP_1对报文进行解封装,得到VM_C发送的原始报文。同时,VTEP_1学习VM_C的MAC地址、VNI和远端VTEP的IP地址(IP_3)的对应关系,并记录在本地MAC表中。之后,VTEP_1将解封装后的报文发送给VM_A。
至此,VM_A和VM_C均已学习到了对方的MAC地址。之后,VM_A和VM_C将采用单播方式进行通信。
不同子网vxlan通信流程 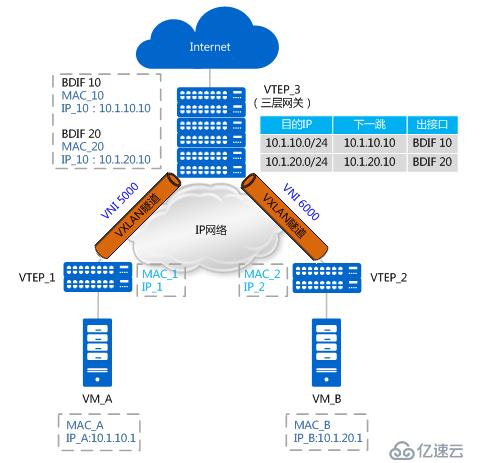
如上图所示,VM_A和VM_B分别属于10.1.10.0/24网段和10.1.20.0/24网段,且分别属于VNI 5000和VNI 6000。VM_A和VM_B对应的三层网关分别是VTEP_3上BDIF 10和BDIF20的IP地址(BDIF接口的功能与VLANIF接口类似,是基于BD创建的三层逻辑接口,用以实现不同子网VM之间或VXLAN网络与非VXLAN网络之间的通信。)。VTEP_3上存在到10.1.10.0/24网段和10.1.20.0/24网段的路由。此时,VM_A想与VM_B进行通信。
由于是首次进行通信,且VM_A和VM_B处于不同网段,VM_A需要先发送ARP广播报文请求网关(BDIF 10)的MAC,获得网关的MAC后,VM_A先将数据报文发送给网关;之后网关也将发送ARP广播报文请求VM_B的MAC,获得VM_B的MAC后,网关再将数据报文发送给VM_B。以上MAC地址学习的过程与同子网互通中MAC地址学习的流程一致,不再赘述。现在假设VM_A和VM_B均已学到网关的MAC、网关也已经学到VM_A和VM_B的MAC,不同子网VM互通报文转发流程如下图所示: 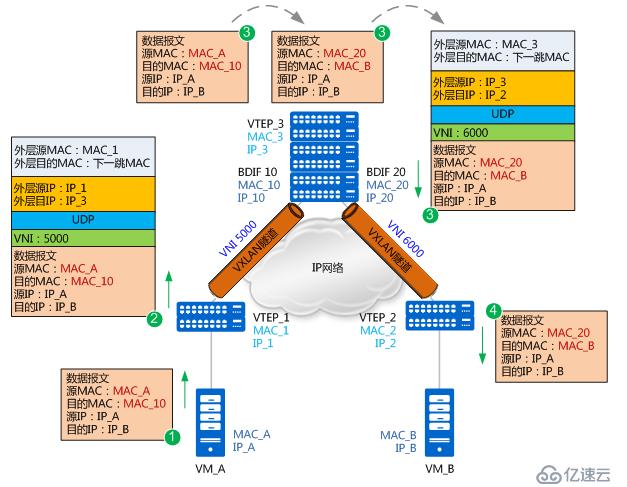
1. VM_A先将数据报文发送给网关。报文的源MAC为MAC_A,目的MAC为网关BDIF10的MAC_10,源IP地址为IP_A,目的IP为IP_B。
2. VTEP_1收到数据报文后,识别此报文所属的VNI(VNI 5000),并根据MAC表项对报文进行封装。这里封装的外层源IP地址为本地VTEP的IP地址(IP_1),外层目的IP地址为对端VTEP的IP地址(IP_3);外层源MAC地址为本地VTEP的MAC地址(MAC_1),而外层目的MAC地址为去往目的IP的网络中下一跳设备的MAC地址。
3. 报文进入VTEP_3,VTEP_3对报文进行解封装,得到VM_A发送的原始报文。然后,VTEP_3会对报文做如下处理:
(1) VTEP_3发现该报文的目的MAC为本机BDIF 10接口的MAC,而目的IP地址为IP_B(10.1.20.1),所以会根据路由表查找到IP_B的下一跳。
(2) 发现下一跳为10.1.20.10,出接口为BDIF 20。此时VTEP_3查询ARP表项,并将原始报文的源MAC修改为BDIF 20接口的MAC(MAC_20),将目的MAC修改为VM_B的MAC(MAC_B)。
