您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
我们的 目标 是
理解Oracle数据库管理系统,并由此串联梳理一下核心关键词。
数据库管理系统就像是一 张 网 ,关键词就是网上的交叉点。我们并不会详细解释具体每个关键词的意思,百度或者官方文档会有详细说明,点到为止,有个全貌,混个脸熟。
不知者,有个印象,知之者,了然一笑。如是而已。
先说 Oracle, 但说Oracle之前,又得先提一下 IBM
IBM( 国际商业机器公司 )或万国商业机器公司,简称IBM(International Business Machines Corporation)
名字就那么大气磅礴,至今也是如雷贯耳。
关键是里面牛人辈出。
首先是这一位 :

他叫 E.F.CODDE 。 对了,他的名字就是一个很重要的关键词。因为他是关系数据库的达摩祖师。
1970年,E.F.CODDE 发表 《 大型共享数据库数据的关系模型》,首次明确而清晰地为数据库系统提出了一种崭新的模型, 即 关系模型 。
一声霹雳,石破天惊。

紧接着,同样是IBM牛人的 唐.钱柏林( Don Chamberlin )登场了。他就是 SQL 之父。E.F.CODD只是在数学层面解决了关系代数的研究,而Don Chamberlin 将关系代数 翻译成能够在计算机中简单实现的语言,也就是SQL。

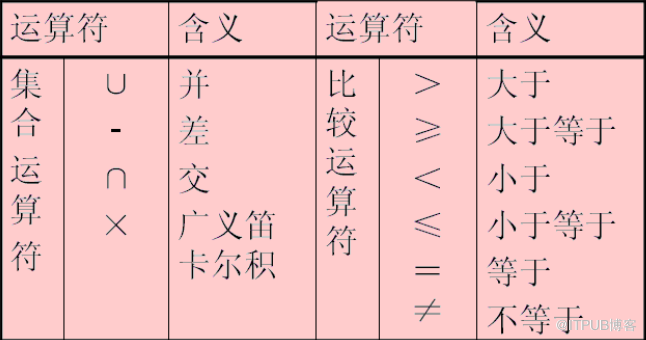
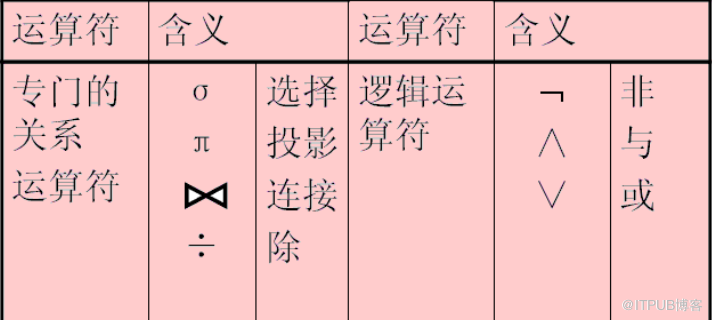
所谓 关系代数 包括
并、差、交、笛卡尔积等集合运算
和
选择、投影、连接、自然连接、外连接、除法等关系运算。
而SQL语言,我们再熟悉不过了。没有它,关系数据库,就是一潭死水。
SQL和关系数据库同样重要!
