жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
AWSйҮҢйқўеҸҜд»Ҙз”ЁAthenaжқҘеҲҶжһҗS3йҮҢйқўдҝқеӯҳзҡ„ж—Ҙеҝ—пјҢд»–жҠҠж—Ҙеҝ—иҪ¬жҚўжҲҗж•°жҚ®еә“иЎЁзҡ„ж јејҸпјҢиҝҷж ·е°ұеҸҜд»ҘйҖҡиҝҮsqlиҜӯеҸҘиҝӣиЎҢжҹҘиҜўдәҶгҖӮиҝҷдёӘеҠҹиғҪе’ҢеңЁwindowsжңҚеҠЎеҷЁдёҠз”ЁlogparserжқҘеҲҶжһҗExchangeжҲ–иҖ…IISзҡ„ж—Ҙеҝ—еҫҲзӣёдјјгҖӮ
дёӢйқўеҒҡдёӘжј”зӨәпјҢйҖҡиҝҮCloudtrailи®°еҪ•з®ЎзҗҶж—Ҙеҝ—пјҢ然еҗҺйҖҡиҝҮAthenaжқҘжҹҘиҜўж—Ҙеҝ—еҶ…е®№гҖӮ
йҰ–е…ҲйҖүжӢ©CloudTrail, CloudTrail жҳҜдёҖдёӘж—Ҙеҝ—и®°еҪ•зҡ„жңҚеҠЎпјҢд»–е’Ңcloudwatchзҡ„еҢәеҲ«еңЁдәҺиҝҷдёӘжңҚеҠЎжӣҙеӨҡжҳҜдҫ§йҮҚдәҺе®Ўи®ЎпјҢд»–зҡ„еҶ…е®№йғҪжҳҜе…ідәҺд»Җд№Ҳж—¶еҖҷпјҢд»Җд№ҲиҙҰеҸ·пјҢд»Һд»Җд№ҲIPдёҠиҝӣиЎҢдәҶд»Җд№Ҳж“ҚдҪңгҖӮ

зӮ№еҮ» Create Trail
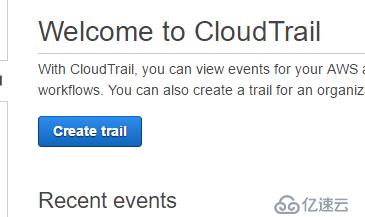
еҸ–дёӘеҗҚеӯ—пјҢ еҲӣе»әдёҖдёӘж–°зҡ„S3 bucketжқҘдҝқеӯҳж—Ҙеҝ—
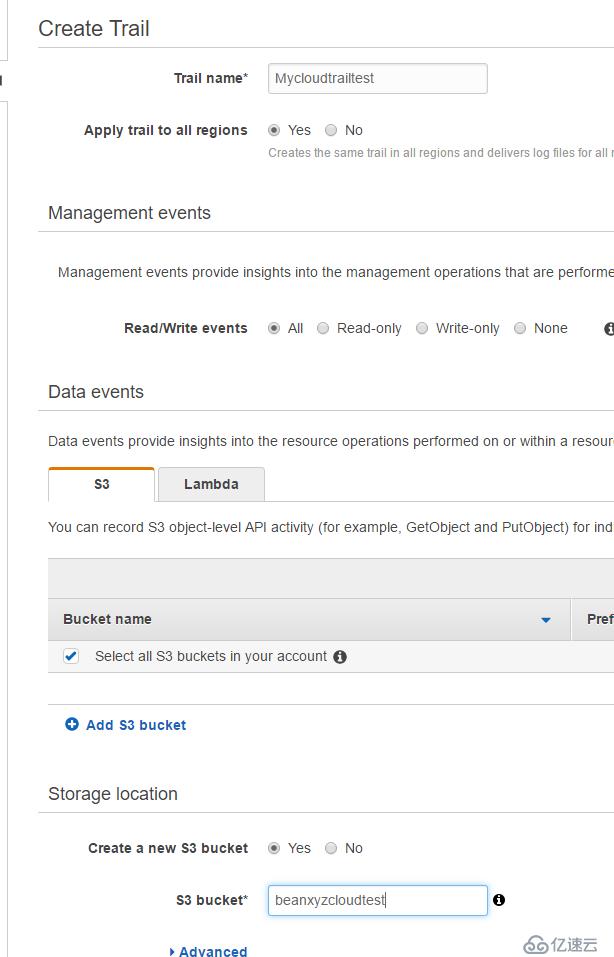
еҲӣе»әеҘҪд№ӢеҗҺеҸҜд»ҘзңӢи§Ғд»–иҮӘеҠЁе·Із»ҸеңЁи®°еҪ•жңҖж–°зҡ„ж—Ҙеҝ—дәҶ