(3) 报文到BDIF20接口时,识别到需要进入VXLAN隧道(VNI 6000),所以根据MAC表对报文进行封装。这里封装的外层源IP地址为本地VTEP的IP地址(IP_3),外层目的IP地址为对端VTEP的IP地址(IP_2);外层源MAC地址为本地VTEP的MAC地址(MAC_3),而外层目的MAC地址为去往目的IP的网络中下一跳设备的MAC地址。
4. 报文到达VTEP_2后,VTEP_2对报文进行解封装,得到内层的数据报文,并将其发送给VM_B。VM_B回应VM_A的流程与上述过程类似,不再赘述。
需要说明的是:VXLAN网络与非VXLAN网络之间的互通,也需要借助于三层网关。其实现不同点在于报文在VXLAN网络侧会进行封装,而在非VXLAN网络侧不需要进行封装。报文从VXLAN侧进入网关并解封装后,就按照普通的单播报文发送方式进行转发。
ovs如何创建vxlan隧道
从前文得知,vtep部署在接入交换机上时还是会学习到vm的mac地址,并没有解决表项限制问题,这也是为什么在公有云场景下vtep角色都是部署在宿主机的ovs中。
不同于在接入交换机上通过手动的方式建立vxlan隧道,openstack中负责网络的neutron-server启动后,会自己建立隧道,下面来介绍neutron-server如何自动建立隧道。 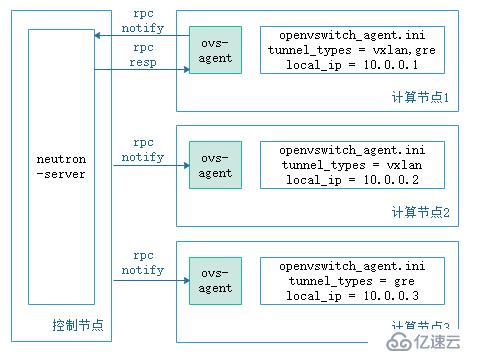
如上图所示,每个宿主机上的ovs是由ovs-aget创建,当计算节点1接入网络中时,他首先会去向neutron-server报告自己的网络类型和local_ip,neutron-server收到这些资源信息后(neutron中network、port、subnet都称为资源)会进行处理,找到相同网络类型的其他计算节点并为他们之间创建隧道,同时将这个消息同步给其他计算节点上的ovs-agent。 
每当neutron资源发生变化时,或者ovs对流量不知该处和处理时,都会像neutron-server汇报或等待它的通知,再加上之前的流表,是不是感觉很熟悉?没错,neutron-server除了接受api请求外,他还是一个sdn控制器。
与接入交换机实现vtep的区别
1. 使用ovs实现的vtep接入交换机只会学习经过vtep封装后的mac地址,学习不到vm的mac地址,这样解决了mack地址表项的问题。
2. 物理交换机是通过bd和vni绑定的方法建立不同的隧道,ovs实现时每一个vtep内可以有多个vsi(virtual switch instance),每一个vsi对用一个vni。
以上就是vxlan在openstack中通过物理设备或者ovs实现的方式。
关于如何理解vxlan在openstack中的使用场景就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。