您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要讲解了“Oracle数据库SQL语句的执行过程”,文中的讲解内容简单清晰,易于学习与理解,下面请大家跟着小编的思路慢慢深入,一起来研究和学习“Oracle数据库SQL语句的执行过程”吧!
1、用户进程在客户端执行SQL语句时,客户端会把这条SQL语句发送给服务器端,让服务器端的进程来处理这语句。也就是说,Oracle 客户端是不会做任何的操作,他的主要任务就是把客户端产生的一些SQL语句发送给服务器端。
2、服务器进程从用户进程把信息接收到后,在 PGA 中就要此进程分配所需内存,存储相关的信息,如在会话内存存储相关的登录信息等。虽然在客户端也有一个数据库进程,但是,这个进程的作用跟服务器上的进程作用是不相同的,服务器上的数据库进程才会对SQL 语句进行相关的处理。当然客户端的进程跟服务器的进程是一一对应的。也就是说,在客户端连接上服务器后,在客户端与服务器端都会形成一个进程,客户端上的我们叫做客户端进程,而服务器上的我们叫做服务器进程。
3、当客户端把SQL语句传送到服务器后,服务器进程会对该语句进行解析。这个解析的工作是在服务器端所进行的,解析过程又可细化。
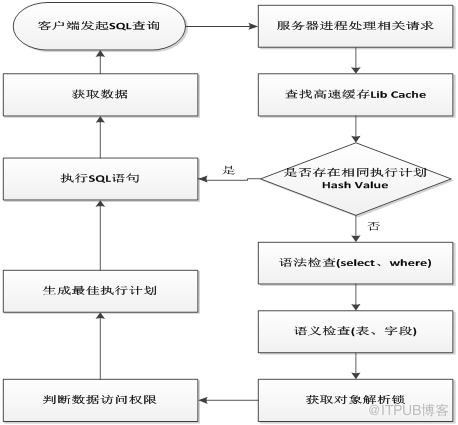
1)查询高速缓存(library cache)
服务器进程在接到客户端传送过来的SQL语句时,不会直接去数据库查询。服务器进程把这个SQL语句的字符转化为ASCII等效数字码,接着这个ASCII码被传递给一个HASH函数,并返回一个hash值,然后服务器进程将到shared pool中的library cache(高速缓存)中去查找是否存在相同的hash值。如果存在,服务器进程将使用这条语句已高速缓存在shared pool的library cache中的已分析过的版本来执行,省去后续的解析工作,这便是软解析。若高速缓存中不存在,则需要进行后面的步骤,这便是硬解析。硬解析通常是昂贵的操作,大约占整个SQL执行的70%左右的时间,硬解析会生成执行树,执行计划,等等。
所以,采用高速数据缓存的话,可以提高SQL 语句的查询效率。其原因有两方面:一方面是从内存中读取数据要比从硬盘中的数据文件中读取数据效率要高,另一方面也是因为避免语句解析而节省了时间。
不过这里要注意一点,这个数据缓存跟有些客户端软件的数据缓存是两码事。有些客户端软件为了提高查询效率,会在应用软件的客户端设置数据缓存。由于这些数据缓存的存在,可以提高客户端应用软件的查询效率。但是,若其他人在服务器进行了相关的修改,由于应用软件数据缓存的存在,导致修改的数据不能及时反映到客户端上。从这也可以看出,应用软件的数据缓存跟数据库服务器的高速数据缓存不是一码事。
2)语句合法性检查(data dictionary cache)
当在高速缓存中找不到对应的SQL语句时,则服务器进程就会开始检查这条语句的合法性。这里主要是对SQL语句的语法进行检查,看看其是否合乎语法规则。如果服务器进程认为这条SQL语句不符合语法规则的时候,就会把这个错误信息反馈给客户端。在这个语法检查的过程中,不会对SQL语句中所包含的表名、列名等等进行检查,只是检查语法。
3)语言含义检查(data dictionary cache)
若SQL 语句符合语法上的定义的话,则服务器进程接下去会对语句中涉及的表、索引、视图等对象进行解析,并对照数据字典检查这些对象的名称以及相关结构,看看这些字段、表、视图等是否在数据库中。如果表名与列名不准确的话,则数据库会就会反馈错误信息给客户端。
所以,有时候我们写select语句的时候,若语法与表名或者列名同时写错的话,则系统是先提示说语法错误,等到语法完全正确后再提示说列名或表名错误。
4)获得对象解析锁(control structer)
当语法、语义都正确后,系统就会对我们需要查询的对象加锁。这主要是为了保障数据的一致性,防止我们在查询的过程中,其他用户对这个对象的结构发生改变。
5)数据访问权限的核对(data dictionary cache)
当语法、语义通过检查之后,客户端还不一定能够取得数据,服务器进程还会检查连接用户是否有这个数据访问的权限。若用户不具有数据访问权限的话,则客户端就不能够取得这些数据。要注意的是数据库服务器进程先检查语法与语义,然后才会检查访问权限。
6)确定最佳执行计划
当语法与语义都没有问题权限也匹配,服务器进程还是不会直接对数据库文件进行查询。服务器进程会根据一定的规则,对这条语句进行优化。在执行计划开发之前会有一步查询转换,如:视图合并、子查询解嵌套、谓语前推及物化视图重写查询等。为了确定采用哪个执行计划,Oracle还需要收集统计信息确定表的访问联结方法等,最终确定可能的最低成本的执行计划。
不过要注意,这个优化是有限的。一般在应用软件开发的过程中,需要对数据库的sql语句进行优化,这个优化的作用要大大地大于服务器进程的自我优化。
