您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这期内容当中小编将会给大家带来有关MySQL慢日志优化的案例分析过程,文章内容丰富且以专业的角度为大家分析和叙述,阅读完这篇文章希望大家可以有所收获。
最近在分析一个问题的时候,尝试了很多的方法,算是一个逐步明朗的过程。
首先问题的现象是慢日志报警比较多,这是一套内部运维业务的数据库,涉及两个独立的数据库,我们暂且称为devopsdb(运维管理系统数据库),taskopsdb(任务管理数据库)。
现在报警的是taskopsdb这个数据库。
在开始之前,我先说下整体的环境和架构,数据库版本是5.7.25,使用了MGR架构模式,并且略微冒一些,使用了双活的模式,从业务上来说,devopsdb和taskopsdb数据写入上是独立的,所以直接的数据冲突可能性几乎没有。
devopdb的写入是实时的,业务种类比较多,而taskopsdb的写入相对要少很多,从我的直观关键,两者的压力基本是9:1或者差异更大。
有慢日志了就进行优化吧,但是这个慢日志报告让我有些懵,可以看到里面94%的响应时间是在处理commit的请求。
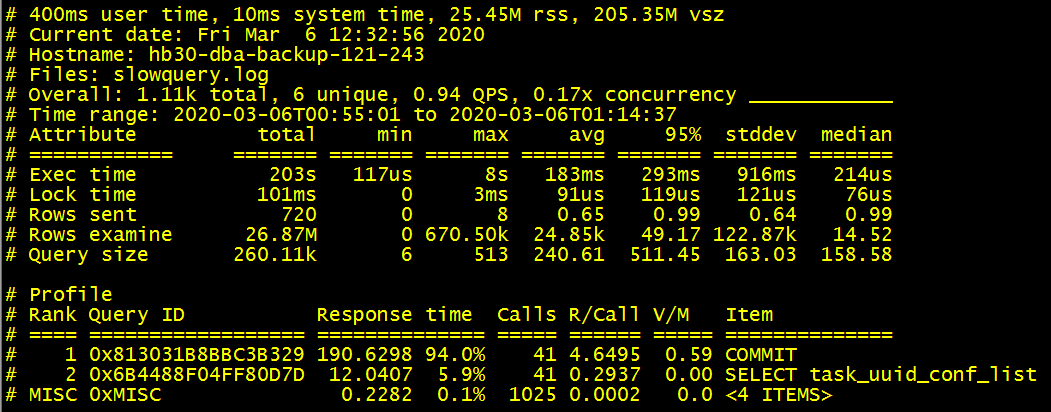
从慢日志的整体情况可以看到来自于两个客户端。
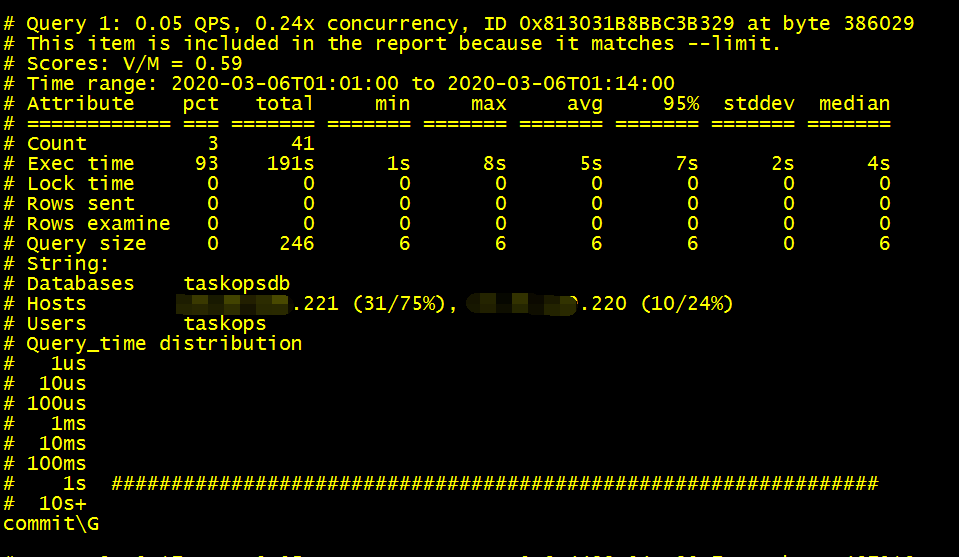
我们直接看下commit相关的SQL吧,结果打开一看慢日志文件,基本就是这样的输出结果,既然是慢日志,那么影响的数据行数应该是比较明显的,但是这里看到“Rows_examined”和“Rows_sent"都是0,但是很直白的是commit的执行时间依旧很长。
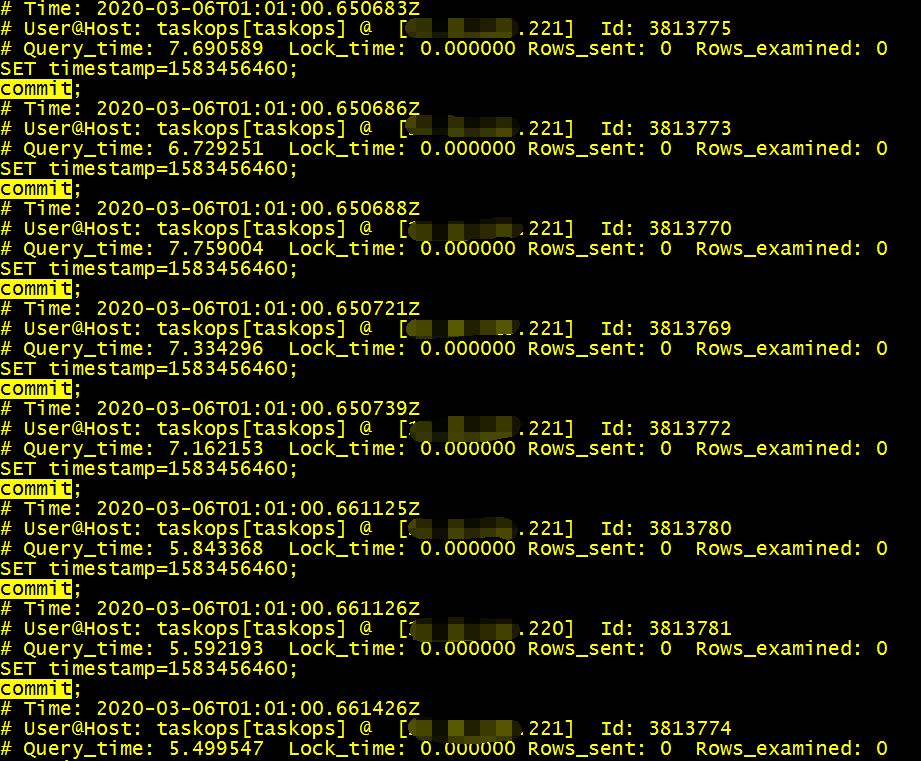
问题到了这里似乎有些两难,想优化但是苦于没有太直接有效的信息,在把整个慢日志梳理了一遍之后,我开始关注那5%的慢日志信息,发现确实有几个表的扫描代价太高了,算是一个优化点。
