您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
一、引言
在运维MySQL时,经常遇到的一个问题就是活跃连接数飙升。一旦遇到这样的问题,都根据后台保存的processlist信息,或者连上MySQL环境,分析MySQL的连接情况。处理类似的故障多了,就萌生了一种想法,做个小工具,每次接到这种报警的时候,能够快速地从各个维度去分析和统计当前MySQL中的连接状态。比如当前连接的分布情况、活跃情况等等。
另外,真实故障处理时,光知道连接分布情况往往还不够,我们需要知道当前MySQL的正在忙于做什么,也就是正在执行一些什么样的SQL。而且,有时候即使我们知道了当前执行的SQL情况,也很难找到根因,因为如果活跃连接一旦飙升,这是的CPU基本上是处于被打满的状态,IO的负载也非常高,即使平时很快的SQL也变成了慢SQL,更不用说本身就很慢的SQL了。那我们怎么去甄别这些SQL里,哪些是导致问题的罪魁祸首,哪些仅仅是受害者呢?
带着这些需求和问题,本文逐渐展开并一一做分析和解答,展示我们这个小工具的功能。
二、连接分析
想知道当前MySQL的连接信息,最直观的方法是看MySQL的processlist,如果希望看到完整的SQL,可以执行show full processlist,或者直接查information_schema中的processlist这个表。当MySQL中连接数比较少的时候,还能够人肉分析出来,可是如果连接数比较多,那就很难考肉眼看processlist去分析问题了。
最开始,我们的做法是写个脚本,用MySQL客户端在命令行登录MySQL,并执行show full processlist,然后将输出作为一个文本分析。本来这种实现方式在MySQL5.5和MariaDB上运行得很好,可是,当在MySQL5.6环境上运行时,出现了问题,在控制台输出中会多出一行Warning: Using a password on the commandline interface can be insecure,相信很多运行orzdba的同学也遇到过这种情况。这个是MySQL5.6本身的安全提示,输入明文密码时,没有办法避免,阿里的同学还分享过他们为此做过源码改造,因为他们很多任务都依赖于命令行执行MySQL命令并捕获结果。
还有另外一种方式规避这个问题就是用mysql_config_editor这个工具,但是这个需要做额外的一些配置,同时也有安全上的隐患。我们没有能力改造源码,但是也不想使用mysql_config_editor,所以我们使用了另外的方式,不从命令行登录,而是用information_schema的表processlist作为数据源,在上面做查询,得到processlist的信息。还有另外一张表performance_schema.threads,也包含了同样的结果,甚至更丰富的后台线程信息,而且相比information_schema.processlist,在查询的时候不用申请mutex,对系统系能影响小,不过这要求打开perfomance schema,感兴趣的同学可以自己尝试。
确定了连接信息来源,下面就开始分析信息统计维度。查看processlist这个表,表结构如下(以MySQL5.6为例,MariaDB可能有额外的信息):
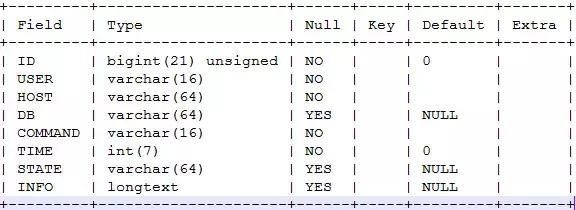
ID:线程ID,这个信息对统计来说没有太大作用
USER:连接使用的账号,这个是一个统计维度,用于统计来自每个账号的连接数
HOST:连接客户端的IP/hostname+网络端口号,这也是一个统计维度,用于确定发起连接的客户端
DB:连接使用的default database,DB通常对应具体服务,可以用于判断服务的连接分布,这算一个统计维度
COMMAND:连接的动作,实际上是说连接处于哪个阶段,常见的有Sleep、Query、Connect、Statistics等,这也是一个统计维度,主要用于判断连接是否处于空闲状态
TIME:连接处于当前状态的时间,单位是s,这个在后面进行分析,暂不算在连接状态的统计维度中
STATE:连接的状态,表示当前MySQl连接正在做什么操作,这算一个统计维度,可能的值也比较多,详细可以查阅官方文档
INFO:连接正在执行的SQL,这个在下一节分析,暂不算在连接状态的统计维度中
通过上面的分析,总结出了5个连接的统计维度:user、host、db、command和state。有了这5个统计维度,我们就可以开始着手写小工具了。

最基本的功能需求就是,查询information_schema.processlist这个表,然后按刚才总结的5个统计维度,对MySQL中的连接进行分组统计,按照统计个数排序。processlist这个表的host字段需要做一些细节上的处理,因为它的值实际上是IP/hostname+网络端口号的组合,我们需要把端口号裁剪掉,这样才能按照客户端进行统计,否则每个客户端连接的端口号都是不一样的,没法进行分组统计。
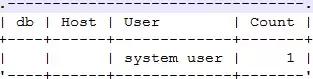
最后的输出如下:

有了最基本的功能,能满足最基本的统计需求。可是在实际排查和处理线上问题时,可能并不关心所有的统计维度,只需要按照上述5个维度中的部分进行统计;另外,可能希望host出现在user的前面,优先按照客户端的IP或者是hostname进行统计。所以,这就要求这个工具具有增加灵活地添加或者删除统计维度的功能,而且能够对统计维度的出现顺序进行动态调整。
最后的示例输出如下:
最开始说了,我们造这个工具的初衷是分析活跃连接,可是统计出来的结果中,包含了空闲连接,那么需要将空闲连接从统计结果中排除出去。当然,除了空闲连接,可能还有一些MySQL本身的一些连接,例如slave线程,binlog dump线程等,也希望从结果排除出去。这就要求有个按照任意统计维度进行排除的功能。既然有了排除功能,那同样也可以增加包含功能,即按照任意统计维度进行过滤,包含固定条件的连接才能出现在统计结果之中。
有了这个连接统计信息,我们就清楚当前MySQL内部的连接状态,大致判断出是哪个业务或者模块有问题。
三、SQL分析
分析到业务或者模块的粒度还不够,到底是哪个接口或者是哪个功能有问题呢?根据上面的连接状态信息,还没有办法准确地回答这个问题。我们继续深入,分析processlist中的SQL,回去看到上节中被我们暂时忽略的information_schema.processlist这个表的INFO字段,里面就保存了每个活跃连接上正在执行的SQL信息。通过分析和统计SQL,我们才真正清晰地掌握MySQL当前的内部活动,活跃连接都在干些什么事。通过这种方式,我们可以协助RD同学快速地定位问题,找到有问题的接口或者是功能模块。
其实,要统计SQL并不容易,因为SQL千变万化,每一条SQL都不是一样的,即使是统一功能模块的SQL,参数也可能不一样。那这种情况下,如何统计SQL呢?这里借鉴了pt-toolkit中的设计思想。在pt-query-digest的分析结果中,有一个fingerprint的字段,它其实是一个hash值,这个hash值代表了一类SQL,这类SQL除了参数不一样之外,其它的SQL结构都是完全一致的。所以我们把这种思路引入到具体实现中,通过正则,将SQL中的具体条件都去掉,然后将正则之后的SQL结构相同的SQL都算作同一条SQL,然后就可以进行分组统计了。举个例子,比如现在应用里有2条SQL,分别如下:
SELECT * FROM `xxxxxxxxxxxxxxxxxxxx` `t` WHERE `t`.`ucid`='1000000020018048' LIMIT 1
SELECT * FROM `xxxxxxxxxxxxxxxxxxxx` `t` WHERE `t`.`ucid`='1000000020281039' LIMIT 1
这2条SQL除了最后where条件中ucid字段的值不一样之外,其他的SQL结构是完全一致的。通过正则匹配之后,将ucid的值和limit的行数去掉,在最终的统计结果中,这2条SQL都变成了下面的SQL:
SELECT * FROM `xxxxxxxxxxxxxxxxxxxx` `t` WHERE `t`.`ucid`=? LIMIT ?
这样,就实现了SQL的分组统计。

示例输出如下:

当然,还可以根据需要,添加一些附加信息,便于定位和分析问题,例如user、Host等。

四、事务分析
有了SQL分析和统计,在某些场景下,基本能定位到问题所在,比如高频的执行计划良好的SQL。可是如果是由于慢SQL导致整个系统响应变慢的场景,上面单纯的SQL统计是否还能够有效地快速定位出问题呢?肯定不能,因为此时,单纯地从统计结果,无法分辨出哪些是导致系统响应变慢的慢SQL,哪些是被影响的SQL。当然,统计结果中,次数多的SQL可能会是慢SQL,但是也可能本身就是一些高频的接口调用,因为系统响应变慢,导致请求堆积。所以,最好的办法就是能够加入一些其它的辅助信息,帮助判断哪些请求可能是慢查询。那加入哪些辅助信息呢?有两种选择。
首先,我们回去看第一节被我们忽略的information_schema.processlist这个表的Time字段,可以用于大概判断连接的上SQL的执行,和实际时长的差异取决于SQL执行时每个阶段所消耗的时间。其次,因为线上表都是InnoDB表,所以可以和InnoDB的事务统计信息进行关联。InnoDB的事务分为只读事务和读写事务,信息都保存在information_schema.INNODB_TRX这张表里。对于某些大事务的场景下,一个事务包含多个操作,这种方式得出的结果会有偏差。如果是非InnoDB的引擎,这种方式不适用。
此处分析时,以只读事务,也就是select语句为例。在实现上,我们将问题简化,通过processlist中time字段的值或者事务的执行时间,去预估一条SQL的执行时间,进而判断在processlist中,积压的大量连接中,哪些请求本身就是慢查询,哪些是受影响变慢的查询。利用事务判断时,将processlist中ID字段和information_schema.INNODB_TRX中trx_MySQl_thread_id字段做关联,具体的SQL为select p.*, now() - t.trx_started as runtime frominformation_schema.processlist p, information_schema.INNODB_TRX t where p.id =t.trx_MySQl_thread_id。最后,统计正则之后每一类SQL总的执行时间,以及平均执行时间。执行时间越长的,我们更倾向于认为是导致问题的罪魁祸首。
示例输出如下:

RT:这一类SQL截止当前,总的执行时间,单位是S(秒)
AVGRT:这一类SQL截止当前,每个事务平均执行时间,单位是S(秒)
加入user、Host等附加信息之后,输出如下:

五、结语
通过上面的3个维度,把MySQL的processlist中的可用信息基本上都挖掘得差不多了。我们在实际问题排查和处理时,也经常使用这个工具,经过实践检验,问题定位效率还是比较高效的。
但是,也还存在很多改进的地方。比如SQL语句分析中,limit值不同的,严格来说其实应该算不同的SQL,因为执行时间可能相差非常大。另外,SQL执行时间分析中,对于单条select语句的只读事务分析结果非常准确,但是对于读写事务,怎么减少结果的误差,因为读写事务相比只读事务会更复杂,因为可能涉及锁等待等一些额外的情况。所有的这些已经在我们的改进计划中,如果大家有好的思路或者是想法,欢迎交流。
我们自己做这些事情,其实日常运维经验的积累和沉淀,如果刚好某位同学的思路和实现有雷同,实属必然。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。