当服务器进程的优化器确定这条查询语句的最佳执行计划后, 就会将这条SQL语句与执行计划保存到数据高速缓存(library cache)。如此,等以后还有这个查询时,就会省略以上的语法、语义与权限检查的步骤,而直接执行SQL语句,提高SQL语句处理效率。
4、绑定变量赋值
如果SQL语句中使用了绑定变量,扫描绑定变量的声明,给绑定变量赋值,将变量值带入执行计划。若在解析的第一个步骤,SQL在高速缓冲中存在,则直接跳到该步骤。
5、语句执行
语句解析只是对SQL语句的语法进行解析,以确保服务器能够知道这条语句到底表达的是什么意思。等到语句解析完成之后,数据库服务器进程才会真正的执行这条SQL语句。
对于SELECT语句:
1)首先服务器进程要判断所需数据是否在db buffer存在,如果存在且可用,则直接获取该数据而不是从数据库文件中去查询数据,同时根据LRU 算法增加其访问计数;
2)若数据不在缓冲区中,则服务器进程将从数据库文件中查询相关数据,并把这些数据放入到数据缓冲区中(buffer cache)。
其中,若数据存在于db buffer,其可用性检查方式为:查看db buffer块的头部是否有事务,如果有事务,则从回滚段中读取数据;如果没有事务,则比较select的scn和db buffer块头部的scn,如果前者小于后者,仍然要从回滚段中读取数据;如果前者大于后者,说明这是一非脏缓存,可以直接读取这个db buffer块的中内容。
对于UPDATE语句(insert、delete、update):
1)检查所需的数据库是否已经被读取到缓冲区缓存中。如果已经存在缓冲区缓存,则直接执行步骤3;
2)若所需的数据库并不在缓冲区缓存中,则服务器将数据块从数据文件读取到缓冲区缓存中;
3)对想要修改的表取得的数据行锁定(Row Exclusive Lock),之后对所需要修改的数据行取得独占锁;
4)将数据的Redo记录复制到redo log buffer;
5)产生数据修改的undo数据;
6)修改db buffer;
7)dbwr将修改写入数据文件;
其中,第2步,服务器将数据从数据文件读取到db buffer经经历以下步骤:
a)首先服务器进程将在表头部请求TM锁(保证此事务执行过程其他用户不能修改表的结构),如果成功加TM锁,再请求一些行级锁(TX锁),如果TM、TX锁都成功加锁,那么才开始从数据文件读数据。
b)在读数据之前,要先为读取的文件准备好buffer空间。服务器进程需要扫描LRU list寻找free db buffer,扫描的过程中,服务器进程会把发现的所有已经被修改过的db buffer注册到dirty list中。如果free db buffer及非脏数据块缓冲区不足时,会触发dbwr将dirty buffer中指向的缓冲块写入数据文件,并且清洗掉这些缓冲区来腾出空间缓冲新读入的数据。
c)找到了足够的空闲buffer,服务器进程将从数据文件中读入这些行所在的每一个数据块(db block)(DB BLOCK是ORACLE的最小操作单元,即使你想要的数据只是DB BLOCK中很多行中的一行或几行,ORACLE也会把这个DB BLOCK中的所有行都读入Oracle DB BUFFER中)放入db buffer的空闲的区域或者覆盖已被挤出LRU list的非脏数据块缓冲区,并且排列在LRU列表的头部,也就是在数据块放入db buffer之前也是要先申请db buffer中的锁存器,成功加锁后,才能读数据到db buffer。
若数据块已经存在于db buffer cache(有时也称db buffer或db cache),即使在db buffer中找到一个没有事务,而且SCN比自己小的非脏缓存数据块,服务器进程仍然要到表的头部对这条记录申请加锁,加锁成功才能进行后续动作,如果不成功,则要等待前面的进程解锁后才能进行动作(这个时候阻塞是tx锁阻塞)。
在记redo日志时,其具体步骤如下:
1)数据被读入到db buffer后,服务器进程将该语句所影响的并被读入db buffer中的这些行数据的rowid及要更新的原值和新值及scn等信息从PGA逐条的写入redo log buffer中。在写入redo log buffer之前也要事先请求redo log buffer的锁存器,成功加锁后才开始写入。
2)当写入达到redo log buffer大小的三分之一或写入量达到1M或超过三秒后或发生检查点时或者dbwr之前发生,都会触发lgwr进程把redo log buffer的数据写入磁盘上的redo file文件中(这个时候会产生log file sync等待事件)。