然еҗҺйҖүжӢ© Athena
и·іиҝҮеҗ‘еҜјпјҢзӣҙжҺҘиҝӣе…ҘжҹҘиҜўеҷЁзҡ„зј–иҫ‘еҷЁпјҢиҝҷйҮҢжҳҜзј–иҫ‘SQLиҜӯеҸҘзҡ„ең°ж–№гҖӮиҝҷйҮҢжҲ‘зӣҙжҺҘеҲӣе»әдёҖдёӘзҡ„ж•°жҚ®еә“
дёӢйқўжқҘеҲӣе»әдёҖдёӘиЎЁпјҢд»ҺжҢҮе®ҡзҡ„S3 BucketйҮҢйқўиҺ·еҸ–ж•°жҚ®гҖӮ
жҲ‘们еҸҜд»ҘйҖҡиҝҮеҗ‘еҜјеҲӣе»әпјҢдҪҶжҳҜжҜ”иҫғз№Ғзҗҗ
жҜ”иҫғе®№жҳ“зҡ„жҳҜйҖҡиҝҮи„ҡжң¬еҲӣе»әпјҢжіЁж„ҸжңҖеҗҺдёҖиЎҢS3еӯҳеӮЁжЎ¶зҡ„ең°еқҖ
CREATE EXTERNAL TABLE cloudtrail_logs (
eventversion STRING,
useridentity STRUCT<
type:STRING,
principalid:STRING,
arn:STRING,
accountid:STRING,
invokedby:STRING,
accesskeyid:STRING,
userName:STRING,
sessioncontext:STRUCT<
attributes:STRUCT<
mfaauthenticated:STRING,
creationdate:STRING>,
sessionissuer:STRUCT<
type:STRING,
principalId:STRING,
arn:STRING,
accountId:STRING,
userName:STRING>>>,
eventtime STRING,
eventsource STRING,
eventname STRING,
awsregion STRING,
sourceipaddress STRING,
useragent STRING,