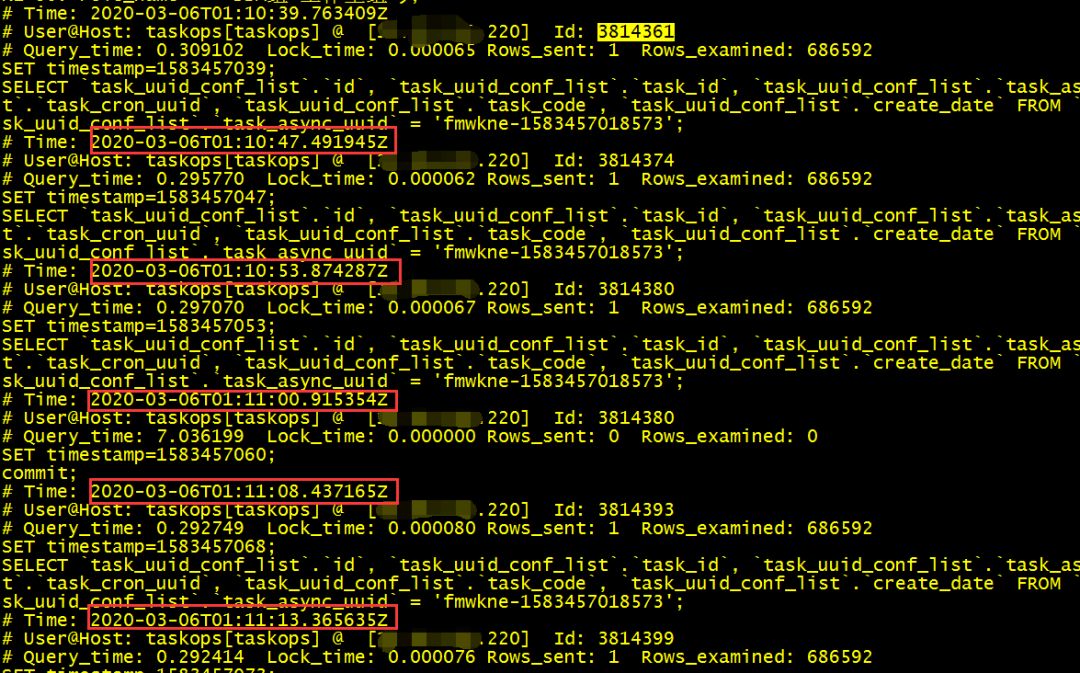
做完优化之后,发现报警频率确实少了很多,但是问题依旧存在。每次收到这样的报警信息,总是让人感觉到不舒服。
于是我开始想有没有其他的思路和方法。
我们从报警入手,报警的阈值是统计慢日志条数超过300就报警,所以我们可以入手的一个显式指标是300个慢日志,如何找到这300个慢查询,按照近期的报警信息,可以看到这些报警的时间相对是比较固定的,比如晚上22:00,或者早上9:00这样的时间,所以问题的发生存在周期性。
基于MGR的方案自身有一些特点,我们暂且先放下,嘉定我们不了解MGR.
两个节点的数据同步,基本是这样的场景,taskopsdb的短时间产生了大量的慢日志,而这些慢日志的表现是commit,这个commit的本质其实不是taskopsdb里面存在大量的commit操作,而是因为其他原因,导致原本无害的commit操作产生了堆积或者阻塞。所以commit的部分只是表象。
另外两个节点的数据同步,devopsdb的DML,DDL才会直接影响taskopsdb的负载,也就意味着devopsdb上面的慢日志从表面来看是不会影响taskopsdb的相关操作的。
顺着这个思路,我们往下分析,我下午的时候做了一个大胆的尝试,那就是从原来的MGR的模式降级为异步双主的模式,结果就好像潮水褪去一样,这些慢日志都付出水面了。
也就意味着根本的慢日志就是taskopsdb上面的两类不起眼的慢日志,修复了索引之后,这个问题就没有出现,当然这个问题的反思还在进行中。
上述就是小编为大家分享的MySQL慢日志优化的案例分析过程了,如果刚好有类似的疑惑,不妨参照上述分析进行理解。如果想知道更多相关知识,欢迎关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。