3)已经被写入redo file的redo log buffer所持有的锁存器会被释放,并可被后来的写入信息覆盖,redo log buffer是循环使用的。Redo file也是循环使用的,当一个redo file写满后,lgwr进程会自动切换到下一redo file(这个时候可能出现log file switch(check point complete)等待事件)。如果是归档模式,归档进程还要将前一个写满的redo file文件的内容写到归档日志文件中(这个时候可能出现log file switch(archiving needed)。
在为事务建立undo信息时,其具体步骤如下:
1)在完成本事务所有相关的redo log buffer之后,服务器进程开始改写这个db buffer的块头部事务列表并写入scn(一开始scn是写在redo log buffer中的,并未写在db buffer)。
2)然后copy包含这个块的头部事务列表及scn信息的数据副本放入回滚段中,将这时回滚段中的信息称为数据块的“前映像”,这个“前映像”用于以后的回滚、恢复和一致性读。(回滚段可以存储在专门的回滚表空间中,这个表空间由一个或多个物理文件组成,并专用于回滚表空间,回滚段也可在其它表空间中的数据文件中开辟)。
在修改信息写入数据文件时,其具体步骤如下:
1)改写db buffer块的数据内容,并在块的头部写入回滚段的地址。
2)将db buffer指针放入dirty list。如果一个行数据多次update而未commit,则在回滚段中将会有多个“前映像”,除了第一个“前映像”含有scn信息外,其他每个"前映像"的头部都有scn信息和"前前映像"回滚段地址。一个update只对应一个scn,然后服务器进程将在dirty list中建立一条指向此db buffer块的指针(方便dbwr进程可以找到dirty list的db buffer数据块并写入数据文件中)。接着服务器进程会从数据文件中继续读入第二个数据块,重复前一数据块的动作,数据块的读入、记日志、建立回滚段、修改数据块、放入dirty list。
3)当dirty queue的长度达到阀值(一般是25%),服务器进程将通知dbwr把脏数据写出,就是释放db buffer上的锁存器,腾出更多的free db buffer。前面一直都是在说明oracle一次读一个数据块,其实oracle可以一次读入多个数据块(db_file_multiblock_read_count来设置一次读入块的个数)
当执行commit时,具体步骤如下:
1)commit触发lgwr进程,但不强制dbwr立即释放所有相应db buffer块的锁。也就是说有可能虽然已经commit了,但在随后的一段时间内dbwr还在写这条sql语句所涉及的数据块。表头部的行锁并不在commit之后立即释放,而是要等dbwr进程完成之后才释放,这就可能会出现一个用户请求另一用户已经commit的资源不成功的现象。
2)从Commit和dbwr进程结束之间的时间很短,如果恰巧在commit之后,dbwr未结束之前断电,因为commit之后的数据已经属于数据文件的内容,但这部分文件没有完全写入到数据文件中。所以需要前滚。由于commit已经触发lgwr,这些所有未来得及写入数据文件的更改会在实例重启后,由smon进程根据重做日志文件来前滚,完成之前commit未完成的工作(即把更改写入数据文件)。
3)如果未commit就断电了,因为数据已经在db buffer更改了,没有commit,说明这部分数据不属于数据文件。由于dbwr之前触发lgwr也就是只要数据更改,(肯定要先有log)所有dbwr在数据文件上的修改都会被先一步记入重做日志文件,实例重启后,SMON进程再根据重做日志文件来回滚。
其实smon的前滚回滚是根据检查点来完成的,当一个全部检查点发生的时候,首先让LGWR进程将redologbuffer中的所有缓冲(包含未提交的重做信息)写入重做日志文件,然后让dbwr进程将dbbuffer已提交的缓冲写入数据文件(不强制写未提交的)。然后更新控制文件和数据文件头部的SCN,表明当前数据库是一致的,在相邻的两个检查点之间有很多事务,有提交和未提交的。
当执行rollback时,具体步骤如下:
服务器进程会根据数据文件块和db buffer中块的头部的事务列表和SCN以及回滚段地址找到回滚段中相应的修改前的副本,并且用这些原值来还原当前数据文件中已修改但未提交的改变。如果有多个”前映像“,服务器进程会在一个“前映像”的头部找到“前前映像”的回滚段地址,一直找到同一事务下的最早的一个“前映像”为止。一旦发出了commit,用户就不能rollback,这使得commit后dbwr进程还没有全部完成的后续动作得到了保障。
感谢各位的阅读,以上就是“Oracle数据库SQL语句的执行过程”的内容了,经过本文的学习后,相信大家对Oracle数据库SQL语句的执行过程这一问题有了更深刻的体会,具体使用情况还需要大家实践验证。这里是亿速云,小编将为大家推送更多相关知识点的文章,欢迎关注!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。