errorcode STRING,
errormessage STRING,
requestparameters STRING,
responseelements STRING,
additionaleventdata STRING,
requestid STRING,
eventid STRING,
resources ARRAY<STRUCT<
ARN:STRING,
accountId:STRING,
type:STRING>>,
eventtype STRING,
apiversion STRING,
readonly STRING,
recipientaccountid STRING,
serviceeventdetails STRING,
sharedeventid STRING,
vpcendpointid STRING
)
ROW FORMAT SERDE 'com.amazon.emr.hive.serde.CloudTrailSerde'
STORED AS INPUTFORMAT 'com.amazon.emr.cloudtrail.CloudTrailInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION 's3://mycloudtrailbucket-faye/AWSLogs/757250003982/';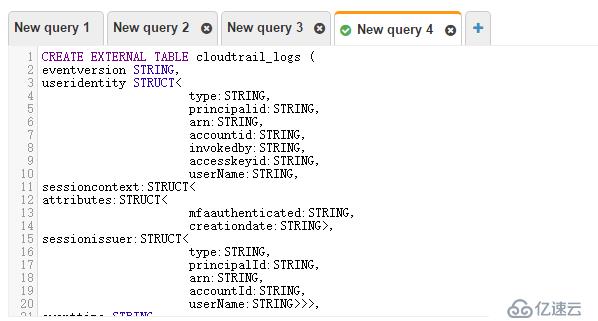
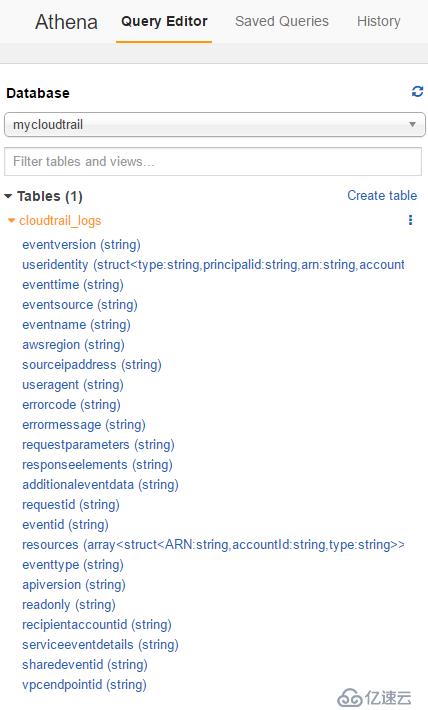
еҲӣе»әиЎЁжҲҗеҠҹзҡ„ж ·еӯҗ
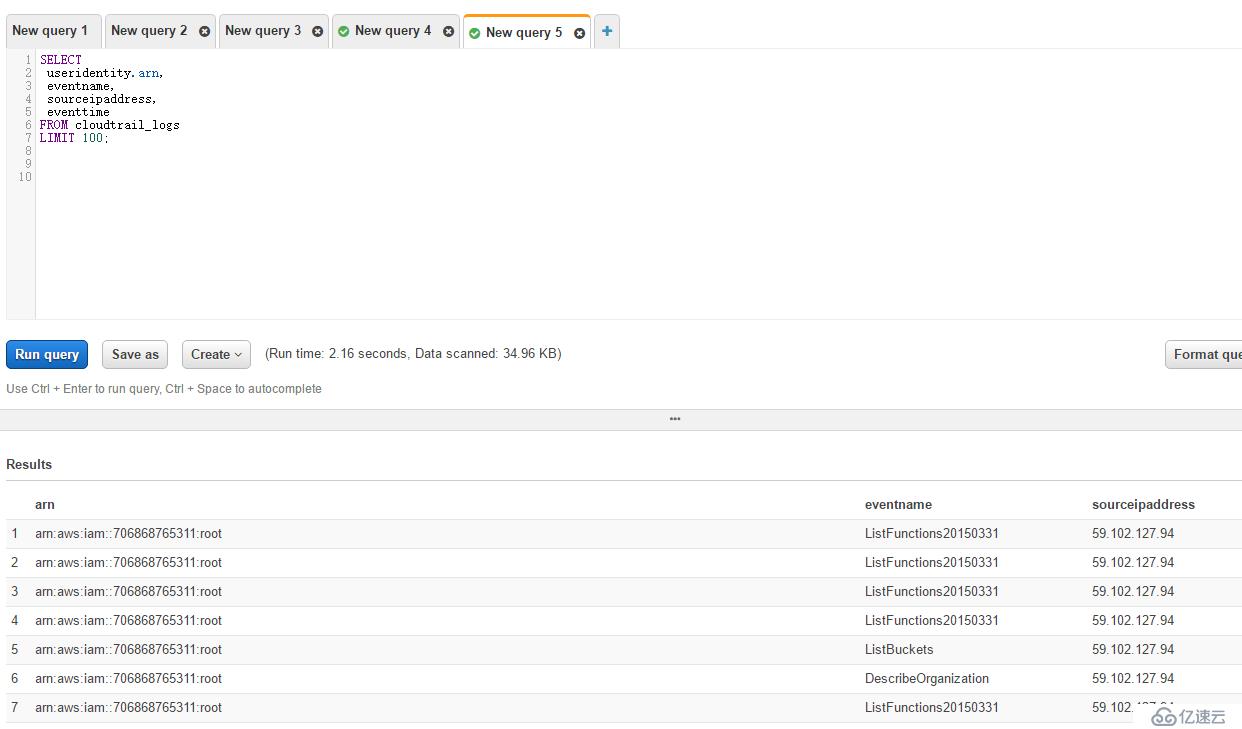
дёӢйқўжҲ‘们еҸҜд»ҘиҝӣиЎҢдёҖдёӘз®ҖеҚ•зҡ„жҹҘиҜўпјҢз»“жһңеҰӮдёӢгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