理论具备,接下来就是怎么用的问题了。当然像SQL标准化之类的问题,是一个逐步角逐的问题,需要时间的沉淀。所有计算机协议和标准都可作如是观。最后,书同文,车同轨都是大势所趋,也势在必然,不然,杂乱无序,只能是一盘散沙,谈何万物互联。
一个具有敏锐商业嗅觉的人,闻风而动。
他就是 拉里·埃里森(Larry Ellison)。 他组建了一个四人团队,如下图:

最右边的就是 拉里·埃里森(Larry Ellison),而手捧蛋糕的就是 Bruce Scott。
Scotte,Oracle数据库里的一个保留测试账号,密码tigger,就是他的猫的名字。
创业维艰,但也可以说顺风顺水。
Oracle迎合潮流而上,站在浪潮之巅。
下图就是如今Oracle在加州的总部。可以看出,气势恢宏,财大气粗。尽管Oracle经过兼收并购,多维发展,不仅仅是一个数据库厂商了,但数据库造型的大楼,也标示着它是依靠数据库起家的。

再说 数据库 不需要过多解释,顾名思义而已,存储数据的仓库。只是随着互联网的发展,如今,数据库又分 关系数据库 和 非关系数据库 ,Oracle数据库,就是关系数据库,当然也包括Mysql,MS-SQL Server,PostgreDB。 非关系数据库,就有点鱼龙混杂,百家争鸣的特色了。如MangoDB,HBASE,Redis, Cassandra. 尽管解释他们的时候,吹嘘 NoSQL 是一项全新的数据库革命性运动,什么“Not only SQL”,但我认为,非关系数据库相比关系数据库来说,没那么伟大,没那个划时代。它只是对关系数据库的变革和改良。因为关系数据库,严谨周密,也就会负重而行。对于有些 应用场景 ,不需要那么严谨,只需要轻装上阵,实现需要的功能即可,什么 ACID , 数据一致性 , 范式 等都将成为累赘。所以非关系数据库,简单一点说,有如下特点:
1.针对特定应用场景,功能单一化。
2.不支持ACID机制,这也是关系数据库的一个基石。
3. 使用相对简单,没有入Mysql,Oracle这样庞大的体系结构。
4. 大部分都是开源的。
记得我十几年前,MySQL还是一个定位中小型的数据库,简陋,不支持事务,读写还是阻塞的等等,作为一个MySQL DBA 是很low的,而如下,Mysql DBA招聘信息琳琅满目,而且报酬丰厚,嫣然已经力压Oracle DBA。因为现在Mysql,InnoDB都是Oracle公司旗下,二者亲密结合,能量级倍增。关系型数据库产品趋于雷同。而且很多问题,都变成了一个架构问题,而Mysql很多欠缺,都可以通过架构来解决。 当然,免费也是一个问题,但对于很多没有那么复杂业务的公司,他们用不了成千上百台数据库服务器(像亚马逊,他们购买数据库产品的费用就不容小觑),数据库产品的费用对于他们的来说,是九牛一毛。而稳定和快捷有效的服务支持才是他们更应该关注的,稳定压倒一切。所以Oracle依旧是他们的首选。
所以,随着开源的关系数据库产品的壮大完善,以及NoSQL数据库的百家争鸣,Oracle随不能说 风光不再,但也不能再说 如日中天。
作为一个DBA,应该懂得更多。
如履薄冰,战战兢兢!
忧心忡忡,兢兢业业!
忧患意识,是每个DBA必需的,尤其是技术快速发展的今天。
再说 数据库管理系统
官方文档如是说:
A database management system (DBMS) is software that controls the storage, organization, and retrieval of data.
Stroage( 存储 ),Organization( 组织 ) ,Retrieval( 检索 )
它 首先是一套 软件 ,只不过它庞大、复杂,是一个系统层面的软件。但终归还是一个软件,有着软件的一般特性。
软件也就是一系列程序的集合。 程序 是死的,是静态的文件,需要让它动起来才能工作。程序被加载进内存中,在内存中活动起来,就表现为 进程 。所以,它依赖于CPU,内存等资源。进程不是尸位素餐,然后死去万事空。计算机不养闲人,占了地方不干活或者不干正事的,那就是病毒。有用的进程是要干活的,是要开花结果的,这些结果是大部分时候要存储下来,需要做持久化保存。这就是外存的作用。 毕竟是数据库,既是数据,还是库,怎能飘然无踪,不做持久存储。
所以,我应该关注:
内存,CPU , 存储,进程状态,这操作系统和硬件层面的因素,在日常的监控和优化时,需要经常关注。
当然,搭建环境(包括软硬件环境)的时候,更应该关注这些因素。特别是 存储架构, I/O吞吐量 ,必须得到保证,I/O分流均衡也是重重之重。毕竟数据库是I/O密集型的应用。好的开始,就是成功的一半,架构好,后面垂拱而治有望,架构差,后面疲于应付难免。
“” 时时勤拂拭,勿使惹尘埃 “”
贴一张《鸟哥的Linux私房菜》的图片,基础,但却不容忽视。
进入数据库内部,我们就应该关注:
内存结构 , 进程状态和功能,以及存储结构
这些都是学习任何一套软件的基本套路,因为计算机的底层都一样,内存,CPU,I/O,外部存储。
下面的几张图中,基本上都是关键词,可以细细品味哦。对于初学者,想了解里面的原理,最好是看图默想和通过一些视频学习,快速学懂,通过官方文档或者是二手说明文字,可能云里雾里
内存结构和进程:
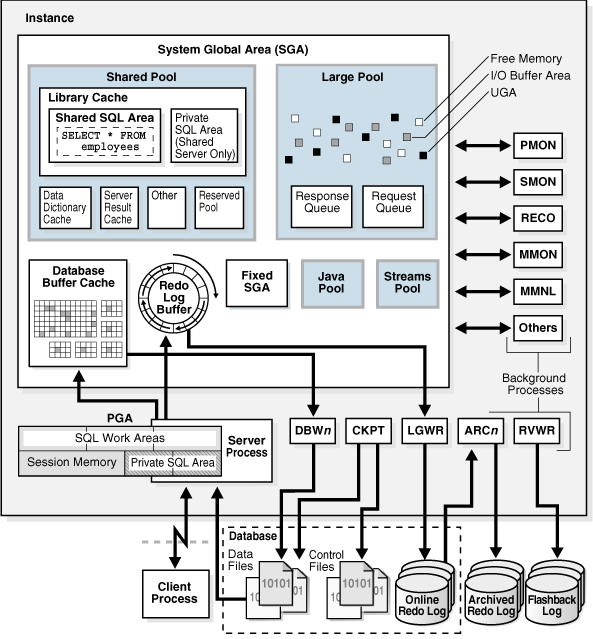
存储结构(物理结构):主要就是一系列文件:
关键文件: 控制文件,数据文件,和在线重做日志文件。
控制文件是中枢,数据文件是基本,在线重做日志文件是保障
三大文件,缺一不可。
非关键文件: 参数文件,密码文件,归档日志文件,告警文件,跟踪文件,备份文件
存储结构(逻辑存储):
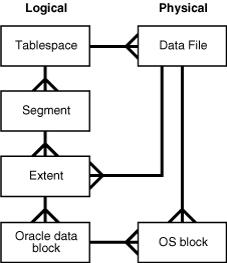
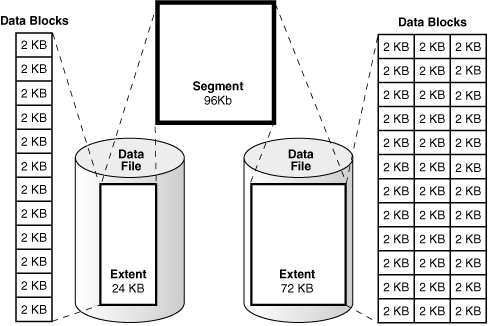
这里需要特别说明一下的是 数据块。
官方如是说:
A data block is the smallest logical unit of data storage in Oracle Database.
One logical data block corresponds to a specific number of bytes of physical disk space, for example, 2 KB. Data blocks are the smallest units of storage that Oracle Database can use or allocate.
数据块
是数据存储在Oracle数据库的最小逻辑单元。
一个逻辑数据块对应于物理磁盘空间的特定字节数,例如,2KB。数据块是Oracle数据库可以使用或分配的最小存储单元。
就像一个盒子,里面放着我们的存储的数据,也就是表中一行一行的数据。每次从磁盘中抽取数据的时候,都是去拿盒子,然后放入内存中。内存中对应的就是 buffer,也就是内存中的一个盒子。计算机中存储的都是0和1,所以盒子,也就块,只是一个逻辑概念上的封装。块是一个逻辑概念,但是存储中中一切概念的基础。
I/O吞吐量是以块为单位的,
性能指标本质上就是 获得多少块 和 用了多少时间 的权衡。
封装,因为要传输。就像邮寄包裹要打包一样。包裹上要写上地址信息,这在TCP/IP中,我们再熟悉不过了,层层打包,层层封装。包邮包头,块有块头。
块头 ,至关重要。因为它存在了事务信息,锁信息等,这可是关系数据的基础哦。
凡事都有头,块有块头,区有区头,段有段头,此种套路,在计算机中,由来已久,甚至与生俱来,所以不容忽视。
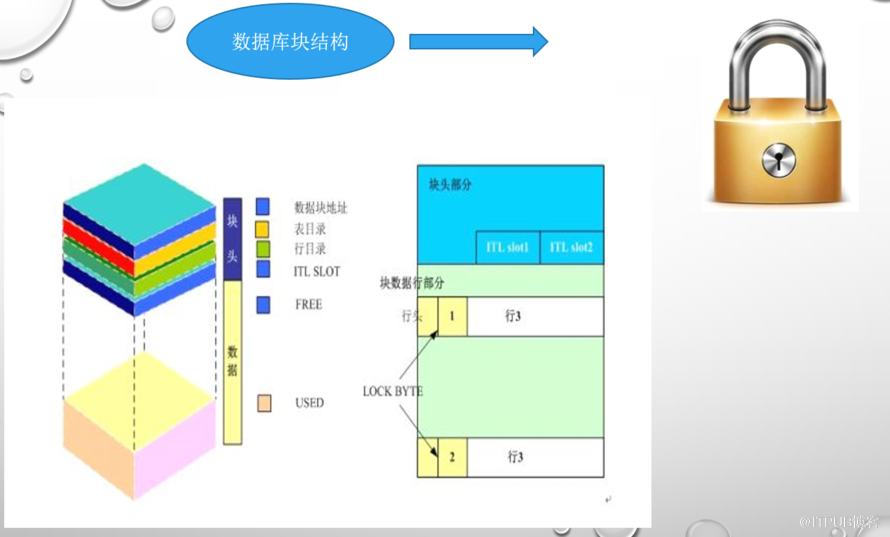
最后再说 数据库 ,这里说的是关系数据库。那么我们就必须知道什么是 关系 。
E.F.CODD提出的关系模型。数学家的论文,我们看不懂,但有人帮我们看懂就行。
关系,就是 二维表 。
在定义关系的时候,科学家做了一系列的工作,我们也没有必要跟走一遍,有兴趣当然可以尝试。
科学家为了定义关系,以及为了解决 数据库设计的时候 冗余 和 一致性 问题而设计出一系列的规范。
所谓规范,遵守即可,因为科学家已经论证过,这是对的。
规范也就是范式,大部分情况,我们设计数据库都应该遵守规范,符合范式要求。但也只是大部分情况,有些情况,为了迎合一些特例,就需要 做 反范式设计 。
所谓反范式设计,也就是故意冗余,将一致性问题交给应用和业务逻辑。以空间换取时间。
说到数据一致性,可以说是结构化数据,也就是关系数据库的一个基石。一个人去修改一个数据,没有不一致的,但数据库管理系统不可能是单一操作的,要不怎么能说它庞大,繁杂呢。 很多人一起访问修改是必然的,也就是 并发 。
并发,是 数据一致性的天敌。道理不言自明。
要两者和谐相处,谈何容易? 于是 锁 就闪亮登场。 它是 并发 和 数据一致性 调节者。
但 锁 是为调节而生的。调节,其实很粗暴。
哲学上说,时间的绝对和空间的相对。 在同一个时间点,一个数据结构,只能是一个人修改。锁,就是让其他人等待,等待就会产生 阻塞 。于是性能问题就出来了。。。
如果没有锁,就没有等待(当然,一些空闲等待,不在这个考虑范围内),也就没有阻塞,数据库会运行的畅通无阻,但这在关系数据库系统中是不可能的。
但是,在非关系数据库中,这是可能的,因为它们可能放弃了锁,为什么能够放弃? 因为它们剔除了对同一资源争议的情况,也就是不要并发了。因为业务不需要。 符合业务需要,又能健步如飞。
end
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。